復旧計画について
この記事では、Azure Site Recovery の復旧計画の概要を説明します。
復旧計画では、フェールオーバーを目的としてマシンを復旧グループに収集します。 復旧計画は、フェールオーバー可能な小規模の独立ユニットを作成して体系的な復旧プロセスを定義するために役立ちます。 ユニットは通常、環境内のアプリを示します。
- 復旧計画はマシンがどのようにフェールオーバーするか、およびフェールオーバー後の起動のシーケンスを定義します。
- 復旧計画は、Azure へのフェールオーバーと Azure からのフェールバックの両方に使用できます。
- 最大 100 の保護インスタンスを 1 つの復旧計画に追加できます。
- 順序、説明、タスクを追加することで計画をカスタマイズできます。
- 計画を定義した後に、フェールオーバーを実行できます。
- マシンは、複数の復旧計画で参照できます。その中で、マシンが別の復旧計画を使用してデプロイされている場合、後続の計画ではマシンのデプロイ/起動はスキップされます。
- バックエンドでは復旧計画の名前を使用してフェールオーバー操作を特定するため、フェールオーバー後は VM をある復旧計画から変更して別の復旧計画に追加しないことをお勧めします。
復旧計画を使用する理由
復旧計画は、次の用途で使用します。
- アプリの依存関係をモデル化する。
- 回復タスクを自動化して、目標復旧時間 (RTO) を短縮します。
- アプリが復旧計画の一部に含まれており、移行またはディザスター リカバリーの準備ができていることを確認する。
- 復旧計画でテストフェールオーバーを実行して、ディザスター リカバリーまたは移行が期待どおりに機能することを確認します。
アプリを形成する
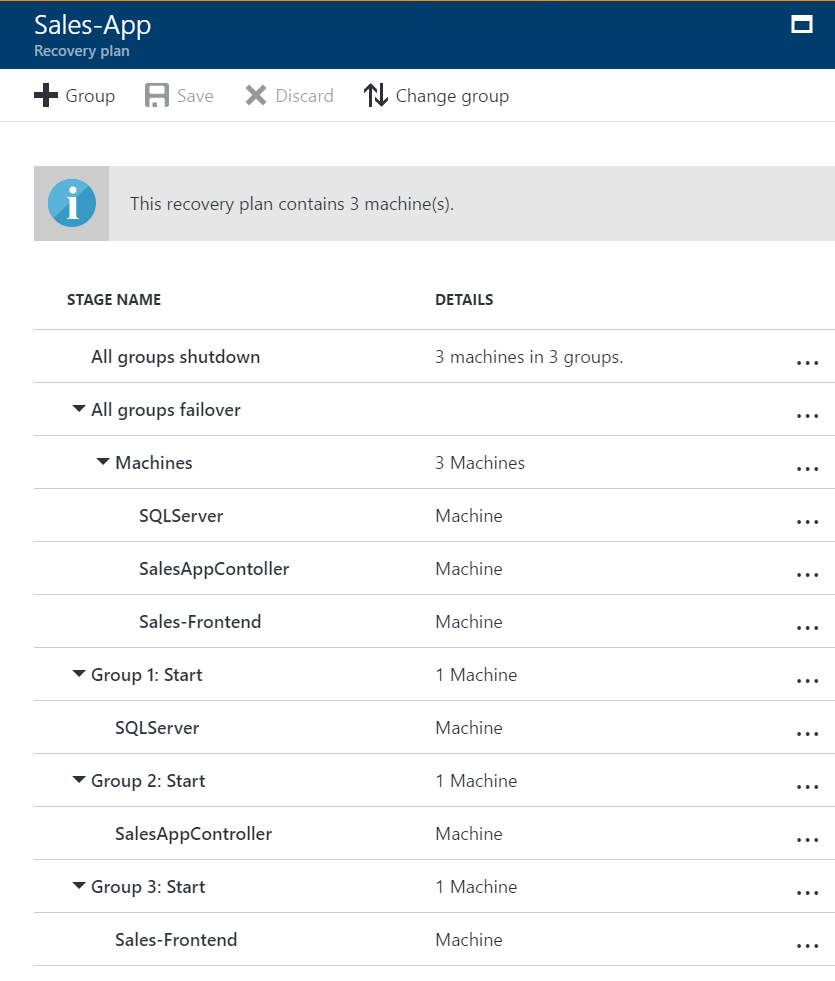
復旧グループを計画および作成してアプリ固有のプロパティをキャプチャできます。 例として、SQL Server バックエンド、ミドルウェア、Web フロントエンドの典型的な 3 層のアプリケーションを考えてみましょう。 通常、フェールオーバー後に各層のマシンが正しい順序で起動するように、復旧計画をカスタマイズします。
- 最初に SQL バックエンド、次にミドルウェア、最後に Web フロントエンドが起動する必要があります。
- この順序であれば、最後のマシンが起動するまでには、アプリケーションが確実に動作しています。
- この順序により、ミドルウェアが起動して SQL Server の層に接続を試行するときには、すでに SQL Server の層が実行されています。
- また、この順序によりフロントエンド サーバーが最後に起動し、すべてのコンポーネントが稼働して、アプリで要求を受け入れる準備ができるまで、エンド ユーザーがアプリの URL に接続することがなくなります。
この順序を作成するには、復旧グループにグループを追加し、マシンをそのグループに追加します。
順序を指定した場所に、シーケンス処理が使用されます。 アクションは、適切な場所で並列実行され、アプリケーションの復旧 RTO が改善します。
1 つのグループに含まれるマシンは並列でフェールオーバーされます。
別のグループのマシンはグループの順序でフェールオーバーされるため、グループ 1 のマシンがフェールオーバーされて起動するまで、グループ 2 のマシンのフェールオーバーは始まりません。
このカスタマイズにより、この復旧計画でフェールオーバーを実行すると、次のように動作します。
- シャットダウンのステップによって、オンプレミスのマシンの停止が試行されます。 例外はテスト フェールオーバーを実行した場合で、プライマリ サイトの実行が継続されます。
- シャットダウンによって、復旧計画に含まれるマシンすべてのフェールオーバーが並列にトリガーされます。
- フェールオーバーにより、レプリケートされたデータを使用して仮想マシンのディスクが準備されます。
- 起動グループは順序どおりに実行され、各グループのマシンが起動されます。 最初はグループ 1、次にグループ 2、最後にグループ 3 が実行されます。 グループに複数のマシンがある場合、すべてのマシンが並列で起動します。
復旧計画のタスクを自動化する
大規模なアプリケーションの復旧は複雑になる可能性があります。 手動でのステップ実行ではプロセスでエラーが発生しやすくなり、フェールオーバーを実行するユーザーがすべてのアプリの技術的詳細を把握していない可能性があります。 復旧計画は順序を指定し、各ステップで必要とされるアクションを自動化します。Azure へのフェールオーバーには Azure Automation の Runbook かスクリプトを使用します。 自動化できないタスクについては、手動アクションを実行するために、復旧計画に一時停止を挿入できます。 次の種類のタスクを構成できます。
-
フェールオーバー後の Azure VM 上のタスク:Azure にフェールオーバーするとき、通常はフェールオーバー後に仮想マシンに接続できるように、アクションを実行する必要があります。 例:
- Azure の仮想マシン上に パブリック IP アドレスを作成します。
- Azure の仮想マシンのネットワーク アダプターにネットワーク セキュリティ グループに割り当てます。
- 可用性セットにロード バランサーを追加します。
-
フェールオーバー後の VM 内のタスク:これらのタスクは通常、マシンで実行されているアプリを再構成し、新しい環境で適切に動作し続けるようにします。 例:
- マシン内のデータベース接続文字列を変更します。
- Web サーバーの構成またはルールを変更します。
復旧計画で、テストフェールオーバーを実行する
復旧計画を使用して、テスト フェールオーバーをトリガーできます。 次のベスト プラクティスを使用してください。
完全なフェールオーバーを実行する前に、常にアプリに対してテスト フェールオーバーを実行する。 テスト フェールオーバーは、アプリが復旧サイトで利用可能になるかどうかを確認するうえで役立ちます。
何かを見落としている場合は、クリーンアップをトリガーし、テスト フェールオーバーを再実行する。
アプリがスムーズに復旧することを確認するまで、テスト フェールオーバー複数回実行する。
アプリはそれぞれが固有であるため、各アプリケーションに合わせてカスタマイズされた復旧計画を作成し、それぞれに対してテスト フェールオーバーを実行する。
アプリとその依存関係は頻繁に変わるため、 復旧計画が最新であることを確認するためには、四半期ごとに各アプリに対してテスト フェールオーバーを実行します。
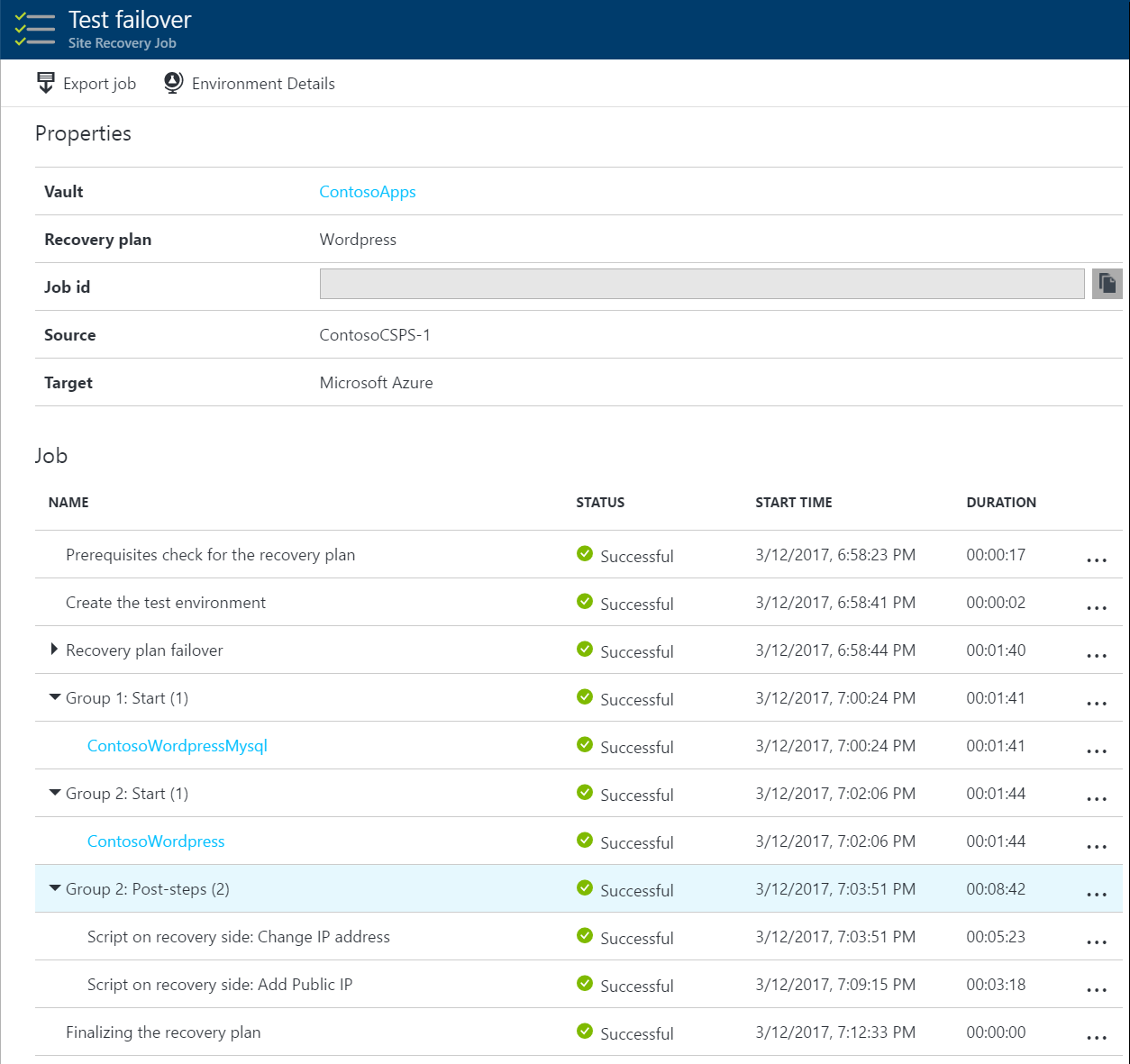
復旧プランのビデオを見る
2 層の WordPress アプリの復旧計画のオンクリック フェールオーバーについての、簡単なサンプル ビデオをご覧ください。