Red Hat Enterprise Linux での SAP HANA スケールアウト システムの高可用性
この記事では、スケールアウト構成で高可用性 SAP HANA システムをデプロイする方法について説明します。 具体的には、この構成では Azure Red Hat Enterprise Linux 仮想マシン (VM) 上で HANA システム レプリケーション (HSR) と Pacemaker を使用します。 提示されたアーキテクチャの共有ファイル システムは NFS でマウントされており、Azure NetApp Files または Azure Files の NFS 共有によって提供されます。
構成例やインストール コマンドでは、HANA インスタンスは 03、HANA システム ID は HN1 です。
前提条件
この記事のトピックに進む前に、さまざまな SAP Note やリソースをご覧になると参考になる場合があります。
- SAP Note 1928533 には、次のものが含まれます。
- SAP ソフトウェアのデプロイでサポートされる Azure VM サイズの一覧。
- Azure VM サイズの容量に関する重要な情報。
- サポートされる SAP ソフトウェア、およびオペレーティング システムとデータベースの組み合わせ。
- Microsoft Azure 上の Windows と Linux に必要な SAP カーネル バージョン。
- SAP Note 2015553: SAP でサポートされる Azure 上の SAP ソフトウェア デプロイの前提条件が記載されています。
- SAP Note [2002167]: RHEL で推奨されるオペレーティング システム設定が記載されています。
- SAP Note 2009879: RHEL の SAP HANA ガイドラインが記載されています。
- SAP Note 3108302 には、SAP HANA Guidelines for Red Hat Enterprise Linux 9.x があります。
- SAP Note 2178632: Azure 上の SAP についてレポートされるすべての監視メトリックに関する詳細情報が記載されています。
- SAP Note 2191498: Azure 上の Linux に必要な SAP ホスト エージェントのバージョンが記載されています。
- SAP Note 2243692: Azure 上の Linux で動作する SAP のライセンスに関する情報が記載されています。
- SAP Note 1999351: Azure Enhanced Monitoring Extension for SAP に関するその他のトラブルシューティング情報が記載されています。
- SAP Note 1900823: SAP HANA のストレージ要件に関する情報が記載されています。
- SAP Community Wiki: Linux に必要なすべての SAP Note が掲載されています。
- Linux 上の SAP のための Azure Virtual Machines の計画と実装。
- Linux 上の SAP のための Azure Virtual Machines のデプロイ。
- Linux 上の SAP のための Azure Virtual Machines DBMS のデプロイ。
- SAP HANA のネットワーク要件。
- 一般的な RHEL ドキュメント:
- Azure 固有の RHEL ドキュメント:
- Azure NetApp Files のドキュメント。
- SAP HANA 用 Azure NetApp Files 上の NFS v4.1 ボリューム。
- Azure Files のドキュメント
概要
HANA スケールアウトのインストールで HANA の高可用性を実現するには、HANA システム レプリケーションを構成し、Pacemaker クラスターで自動フェールオーバーを許可することによりソリューションを保護できます。 アクティブ ノードで障害が発生すると、クラスターは HANA リソースを他のサイトにフェールオーバーします。
次の図では、各サイトに 3 つの HANA ノードと、"スプリットブレイン" シナリオを防ぐためのマジョリティ メーカー ノードがあります。 より多くの VM を HANA DB ノードとして含めるように、手順を調整できます。
提示されたアーキテクチャの HANA 共有ファイル システム /hana/shared は、Azure NetApp Files または Azure Files の NFS 共有によって提供できます。 HANA 共有ファイル システムは、同じ HANA システム レプリケーション サイト内の各 HANA ノードにマウントされた NFS です。 ファイル システム /hana/data と /hana/log はローカル ファイル システムであり、HANA DB ノード間で共有されません。 SAP HANA は非共有モードでインストールされます。
推奨される SAP HANA のストレージ構成については、「SAP HANA Azure VM のストレージ構成」を参照してください。
重要
パフォーマンスが重要な運用システムの場合、すべての HANA ファイル システムを Azure NetApp Files にデプロイする場合は、SAP HANA 用の Azure NetApp Files アプリケーション ボリューム グループを使用することを評価し、検討することをお勧めします。

上の図は、SAP HANA ネットワークの推奨事項に従って、1 つの Azure 仮想ネットワーク内に 3 つのサブネットがあることを示しています。
- クライアント通信用:
client10.23.0.0/24 - HANA 内部のノード間通信用:
inter10.23.1.128/26 - HANA システム レプリケーション用:
hsr10.23.1.192/26
/hana/data と /hana/log はローカル ディスク上にデプロイされるため、ストレージとの通信用に別のサブネットと仮想ネットワーク カードをデプロイする必要はありません。
Azure NetApp Files を使用している場合、 /hana/shared の NFS ボリュームは別のサブネットにデプロイされ、Azure NetApp Filesに委任されます: anf 10.23.1.0/26。
インフラストラクチャをセットアップする
これ以降の手順は、リソース グループおよび 3 つの Azure ネットワーク サブネット (client、inter、hsr) を持つ Azure 仮想ネットワークが既に作成されていることを前提としています。
Azure portal を使用して Linux 仮想マシンをデプロイする
Azure VM を展開します。 この構成では、7 つの仮想マシンをデプロイします。
- HANA レプリケーション サイト 1 の HANA DB ノードとして機能する 3 台の仮想マシン: hana-s1-db1、hana-s1-db2、hana-s1-db3。
- HANA レプリケーション サイト 2 の HANA DB ノードとして機能する 3 台の仮想マシン: hana-s2-db1、hana-s2-db2、hana-s2-db3。
- マジョリティ メーカーとして機能する小規模な仮想マシン: hana-s-mm。
SAP DB HANA ノードとしてデプロイされる VM は、SAP HANA ハードウェア ディレクトリで公開されているように、SAP for HANA によって認定されている必要があります。 HANA DB ノードをデプロイするときは、必ず高速ネットワークを選択します。
マジョリティ メーカー ノードにデプロイする VM では SAP HANA リソースが実行されないため、小規模の VM をデプロイできます。 マジョリティ メーカー VM は、スプリットブレイン シナリオで奇数個のクラスター ノードを実現するためのクラスター構成として使用されます。 今回の例では、マジョリティ メーカー VM には
clientサブネットに 1 つの仮想ネットワーク インターフェイスが必要となるだけです。/hana/dataおよび/hana/log用のローカル マネージド ディスクを展開します。/hana/dataと/hana/logに推奨される最小ストレージ構成については、「SAP HANA Azure VM のストレージ構成」を参照してください。各 VM のプライマリ ネットワーク インターフェイスを
client仮想ネットワーク サブネット内に展開します。 Azure portal 経由で VM が展開されると、ネットワーク インターフェイス名が自動的に生成されます。 この記事では、自動的に生成されたプライマリ ネットワーク インターフェイスを、hana-s1-db1-client、hana-s1-db2-client、hana-s1-db3-client などのように呼びます。 これらのネットワーク インターフェイスは、clientAzure 仮想ネットワーク サブネットに接続されます。重要
選択したオペレーティング システムが、使用している特定の VM の種類の SAP HANA に対して SAP 認定されていることを確認してください。 SAP HANA 認定 VM の種類と、その種類に対応するオペレーティング システム リリースの一覧については、SAP HANA 認定 IaaS プラットフォームに関するページを参照してください。 一覧表示されている VM の種類の詳細を表示すると、その種類に対して SAP HANA でサポートされているオペレーティング システム リリースの完全な一覧が表示されます。
HANA DB 仮想マシンごとに 1 つずつ、6 つのネットワーク インターフェイスを
inter仮想ネットワーク サブネットに作成します (この例では、hana-s1-db1-inter、hana-s1-db2-inter、hana-s1-db3-inter、hana-s2-db1-inter、hana-s2-db2-inter、hana-s2-db3-inter とします)。HANA DB 仮想マシンごとに 1 つずつ、6 つのネットワーク インターフェイスを
hsr仮想ネットワーク サブネットに作成します (この例では、hana-s1-db1-hsr、hana-s1-db2-hsr、hana-s1-db3-hsr、hana-s2-db1-hsr、hana-s2-db2-hsr、hana-s2-db3-hsr とします)。新しく作成した仮想ネットワーク インターフェイスを、対応する仮想マシンに接続します。
- Azure portal で仮想マシンに移動します。
- 左側のペインで、 [仮想マシン] を選択します。 仮想マシン名でフィルター処理し (たとえば hana-s1-db1)、その仮想マシンを選択します。
- [概要] ペインで、 [停止] を選択して仮想マシンの割り当てを解除します。
-
[ネットワーク] を選択してから、ネットワーク インターフェイスを接続します。
[ネットワーク インターフェイスの接続] ドロップダウン リストで、
interおよびhsrサブネットに対して既に作成したネットワーク インターフェイスを選択します。 - [保存] を選択します。
- 残りの仮想マシン (この例では hana-s1-db2、hana-s1-db3、hana-s2-db1、hana-s2-db2、hana-s2-db3) に対して、手順 b から e を繰り返します。
- 今のところ、仮想マシンは停止状態のままにしておきます。
以下のようにして、
interおよびhsrサブネット用の追加ネットワーク インターフェイスに対して高速ネットワークを有効にします。Azure portal で Azure Cloud Shell を開きます。
次のコマンドを実行して、
interおよびhsrサブネットに接続された、追加のネットワーク インターフェイスに対して高速ネットワークを有効にします。az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-hsr --accelerated-networking true
HANA DB 仮想マシンを起動します。
Azure Load Balancer の構成
VM 構成中に、ネットワーク セクションでロード バランサーを作成するか既存のものを選択する選択肢もあります。 HANA データベースの高可用性セットアップ用に Standard Load Balancer をセットアップするには、次の手順のようにします。
Note
- HANA スケールアウトの場合は、バックエンド プールに仮想マシンを追加する際に、
clientサブネット用の NIC を選択します。 - Azure CLI と PowerShell のコマンドの完全なセットを実行すると、プライマリ NIC を備えた VM がバックエンド プールに追加されます。
- Azure Portal
- Azure CLI
- PowerShell
Azure portal を使って高可用性 SAP システム用の標準ロード バランサーを設定するには、「ロード バランサーの作成」の手順に従います。 ロード バランサーのセットアップ時には、以下の点を考慮してください。
- フロントエンド IP 構成: フロントエンド IP を作成します。 お使いのデータベース仮想マシンと同じ仮想ネットワークとサブネットを選択します。
- バックエンド プール: バックエンド プールを作成し、データベース VM を追加します。
-
インバウンド規則: 負荷分散規則を作成します。 両方の負荷分散規則で同じ手順に従います。
- フロントエンド IP アドレス: フロントエンド IP を選択します。
- バックエンド プール: バックエンド プールを選択します。
- 高可用性ポート: このオプションを選択します。
- [プロトコル]: [TCP] を選択します。
-
正常性プローブ: 次の詳細を使って正常性プローブを作成します。
- [プロトコル]: [TCP] を選択します。
- ポート: 例: 625<インスタンス番号>。
- サイクル間隔: 「5」と入力します。
- プローブしきい値: 「2」と入力します。
- アイドル タイムアウト (分): 「30」と入力します。
- フローティング IP を有効にする: このオプションを選択します。
Note
正常性プローブ構成プロパティ numberOfProbes (ポータルでは [異常なしきい値] とも呼ばれます) は考慮されません。 成功または失敗した連続プローブの数を制御するには、プロパティ probeThreshold を 2 に設定します。 現在、このプロパティは Azure portal を使用して設定できないため、Azure CLI または PowerShell コマンドを使用してください。
Note
Standard Load Balancer を使用している場合は、次の制限に注意する必要があります。 パブリック IP アドレスのない VM を内部ロード バランサーのバックエンド プールに配置する場合、アウトバウンド インターネット接続はありません。 パブリック エンド ポイントへのルーティングを許可するには、追加の構成を行う必要があります。 詳細は、SAP の高可用性シナリオにおける Azure Standard Load Balancer を使用した仮想マシンのパブリック エンドポイント接続を参照してください。
重要
Azure Load Balancer の背後に配置された Azure VM では TCP タイムスタンプを有効にしないでください。 TCP タイムスタンプを有効にすると正常性プローブが失敗します。 パラメーター net.ipv4.tcp_timestamps を 0 に設定します。 詳細については、「Load Balancer の正常性プローブ」および SAP Note 2382421 を参照してください。
NFS の展開
/hana/shared に Azure ネイティブ NFS をデプロイするには、2 つのオプションがあります。 NFS ボリュームは、Azure NetApp Files または、Azure Files の NFS 共有にデプロイできます。 Azure ファイルは NFSv4.1 プロトコルをサポートし、Azure NetApp ファイル上の NFS は NFSv4.1 と NFSv3 の両方をサポートします。
次のセクションでは、NFS をデプロイする手順について説明します。1 つのオプションのみを選択する必要があります。
ヒント
/hana/shared を Azure Files の NFS 共有または Azure NetApp Files の NFS ボリュームのいずれかにデプロイすることを選択しました。
Azure NetApp Files インフラストラクチャを展開する
/hana/shared ファイル システムの Azure NetApp Files ボリュームをデプロイします。 HANA システム レプリケーション サイトごとに、個別の /hana/shared ボリュームが必要です。 詳細については、「Azure NetApp Files インフラストラクチャを設定する」を参照してください。
この例では、次の Azure NetApp Files ボリュームを使用します。
- ボリューム HN1-shared-s1 (nfs://10.23.1.7/HN1-shared-s1)
- ボリューム HN1-shared-s2 (nfs://10.23.1.7/HN1-shared-s2)
Azure Files インフラストラクチャに NFS をデプロイする
/hana/shared ファイル システム用に Azure Files NFS 共有をデプロイします。 HANA システム レプリケーション サイトごとに、個別の /hana/shared Azure Files NFS 共有が必要になります。 詳細については、NFS 共有の作成方法に関するページをご覧ください。
この例では、次の Azure Files NFS 共有が使用されています。
- share hn1-shared-s1 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1)
- share hn1-shared-s2 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2)
オペレーティング システムの構成と準備
次のセクションの手順には、次の省略形のいずれかを表すプレフィックスが付いています。
- [A] :すべてのノードに適用できます
- [AH]: すべての HANA DB ノードに適用できます
- [M]: マジョリティ メーカーノードに適用できます
- [AH1]: SITE 1 のすべての HANA DB ノードに適用できます
- [AH2]: SITE 2 のすべての HANA DB ノードに適用できます
- [1]: HANA DB ノード 1、SITE 1 のみに適用できます
- [2]: HANA DB ノード 1、SITE 2 のみに適用できます
次の手順を実行して、オペレーティング システムを構成して準備します。
[A] 仮想マシン上にホスト ファイルを維持します。 すべてのサブネットのエントリを含めます。 この例では、次のエントリが
/etc/hostsに追加されます。# Client subnet 10.23.0.11 hana-s1-db1 10.23.0.12 hana-s1-db1 10.23.0.13 hana-s1-db2 10.23.0.14 hana-s2-db1 10.23.0.15 hana-s2-db2 10.23.0.16 hana-s2-db3 10.23.0.17 hana-s-mm # Internode subnet 10.23.1.138 hana-s1-db1-inter 10.23.1.139 hana-s1-db2-inter 10.23.1.140 hana-s1-db3-inter 10.23.1.141 hana-s2-db1-inter 10.23.1.142 hana-s2-db2-inter 10.23.1.143 hana-s2-db3-inter # HSR subnet 10.23.1.202 hana-s1-db1-hsr 10.23.1.203 hana-s1-db2-hsr 10.23.1.204 hana-s1-db3-hsr 10.23.1.205 hana-s2-db1-hsr 10.23.1.206 hana-s2-db2-hsr 10.23.1.207 hana-s2-db3-hsr[A] Azure 用の Microsoft の構成設定を使用して、構成ファイル /etc/sysctl.d/ms-az.conf を作成します。
vi /etc/sysctl.d/ms-az.conf # Add the following entries in the configuration file net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10ヒント
SAP ホスト エージェントからポート範囲を管理できるように、
sysctl構成ファイルでは明示的にnet.ipv4.ip_local_port_rangeとnet.ipv4.ip_local_reserved_portsを設定しないでください。 詳細については、SAP Note 2382421 を参照してください。[A] NFS クライアント パッケージをインストールします。
yum install nfs-utils[AH] HANA 用の Red Hat の構成。
Red Hat カスタマー ポータル および次の SAP Note で説明されているように RHEL を構成します。
ファイル システムを準備する
以下のセクションでは、ファイル システムを準備する手順について説明します。 Azure Files 上 NFS 共有に /hana/shared' をデプロイするか、Azure NetApp Files で NFS ボリュームをデプロイすることを選択しました。
共有ファイル システムをマウントする (NFS Azure NetApp Files)
この例では、共有 HANA ファイル システムが Azure NetApp Files にデプロイされ、NFSv4.1 経由でマウントされています。 Azure NetApp Files で NFS を使用している場合にのみ、このセクションの手順に従います。
[AH] SAP Note 3024346 - Linux Kernel Settings for NetApp NFS に記載されているように、NFS を使用して NetApp システムで SAP HANA を実行する目的で OS を準備します。 NetApp 構成設定用の構成ファイル /etc/sysctl.d/91-NetApp-HANA.conf を作成します。
vi /etc/sysctl.d/91-NetApp-HANA.conf # Add the following entries in the configuration file net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[AH] SAP Note 3024346 - Linux Kernel Settings for NetApp NFS での推奨のとおりに sunrpc の設定を調整します。
vi /etc/modprobe.d/sunrpc.conf # Insert the following line options sunrpc tcp_max_slot_table_entries=128[AH] HANA データベース ボリュームのマウント ポイントを作成します。
mkdir -p /hana/shared[AH] NFS ドメイン設定を確認します。 ドメインが既定の Azure NetApp Files ドメイン (
defaultv4iddomain.com) として設定されていることを確認します。 マッピングがnobodyに設定されていることを確認します。
(この手順は、Azure NetAppFiles NFS v4.1 を使用する場合にのみ必要です。)重要
Azure NetApp Files の既定のドメイン構成 (
defaultv4iddomain.com) と一致するように、VM 上の/etc/idmapd.confに NFS ドメインを設定していることを確認します。 NFS クライアントと NFS サーバーのドメイン構成が一致しない場合、VM にマウントされている Azure NetApp ボリューム上のファイルのアクセス許可はnobodyと表示されます。sudo cat /etc/idmapd.conf # Example [General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobody[AH]
nfs4_disable_idmappingを確認します。 これはYに設定する必要があります。nfs4_disable_idmappingが配置されるディレクトリ構造を作成するには、mount コマンドを実行します。 アクセスがカーネルまたはドライバー用に予約されるため、 /sys/modules の下に手動でディレクトリを作成することはできなくなります。
この手順は、Azure NetAppFiles NFSv4.1 を使用する場合にのみ必要です。# Check nfs4_disable_idmapping cat /sys/module/nfs/parameters/nfs4_disable_idmapping # If you need to set nfs4_disable_idmapping to Y mkdir /mnt/tmp mount 10.9.0.4:/HN1-shared /mnt/tmp umount /mnt/tmp echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping # Make the configuration permanent echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confnfs4_disable_idmappingパラメーターを変更する方法の詳細については、Red Hat カスタマー ポータルを参照してください。[AH1] SITE1 HANA DB VM に共有 Azure NetApp Files ボリュームをマウントします。
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s1 /hana/shared[AH2] SITE2 HANA DB VM に共有 Azure NetApp Files ボリュームをマウントします。
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s2 /hana/shared[AH] 対応する
/hana/shared/ファイル システムが、NFS プロトコル バージョン NFSv4 を使用しているすべての HANA DB VM にマウントされていることを確認します。sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7
共有ファイル システムをマウントする (Azure Files NFS)
この例では、共有 HANA ファイル システムが Azure Files の NFS にデプロイされます。 Azure Files で NFS を使用している場合にのみ、このセクションの手順に従います。
[AH] HANA データベース ボリュームのマウント ポイントを作成します。
mkdir -p /hana/shared[AH1] SITE1 HANA DB VM に共有 Azure NetApp Files ボリュームをマウントします。
sudo vi /etc/fstab # Add the following entry sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount all volumes sudo mount -a[AH2] SITE2 HANA DB VM に共有 Azure NetApp Files ボリュームをマウントします。
sudo vi /etc/fstab # Add the following entries sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount the volume sudo mount -a[AH] 対応する
/hana/shared/ファイル システムが、NFS プロトコル バージョン NFSv4.1 を使用しているすべての HANA DB VM にマウントされていることを確認します。sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
データおよびログのローカル ファイル システムを準備する
提示されている構成では、ファイル システム /hana/data と /hana/log をマネージド ディスクにデプロイし、これらのファイル システムを各 HANA DB VM にローカルで接続します。 次の手順を実行して、各 HANA DB 仮想マシンで、ローカルのデータとログのボリュームを作成します。
論理ボリューム マネージャー (LVM) を使用してディスク レイアウトを設定します。 次の例は、各 HANA 仮想マシンに 3 つのデータ ディスクが接続されていて、これらのディスクを使用して 2 つのボリュームを作成することを前提としています。
[AH] すべての使用できるディスクの一覧を出力します。
ls /dev/disk/azure/scsi1/lun*出力例:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2[AH] 使用するすべてのディスクの物理ボリュームを作成します。
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2[AH] データ ファイル用のボリューム グループを作成します。 ログ ファイル用に 1 つ、SAP HANA の共有ディレクトリ用に 1 つのボリューム グループを作成します。
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2[AH] 論理ボリュームを作成します。
-iスイッチを指定せずにlvcreateを使用すると、"線形" のボリュームが作成されます。 I/O パフォーマンスが向上するように、"ストライプ" ボリュームを作成することお勧めします。 ストライプ サイズは、SAP HANA VM のストレージ構成に関するページに記載されている値に合わせます。-i引数は、基になる物理ボリュームの数、-I引数はストライプ サイズにする必要があります。 この記事では、2 つの物理ボリュームを使用するので、-iスイッチ引数を2に設定します。 データ ボリュームのストライプ サイズは256 KiBです。 ログ ボリュームには物理ボリュームを 1 つ使用するので、ログ ボリューム コマンドに-iおよび-Iスイッチを明示的には使用する必要はありません。重要
データまたはログ ボリュームごとに複数の物理ボリュームを使用する場合は、
-iスイッチを使用して基になる物理ボリュームの数を設定します。 ストライプ ボリュームを作成するときにストライプ サイズを指定するには、-Iスイッチを使用します。 ストライプ サイズやディスク数など、推奨されるストレージ構成については、SAP HANA VM ストレージ構成に関する記事を参照してください。sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log[AH] マウント ディレクトリを作成し、すべての論理ボリュームの UUID をコピーします。
sudo mkdir -p /hana/data/HN1 sudo mkdir -p /hana/log/HN1 # Write down the ID of /dev/vg_hana_data_HN1/hana_data and /dev/vg_hana_log_HN1/hana_log sudo blkid[AH] 論理ボリュームの
fstabエントリを作成してマウントします。sudo vi /etc/fstab/etc/fstabファイルに次の行を挿入します。/dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_data_HN1-hana_data /hana/data/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_log_HN1-hana_log /hana/log/HN1 xfs defaults,nofail 0 2新しいボリュームをマウントします。
sudo mount -a
インストール
この例では、Azure VM で HSR を使用したスケールアウト構成で SAP HANA をデプロイするために、HANA 2.0 SP4 を使用します。
HANA のインストールの準備
[AH] HANA をインストールする前に、ルート パスワードを設定します。 インストールが完了した後で、ルート パスワードを無効にすることができます。
rootとしてpasswdコマンドを実行してパスワードを設定します。[1,2]
/hana/sharedのアクセス許可を変更します。chmod 775 /hana/shared[1] パスワードの入力を求められることなく、Secure Shell (SSH) 経由で hana-s1-db2 および hana-s1-db3 にサインインできることを確認します。 そうでない場合は、キーベースの認証の使用に関するページに記載されているように、
sshキーを交換します。ssh root@hana-s1-db2 ssh root@hana-s1-db3[2] パスワードの入力を求められることなく、SSH 経由で hana-s2-db2 および hana-s2-db3 にサインインできることを確認します。 そうでない場合は、キーベースの認証の使用に関するページに記載されているように、
sshキーを交換します。ssh root@hana-s2-db2 ssh root@hana-s2-db3[AH] HANA 2.0 SP4 に必要な追加のパッケージをインストールします。 詳細については、RHEL 7 向けの SAP Note 2593824 を参照してください。
# If using RHEL 7 yum install libgcc_s1 libstdc++6 compat-sap-c++-7 libatomic1 # If using RHEL 8 yum install libatomic libtool-ltdl.x86_64[A] HANA のインストールに干渉しないように、ファイアウォールを一時的に無効にします。 HANA のインストールが完了したら、再度有効にすることができます。
# Execute as root systemctl stop firewalld systemctl disable firewalld
各サイトの最初のノードへの HANA のインストール
[1] 「SAP HANA 2.0 のインストールと更新ガイド」の指示に従って、SAP HANA をインストールします。 次の手順では、SITE 1 の最初のノードへの SAP HANA のインストールを示します。
HANA のインストール ソフトウェア ディレクトリから、
hdblcmプログラムをrootとして開始します。internal_networkパラメーターを使用して、内部 HANA のノード間通信に使用されるサブネットのアドレス空間を渡します。./hdblcm --internal_network=10.23.1.128/26プロンプトで次の値を入力します。
- [Choose an action](アクションを選択する) : 「1」と入力します (インストールの場合)。
- [Additional components for installation](追加でインストールするコンポーネント) : 「2, 3」と入力します。
- [installation path](インストール パス): Enter キーを押します (既定値は /hana/shared)。
- [Local Host Name](ローカル ホスト名) : Enter キーを押して既定値をそのまま使用します。
- [Do you want to add hosts to the system?](システムにホストを追加しますか?) : 「n」と入力します。
- [SAP HANA System ID](SAP HANA システム ID) : 「HN1」と入力します。
- [Instance number](インスタンス番号) [00]: 「03」と入力します。
- [Local Host Worker Group](ローカル ホスト ワーカー グループ) [既定値]: Enter キーを押して既定値をそのまま使用します。
- [Select System Usage / Enter index [4]](システム用途の選択/インデックスを入力 [4]) : 「4」と入力します (カスタム)。
- [Location of Data Volumes](データ ボリュームの場所) [/hana/data/HN1]: Enter キーを押して既定値をそのまま使用します。
- [Location of Log Volumes](ログ ボリュームの場所) [/hana/log/HN1]: Enter キーを押して既定値をそのまま使用します。
- [Restrict maximum memory allocation?](メモリの最大割り当てを制限しますか?) [n]: 「n」と入力します。
- [Certificate Host Name For Host hana-s1-db1](ホスト hana-s1-db1 の証明書ホスト名) [hana-s1-db1]: Enter キーを押して既定値をそのまま使用します。
- [SAP Host Agent User (sapadm) Password](SAP ホスト エージェント ユーザー (sapadm) のパスワード) : パスワードを入力します。
- [Confirm SAP Host Agent User (sapadm) Password](SAP ホスト エージェント ユーザー (sapadm) のパスワードの確認) : パスワードを入力します。
- [System Administrator (hn1adm) Password](システム管理者 (hn1adm) のパスワード) : パスワードを入力します。
- [System Administrator Home Directory](システム管理者のホーム ディレクトリ) [/usr/sap/HN1/home]: Enter キーを押して既定値をそのまま使用します。
- [System Administrator Login Shell](システム管理者のログイン シェル) [/bin/sh]: Enter キーを押して既定値をそのまま使用します。
- [System Administrator User ID](システム管理者のユーザー ID) [1001]: Enter キーを押して既定値をそのまま使用します。
- [Enter ID of User Group (sapsys)](ユーザー グループ (sapsys) の ID を入力) [79]: Enter キーを押して既定値をそのまま使用します。
- [System Database User (system) Password](システム データベース ユーザー (system) のパスワード) : system のパスワードを入力します。
- [Confirm System Database User (system) Password](システム データベース ユーザー (system) のパスワードの確認) : system のパスワードを入力します。
- [Restart system after machine reboot?](コンピューターの再起動後にシステムを再起動しますか?) [n]: 「n」と入力します。
- [Do you want to continue (y/n)](続行しますか? (y/n)) : 概要を検証し、すべて問題がなさそうな場合は「y」と入力します。
[2] 上記の手順を繰り返して、SITE 2 の最初のノードに SAP HANA をインストールします。
[1,2]global.ini を確認します。
global.ini を表示し、内部 SAP HANA のノード間通信が正しく構成されていることを確認します。
communicationのセクションを確認します。interサブネットに対するアドレス空間があり、listeninterfaceが.internalに設定されている必要があります。internal_hostname_resolutionのセクションを確認します。interサブネットに属する HANA 仮想マシンの IP アドレスが含まれている必要があります。sudo cat /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini # Example from SITE1 [communication] internal_network = 10.23.1.128/26 listeninterface = .internal [internal_hostname_resolution] 10.23.1.138 = hana-s1-db1 10.23.1.139 = hana-s1-db2 10.23.1.140 = hana-s1-db3[1,2] SAP Note 2080991 の説明に従って、共有されていない環境でのインストールのために global.ini を準備します。
sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini [persistence] basepath_shared = no[1,2] SAP HANA を再起動して、変更をアクティブにします。
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem[1,2] クライアント インターフェイスが
clientサブネットの IP アドレスを使用して通信するようになっていることを確認します。# Execute as hn1adm /usr/sap/HN1/HDB03/exe/hdbsql -u SYSTEM -p "password" -i 03 -d SYSTEMDB 'select * from SYS.M_HOST_INFORMATION'|grep net_publicname # Expected result - example from SITE 2 "hana-s2-db1","net_publicname","10.23.0.14"構成を確認する方法については、SAP Note 「2183363 - SAP HANA 内部ネットワークの構成」を参照してください。
[AH] HANA のインストール エラーを回避するために、データ ディレクトリとログ ディレクトリのアクセス許可を変更します。
sudo chmod o+w -R /hana/data /hana/log[1] セカンダリ HANA ノードをインストールします。 このステップでは、例として SITE 1 での手順を示します。
常駐の
hdblcmプログラムをrootで開始します。cd /hana/shared/HN1/hdblcm ./hdblcmプロンプトで次の値を入力します。
- [Choose an action](アクションを選択する) : 「2」と入力します (ホストの追加)。
- [Enter comma separated host names to add](追加するホストの名前をコンマ区切りで入力) : 「hana-s1-db2, hana-s1-db3」と入力します。
- [Additional components for installation](追加でインストールするコンポーネント) : 「2, 3」と入力します。
- [Enter Root User Name](ルート ユーザー名を入力) [root] : Enter キーを押して既定値をそのまま使用します。
- [Select roles for host 'hana-s1-db2'](ホスト 'hana-s1-db2' のロールを選択) [1] : 1 を選択します (worker の場合)。
- [Enter Host Failover Group for host 'hana-s1-db2'](ホスト 'hana-s1-db2' のホスト フェールオーバー グループを入力) [既定値] : Enter キーを押して既定値をそのまま使用します。
- [Enter Storage Partition Number for host 'hana-s1-db2' [<<assign automatically>>]](ホスト 'hana-s1-db2' のストレージ パーティション番号を入力 [<<自動割り当て>>]): Enter キーを押して既定値をそのまま使用します。
- [Enter Worker Group for host 'hana-s1-db2'](ホスト 'hana-s1-db2' の worker グループを入力) [既定値] : Enter キーを押して既定値をそのまま使用します。
- [Select roles for host 'hana-s1-db3'](ホスト 'hana-s1-db3' のロールを選択) [1] : 1 を選択します (worker の場合)。
- [Enter Host Failover Group for host 'hana-s1-db3'](ホスト 'hana-s1-db3' のホスト フェールオーバー グループを入力) [既定値] : Enter キーを押して既定値をそのまま使用します。
- [Enter Storage Partition Number for host 'hana-s1-db3' [<<assign automatically>>]](ホスト 'hana-s1-db3' のストレージ パーティション番号を入力 [<<自動割り当て>>]): Enter キーを押して既定値をそのまま使用します。
- [Enter Worker Group for host 'hana-s1-db3'](ホスト 'hana-s1-db3' の worker グループを入力) [既定値] : Enter キーを押して既定値をそのまま使用します。
- [System Administrator (hn1adm) Password](システム管理者 (hn1adm) のパスワード) : パスワードを入力します。
- [Enter SAP Host Agent User (sapadm) Password](SAP ホスト エージェント ユーザー (sapadm) のパスワードを入力) : パスワードを入力します。
- [Confirm SAP Host Agent User (sapadm) Password](SAP ホスト エージェント ユーザー (sapadm) のパスワードの確認) : パスワードを入力します。
- [Certificate Host Name For Host hana-s1-db2](ホスト hana-s1-db2 の証明書ホスト名) [hana-s1-db2]: Enter キーを押して既定値をそのまま使用します。
- [Certificate Host Name For Host hana-s1-db3](ホスト hana-s1-db3 の証明書ホスト名) [hana-s1-db3]: Enter キーを押して既定値をそのまま使用します。
- [Do you want to continue (y/n)](続行しますか? (y/n)) : 概要を検証し、すべて問題がなさそうな場合は「y」と入力します。
[2] 上記の手順を繰り返して、SITE 2 にセカンダリ SAP HANA ノードをインストールします。
SAP HANA 2.0 システム レプリケーションの構成
次の手順では、システム レプリケーションを設定します。
[1] SITE 1 でシステム レプリケーションを構成します。
hn1adm としてデータベースをバックアップします。
hdbsql -d SYSTEMDB -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')"システム PKI ファイルをセカンダリ サイトにコピーします。
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/プライマリ サイトを作成します。
hdbnsutil -sr_enable --name=HANA_S1[2] SITE 2 でシステム レプリケーションを構成します。
2 番目のサイトを登録して、システム レプリケーションを開始します。 <hanasid>adm として次のコマンドを実行します。
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 sapcontrol -nr 03 -function StartSystem[1] レプリケーションの状態をチェックし、すべてのデータベースが同期されるまで待機します。
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | ------------- | ----- | ------------ | --------- | ------- | --------- | ------------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 1 | HANA_S1 | hana-s2-db3 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 1 | HANA_S1 | hana-s2-db1 | 30301 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 1 | HANA_S1 | hana-s2-db1 | 30307 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 1 | HANA_S1 | hana-s2-db1 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 1 | HANA_S1 | hana-s2-db2 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # # mode: PRIMARY # site id: 1 # site name: HANA_S1[1,2] HANA システム レプリケーション仮想ネットワーク インターフェイスを通じて、HANA システム レプリケーションの通信が行われるように、HANA の構成を変更します。
両方のサイトで HANA を停止します。
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem HDBglobal.ini を編集して、HANA システム レプリケーションのホスト マッピングを追加します。
hsrサブネットの IP アドレスを使用します。sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini #Add the section [system_replication_hostname_resolution] 10.23.1.202 = hana-s1-db1 10.23.1.203 = hana-s1-db2 10.23.1.204 = hana-s1-db3 10.23.1.205 = hana-s2-db1 10.23.1.206 = hana-s2-db2 10.23.1.207 = hana-s2-db3両方のサイトで HANA を開始します。
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem HDB
詳細については、システム レプリケーションのホスト名前解決に関するページを参照してください。
[AH] ファイアウォールを再び有効にし、必要なポートを開きます。
ファイアウォールを再度有効にします。
# Execute as root systemctl start firewalld systemctl enable firewalld必要なファイアウォール ポートを開きます。 HANA インスタンス番号に合わせてポートを調整する必要があります。
重要
HANA のノード間通信とクライアント トラフィックを許可するファイアウォール規則を作成します。 必要なポートは、すべての SAP 製品の TCP/IP ポートのページにあります。 次にコマンドは 1 つの例にすぎません。 このシナリオでは、システム番号 03 を使用します。
# Execute as root sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp --permanent sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp
Pacemaker クラスターの作成
基本的な Pacemaker クラスターを作成するには、「Azure での Red Hat Enterprise Linux での Pacemaker の設定」の手順に従います。 クラスターのマジョリティ メーカーを含む、すべての仮想マシンを含めます。
重要
quorum expected-votes は 2 に設定しません。 これは 2 ノード クラスターではありません。 ノード フェンシングが逆シリアル化されるように、クラスター プロパティ concurrent-fencing が有効になっていることを確認します。
ファイル システム リソースの作成
このプロセスの次の部分では、ファイル システム リソースを作成する必要があります。 その方法は次のとおりです。
[1,2] 両方のレプリケーション サイトで SAP HANA を停止します。 <sid>adm として実行します。
sapcontrol -nr 03 -function StopSystem[AH] インストールのためにすべての HANA DB VM に一時的にマウントされていた、ファイル システム
/hana/sharedをマウント解除します。 マウントを解除する前に、ファイル システムを使用しているプロセスとセッションを停止する必要があります。umount /hana/shared[1] 無効な状態の
/hana/shared用のファイル システム クラスター リソースを作成します。 マウントを有効にする前に場所の制約を定義する必要があるため、--disabledを使用します。
Azure Files 上 NFS 共有に /hana/shared' をデプロイするか、Azure NetApp Files で NFS ボリュームをデプロイすることを選択しました。この例では、'/hana/shared' ファイル システムが Azure NetApp Files にデプロイされ、NFSv4.1 経由でマウントされます。 Azure NetApp Files で NFS を使用している場合にのみ、このセクションの手順に従います。
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=true
推奨されるタイムアウト値により、クラスター リソースは、Azure NetApp Files での NFSv4.1 リース更新に関連するプロトコル固有の一時停止に耐えられます。 詳細については、NetApp での NFS のベスト プラクティスに関するページを参照してください。
この例では、'/hana/shared' ファイル システムが Azure Files 上の NFS にデプロイされます。 Azure Files で NFS を使用している場合にのみ、このセクションの手順に従います。
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=true監視操作に
OCF_CHECK_LEVEL=20属性を追加して、監視操作でファイル システムの読み取りおよび書き込みテストを実行できるようにします。 この属性がない場合、監視操作ではファイル システムがマウントされていることのみを確認します。 接続が失われると、アクセス不可能であるにもかかわらずファイル システムがマウントされたままになる場合があるため、これは問題になる可能性があります。on-fail=fence属性も監視操作に追加されます。 このオプションを使用すると、ノードで監視操作が失敗した場合、そのノードはすぐにフェンスされます。 このオプションがない場合、既定の動作では、障害が発生したリソースに依存するすべてのリソースが停止され、障害が発生したリソースが再起動されてから、障害が発生したリソースに依存するすべてのリソースが起動されます。 障害が発生したリソースに SAP HANA リソースが依存している場合、この動作は時間がかかる可能性があるだけでなく、完全に失敗する可能性もあります。 HANA バイナリを保持している NFS 共有にアクセスできない場合、SAP HANA リソースは正常に停止できません。上記の構成のタイムアウトは、特定の SAP セットアップに適合させる必要がある場合があります。
[1] ノード属性を構成して検証します。 レプリケーション サイト 1 のすべての SAP HANA DB ノードには属性
S1が割り当てられ、レプリケーション サイト 2 のすべての SAP HANA DB ノードには属性S2が割り当てられます。# HANA replication site 1 pcs node attribute hana-s1-db1 NFS_SID_SITE=S1 pcs node attribute hana-s1-db2 NFS_SID_SITE=S1 pcs node attribute hana-s1-db3 NFS_SID_SITE=S1 # HANA replication site 2 pcs node attribute hana-s2-db1 NFS_SID_SITE=S2 pcs node attribute hana-s2-db2 NFS_SID_SITE=S2 pcs node attribute hana-s2-db3 NFS_SID_SITE=S2 # To verify the attribute assignment to nodes execute pcs node attribute[1] NFS ファイル システムをマウントする場所を決定する制約を構成し、ファイル システム リソースを有効にします。
# Configure the constraints pcs constraint location fs_hana_shared_s1-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S1 pcs constraint location fs_hana_shared_s2-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S2 # Enable the file system resources pcs resource enable fs_hana_shared_s1 pcs resource enable fs_hana_shared_s2ファイル システム リソースを有効にすると、クラスターによって
/hana/sharedファイル システムがマウントされます。[AH] 両方のサイトのすべての HANA DB VM で、
/hana/sharedに Azure NetApp Files ボリュームがマウントされていることを確認します。Azure NetApp Files を使用している場合の例:
sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7Azure Files NFS を使用する場合の例:
sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
[1] 次のように、属性リソースを構成してクローンし、制約を構成します。
# Configure the attribute resources pcs resource create hana_nfs_s1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s1_active pcs resource create hana_nfs_s2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s2_active # Clone the attribute resources pcs resource clone hana_nfs_s1_active meta clone-node-max=1 interleave=true pcs resource clone hana_nfs_s2_active meta clone-node-max=1 interleave=true # Configure the constraints, which will set the attribute values pcs constraint order fs_hana_shared_s1-clone then hana_nfs_s1_active-clone pcs constraint order fs_hana_shared_s2-clone then hana_nfs_s2_active-cloneヒント
構成に /
hana/shared以外のファイル システムが含まれており、これらのファイル システムが NFS でマウントされている場合は、sequential=falseオプションを指定します。 このオプションを指定すると、ファイル システム間に順序の依存関係がなくなります。 NFS でマウントされたすべてのファイル システムは、対応する属性リソースの前に起動する必要がありますが、互いに決まった順序で起動する必要はありません。 詳細については、HANA ファイル システムが NFS 共有である場合の、Pacemaker クラスターでの SAP HANA スケールアウト HSR の構成方法に関するページを参照してください。[1] HANA クラスター リソースの作成準備として、Pacemaker をメンテナンス モードにします。
pcs property set maintenance-mode=true
SAP HANA クラスター リソースの作成
これで、クラスター リソースを作成する準備が整いました。
[A] マジョリティ メーカーを含むすべてのクラスター ノードに HANA スケールアウト リソース エージェントをインストールします。
yum install -y resource-agents-sap-hana-scaleoutNote
お使いのオペレーティング システム リリースでサポートされているパッケージ
resource-agents-sap-hana-scaleoutの最小バージョンのパッケージについては、RHEL HA クラスターのサポート ポリシー - クラスターでの SAP HANA の管理に関するページを参照してください。[1, 2] 各システム レプリケーション サイトの 1 つの HANA DB ノードで HANA システム レプリケーション フックを構成します。 SAP HANA は引き続き停止している必要があります。
resource-agents-sap-hana-scaleoutのバージョン 0.185.3-0 移行には、SAPHanaSR と ChkSrv の両方のフックが含まれています。 SAPHanaSR フックを有効にするには、正しいクラスター操作が必須です。 SAPHanaSR フックと ChkSrv Python フックの両方を構成することを強くお勧めします。global.iniを調整します。# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR-ScaleOut execution_order = 1 [ha_dr_provider_chksrv] provider = ChkSrv path = /usr/share/SAPHanaSR-ScaleOut execution_order = 2 action_on_lost = kill [trace] ha_dr_saphanasr = info ha_dr_chksrv = info
パラメーター
pathが既定の場所/usr/share/SAPHanaSR-ScaleOutを指すように設定すると、Python フック コードは OS の更新プログラムによって自動的に更新されます。 HANA は、次回再起動するときにフック コードの更新を使用します。/hana/shared/myHooksなどの省略可能な独自のパスを使用すると、HANA が使用するフック バージョンから OS 更新プログラムを切り離すことができます。action_on_lostパラメータを使用して、ChkSrvフックの動作を調整できます。 有効な値は [ignore|stop|kill] です。SAP HANA フックの実装の詳細については、「SAP HANA srConnectionChanged() フックの有効化」および「hdbindexserver プロセス障害アクションの SAP HANA srServiceStateChanged() フックの有効化 (省略可能)」を参照してください。
[AH] クラスターでは、<sid>adm のクラスター ノードで sudoers 構成が必要です。 この例では、新しいファイルを作成することによって、これを実行します。
rootとしてコマンドを実行します。sudo visudo -f /etc/sudoers.d/20-saphana # Insert the following lines and then save Cmnd_Alias SOK = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SRREBOOT = /usr/sbin/crm_attribute -n hana_hn1_gsh -v * -l reboot -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SOK, SFAIL, SRREBOOT Defaults!SOK, SFAIL, SRREBOOT !requiretty[1,2] 両方のレプリケーション サイトで SAP HANA を開始します。 <sid>adm として実行します。
sapcontrol -nr 03 -function StartSystem[1] フックのインストールを確認します。 アクティブな HANA システム レプリケーション サイトで、<sid>adm として実行します。
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example entries # 2020-07-21 22:04:52.782774 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:53.117492 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:06:35.599324 ha_dr_SAPHanaSR SOK[1] ChkSrv フックのインストールを確認します。 アクティブな HANA システム レプリケーション サイトで、<sid>adm として実行します。
cdtrace tail -20 nameserver_chksrv.trc[1] HANA クラスター リソースを作成します。
rootとして次のコマンドを実行します。クラスターが既にメンテナンス モードになっていることを確認します。
次に、HANA トポロジ リソースを作成します。
RHEL 7.x クラスターを構築している場合は、次のコマンドを使用します。pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopologyScaleOut \ SID=HN1 InstanceNumber=03 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueRHEL >= 8.x クラスターを構築する場合は、次のコマンドを使用します:
pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopology \ SID=HN1 InstanceNumber=03 meta clone-node-max=1 interleave=true \ op methods interval=0s timeout=5 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueHANA インスタンス リソースを作成します。
Note
この記事には、Microsoft が使用しなくなった用語への言及が含まれています。 ソフトウェアからこの用語が削除された時点で、この記事から削除します。
RHEL 7.x クラスターを構築している場合は、次のコマンドを使用します。
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource master msl_SAPHana_HN1_HDB03 SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueRHEL >= 8.x クラスターを構築する場合は、次のコマンドを使用します:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op demote interval=0s timeout=320 op methods interval=0s timeout=5 \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource promotable SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=true重要
フェールオーバー テストの実行中に
AUTOMATED_REGISTERをfalseに設定して、失敗したプライマリ インスタンスが自動的にセカンダリとして登録されないようにすることをお勧めします。 ベスト プラクティスとして、テストが終わったらAUTOMATED_REGISTERをtrueに設定し、引き継ぎ後にシステム レプリケーションが自動的に再開できるようにします。仮想 IP と関連するリソースを作成します。
pcs resource create vip_HN1_03 ocf:heartbeat:IPaddr2 ip=10.23.0.18 op monitor interval="10s" timeout="20s" sudo pcs resource create nc_HN1_03 azure-lb port=62503 sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03クラスターの制約を作成します。
RHEL 7.x クラスターを構築している場合は、次のコマンドを使用します。
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then msl_SAPHana_HN1_HDB03 pcs constraint colocation add g_ip_HN1_03 with master msl_SAPHana_HN1_HDB03 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne trueRHEL >= 8.x クラスターを構築する場合は、次のコマンドを使用します:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then SAPHana_HN1_HDB03-clone pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_HDB03-clone 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne true
[1] クラスターのメンテナンス モードを解除します。 クラスターの状態が
okであることと、すべてのリソースが起動されていることを確認します。sudo pcs property set maintenance-mode=false #If there are failed cluster resources, you may need to run the next command pcs resource cleanupNote
前の構成のタイムアウトは例にすぎないため、特定の HANA セットアップに適合させる必要がある場合があります。 たとえば、SAP HANA データベースの起動に時間がかかる場合は、開始タイムアウトを長くする必要がある可能性があります。
HANA のアクティブかつ読み取り可能のシステム レプリケーションの構成
SAP HANA 2.0 SPS 01 以降、SAP では SAP HANA システム レプリケーションに対してアクティブかつ読み取り可能なセットアップが可能になりました。 この機能を使用すると、読み取りを集中的に行うワークロードに対して、SAP HANA システム レプリケーションのセカンダリ システムをアクティブに使用できます。 クラスターでこのようなセットアップをサポートするには、2 番目の仮想 IP アドレスが必要です。これにより、読み取りが有効なセカンダリ SAP HANA データベースにクライアントからアクセスできます。 引き継ぎの実行後もセカンダリ レプリケーション サイトにアクセスできるようにするには、SAP HANA リソースのセカンダリを使用して、クラスターで仮想 IP アドレスを移動する必要があります。
このセクションでは、Red Hat 高可用性クラスターで、2 番目の仮想 IP アドレスを使用して、この種のシステム レプリケーションを管理するために必要な追加の手順について説明します。
先に進む前に、この記事で前述したように、SAP HANA データベースを管理する Red Hat 高可用性クラスターの構成が完了していることを確認してください。
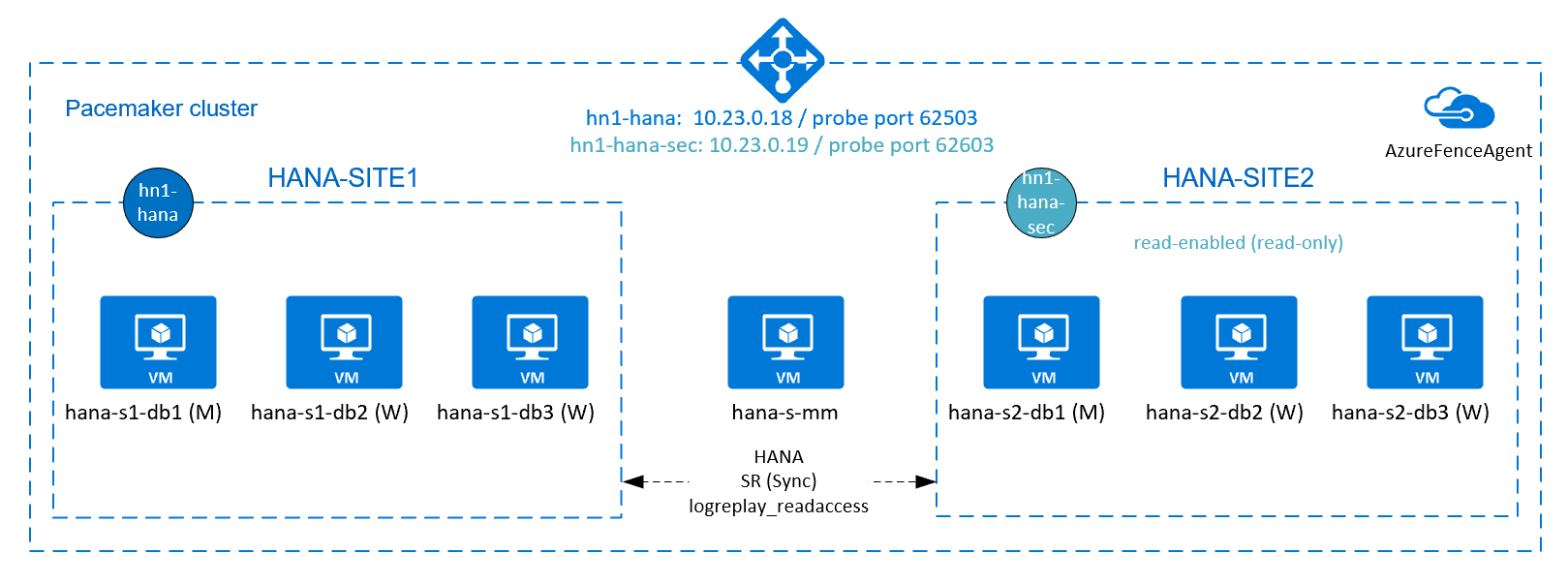
アクティブかつ読み取り可能なセットアップ用の Azure Load Balancer の追加設定
2 番目の仮想 IP のプロビジョニングに進むには、「Azure Load Balancer の構成」の説明に従って Azure Load Balancer の構成が完了していることを確認してください。
Standard Load Balancer の場合は、前のセクションで作成したのと同じロード バランサーで、下の追加手順に従います。
2 番目のフロントエンド IP プールを作成する:
- ロード バランサーを開き、 [frontend IP pool](フロントエンド IP プール) を選択して [Add](追加) を選択します
- この 2 番目のフロントエンド IP プールの名前を入力します (例: hana-secondaryIP)。
- [割り当て] を [静的] に設定し、IP アドレスを入力します (例: 10.23.0.19)。
- [OK] を選択します。
- 新しいフロントエンド IP プールが作成されたら、プールの IP アドレスを書き留めます。
次に、正常性プローブを作成します。
- ロード バランサーを開き、 [health probes](正常性プローブ) を選択して [Add](追加) を選択します。
- 新しい正常性プローブの名前を入力します (例: hana-secondaryhp)。
- プロトコルとして [TCP] を、ポートは 62603 を選択します。 [Interval](間隔) の値を 5 に設定し、 [Unhealthy threshold](異常しきい値) の値を 2 に設定します。
- [OK] を選択します。
次に、負荷分散規則を作成します。
- ロード バランサーを開き、 [load balancing rules](負荷分散規則) を選択して [Add](追加) を選択します。
- 新しいロード バランサー規則の名前を入力します (例: hana-secondarylb)。
- 前の手順で作成したフロントエンド IP アドレス、バックエンド プール、正常性プローブを選択します (例: hana-secondaryIP、hana-backend、hana-secondaryhp)。
- [HA ポート] を選択します。
- Floating IP を有効にします。
- [OK] を選択します。
HANA のアクティブかつ読み取り可能のシステム レプリケーションの構成
HANA システム レプリケーションを構成する手順については、「SAP HANA 2.0 システム レプリケーションの構成」セクションを参照してください。 読み取り可能なセカンダリ シナリオをデプロイする場合、2 番目のノードでシステム レプリケーションを構成するときに、次のコマンドを hanasidadm として実行します。
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 --operationMode=logreplay_readaccess
アクティブかつ読み取り可能のセットアップ用のセカンダリ仮想 IP アドレス リソースを追加する
2 番目の仮想 IP と追加の制約は、次のコマンドを使用して構成できます。 セカンダリインスタンスがダウンしている場合は、セカンダリ仮想 IP がプライマリに切り替わります。
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.23.0.19"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
# RHEL 8.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote SAPHana_HN1_HDB03-clone then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave SAPHana_HN1_HDB03-clone 5
# RHEL 7.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote msl_SAPHana_HN1_HDB03 then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave msl_SAPHana_HN1_HDB03 5
pcs property set maintenance-mode=false
クラスターの状態が ok であることと、すべてのリソースが起動されていることを確認します。 2 番目の仮想 IP は、セカンダリ サイトで SAP HANA セカンダリ リソースと共に実行されます。
# Example output from crm_mon
#Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#
#Active resources:
#
#rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm
#Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1]
# Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03]
# Masters: [ hana-s1-db1 ]
# Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1
#Resource Group: g_secip_HN1_03
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1
次のセクションでは、実行する典型的なフェールオーバー テストのセットを示します。
読み取りが有効なセカンダリで構成された HANA クラスターをテストする場合は、2 番目の仮想 IP の次の動作に注意します。
クラスター リソース SAPHana_HN1_HDB03 がセカンダリ サイト (S2) に移動すると、2 番目の仮想 IP がもう一方のサイト (hana-s1-db1) に移動します。
AUTOMATED_REGISTER="false"が構成済みで、HANA システム レプリケーションが自動的に登録されていない場合は、2 番目の仮想 IP が hana-s2-db1 で実行されます。サーバーのクラッシュをテストする場合、2 番目の仮想 IP リソース (rsc_secvip_HN1_03) と Azure Load Balancer のポート リソース (secnc_HN1_03) は、プライマリ仮想 IP リソースと共にプライマリ サーバー上で実行されます。 セカンダリ サーバーが停止している間、読み取り可能な HANA データベースに接続されているアプリケーションは、プライマリ HANA データベースに接続します。 これは正しい動作です。 セカンダリ サーバーが使用できなくても、読み取りが有効な HANA データベースに接続されているアプリケーションは動作することができます。
フェールオーバーとフォールバックの間は、2 番目の仮想 IP を使用して HANA データベースに接続するアプリケーションの既存の接続が中断される場合があります。
SAP HANA フェールオーバーのテスト
テストを開始する前に、クラスターと SAP HANA システムのレプリケーション状態を確認します。
失敗したクラスター アクションがないことを確認します。
#Verify that there are no failed cluster actions pcs status # Example #Stack: corosync #Current DC: hana-s-mm (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum #Last updated: Thu Sep 24 06:00:20 2020 #Last change: Thu Sep 24 05:59:17 2020 by root via crm_attribute on hana-s1-db1 # #7 nodes configured #45 resources configured # #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: # #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm #Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1SAP HANA システム レプリケーションが同期されていることを確認します。
# Verify HANA HSR is in sync sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" #| Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary| Secondary | Secondary | Secondary | Replication | Replication | Replication | #| | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | #| -------- | ----------- | ----- | ------------ | --------- | ------- | --------- | ------------- | -------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | #| HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 2 | HANA_S1 | hana-s2-db3 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 2 | HANA_S1 | hana-s2-db2 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 2 | HANA_S1 | hana-s2-db1 | 30301 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 2 | HANA_S1 | hana-s2-db1 | 30307 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 2 | HANA_S1 | hana-s2-db1 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #status system replication site "1": ACTIVE #overall system replication status: ACTIVE #Local System Replication State #~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #mode: PRIMARY #site id: 1 #site name: HANA_S1
ノードが NFS 共有 (
/hana/shared) へのアクセスを失ったときの障害シナリオに備えてクラスター構成を検証します。SAP HANA リソース エージェントでは、フェールオーバー中の操作の実行は
/hana/sharedに保存されるバイナリに依存しています。 提示されている構成では、ファイル システム/hana/sharedは NFS 経由でマウントされています。 実行可能なテストは、プライマリ サイト VM の 1 つで/hana/sharedNFS マウント ファイル システムへのアクセスをブロックする一時的なファイアウォール規則を作成することです。 この方法では、アクティブなシステム レプリケーション サイトで/hana/sharedへのアクセスが失われた場合に、クラスターがフェールオーバーされることを検証します。予想される結果: プライマリ サイト VM の 1 つで
/hana/sharedNFS マウント ファイル システムへのアクセスをブロックすると、ファイル システムに対して読み取り/書き込み操作を実行する監視操作は失敗します。これは、ファイル システムにアクセスできず、HANA リソースのフェールオーバーがトリガーされるためです。 HANA ノードが NFS 共有へのアクセスを失った場合も、同じ結果が予想されます。クラスター リソースの状態を確認するには、
crm_monまたはpcs statusを実行します。 テスト開始前のリソースの状態:# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1/hana/sharedのエラーをシミュレートするには:- ANF で NFS を使用している場合は、最初にプライマリ サイトの
/hana/sharedANF ボリュームの IP アドレスを確認します。 これを行うには、df -kh|grep /hana/sharedを実行します。 - Azure Files で NFS を使用している場合は、最初にストレージ アカウントのプライベート エンドポイントの IP アドレスを確認します。
次に、いずれかのプライマリ HANA システム レプリケーション サイト VM で次のコマンドを実行して、
/hana/sharedNFS ファイル システムの IP アドレスへのアクセスをブロックする一時的なファイアウォール規則を設定します。この例では、ANF ボリューム
/hana/sharedの hana-s1-db1 でコマンドが実行されました。iptables -A INPUT -s 10.23.1.7 -j DROP; iptables -A OUTPUT -d 10.23.1.7 -j DROP/hana/sharedへのアクセスが失われた HANA VM は、クラスター構成に応じて再起動または停止する必要があります。 クラスター リソースは、他の HANA システム レプリケーション サイトに移行されます。再起動された VM でクラスターが開始されていない場合は、次を実行してクラスターを開始します。
# Start the cluster pcs cluster startクラスターが開始されると、ファイル システム
/hana/sharedが自動的にマウントされます。AUTOMATED_REGISTER="false"を設定している場合は、セカンダリ サイトで SAP HANA システム レプリケーションを構成する必要があります。 この場合、次のコマンドを実行して、SAP HANA をセカンダリとして再構成することができます。# Execute on the secondary su - hn1adm # Make sure HANA is not running on the secondary site. If it is started, stop HANA sapcontrol -nr 03 -function StopWait 600 10 # Register the HANA secondary site hdbnsutil -sr_register --name=HANA_S1 --remoteHost=hana-s2-db1 --remoteInstance=03 --replicationMode=sync # Switch back to root and clean up failed resources pcs resource cleanup SAPHana_HN1_HDB03テスト後のリソースの状態は次のようになります。
# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s2-db1 ] # Slaves: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1- ANF で NFS を使用している場合は、最初にプライマリ サイトの
RHEL 上の Azure VM における SAP HANA の高可用性に関するページに記載されているテストも行い、SAP HANA クラスター構成を十分にテストすることをお勧めします。
次のステップ
- SAP のための Azure Virtual Machines の計画と実装
- SAP のための Azure Virtual Machines のデプロイ
- SAP のための Azure Virtual Machines DBMS のデプロイ
- SAP HANA 用 Azure NetApp Files 上の NFS v4.1 ボリューム
- Azure VM 上の SAP HANA の高可用性を確保し、ディザスター リカバリーを計画する方法については、Azure VM 上の SAP HANA の高可用性に関するページを参照してください。