セマンティック ランカーを構成して検索結果でキャプションを返す
セマンティック ランク付けは、最初の結果セットを反復処理し、意味的に最も関連性の高い結果をスタックの最上位に昇格させる L2 ランク付け手法を適用します。 また、最も関連性の高い用語と語句を強調表示したセマンティック キャプションと、セマンティック回答を取得することもできます。
この記事では、セマンティック再ランク付けの検索インデックスを構成する方法について説明します。
Note
プレビューまたは以前の API バージョンを呼び出す既存のコードがある場合は、「セマンティック ランク付けコードの移行」で、コードの変更に関するヘルプを参照してください。
前提条件
Basic レベル以上の検索サービスは、リージョンの可用性に応じて異なります。
検索サービスで有効になっているセマンティック ランカー。
リッチ テキスト コンテンツを含む既存の検索インデックス。 セマンティック ランク付けは、文字列 (ベクトル以外) フィールドに適用され、情報または説明であるコンテンツに最適です。
クライアントを選択する
セマンティック構成を追加するために、次のいずれかのツールおよびソフトウェア開発キット (SDK) を使用して、新規または既存のインデックスのセマンティック構成を指定できます。
- インデックス デザイナーを使用してセマンティック構成を追加する Azure portal。
- REST クライアントを備えた Visual Studio Code と、Create or Update Index (REST) API。
- Azure SDK for .NET
- Azure SDK for Python
- Azure SDK for Java
- Azure SDK for JavaScript
セマンティック構成を追加する
"セマンティック構成" は、セマンティック ランク付けのフィールド入力を設定する、インデックス内のセクションです。 再構築することなく、セマンティック構成をいつでも追加または更新できます。 複数の構成を作成すると、既定値を指定できます。 クエリ時に、クエリ要求のセマンティック構成を指定するか、空白のままにして既定値を使用します。
セマンティック構成には、名前と次のプロパティがあります。
| プロパティ | 特性 |
|---|---|
| [タイトル] フィールド | 短い文字列 (理想的には 25 語以下)。 このフィールドは、ドキュメントのタイトル、製品の名前、または一意の ID である場合があります。 適切なフィールドがない場合は、空白のままにします。 |
| コンテンツ フィールド | 自然言語形式のテキストのより長いチャンク。機械学習モデルで最大トークン入力制限が適用されます。 一般的な例としては、ドキュメントの本文、製品の説明、またはその他の自由形式のテキストがあります。 |
| キーワード フィールド | ドキュメントのタグなどのキーワードのリスト、または項目のカテゴリなどの記述用語。 |
指定できるタイトル フィールドは 1 つだけですが、コンテンツおよびキーワード フィールドはいくつあっても構いません。 コンテンツおよびキーワード フィールドについては、優先順位の低いフィールドが切り捨てられる可能性があるため、優先順位の順に一覧表示します。
すべてのセマンティック構成プロパティで、割り当てるフィールドは次のようにする必要があります。
searchableおよびretrievableとして属性付けるEdm.String、Collection(Edm.String)型の文字列、Edm.ComplexTypeの文字列サブフィールド
Azure portal にサインインし、セマンティック ランク付けが有効になっている検索サービスに移動します。
左側のナビゲーション ウィンドウの [インデックス] からインデックスを選択します。
[セマンティック構成] を選択し、次に [セマンティック構成の追加] を選択します。

[新しいセマンティック構成] ページで、セマンティック構成名を入力し、セマンティック構成で使用するフィールドを選択します。 検索可能および取得可能な文字列フィールドのみが対象です。 コンテンツ フィールドとキーワード フィールドを優先順位に従って一覧表示するようにしてください。
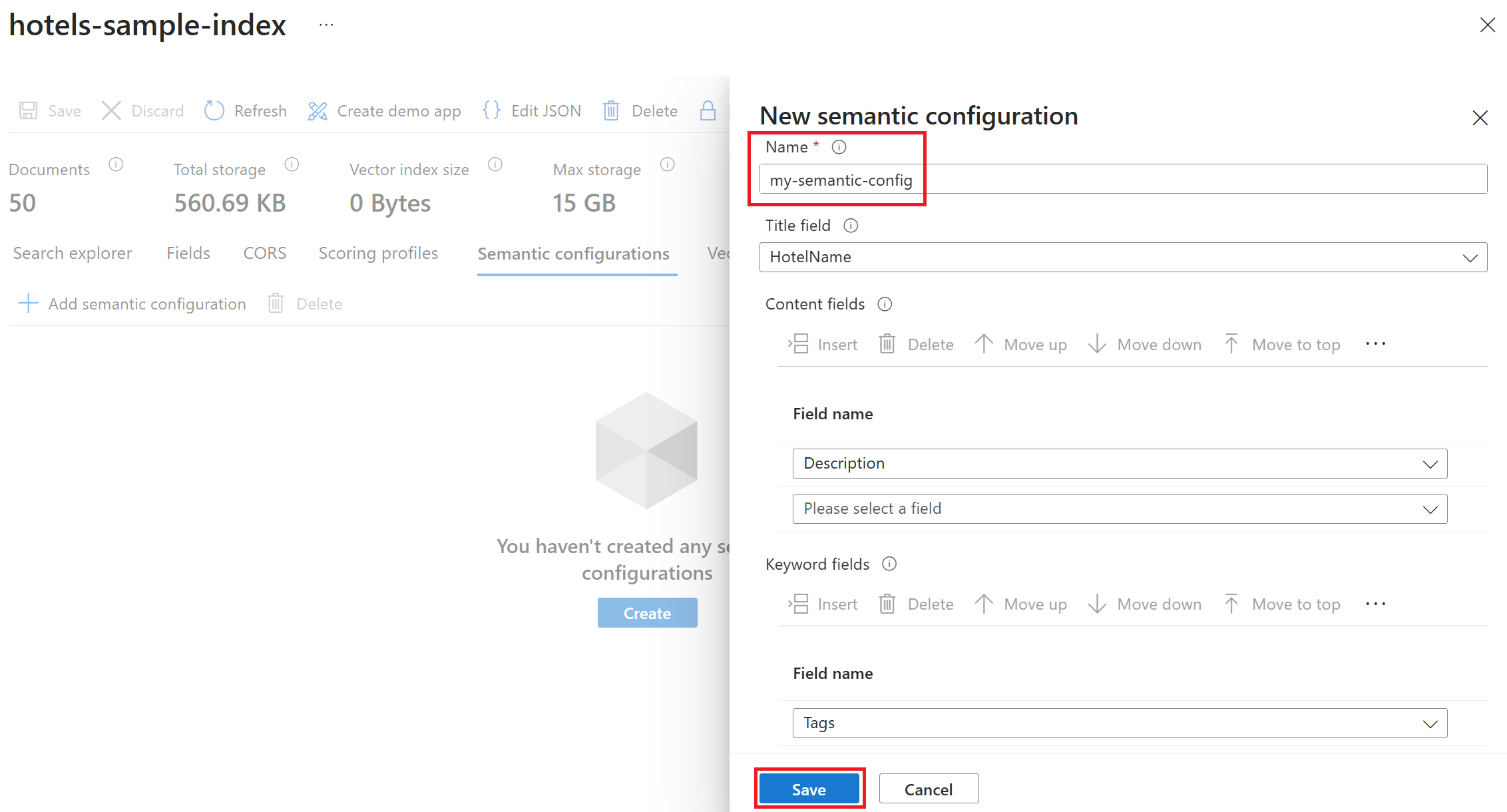
[保存] を選択して構成設定を保存します。
インデックス ページでもう一度 [保存] を選択して、セマンティック構成をインデックスに保存します。


次のステップ
セマンティック クエリを実行して、セマンティック構成をテストします。