インデクサー、スキル、ドキュメントを実行またはリセットする
Azure AI Search では、インデクサーを実行する方法がいくつかあります。
- インデクサーの作成時にすぐに実行は、"無効" モードで作成されていないと仮定しています。
- スケジュールに基づいて実行する: これによって、定期的に実行を呼び出します。
- "リセット" あり、またはなしでオンデマンドで実行する。
この記事では、リセットの有無に関係なく、オンデマンドでインデクサーを実行する方法について説明します。 また、インデクサーの実行、期間、コンカレンシーについても説明します。
インデクサーが Azure リソースに接続する方法
インデクサーは、他の Azure リソースへの公開の送信呼び出しを行う数少ないサブシステムの 1 つです。 Azure ロールに関しては、インデクサーには個別の ID がありません。検索エンジンから別の Azure リソースへの接続は、検索サービスのシステムまたはユーザー割り当てマネージド ID を使用して行われます。 インデクサーが仮想ネットワーク上の Azure リソースに接続する場合は、その接続用に共有プライベート リンクを作成する必要があります。 セキュリティで保護された接続の詳細については、Azure AI Search のセキュリティに関するページを参照してください。
インデクサーの実行
検索サービスは、検索ユニットごとに 1 つのインデクサー ジョブを実行します。 すべての検索サービスは 1 つの検索単位で始まりますが、新しいパーティションまたはレプリカごとにサービスの検索単位が増加します。 検索ユニット数は、Azure portal の [概要] ページの [要点] セクションで確認できます。 同時処理が必要な場合は、検索ユニットに十分なレプリカが含まれていることをご確認ください。 インデクサーはバックグラウンドで実行されないため、サービスに負荷がかかっている場合は、通常よりも多くのクエリ調整を検出する可能性があります。
次のスクリーンショットは、一度に実行できるインデクサーの数を決定する検索単位の数を示しています。
![検索ユニットを示す、概要ページの [Essentials] セクションのスクリーンショット。](media/search-howto-run-reset-indexers/search-units.png)
インデクサーの実行が開始されると、一時停止または停止することはできません。 インデクサーの実行は、読み込むまたは更新するドキュメントがなくなった場合、あるいは実行時間の上限に達すると停止します。
十分な容量を想定して一度に複数のインデクサーを実行できますが、各インデクサー自体は単一インスタンスです。 インデクサーが既に実行されているときに新しいインスタンスを開始すると、エラー "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."が発生します。
インデクサー実行環境
インデクサー ジョブは、マネージド実行環境で実行されます。 現在、次の 2 つの環境があります。
プライベート実行環境は、検索サービスに固有の検索クラスターで実行されます。 検索サービスが Standard2 以上の場合は、常にプライベート実行環境でインデクサーを実行するようにインデクサー定義で
executionEnvironmentパラメーターを設定できます。マルチテナント環境は、追加料金なしで Microsoft によって管理およびセキュリティ保護されるコンテンツ プロセッサを備えています。 この環境は、大量のコンピューティング処理を要する処理の負荷を軽減して、サービス固有のリソースをルーチン処理に残しておくために使います。 可能な限り、ほとんどのスキルセットはマルチテナント環境で実行されます。 これが既定です。
"計算負荷の高い処理" は、コンテンツ プロセッサで実行されているスキルセット、大量のドキュメントや大きなサイズのドキュメントを処理するインデクサー ジョブを指します。 マルチテナント コンテンツ プロセッサにおける非スキルセット処理は、ヒューリスティックおよびシステム情報によって決定され、顧客の管理下にはありません。 S2 サービス以上では、
executionEnvironmentパラメーターを使用して、インデクサーとスキルセットの処理を検索クラスターのみに固定できます。Note
IP ファイアウォールはマルチテナント環境をブロックするため、ファイアウォールがある場合は、マルチテナント処理を許可するルールを作成してください。
インデクサーの制限は、環境ごとに異なります。
| ワークロード | 最長期間 | 最大ジョブ数 | 実行環境 |
|---|---|---|---|
| プライベート実行 | 24 時間 | 検索ユニットあたり 1 つのインデクサー ジョブ 1。 | インデックス作成は、バックグラウンドで実行されません。 代わりに、検索サービスによって、すべてのインデックス作成ジョブと、進行中のクエリおよびオブジェクト管理アクション (インデックスの作成や更新など) とのバランスが調整されます。 インデクサーを実行する際、インデックスの作成量が多い場合、多少のクエリ待機時間が発生することを見込んでおく必要があります。 |
| マルチテナント | 2 時間 2 | 不確定 3 | コンテンツ処理クラスターはマルチテナントであるため、需要に合わせてコンテンツ プロセッサが追加されます。 オンデマンドまたはスケジュールされた実行で遅延が発生した場合は、システムがプロセッサを追加しているか、プロセッサが使用可能になるのを待機していることが原因である可能性があります。 |
1 検索ユニットでは、パーティションとレプリカを柔軟に組み合わせることができますが、インデクサー ジョブはどちらにも関連付けられません。 つまり、検索ユニットのデプロイ方法に関係なく、12 個のユニットがある場合には、プライベート実行で同時に 12 個のインデクサー ジョブを実行できます。
2 すべてのデータを処理するために 2 時間以上必要な場合は、変更の検出を有効にし、5 分間隔で実行されるようにインデクサーをスケジュールし、タイムアウトが原因でインデックス作成が停止した場合にすばやく再開できるようにします。 その他の戦略については、大規模なデータ セットのインデックス作成に関するページを参照してください。
3 "不確定" は、ジョブの数によって制限が定量化されないことを意味します。 スキルセット処理などの一部のワークロードは並列で実行できるため、1 つのインデクサーのみが関わっている場合でも多くのジョブが発生する可能性があります。 環境で制約が課されない場合でも、検索サービスのインデクサーの制限は適用されます。
リセットなしで実行
インデクサーの実行操作では、検索インデックスを、基になるデータ ソース内の変更と同期させるために必要なものだけが検出され処理されます。 増分インデックスは、内部の高基準値を見つけて、最後に更新された検索ドキュメントを見つけることから始まります。これは、データソース内の新規および更新されたドキュメントに対するインデクサー実行の開始点になります。
変更の検出は、データ ソースの新しい内容または更新された内容を判別するために不可欠です。 インデクサーは、基になるデータ ソースの変更の検出機能を使用して、データ ソースの新しい内容または更新された内容を判別します。
Azure Storage には、LastModified プロパティを利用する組み込みの変更の検出機能があります。
Azure SQL や Azure Cosmos DB などの他のデータ ソースは、インデクサーで新しいおよび更新された行を読み取る前に変更を検出するように構成する必要があります。
基になる内容が変更されていない場合、実行操作は無効になります。 この場合、インデクサーの実行履歴では、0\0 件のドキュメントが処理されたことが示されます。
完全に再処理するには、次のセクションで説明されているように、インデクサーをリセットする必要があります。
インデクサーのリセット
最初の実行後、インデクサーは、内部の "高基準値" を使用してどの検索ドキュメントがインデックス付けされたかを追跡します。 このマーカーは公開されませんが、内部でインデクサーは最後に停止した場所を認識します。
インデックスの全体または一部を再構築する必要がある場合は、リセットすることでインデクサーの高基準値をクリアできます。 リセット API は、オブジェクト階層でレベルを下げて利用できます。
- インデクサーのリセットによって、高基準値がクリアされ、すべてのドキュメントの完全な再インデックス化が実行される
- ドキュメントのリセット (プレビュー) によって、特定のドキュメントまたはドキュメントの一覧が再インデックス化される
- スキルのリセット (プレビュー) によって、特定のスキルのスキル処理が呼び出される
リセットした後、続いて実行コマンドを発行し、新規および既存のドキュメントを再処理します。 データ ソース内に対応するドキュメントがない孤立した検索ドキュメントは、リセットと実行を使用して削除できません。 ドキュメントを削除する必要がある場合は、Documents の Index に関する記事を参照してください。
インデクサーをリセットおよび実行する方法
リセットによって、高基準値はクリアされます。 検索インデックス内のすべてのドキュメントには、インライン更新や既存のコンテンツへのマージを行わずに完全に上書きするためのフラグが設定されます。 スキルセットおよびエンリッチメント キャッシュを含むインデクサーの場合、インデックスをリセットすると、スキルセットも暗黙的にリセットされます。
実際の作業は、リセットに続いて実行コマンドを発行したときに発生します。
- 基になるソースが見つかった新しいドキュメントはすべて、検索インデックスに追加されます。
- データ ソースと検索インデックスの両方に存在するドキュメントはすべて、検索インデックス内で上書きされます。
- スキルセットから作成され、エンリッチされたコンテンツは再構築されます。 エンリッチメント キャッシュは、有効になっている場合、更新されます。
前に述べたように、リセットはパッシブ操作です。つまり、インデックスを再構築するには、続いて実行要求を発行する必要があります。
リセットと実行の操作は、検索インデックスまたはナレッジ ストア、特定のドキュメントまたはプロジェクション、およびリセットに明示的または暗黙的にスキルが含まれている場合はキャッシュされたエンリッチメントに適用されます。
リセットは、作成操作と更新操作にも適用されます。 これによって、検索インデックス内の孤立したドキュメントの削除またはクリーンアップはトリガーされません。 ドキュメントの削除の詳細については、「Documents - Index」を参照してください。
いったんインデクサーをリセットすると、その操作は元に戻せません。
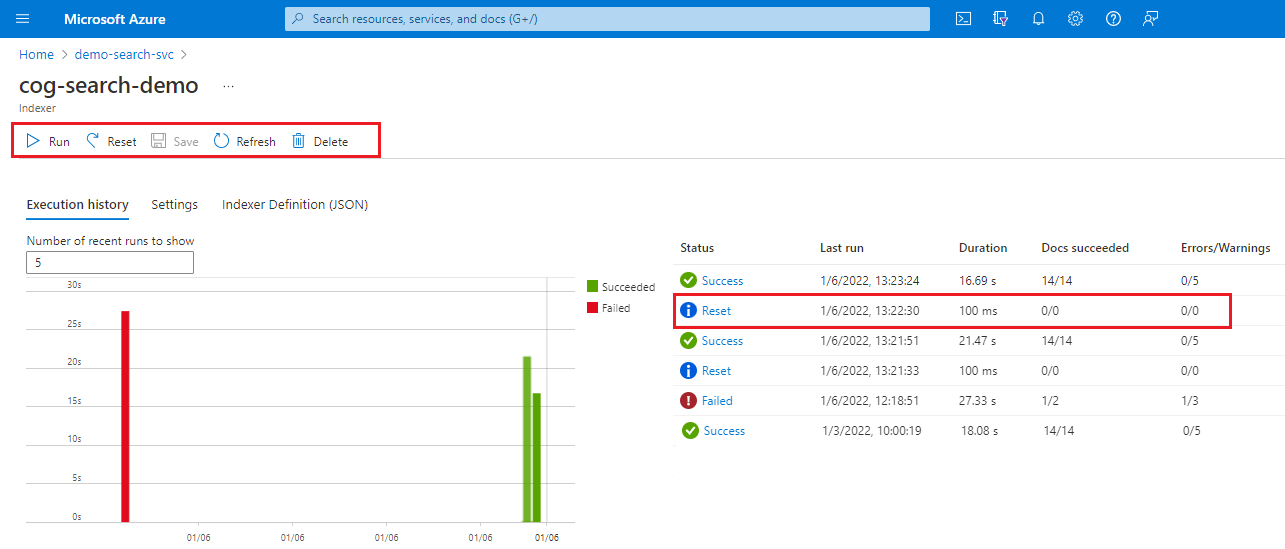
Azure portal にサインインし、検索サービス ページを開きます。
[概要] ページで、[インデクサー] タブを選択します。
インデクサーを選択します。
[リセット] コマンドを選択し、[はい] を選択して、操作を確定します。
ページを更新して状態を表示します。 項目を選択すると、その詳細が表示されます。
[実行] を選択してインデクサー処理を開始するか、スケジュールされた次の実行を待ちます。
スキルをリセットする方法 (プレビュー)
スキルセットを含むインデクサーの場合、個々のスキルをリセットして、そのスキルと、その出力に依存するダウンストリーム スキルのみを強制的に処理することができます。 エンリッチメント キャッシュが有効になっている場合、それも更新されます。
スキルのリセットは、現在 REST のみであり、2020-06-30-preview 以降で使用できます。 最新のプレビュー API をお勧めします。
POST /skillsets/[skillset name]/resetskills?api-version=2024-05-01-preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
上記の例に示されているように、個々のスキルを指定することもできます。しかし、それらのスキルのいずれかで、一覧にないスキル (#2 から #4) からの出力が必要な場合は、キャッシュが必要な情報を提供できない限り、一覧にないスキルが実行されます。 これが可能であるには、#2 から #4 のスキルのキャッシュされたエンリッチメントが #1 に依存していない必要があります (リセットのためにリストされています)。
スキルが指定されていない場合は、スキルセット全体が実行されます。また、キャッシングが有効になっている場合は、キャッシュも更新されます。
実際の処理を呼び出すには、続いてインデクサーの実行を発行することを忘れないでください。
ドキュメントをリセットする方法 (プレビュー)
インデクサー - ドキュメントのリセットは、ドキュメント キーの一覧を受け取って、特定のドキュメントを更新できるようにします。 リセット パラメーターを指定すると、基になるデータの他の変更には関係なく、リセット パラメーターによってのみ処理対象が決定されます。 たとえば、インデクサーの最後の実行後に 20 個の BLOB が追加または更新されたが、1 つのドキュメントのみをリセットした場合、そのドキュメントだけが処理されます。
ドキュメントごとに、その検索ドキュメント内のすべてのフィールドがデータ ソースの値で更新されます。 更新するフィールドは選択できません。
ドキュメントがスキルセットによってエンリッチされ、キャッシュされたデータがある場合は、指定されたドキュメントに対してのみスキルセットが呼び出され、再処理されたドキュメントに対してキャッシュが更新されます。
この API を初めてテストするときは、次の API が、動作の検証とテストに役立ちます。 プレビュー API バージョン 2020-06-30-preview 以降を使用できます。 最新のプレビュー API をお勧めします。
プレビュー API バージョンのインデクサー - 状態の取得を呼び出して、リセットの状態と実行の状態を確認します。 状態応答の最後でリセット要求に関する情報を確認できます。
プレビュー API バージョンのインデクサー - ドキュメントのリセットを呼び出して、処理するドキュメントを指定します。
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2024-05-01-preview { "documentKeys" : [ "1001", "4452" ] }要求で提供されるドキュメント キーは検索インデックスの値であり、データ ソース内の対応するフィールドとは異なる場合があります。 キーの値がわからない場合は、クエリを送信して値を返します。
selectを使用すると、ドキュメント キー フィールドのみを返すことができます。複数の検索ドキュメントに解析される BLOB の場合 (たとえば、parsingMode が jsonLines または jsonArrays、あるいは delimitedText に設定されている場合)、ドキュメント キーがインデクサーによって生成され、ユーザーにはわからないことがあります。 このシナリオでは、ドキュメント キーが正しい値を返すクエリです。
インデクサーの実行 (任意の API バージョン) を呼び出して、指定したドキュメントを処理します。 これらの特定のドキュメントのみがインデックス化されます。
2 回目の インデクサーの実行を呼び出して、最後の高基準値から処理します。
ドキュメントの検索を呼び出して、更新された値を確認します。また、値がわからない場合は、ドキュメント キーを返します。 応答に表示するフィールドを制限する場合は、
"select": "<field names>"を使用します。
ドキュメント キー リストの上書き
異なるキーを使用して、ドキュメントのリセット API を複数回呼び出すと、ドキュメント キーのリセットの一覧に新しいキーが追加されます。
overwrite パラメーターを true に設定して API を呼び出すと、現在の一覧が新しい一覧で上書きされます。
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
リセット状態 "currentState" を確認する
リセット状態を確認し、処理のためにキューに入れられたドキュメント キーを確認するには、次の手順を行います。
プレビュー API のインデクサー - 状態の取得を呼び出します。
プレビュー API は、
currentStateセクションを返します。これは、応答の最後にあります。"currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }"モード" を確認します。
スキルのリセットの場合は "モード" を
indexingAllDocsに設定する必要があります (AI エンリッチメントで設定されるフィールドについてはすべてのドキュメントが影響を受ける可能性があるため)。ドキュメントのリセットの場合は、"モード" を
indexingResetDocsに設定する必要があります。 ドキュメントのリセット呼び出しで指定されたすべてのドキュメント キーが処理されるまで (この操作の進行中、他のインデクサー ジョブは実行されません)、インデクサーはこの状態を保持します。 ドキュメント キー リスト内のすべてのドキュメントを見つけるには、各ドキュメントを解読してキーを特定し、一致させる必要があります。データ セットが大きい場合は、この処理に時間がかかることがあります。 BLOB コンテナーに数百の BLOB が含まれていて、リセットするドキュメントが最後にある場合、インデクサーは、他のすべてのものがチェックされるまで、一致する BLOB を検索しません。ドキュメントが再処理された後、インデクサーの状態の取得を再度実行します。 インデクサーは
indexingAllDocsモードに戻り、次の実行で、新しいまたは更新されたドキュメントを処理します。
次のステップ
リセット API は、次回のインデクサー実行のスコープを通知するのに使用されます。 実際の処理では、オンデマンドのインデクサー実行を呼び出すか、スケジュールされたジョブで作業を完了できるようにする必要があります。 実行が完了すると、スケジュールされた処理かオンデマンドの処理かにかかわらず、インデクサーは通常の処理に戻ります。
インデクサー ジョブをリセットして再実行した後、検索サービスで状態を監視したり、リソース ログを使用して詳細情報を取得したりできます。