Azure Database for PostgreSQL - フレキシブル サーバーでの高可用性 (信頼性)
適用対象: Azure Database for PostgreSQL - フレキシブル サーバー
Azure Database for PostgreSQL - フレキシブル サーバー
この記事では、Azure Database for PostgreSQL - フレキシブル サーバーの高可用性について説明します。これには、可用性ゾーン、リージョン間の復旧とビジネス継続性が含まれます。 Azure における信頼性の詳細については、Azure の信頼性に関するページを参照してください。
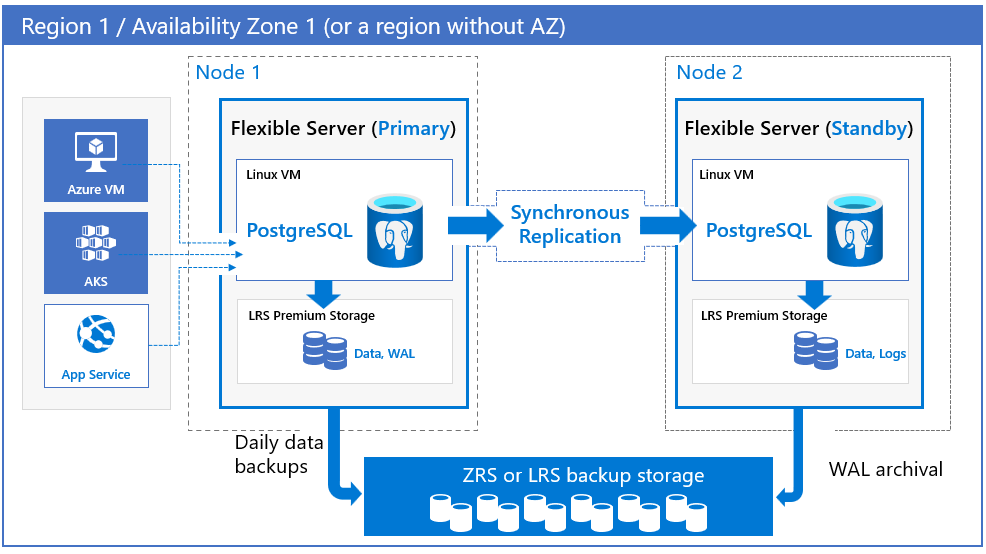
Azure Database for PostgreSQL - フレキシブル サーバーでは、同じ可用性ゾーン内 (ゾーン) または可用性ゾーン間 (ゾーン冗長) で、物理的に分離されたプライマリ レプリカとスタンバイ レプリカをプロビジョニングすることで、高可用性のサポートを提供します。 この高可用性モデルは、障害が発生した場合にコミットされたデータが失われないように設計されています。 高可用性 (HA) セットアップでは、データはプライマリ サーバーとスタンバイ サーバーの両方に同期的にコミットされます。 このモデルは、データベースがソフトウェア アーキテクチャにおける単一障害点にならないように設計されています。 高可用性と可用性ゾーンのサポートに関する詳細については、「可用性ゾーンのサポート」をご覧ください。
可用性ゾーンのサポート
可用性ゾーンとは、各 Azure リージョン内にある、物理的に分離されたデータセンターのグループです。 1 つのゾーンで障害が発生した際には、サービスを残りのゾーンのいずれかにフェールオーバーできます。
Azure の可用性ゾーンの詳細については、「可用性ゾーンとは」を参照してください。
Azure Database for PostgreSQL - フレキシブル サーバーでは、高可用性構成のためのゾーン冗長モデルとゾーン モデルの両方がサポートされています。 どちらの高可用性構成でも、計画的なイベントと計画外のイベントの両方で、データ損失ゼロの自動フェールオーバー機能が有効になります。
ゾーン冗長。 ゾーン冗長の高可用性では、別のゾーン内に自動フェールオーバー機能を備えたスタンバイ レプリカがデプロイされます。 ゾーン冗長では最高レベルの可用性が提供されますが、ゾーン間でアプリケーションの冗長性を構成する必要があります。 そのため、ゾーン冗長は、可用性ゾーン レベルの障害からの保護が必要な場合や、可用性ゾーン間の待機時間を許容できる場合に選択します。 書き込みとコミットの待ち時間は同期レプリケーションによってある程度影響を受ける可能性がありますが、読み取りクエリへの影響はありません。 この影響は、ワークロード、選択した SKU の種類、リージョンに極めて固有のものです。
プライマリ サーバーとスタンバイ サーバーの両方について、リージョンと可用性ゾーンを選択できます。 スタンバイ レプリカ サーバーは、同じリージョン内の選択した可用性ゾーンにプロビジョニングされ、コンピューティング、ストレージ、ネットワーク構成はプライマリ サーバーと同じになります。 データ ファイルとトランザクション ログ ファイル (先書きログ、別名 WAL) は、各可用性ゾーン内のローカル冗長ストレージ (LRS) に保存され、その際に 3 つのデータ コピーが自動的に保存されます。 ゾーン冗長構成では、プライマリ サーバーとスタンバイ サーバー間でスタック全体が物理的に分離されます。

ゾーン ベース。 単一の可用性ゾーン内で最高レベルの可用性を実現しながら、ネットワーク待機時間を最小限に抑えたい場合は、ゾーン デプロイを選択します。 両方のプライマリ データベース サーバーをデプロイするリージョンと可用性ゾーンを選択できます。 スタンバイ レプリカ サーバーは、同じ可用性ゾーンで自動的にプロビジョニングおよび管理され、コンピューティング、ストレージ、ネットワーク構成はプライマリ サーバーと同じになります。 ゾーン構成は、ノードレベルの障害からデータベースを保護し、計画的および計画外のダウンタイム イベント中のアプリケーションのダウンタイムを削減するのにも役立ちます。 プライマリ サーバーからのデータは、同期モードでスタンバイ レプリカにレプリケートされます。 プライマリ サーバーで何らかの障害が発生した場合、サーバーは自動的にスタンバイ レプリカにフェールオーバーされます。


Note
ゾーン デプロイ モデルとゾーン冗長デプロイ モデルは、アーキテクチャ的にはどちらも同じように動作します。 以下のセクションのさまざまな記述は、特に明記されていない限り、両方に適用されます。
前提条件
ゾーン冗長性:
ゾーン冗長オプションは、可用性ゾーンをサポートするリージョンでのみ使用できます。
ゾーン冗長は、次ではサポートされていません。
- Azure Database for PostgreSQL - 単一サーバー SKU。
- バースト可能なコンピューティング層。
- 単一ゾーンの可用性を持つリージョン。
ゾーン:
- ゾーン デプロイ オプションは、フレキシブル サーバーをデプロイできるすべての Azure リージョンで利用できます。
高可用性機能
スタンバイ レプリカは、プライマリ サーバーと同じ VM 構成 (仮想コア、ストレージ、ネットワーク設定を含む) でデプロイされます。
既存のデータベース サーバーに可用性ゾーンのサポートを追加できます。
高可用性を無効にすることで、スタンバイ レプリカを削除できます。
ゾーン冗長可用性を実現するために、プライマリ データベース サーバーとスタンバイ データベース サーバーの可用性ゾーンを選択できます。
停止、開始、再起動などの操作は、プライマリとスタンバイの両方のデータベース サーバーで同時に実行されます。
ゾーン冗長モデルおよびゾーン モデルでは、自動バックアップがプライマリ データベース サーバーから定期的に実行されます。 同時に、トランザクション ログがスタンバイ レプリカからバックアップ ストレージに継続的にアーカイブされます。 リージョンで可用性ゾーンがサポートされている場合、バックアップ データがゾーン冗長ストレージ (ZRS) に保存されます。 可用性ゾーンがサポートされていないリージョンでは、バックアップ データがローカル冗長ストレージ (LRS) に保存されます。
クライアントは常に、プライマリ データベース サーバーのエンド ホスト名に接続されます。
サーバー パラメーターへの変更は、スタンバイ レプリカにも適用されます。
静的サーバー パラメーターの変更を取得するためにサーバーを再起動する機能。
マイナー バージョンのアップグレードなどの定期的なメンテナンス アクティビティは、ダウンタイムを減らすために、最初にスタンバイで行われ、残りのノードにメンテナンス タスクが適用されている間、ワークロードを維持できるようにスタンバイがプライマリに昇格されます。
高可用性の正常性を監視する
Azure Database for PostgreSQL - フレキシブル サーバーでの高可用性 (HA) の正常性状態の監視では、HA 対応インスタンスの正常性と準備状況の概要が継続的に提供されます。 この監視機能は、Azure のリソース正常性チェック (RHC) フレームワークを利用して、データベースのフェールオーバーの準備状況または全体的な可用性に影響を与える可能性のある問題を検出し、アラートを生成します。 HA 正常性状態の監視では、接続状態、フェールオーバー状態、データ レプリケーションの正常性などの主要なメトリックを評価することで、予防的なトラブルシューティングが可能になり、データベースのアップタイムとパフォーマンスを維持するのに役立ちます。
お客様は HA の正常性状態の監視を使用して、次のことができます。
- パフォーマンスの低下やネットワークのブロックなど、潜在的な問題を明らかにする状態インジケーターを使用して、プライマリとスタンバイの両方のレプリカの正常性に関するリアルタイムの分析情報を取得します。
- HA 状態の変更に関するタイムリーな通知のためのアラートを構成し、潜在的な中断に対処するための即時対応を確実に行います。
- データベース操作に影響を与える前に問題を特定して対処することで、フェールオーバーの準備を最適化します。
HA 正常性状態の構成と解釈に関する詳細なガイドについては、メインの記事「Azure Database for PostgreSQL - フレキシブル サーバーの高可用性 (HA) 正常性状態の監視」を参照してください。
高可用性の制限
スタンバイ サーバー (特にゾーン冗長構成を使用したもの) への同期レプリケーションのため、アプリケーションで書き込みとコミットの待機時間が長くなる場合があります。
スタンバイ レプリカを読み取りクエリに使用することはできません。
プライマリ サーバーでのワークロードとアクティビティによっては、昇格する前にスタンバイ レプリカで復旧が必要な場合、フェールオーバー プロセスにかかる時間が 120 秒を超える場合があります。
通常、スタンバイ サーバーでは、40 MB/秒で WAL ファイルが復旧されます。 大きい SKU の場合、このレートは 200 MB/秒まで増加する可能性があります。 ワークロードがこの制限を超える場合、フェールオーバー中または新しいスタンバイの確立後、復旧完了までの時間が延びる可能性があります。
プライマリ データベース サーバーを再起動すると、スタンバイ レプリカも再起動されます。
追加のスタンバイの構成はサポートされていません。
お客様が開始した管理タスクの構成は、管理されたメンテナンス期間中にスケジュールすることはできません。
コンピューティングのスケーリングやストレージのスケーリングなどの計画的なイベントは、最初にスタンバイで、その後にプライマリ サーバーで実行されます。 現在、これらの計画的な操作については、サーバーのフェールオーバーは行われません。
可用性が構成されているたフレキシブル サーバーで論理デコードまたは論理レプリケーションが構成されている場合、スタンバイ サーバーへのフェールオーバー発生時に、論理レプリケーション スロットがスタンバイ サーバーにコピーされることはありません。 論理レプリケーション スロットを維持し、フェールオーバー後のデータ整合性を確保するには、PG フェールオーバー スロット拡張機能を使用することをお勧めします。 この拡張機能を有効にする方法の詳細については、ドキュメントを参照してください。
プライベート (VNET) とプライベート エンドポイントを使用したパブリック アクセス間の可用性ゾーンの構成はサポートされていません。 VNET 内 (1 つのリージョン内の複数の可用性ゾーンにまたがる) で可用性ゾーンを構成するか、またはプライベート エンドポイントを使用したパブリック アクセスを構成する必要があります。
可用性ゾーンは、単一のリージョン内でのみ構成されます。 可用性ゾーンをリージョン間で構成することはできません。
SLA
ゾーン モデルでは、99.95% の SLA のアップタイムを実現します。
ゾーン冗長モデルでは、99.99% の SLA のアップタイムを実現します。
可用性ゾーンが有効な Azure Database for PostgreSQL フレキシブル サーバーを作成する
可用性ゾーンを使用して高可用性を実現する Azure Database for PostgreSQL - フレキシブル サーバーを作成する方法については、「クイック スタート:Azure portal 内で Azure Database for PostgreSQL - フレキシブル サーバーを作成する」をご覧ください。
可用性ゾーンの再デプロイと移行
ゾーン冗長デプロイ モデルとゾーン デプロイ モデルの両方で、フレキシブル サーバーでの高可用性構成を有効または無効にする方法については、「フレキシブル サーバーで高可用性を管理する」をご覧ください。
高可用性コンポーネントとワークフロー
トランザクションの完了
アプリケーションのトランザクションによってトリガーされた書き込みとコミットは、まずプライマリ サーバー上の WAL に記録されます。 これらはその後、Postgres ストリーミング プロトコルを使用してスタンバイ サーバーにストリーミングされます。 ログがスタンバイ サーバーのストレージで永続化されたら、プライマリ サーバーが書き込みの完了を確認します。 その後はじめて、アプリケーションでトランザクションのコミットが確認されます。 この追加的なラウンド トリップの分、アプリケーションでの待機時間が長くなります。 影響の度合いは、アプリケーションによって異なります。 この確認プロセスでは、スタンバイ サーバーへのログの適用を待機しません。 スタンバイ サーバーは、昇格されるまで永続的に復旧モードになります。
正常性チェック
フレキシブル サーバーの稼働状況の監視では、プライマリとスタンバイの両方の正常性が定期的にチェックされます。 複数の ping の後、稼働状況の監視でプライマリ サーバーに到達できないことが検出された場合、サービスはスタンバイ サーバーへの自動フェールオーバーを開始します。 稼働状況の監視のアルゴリズムは、擬陽性を回避するため、複数のデータ ポイントに基づいています。
フェールオーバー モード
フレキシブル サーバーは、計画フェールオーバーと計画外フェールオーバー の 2 つのフェールオーバー モードをサポートします。 どちらのモードでも、レプリケーションが切断されると、スタンバイ サーバーはプライマリとして昇格されたり、読み取り/書き込み用に開かれる前に、復旧を実行します。 新しいプライマリ サーバー エンドポイントで自動 DNS エントリが更新されると、アプリケーションは同じ エンドポイントを使用してサーバーに接続できるようになります。 新しいスタンバイ サーバーがバックグラウンドで確立されるので、それによってアプリケーションは接続性を維持できます。
高可用性の状態
プライマリとスタンバイ サーバーの正常性は継続的に監視され、スタンバイ サーバーへのフェールオーバーのトリガーなど、問題を修復するための適切なアクションが実行されます。 次の表に、考えられる高可用性の状態を示します。
| 状態 | 説明 |
|---|---|
| 初期化中 | 新しいスタンバイ サーバーの作成中です。 |
| データのレプリケート中 | スタンバイの作成後、そのスタンバイがプライマリに追い付こうとしています。 |
| Healthy | レプリケーションは安定状態にあり、正常です。 |
| フェールオーバー中 | データベース サーバーはスタンバイにフェールオーバー中です。 |
| スタンバイの削除中 | スタンバイ サーバーの削除中です。 |
| 有効ではない | 高可用性が有効ではありません。 |
Note
高可用性の有効化はサーバーの作成時に行うことも、後で行うこともできます。 作成後のステージで高可用性の有効化または無効化を行う場合は、プライマリ サーバーのアクティビティが少ないときに操作することをお勧めします。
安定状態の操作
PostgreSQL クライアント アプリケーションは、DB サーバー名を使用してプライマリ サーバーに接続されます。 アプリケーションの読み取りは、プライマリ サーバーから直接行なわれます。 同時に、コミットと書き込みは、ログ データがプライマリ サーバーとスタンバイ レプリカの両方に保存された後にのみ、アプリケーションに確認されます。 この余分なラウンドトリップのため、アプリケーションでは、書き込みとコミットの待機時間が長くなることが予想されます。 高可用性の正常性はポータルで監視できます。
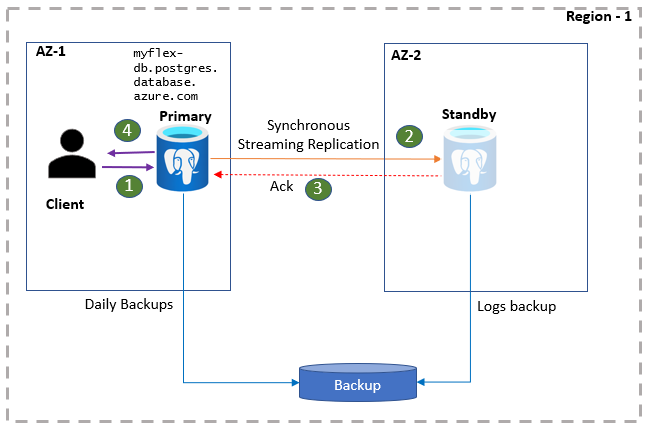
- クライアントがフレキシブル サーバーに接続し、書き込み操作を実行します。
- 変更はスタンバイ サイトにレプリケートされます。
- プライマリが受信確認を受け取ります。
- 書き込み/コミットが確認されます。
高可用性サーバーのポイントインタイム リストア
高可用性が構成されているフレキシブル サーバーでは、ログ データはリアルタイムでスタンバイ サーバーにレプリケートされます。 プライマリ サーバー上のユーザー エラー (テーブルの予想外の切断やデータの間違った更新など) は、スタンバイ レプリカにレプリケートされます。 そのため、このような論理エラーから復旧するためにスタンバイを使用することはできません。 このようなエラーから復旧するには、バックアップからポイントインタイム リストアを実行する必要があります。 フレキシブル サーバーのポイントインタイム リストア機能を使用すると、エラーが発生する前の時刻に復元できます。 新しいデータベース サーバーが、高可用性が構成されたデータベースのために単一ゾーン フレキシブル サーバーとして復元され、ユーザーが指定した新しいサーバー名が付けられます。 復元されたサーバーは、次のようないくつかのユース ケースに使用できます:
復元されたサーバーを運用環境に使用し、必要に応じて、同じゾーンまたは同じリージョン内の別のゾーンのスタンバイ レプリカで高可用性を有効にすることができます。
オブジェクトを復元する場合は、復元されたデータベース サーバーからオブジェクトをエクスポートして、運用データベース サーバーにインポートします。
テストおよび開発目的でデータベース サーバーを複製する場合や、その他の目的のために復元する場合は、ポイントインタイム リストアを実行できます。
フレキシブル サーバーのポイントインタイム リストアを実行する方法については、「フレキシブル サーバー のポイントインタイム リストア」をご覧ください。
フェールオーバーのサポート
計画されたフェールオーバー
計画的なダウンタイムのイベントには、Azure のスケジュールされた定期的なソフトウェア更新やマイナー バージョンのアップグレードが含まれます。 計画フェールオーバーを使用して、プライマリ サーバーを優先可用性ゾーンに戻すこともできます。 高可用性で構成されている場合は、アプリケーションが引き続きプライマリ サーバーにアクセスしている間、これらの操作は最初にスタンバイ レプリカに適用されます。 スタンバイ レプリカが更新されると、プライマリ サーバーの接続がドレインされ、スタンバイ レプリカを同じデータベース サーバー名を持つプライマリとしてアクティブ化するフェールオーバーがトリガーされます。 クライアント アプリケーションは、同じデータベース サーバー名を使用して新しいプライマリ サーバーに再接続する必要があり、その後に操作を再開できます。 新しいスタンバイ サーバーは、古いプライマリと同じゾーン内に確立されます。
他のユーザーが開始した操作 (コンピューティングのスケーリングやストレージのスケーリングなど) の場合、変更は最初にスタンバイで、その後にプライマリで適用されます。 現在、サービスはスタンバイにフェールオーバーされないため、スケール操作がプライマリ サーバーで実行されている間、アプリケーションで短時間のダウンタイムが発生します。
また、この機能を使用すると、ダウンタイムを短縮してスタンバイ サーバーにフェールオーバーできます。 例えば、計画外のフェールオーバー後に、プライマリがアプリケーションとは異なる可用性ゾーンに存在する可能性があります。 アプリケーションと併置するために、プライマリ サーバーを前のゾーンに戻す必要があります。
この機能を実行する場合、スタンバイ サーバーでは、まず最新のトランザクションに追い付いていることを確認するための準備が行われ、アプリケーションで読み取りや書き込みを続行できるようになります。 その後、スタンバイが昇格され、プライマリへの接続が切断されます。 新しいスタンバイ サーバーがバックグラウンドで確立されている間、アプリケーションは引き続きプライマリに書き込みを行うことができます。 計画フェールオーバーに伴う手順を次に示します。
| Step | 説明 | アプリのダウンタイムが予想されるかどうか |
|---|---|---|
| 1 | スタンバイ サーバーがプライマリに追い付くまで待ちます。 | いいえ |
| 2 | 内部監視システムによって、フェールオーバー ワークフローが開始されます。 | いいえ |
| 3 | スタンバイ サーバーがプライマリのログ シーケンス番号 (LSN) に近い場合、アプリケーションの書き込みはブロックされます。 | はい |
| 4 | スタンバイ サーバーが独立したサーバーに昇格されます。 | はい |
| 5 | DNS レコードがスタンバイ サーバーの新しい IP アドレスで更新されます。 | はい |
| 6 | アプリケーションが新しいプライマリに再接続され、読み取り/書き込みが再開されます。 | いいえ |
| 7 | 別のゾーンの新しいスタンバイ サーバーが確立されます。 | いいえ |
| 8 | スタンバイ サーバーで、確立中に失われたログの復旧が (Azure BLOB から) 開始されます。 | いいえ |
| 9 | プライマリ サーバーとスタンバイ サーバーの間に安定した状態が確立されます。 | いいえ |
| 10 | 計画されたフェールオーバーのプロセスが完了します。 | いいえ |
アプリケーションのダウンタイムは手順 3 から始まり、手順 5 の後に操作を再開できます。 残りの手順は、アプリケーションの書き込みとコミットに影響を与えることなく、バックグラウンドで行われます。
ヒント
フレキシブル サーバーでは、必要に応じて、データベース上のアクティビティが少ないと予測される任意の日の 60 分の期間を選択することによって、Azure によって開始されるメンテナンス アクティビティをスケジュールできます。 修正プログラムの適用やマイナー バージョンのアップグレードなどの Azure のメンテナンス タスクは、その期間中に実行されます。 カスタム期間を選択しない場合は、システムによって割り当てられたローカル時刻の午後 11 時から午前 7 時の間の 1 時間がサーバーに対して選択されます。 Azure が開始するこれらのメンテナンス アクティビティは、可用性ゾーンが構成されているフレキシブル サーバーのスタンバイ レプリカでも実行されます。
発生する可能性のある計画的なダウンタイム イベントの一覧については、「計画的なダウンタイム イベント」をご覧ください
計画外のフェールオーバー
計画外のダウンタイムは、基になるハードウェアの障害、ネットワークの問題、ソフトウェアのバグなど、予期しない中断の結果として発生する可能性があります。 高可用性が構成されているデータベース サーバーが予期せず停止した場合は、スタンバイ レプリカがアクティブ化され、クライアントは操作を再開できます。 高可用性 (HA) が構成されていない場合は、再起動の試みが失敗すると、新しいデータベース サーバーが自動的にプロビジョニングされます。 計画外のダウンタイムは回避できませんが、フレキシブル サーバーを使用すると、ユーザーの介入を必要とすることなく自動的に復旧操作を実行することでダウンタイムが軽減されます。
考えられるシナリオなど、計画外のフェールオーバーとダウンタイムの詳細については、「計画外のダウンタイムの軽減」をご覧ください。
フェールオーバー テスト (強制フェールオーバー)
強制フェールオーバーを使用すると、運用ワークロードの実行中に計画外の停止シナリオをシミュレートし、アプリケーションのダウンタイムを観察できます。 プライマリ サーバーが応答しなくなったときに強制フェールオーバーを使用することもできます。
強制フェールオーバーによってプライマリ サーバーが停止され、スタンバイ 昇格操作が実行されるフェールオーバー ワークフローが開始されます。 スタンバイは、最後にコミットされたデータまで復旧プロセスを完了すると、プライマリ サーバーに昇格されます。 DNS レコードが更新され、アプリケーションは昇格されたプライマリ サーバーに接続できます。 新しいスタンバイ サーバーがバックグラウンドで確立されている間、アプリケーションは引き続きプライマリに書き込みを行うことができます。これが稼働時間に影響を及ぼすことはありません。
以下は、強制フェールオーバー中に実行されるステップです。
| Step | 説明 | アプリのダウンタイムが予想されるかどうか |
|---|---|---|
| 1 | プライマリ サーバーは、フェールオーバー要求を受信した直後に停止します。 | はい |
| 2 | プライマリ サーバーがダウンしているため、アプリケーションでダウンタイムが発生します。 | はい |
| 3 | 内部監視システムによってエラーが検出され、スタンバイ サーバーへのフェールオーバーが開始されます。 | はい |
| 4 | スタンバイ サーバーは、独立したサーバーとして完全に昇格される前に、回復モードに移行します。 | はい |
| 5 | フェールオーバー プロセスは、スタンバイの復旧が完了するまで待機します。 | はい |
| 6 | サーバーが起動すると、DNS レコードは同じホスト名で更新されますが、スタンバイの IP アドレスが使用されます。 | はい |
| 7 | アプリケーションは新しいプライマリ サーバーに再接続して操作を再開できます。 | いいえ |
| 8 | 優先ゾーン内のスタンバイ サーバーが確立されます。 | いいえ |
| 9 | スタンバイ サーバーで、確立中に失われたログの復旧が (Azure BLOB から) 開始されます。 | いいえ |
| 10 | プライマリ サーバーとスタンバイ サーバーの間に安定した状態が確立されます。 | いいえ |
| 11 | 強制フェールオーバー プロセスが完了します。 | いいえ |
アプリケーションのダウンタイムは、ステップ 1 の後に始まり、ステップ 6 が完了するまで継続することが予想されます。 残りのステップは、そのアプリケーションの書き込みとコミットに影響を与えることなく、バックグラウンドで行われます。
重要
エンドツーエンドのフェールオーバー プロセスには、(a) プライマリの障害発生後のスタンバイ サーバーへのフェールオーバーと (b) 定常状態での新しいスタンバイ サーバーの確立が含まれます。 スタンバイへのフェイルオーバーが完了するまでアプリケーションのダウンタイムが発生するため、エンドツーエンドのフェイルオーバー プロセス全体ではなく、アプリケーション/クライアントの観点からダウンタイムを測定してください。
強制フェールオーバーを実行する際の考慮事項
エンドツーエンドの全体的な操作時間は、アプリケーションで発生する実際のダウンタイムよりも長く見える可能性があります。
重要
常にアプリケーションの観点からダウンタイムを観察してください。
フェールオーバーをすぐに連続して実行することはしないでください。 フェールオーバー間は少なくとも 15 分から 20 分待ち、新しいスタンバイ サーバーが完全に確立されるようにします。
ダウンタイムを減らすために、アクティビティの少ない期間中に強制フェールオーバーを実行することをお勧めします。
フェールオーバー後の PostgreSQL 統計のベスト プラクティス
PostgreSQL のフェールオーバー後、最適なデータベース パフォーマンスを維持するための主要なメカニズムには、pg_statistic テーブルと pg_stat_* テーブルの個別のロールを解釈することが含まれます。
pg_statistic テーブルには、クエリ プランナーにとって重要なオプティマイザー統計が含まれます。 これらの統計にはテーブル内のデータ分散が含まれており、フェールオーバー後もそのまま残ります。これにより、クエリ プランナーは、正確な履歴データ分散情報に基づいてクエリの実行を効果的に最適化し続けることができます。
これに対し、スキャンの数、読み取られたタプル、更新などのアクティビティの統計情報を記録する pg_stat_* テーブルは、フェールオーバー時にリセットされます。 このようなテーブルの例として、ユーザー定義テーブルのアクティビティを追跡する pg_stat_user_tables テーブルがあります。 このリセットは、新しいプライマリの運用状態を正確に反映するように設計されていますが、自動バキューム プロセスやその他の運用効率を通知する可能性のある履歴アクティビティ メトリックが失われることも意味します。
この違いを考えると、PostgreSQL フェールオーバーの後のベスト プラクティスは ANALYZE を実行することです。 このアクションにより、新しいアクティビティ統計などを含むpg_stat_* テーブル (例えば pg_stat_user_tables) が更新され、自動バキューム プロセスに役立ち、新しいロールでデータベースのパフォーマンスが最適なまま維持されます。 このプロアクティブな手順は、データベースの現在の状態に合わせて、基本的なオプティマイザー統計を保持することとアクティビティ メトリックを更新することとのギャップを埋めます。
ゾーンダウン エクスペリエンス
ゾーン: ゾーンレベルの障害から復旧するには、バックアップを使用してポイントインタイム リストアを実行します。 最新時刻のカスタム復元ポイントを選択して、最新のデータを復元できます。 影響を受けていない別のゾーンに、新しいフレキシブル サーバーがデプロイされます。 復元にかかる時間は、前回のバックアップと、復旧するトランザクション ログの量によって異なります。
ポイントインタイム リストアの詳細については、「Azure Database for PostgreSQL フレキシブル サーバー でのバックアップと復元」を参照してください。
ゾーン冗長: フレキシブル サーバーは、60 秒から 120 秒以内にデータ損失なしでスタンバイ サーバーに自動的にフェールオーバーされます。
可用性ゾーンのない構成
推奨はされませんが、高可用性を有効にせずにフレキシブル サーバーを構成することもできます。 高可用性なしで構成されたフレキシブル サーバーの場合、このサービスは、データのコピーが 3 つあるローカル冗長ストレージ、ゾーン冗長バックアップ (サポートされるリージョンの場合) を提供します。また、クラッシュしたサーバーを自動的に再起動し、サーバーを別の物理ノードに再配置する組み込みのサーバー回復性も提供します。 この構成では、99.9% の SLA のアップタイムが提供されます。 計画的または計画外のフェールオーバー イベント中にサーバーがダウンした場合、サービスでは次の自動化された手順を使用してサーバーの高可用性が維持されます。
- 新しいコンピューティング Linux VM がプロビジョニングされます。
- データ ファイルを含むストレージが新しい仮想マシンにマップされます。
- 新しい仮想マシン上で PostgreSQL データベース エンジンがオンラインになります。
次の図は、VM とストレージの障害の遷移を示しています。

リージョン間のディザスター リカバリーおよび事業継続
リージョン全体の障害が発生した場合、Azure では別のリージョンを使用することで、ディザスター リカバリーによる局地的または大規模な地理的災害からの保護を提供できます。 Azure ディザスター リカバリー アーキテクチャの詳細については、「Azure から Azure へのディザスター リカバリー アーキテクチャ」を参照してください。
フレキシブル サーバーでは、計画的および計画外のダウンタイム イベントの発生時に、データを保護し、ミッション クリティカルなデータベースのダウンタイムを軽減する機能が提供されています。 フレキシブル サーバーは堅牢な回復性と可用性を提供する Azure インフラストラクチャ上に構築されており、障害からの保護を強化し、復旧時間要件に対処し、データ損失の発生を減らすビジネス継続性機能を備えています。 アプリケーションを設計するときは、ダウンタイムの許容範囲 (目標復旧時間 (RTO)) とデータ損失の発生 (目標復旧時点 (RPO)) を考慮する必要があります。 たとえば、ビジネス クリティカルなデータベースでは、テスト データベースよりも厳しいアップタイムが必要になります。
複数リージョンの地域でのディザスター リカバリー
geo 冗長バックアップと復元
地理的冗長バックアップと復元により、災害発生時に別のリージョンにサーバーを復元することができます。 さらにこれにより、バックアップ オブジェクトの年間 99.99999999999999% (9 が 16 個) 以上の持続性が実現されます。
geo 冗長バックアップの構成は、サーバーの作成時にのみ行うことができます。 サーバーが geo 冗長バックアップで構成されている場合、バックアップ データとトランザクション ログは、ストレージ レプリケーションを使用してペア リージョンに非同期的にコピーされます。
地理的冗長バックアップと復元の詳細については、「地理的冗長バックアップと復元」をご覧ください。
読み取りレプリカ
リージョンにまたがる読み取りレプリカは、リージョン レベルの障害からデータベースを保護するためにデプロイできます。 読み取りレプリカは、PostgreSQL の物理的なレプリケーション テクノロジを使用して非同期的に更新され、プライマリより遅れることがあります。 読み取りレプリカは、汎用およびメモリ最適化されたコンピューティング レベルでサポートされます。
読み取りレプリカの機能と考慮事項の詳細については、読み取りレプリカに関する記事をご覧ください。
停止の検出、通知、管理
サーバーが geo 冗長バックアップを使用して構成されている場合は、ペアになっているリージョンで geo 復元を実行できます。 新しいサーバーがプロビジョニングされ、そのリージョンにコピーされた使用可能な最後のデータに復旧されます。
リージョンにまたがる読み取りレプリカも使用できます。 リージョンで障害が発生した場合、読み取りレプリカを昇格させてスタンドアロンの読み取り/書き込み可能サーバーにすることで、ディザスター リカバリー操作を実行できます。 RPO は最長 5 分と予想されます (データ損失の可能性あり)。ただし、重大なリージョン障害が発生した場合を除きます。この場合、RPO は障害発生時のレプリケーション ラグに近くなる可能性があります。
計画外のダウンタイム軽減策とリージョン障害後の復旧の詳細については、「計画外のダウンタイムの軽減」をご覧ください。