ビジネス継続性、高可用性、ディザスター リカバリーとは
この記事では、高可用性とディザスター リカバリー設計によるリスク管理の観点から、ビジネス継続性とビジネス継続性の計画を定義し、説明します。 この記事は、独自のビジネス継続性のニーズを満たす方法について明示的なガイダンスを提供するものではありませんが、Microsoft の信頼性ガイダンス全体で使用される概念を理解するのに役立ちます。
"ビジネス継続性" は、障害、停止、災害が発生しても企業が事業を継続できる状態を指します。 ビジネス継続性には、予防的な計画、準備、回復性があるシステムとプロセスの実装が必要です。
ビジネス継続性の計画には、リスクを特定、理解、分類、管理することが必要です。 リスクとその発生の可能性に基づいて、"高可用性" (HA) と "ディザスター リカバリー" (DR) の両方のために設計します。
"高可用性" とは、日々の問題に対する回復性を備え、可用性に関するビジネス ニーズを満たすソリューションを設計することです。
"ディザスター リカバリー" とは、一般的でないリスクや、発生する可能性のある致命的な停止に対処する方法を計画することです。
ビジネス継続性
一般に、クラウド ソリューションはビジネス運用に直接関連付けられています。 クラウド ソリューションが利用できなくなったり、重大な問題が発生したりするたびに、ビジネス運用に深刻な影響が出る可能性があります。 影響が重大な場合はビジネス継続性が損なわれる可能性があります。
ビジネス継続性に対する重大な影響には次のようなものがあります。
- 事業収入の損失。
- ユーザーに重要なサービスを提供できない。
- 顧客または他の当事者に対するコミットメント違反。
ビジネス上の期待と障害の結果を理解して、ワークロードを設計、実装、運用する関係者を含む重要な利害関係者に伝えることが重要です。 そうすると、それらの利害関係者は、そのビジョンの達成に必要なコストを分担することで対応します。 通常、予算やその他の制約に基づいて、そのビジョンの交渉と修正のプロセスがあります。
事業継続計画
ビジネス継続性への悪影響を制御または完全に回避するには、"ビジネス継続性計画" を事前に作成することが重要です。 ビジネス継続性計画は、リスク評価と、さまざまなアプローチを通じてそれらのリスクを制御する方法の開発に基づいています。 軽減すべき具体的なリスクとアプローチは、組織とワークロードごとに異なります。
ビジネス継続性計画では、クラウド プラットフォーム自体の回復性機能だけでなく、アプリケーションの機能も考慮します。 堅牢なビジネス継続性計画には、要員、ビジネス関連の手動または自動化されたプロセス、その他のテクノロジなど、ビジネスにおけるサポートのあらゆる側面も組み込まれています。
ビジネス継続性計画には、次の一連の手順を含める必要があります。
リスクの識別。 ワークロードの可用性または機能に対するリスクを特定します。 考えられるリスクは、ネットワークの問題、ハードウェア障害、人的エラー、リージョンの停止などです。各リスクの影響を理解します。
リスク分類。 各リスクを、HA のための計画に組み込むべき一般的なリスクと、DR 計画の一部とする一般的でないリスクのいずれかとして分類します。
リスクの軽減。 リスクを最小限に抑えたり軽減したりするために、冗長性、レプリケーション、フェールオーバー、バックアップを使用するなどの HA または DR の軽減戦略を設計します。 また、技術面以外の、およびプロセスベースの軽減策と制御を検討します。
ビジネス継続性計画はプロセスであり、1 回限りのイベントではありません。 作成されたビジネス継続性計画は、関連性が高く効果的であり、現在のビジネス ニーズをサポートしていることを確認するために、定期的に見直して更新する必要があります。
リスクの特定
ビジネス継続性計画の最初のフェーズは、ワークロードの可用性または機能に対するリスクを特定することです。 各リスクを分析して、その可能性と重大度を理解する必要があります。 重大度は、潜在的なダウンタイムやデータ損失、およびソリューション設計の残りの部分で悪影響を補えるかどうかを考慮したものである必要があります。
次の表は、リスクを発生の可能性の高い順に並べたものであり、すべてのリスクを網羅した一覧ではありません。
| リスクの例 | 説明 | 規則性 (確率) |
|---|---|---|
| 一時的なネットワークの問題 | ネットワーク スタックのコンポーネントの一時的な障害。短時間 (通常は数秒以下) で復旧できます。 | Regular |
| 仮想マシンの再起動 | 使用している仮想マシン、または依存サービスによって使用されている仮想マシンの再起動。 再起動は、仮想マシンがクラッシュしたり、パッチを適用する必要が生じたりするために発生する可能性があります。 | Regular |
| ハードウェアの障害 | ハードウェア ノード、ラック、クラスターなど、データセンター内のコンポーネントの障害。 | ときどき |
| データセンターの停止 | 停電、ネットワーク接続の問題、加熱と冷却の問題など、ほとんどのデータセンターまたはすべてのデータセンターに影響を与える停止。 | まれ |
| リージョンの停止 | 大規模な自然災害など、大都市圏全体またはより広い地域に影響を与える停止。 | 非常にまれ |
ビジネス継続性の計画は、クラウド プラットフォームとインフラストラクチャについてだけ考えればよいのではありません。 人為的ミスのリスクを考慮することが重要です。 さらに、従来はセキュリティ、パフォーマンス、または運用上のリスクと見なされていたであろう一部のリスクも、ソリューションの可用性に影響を与えるため、信頼性リスクと見なす必要があります。
次に例をいくつか示します。
| リスクの例 | 説明 |
|---|---|
| データの損失または破損 | データが誤って、またはランサムウェア攻撃などのセキュリティ侵害によって、削除、上書きされたり、破損したりする。 |
| ソフトウェアのバグ | 新しいコードまたは更新されたコードをデプロイしたことで、可用性または整合性に影響を与えるバグが発生し、ワークロードが正常に動作しなくなる。 |
| 失敗した展開 | 新しいコンポーネントまたはバージョンのデプロイが失敗し、ソリューションが一貫性のない状態になる。 |
| サービス拒否攻撃 | ソリューションの正当な使用を妨げるためにシステムが攻撃された。 |
| 不正な管理者 | 管理者特権を持つユーザーが、システムに対して意図的に有害なアクションを実行した。 |
| アプリケーションへの予期しないトラフィックの流入 | トラフィックの急増により、システムのリソースが圧迫されている。 |
"障害モード分析" (FMA) は、ワークロードまたはそのコンポーネントにどのように障害が発生する可能性があり、そのような状況でソリューションがどのように動作するかを特定するプロセスです。 詳細については。「障害モード分析を実行するための推奨事項」を参照してください。
リスク分類
ビジネス継続性計画では、一般的なリスクと一般的でないリスクの両方に対処する必要があります。
"一般的なリスク" は計画に組み込まれており、想定されています。 たとえば、クラウド環境では、ネットワークの短時間の停止、パッチによる機器の再起動、サービスがビジー状態の場合のタイムアウトなど、"一時的な障害" が発生することが一般的です。 これらのイベントは定常的に発生するため、ワークロードにはこれらに対する回復性が必要です。
高可用性戦略では、この種類の各リスクを考慮して制御する必要があります。
"一般的でないリスク" は、自然災害や大規模なネットワーク攻撃など、予期しないイベントの結果であり、致命的な停止につながる可能性があります。
ディザスター リカバリー プロセスは、このようなまれなリスクに対処します。
高可用性とディザスター リカバリーは相互に関連しているため、両方の戦略を一緒に計画することが重要です。
リスク分類はワークロード アーキテクチャとビジネス要件に依存し、一部のリスクは 1 つのワークロードでは HA、別のワークロードでは DR として分類できることを理解しておくことが重要です。 たとえば、Azure リージョンの完全な停止は、通常、そのリージョンのワークロードに対する DR リスクと見なされます。 ただし、完全なレプリケーション、冗長性、自動リージョン フェールオーバーを備えたアクティブ/アクティブ構成で複数の Azure リージョンを使用するワークロードの場合、リージョンの停止は HA リスクとして分類されます。
リスク軽減
リスク軽減は、ビジネス継続性に対するリスクを最小限に抑える、あるいは軽減するための HA または DR の戦略を策定することです。 リスク軽減策には、テクノロジベースのものと人間中心のものがあります。
テクノロジベースのリスク軽減策
テクノロジベースのリスク軽減策では、ワークロードがどのように実装および構成されているかに基づくリスク コントロールが使用されます。次に例を示します。
- 冗長性
- データのレプリケーション
- [フェールオーバー]
- バックアップ
テクノロジベースのリスク コントロールは、ビジネス継続性計画のコンテキスト内で考慮する必要があります。
次に例を示します。
少ないダウンタイムの要件 一部のビジネス継続性計画では、厳格な高可用性の要件により、どのような形でもダウンタイムのリスクを許容できません。 特定のテクノロジベースの制御では、人が通知を受け取ってから応答する時間が必要になる場合があります。 低速な手動プロセスを含むテクノロジベースのリスク コントロールは、リスク軽減戦略に含めることに適さない可能性があります。
部分的な障害に対する許容範囲。 一部のビジネス継続性計画では、"機能低下状態" で実行されるワークフローを許容できます。 ソリューションが機能低下状態で動作する場合、一部のコンポーネントが無効または動作不能である可能性がありますが、基幹業務は引き続き実行できます。 詳細については、「self-healing と自己保存に関する推奨事項」を参照してください。
人間中心のリスク軽減策
人間中心のリスク軽減策では、次のようなビジネス プロセスに基づくリスク コントロールが使用されます。
- 応答プレイブックのトリガー。
- 手動操作へのフォールバック。
- トレーニングとカルチャの変化。
重要
ワークロードを設計、実装、運用、進化させる個人は、適格であることが求められ、懸念がある場合は発言し、システムに対する責任感を持つことが奨励される必要があります。
人間中心のリスク コントロールは、多くの場合、テクノロジベースのコントロールよりもスピードが遅く、人為的なエラーが発生しやすいため、適切なビジネス継続性計画には、実行中のシステムの状態を変更するあらゆるものに対する正式な変更制御プロセスを含める必要があります。 たとえば、次のプロセスを実装することを検討してください。
- ワークロードの重要度に従って、ワークロードを厳密にテストします。 変更関連の問題を防ぐには、ワークロードに加えられた変更を必ずテストしてください。
- ワークロードの安全なデプロイ プラクティスの一環として、戦略的な品質ゲートを導入します。 詳細については、「安全なデプロイの実践に関する推奨事項」を参照してください。
- アドホックな運用アクセスとデータ操作の手順を形式化します。 これらのアクティビティは、どんなに軽微であっても、信頼性インシデントを引き起こす高いリスクを伴う可能性があります。 手順には、別のエンジニアとのペアリング、チェックリストの使用、スクリプトの実行または変更の適用前のピア レビューの実施が含まれる場合があります。
高可用性
高可用性とは、一時的な障害や断続的な障害が発生した場合でも、特定のワークロードが必要なレベルのアップタイムを日常的に維持できる状態です。 これらのイベントは定常的に発生するため、各ワークロードは、特定のアプリケーションの要件と顧客の期待事項に従って、高可用性を実現するように設計および構成されていることが重要です。 各ワークロードの HA は、ビジネス継続性計画に影響します。
HA はワークロードごとに異なる可能性があるため、高可用性を決定する際に要件と顧客の期待事項を理解することが重要です。 たとえば、組織がオフィス用品の注文に使用するアプリケーションで必要なアップタイムは、比較的低レベルになる可能性があります。一方、重要な金融アプリケーションでは、はるかに高いアップタイムが必要になるでしょう。 ワークロード内であっても、"フロー" によって要件が異なる場合があります。 たとえば、eコマース アプリケーションでは、顧客の閲覧と注文をサポートするフローが、注文フルフィルメント フローやバックオフィス処理フローよりも重要になるでしょう。 フローの詳細については、「フローの識別と評価に関する推奨事項」を参照してください。
一般的に、アップタイムは稼働状態の割合を示す "稼働率" の桁数に基づいて測定されます。 アップタイムの割合は、特定の期間に許容されるダウンタイムの量に関係します。 次に例をいくつか示します。
- 99.9% のアップタイム要件 (スリー ナイン) では、1 か月に約 43 分間のダウンタイムが許容されます。
- 99.95% のアップタイム要件 (スリー アンド ハーフ ナイン) では、1 か月に約 21 分間のダウンタイムが許容されます。
アップタイム要件が高いほど、障害に対する許容度が低くなり、そのレベルの可用性に到達するために必要な作業が多くなります。 アップタイムは、ノードのような 1 つのコンポーネントの稼働状態ではなく、ワークロード全体の全体的な可用性で測定されます。
重要
妥当なレベル以上に高い信頼性レベルに達するようにソリューションを過剰に設計しないでください。 ビジネス要件を使用して意思決定を導きます。
高可用性の設計要素
HA 要件を達成するために、ワークロードに多数の設計要素が含まれることがあります。 このセクションでは一般的な要素の一部を以下に示して説明します。
Note
一部のワークロードは "ミッション クリティカル" です。つまり、ダウンタイムが人間の生命と安全に重大な影響を与えたり、大きな財政的損失を招いたりする可能性があります。 ミッション クリティカルなワークロードを設計する場合、ソリューションを設計してビジネス継続性を管理するときに考慮する必要がある特定の事項があります。 詳細については、「Azure Well-Architected Framework: ミッション クリティカルなワークロード」を参照してください。
高可用性をサポートする Azure のサービスとレベル
多くの Azure サービスは高可用性を実現するように設計されており、可用性の高いワークロードの構築に使用できます。 次に例をいくつか示します。
- Azure Virtual Machine Scale Sets は、VM インスタンスを自動的に作成および管理し、それらの VM インスタンスを分散してインフラストラクチャ障害の影響を軽減することで、仮想マシン (VM) の高可用性を実現します。
- Azure App Service は、異常なノードから正常なノードにワーカーを自動的に移動したり、多くの一般的な障害の種類から自己復旧する機能 (self-healing) を提供するなど、さまざまな方法で高可用性を実現します。
それぞれのサービス信頼性ガイドを使用してサービスの機能を理解し、使用するレベルを決め、高可用性戦略に含める機能を決定します。
各サービスのサービス レベル アグリーメント (SLA) を確認して、予想される可用性レベルと満たす必要がある条件を理解します。 特定のレベルの可用性を実現するには、特定のレベルのサービスを選択または回避することが必要になる場合があります。 Microsoft の一部のサービスは、SLA が提供されない (開発レベルや Basic レベルなど)、または実行中のシステムにリソースが再要求される可能性がある (スポットベースのオファリングなど) ことを前提に提供されています。 また、一部のレベルでは、可用性ゾーンのサポートなどの信頼性機能が追加されています。
フォールト トレランス
フォールト トレランスは、障害が発生した場合に、一定の定義済みキャパシティでシステムの動作を継続する機能です。 たとえば、Web アプリケーションは、1 つの Web サーバーで障害が発生した場合でも動作を継続するように設計されている場合があります。 フォールト トレランスは、冗長性、フェールオーバー、パーティション分割、適切なサービス レベルの低下、その他の手法によって実現できます。
フォールト トレランスでは、アプリケーションが一時的な障害を処理することも必要です。 独自のコードをビルドするときに、一時的な障害処理を自分で有効にすることが必要になる場合があります。 一部の Azure サービスでは、状況によっては一時的な障害処理が組み込まれています。 たとえば、既定では、Azure Logic Apps は失敗した要求を他のサービスに対して自動的に再試行します。 詳細については、「一時的な障害を処理するための推奨事項」を参照してください。
冗長性
冗長性とは、インスタンスまたはデータを複製してワークロードの信頼性を高めるプラクティスです。
冗長性を実現するには、レプリカまたは冗長インスタンスを次の 1 つ以上の方法で分散します。
- データセンター内 ("ローカル冗長")
- リージョン内の可用性ゾーン間 ("ゾーン冗長")
- リージョン間 ("geo 冗長")。
一部の Azure サービスで冗長オプションがどのように提供されているかの例をいくつか次に示します。
- Azure App Service を使用すると、アプリケーションの複数のインスタンスを実行して、1 つのインスタンスで障害が発生した場合でもアプリケーションが利用可能な状態を維持できます。 ゾーン冗長を有効にした場合、これらのインスタンスは、使用する Azure リージョン内の複数の可用性ゾーンに分散されます。
- Azure Storage は、少なくとも 3 回データを自動的にレプリケートすることで高可用性を実現します。 ゾーン冗長ストレージ (ZRS) を有効にすることで、それらのレプリカを可用性ゾーン間で分散できます。また、多くのリージョンでは、geo 冗長ストレージ (GRS) を使用してリージョン間でストレージ データをレプリケートすることもできます。
- Azure SQL Database には複数のレプリカがあり、1 つのレプリカで障害が発生した場合でもデータを確実に利用可能に維持できます。
冗長性の詳細については、「冗長性のための設計に関する推奨事項」および「可用性ゾーンとリージョンを使用するための推奨事項」を参照してください。
スケーラビリティと弾力性
スケーラビリティと弾力性は、リソースの追加と削除によって増加した負荷を処理し (スケーラビリティ)、要件の変化に合わせて迅速に行う (弾力性) システムの機能です。 スケーラビリティと弾力性は、ピーク負荷時にシステムの可用性を維持するのに役立ちます。
スケーラビリティは多くの Azure サービスでサポートされています。 次に例をいくつか示します。
- Azure Virtual Machine Scale Sets、Azure API Management、および他のいくつかのサービスでは、Azure Monitor の自動スケーリングがサポートされています。 Azure Monitor の自動スケーリングを使用すると、"CPU が一貫して 80% を超えたら別のインスタンスを追加する" などのポリシーを指定できます。
- Azure Functions では、要求を処理するためにインスタンスを動的にプロビジョニングできます。
- Azure Cosmos DB では、自動スケーリング スループットがサポートされており、指定したポリシーに基づいて、データベースに割り当てられたリソースをシステムで自動的に管理できます。
スケーラビリティは、部分的または完全な誤動作時に考慮すべき重要な要素です。 レプリカまたはコンピューティング インスタンスが使用不可になった場合は、障害が発生したノードで以前処理されていた負荷を処理するために、残りのコンポーネントの負荷を増やすことが必要になる場合があります。 システムが負荷の予想される変更を処理するのに十分な速さでスケーリングできない場合は、"オーバープロビジョニング" を検討してください。
スケーラブルで弾力性のあるシステムを設計する方法の詳細については、「信頼性の高いスケーリング戦略を設計するための推奨事項」を参照してください。
ダウンタイムなしのデプロイ手法
デプロイやその他のシステム変更により、ダウンタイムの重大なリスクが生じます。 ダウンタイムのリスクは高可用性の要件の課題であるため、ダウンタイムなしのデプロイ プラクティスを使用して、ダウンタイムを必要としない更新と構成の変更を行うことが重要です。
ダウンタイムなしのデプロイ手法には、次のようなものがあります。
- リソースのサブセットを一度に更新する。
- 新しいデプロイに到達するトラフィックの量を制御する。
- ユーザーまたはシステムへの影響を監視する。
- 以前の既知の適切なデプロイにロールバックするなどして、問題を迅速に修復する。
ダウンタイムなしのデプロイ手法の詳細については、「安全なデプロイ プラクティス」を参照してください。
Azure 自体、その独自のサービスにダウンタイムなしのデプロイ アプローチを使用しています。 ご自身の独自アプリケーションをビルドする場合は、次のようなさまざまな方法でダウンタイムなしのデプロイを採用できます。
- Azure Container Apps では、アプリケーションの複数のリビジョンが提供され、ダウンタイムなしのデプロイを実現するために使用できます。
- Azure Kubernetes Service (AKS) では、ダウンタイムなしのさまざまなデプロイ手法がサポートされています。
ダウンタイムなしのデプロイは、多くの場合、アプリケーションのデプロイに関連しますが、構成変更の場合にも使用する必要があります。 構成変更を安全に適用する方法を次に示します。
- Azure Storage を使用すると、ストレージ アカウントのアクセス キーを複数のステージで変更できるため、キー ローテーション操作中のダウンタイムを防ぐことができます。
- Azure App Configuration には機能フラグ、スナップショットに加えて、構成変更の適用方法を制御するのに役立つその他の機能が用意されています。
ダウンタイムなしのデプロイを実装しない場合は、"メンテナンス ウィンドウ" を定義して、ユーザーが予期したタイミングでシステムを変更できます。
自動テスト
HA のスコープ内にあると考えられる停止や障害に耐えるソリューションの能力をテストすることが重要です。 これらの障害の多くは、テスト環境でシミュレートできます。 さまざまな種類の障害を自動的に許容または復旧するソリューションの機能をテストすることは、"カオス エンジニアリング" と呼ばれます。 カオス エンジニアリングは、HA の厳格な標準を持つ成熟した組織にとって重要です。 Azure Chaos Studio は、一般的な障害の種類をシミュレートできるカオス エンジニアリング ツールです。
詳細については、「信頼性テスト戦略を設計するための推奨事項」を参照してください。
監視とアラート
監視を使用すると、自動化された軽減策が実行された場合でも、システムの正常性を把握できます。 監視は、ソリューションがどのように動作しているかを理解し、エラー率の増加やリソース消費量の増加などの障害の早期シグナルを監視するために重要です。 アラートを使用すると、環境内の重要な変化を事前に受け取ることができます。
Azure には、次のようなさまざまな監視とアラート機能が用意されています。
- Azure Monitor は Azure のリソースとアプリケーションからログとメトリックを収集し、アラートを送信してダッシュボードにデータを表示できます。
- Azure Monitor Application Insights では、アプリケーションの詳細な監視が提供されます。
- Azure Service Health と Azure Resource Health は、Azure プラットフォームとリソースの正常性を監視します。
- Scheduled Events は、仮想マシンのメンテナンスがいつ予定されているかを知らせます。
詳細については、「信頼性の高い監視およびアラート戦略を設計するための推奨事項」を参照してください。
障害復旧
"災害" は、アプリケーションの設計上の高可用性の側面によって軽減できる影響よりも大きく、影響が長く続く、明確でまれな重大なイベントです。 災害の例を次に示します。
- 自然災害 (ハリケーン、地震、洪水、火災など)。
- 誤って運用環境のデータを削除したり、ファイアウォールの設定ミスにより機密データが公開されたりするなど、重大な影響をもたらす人為的エラー。
- サービス拒否やランサムウェア攻撃のように、データの破損、データ損失、サービスの停止につながる重大なセキュリティ インシデント。
"ディザスター リカバリー" では、このような状況にどのように対応するかを計画します。
Note
これらのイベントが発生する可能性を最小限に抑えるには、ソリューション全体で推奨されるプラクティスに従う必要があります。 ただし、慎重に事前に計画した後でも、このような状況が発生した場合の対応方法を計画することをお勧めします。
ディザスター リカバリーの要件
災害の発生頻度と深刻度により、DR 計画では対応に対する期待が異なります。 多くの組織は、災害シナリオでは、ある程度のダウンタイムやデータ損失は避けられないという事実を受け入れます。 完全な DR 計画では、各フローに対して次の重要なビジネス要件を指定する必要があります。
回復ポイントの目標 (RPO) は、災害発生時に許容できるデータ損失の最大期間です。 RPO は、"30 分間のデータ" や "4 時間のデータ" など、時間単位で測定されます。
目標復旧時間 (RTO) は、災害発生時に許容されるダウンタイムの最大継続時間です。"ダウンタイム" は仕様によって定義されます。 RTO は、"8 時間のダウンタイム" のように、時間単位でも測定されます。
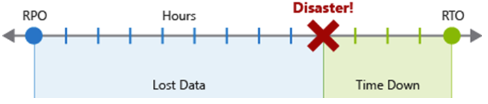
ワークロード内の各コンポーネントまたはフローには、個々の RPO 値と RTO 値が存在する場合があります。 要件を決定する際に、ディザスター シナリオのリスクと潜在的な復旧戦略を調べます。 RPO と RTO を指定するプロセスにより、固有のビジネス上の懸念事項 (コスト、影響、データ損失など) の結果として、ワークロードの DR 要件が効果的に作成されます。
Note
RTO と RPO ゼロ (障害発生時のダウンタイムやデータ損失なし) を目指したくなる一方で、実際には実装が困難でコストがかかります。 技術的およびビジネスの利害関係者がこれらの要件について一緒に話し合い、現実的な要件を決定することが重要です。 詳細については、「信頼性目標の定義に関する推奨事項」を参照してください。
ディザスター リカバリー計画
障害の原因に関係なく、明確に定義されたテスト可能な DR 計画を作成することが重要です。 この計画は、それを積極的にサポートするためのインフラストラクチャとアプリケーション設計の一部として使用されます。 さまざまな種類の状況に対して複数の DR 計画を作成できます。 DR 計画は、多くの場合、プロセス制御と手動介入に依存します。
DR は Azure の自動機能ではありません。 ただし、多くのサービスには、DR 戦略をサポートするために使用できる機能が用意されています。 各 Azure サービスの信頼性ガイドを確認して、サービスのしくみとその機能を理解し、それらの機能を DR 計画にマップする必要があります。
次のセクションでは、ディザスター リカバリー 計画の一般的な要素の一覧を示し、それらを実現するために Azure がどのように役立つかについて説明します。
フェールオーバーとフェールバック
一部のディザスター リカバリー計画では、別の場所にセカンダリ デプロイをプロビジョニングする必要があります。 障害によってソリューションのプライマリ デプロイに影響があった場合、トラフィックは他のサイトに "フェールオーバー" されます。 フェールオーバーには慎重な計画と実装が必要です。 Azure には、フェールオーバーを支援する次のようなさまざまなサービスが用意されています。
- Azure Site Recovery では、オンプレミス環境と Azure の仮想マシンでホストされるソリューションの自動フェールオーバーが提供されます。
- Azure Front Door と Azure Traffic Manager では、異なるリージョンなど、ソリューションのさまざまなデプロイ間の受信トラフィックの自動フェールオーバーがサポートされます。
通常、プライマリ インスタンスが失敗したことを検出してセカンダリ インスタンスに切り替えるには、フェールオーバー プロセスに時間がかかります。 ワークロードの RTO がフェールオーバー時間と整合性があることを確認します。
また、"フェールバック" を検討することも重要です。これは、復旧後にプライマリ リージョンに操作を復元するプロセスです。 フェールバックは、計画と実装が複雑になる場合があります。 たとえば、プライマリ リージョンのデータは、フェールオーバーが始まった "後" に書き込まれた可能性があります。 そのデータの処理方法について慎重にビジネス上の意思決定を行う必要があります。
バックアップ
バックアップには、データのコピーを取得し、定義された期間、それを安全に保存することが含まれます。 バックアップを使用すると、別のレプリカへの自動フェールオーバーが不可能な場合や、データの破損が発生した場合に、災害から復旧できます。
ディザスター リカバリー計画の一部としてバックアップを使用する場合は、次の点を考慮することが重要です。
保存場所。 ディザスター リカバリー計画の一部としてバックアップを使用する場合は、メイン データに個別に保存する必要があります。 通常、バックアップは別の Azure リージョンに保存されます。
"データ損失"。 一般にバックアップは頻繁には作成されないため、バックアップの復元には通常、データの損失が伴います。 このため、バックアップ復旧は最後の手段として使用する必要があり、ディザスター リカバリー計画では、バックアップから復元する "前" に実行しなければならない一連の手順と復旧の試行を指定する必要があります。 ワークロード RPO がバックアップ間隔と整合していることを確認することが重要です。
"復旧時間"。 多くの場合、バックアップの復元には時間がかかるため、バックアップと復元プロセスをテストして整合性を確認し、復元プロセスにかかる時間を把握することが重要です。 ワークロードの RTO がバックアップの復元にかかる時間を考慮していることを確認します。
多くの Azure データおよびストレージ サービスでは、次のようなバックアップがサポートされています。
- Azure Backup では、仮想マシン ディスク、ストレージ アカウント、AKS、およびその他のさまざまなソースの自動バックアップが提供されます。
- Azure SQL Database や Azure Cosmos DB を含む多くの Azure データベース サービスには、データベースの自動バックアップ機能があります。
- Azure Key Vault には、シークレット、証明書、キーをバックアップする機能が用意されています。
自動化されたデプロイ
障害発生時に必要なリソースを迅速にデプロイして構成するには、Bicep ファイル、ARM テンプレート、Terraform 構成ファイルなどのコードとしてのインフラストラクチャ (IaC) 資産を使用します。 IaC を使用すると、リソースを手動でデプロイおよび構成する場合と比較して、復旧時間が短縮され、エラーが発生する可能性が減ります。
テストとドリル
DR 計画と、より広範な信頼性戦略を定期的に検証してテストすることが重要です。 ドリルにすべての人間のプロセスを含め、技術的なプロセスだけに焦点を当てないでください。
ディザスター シミュレーションで復旧プロセスをテストしていない場合は、実際の災害で使用するときに大きな問題に直面する可能性が高くなります。 また、DR 計画と必要なプロセスをテストすることで、RTO の実現可能性を検証できます。
詳細については、「信頼性テスト戦略を設計するための推奨事項」を参照してください。
関連するコンテンツ
- Azure サービス信頼性ガイドを使用して各 Azure サービスがその設計における信頼性をどのようにサポートしているかを理解し、HA および DR プランに組み込むことができる機能について学習します。
- Azure で信頼性の高いワークロードを設計する方法の詳細については、「Azure Well-Architected フレームワーク: 信頼性の柱」を参照してください。
- 「Azure サービスに関する Well-Architected フレームワークの観点」を使用して、信頼性の要件を満たすように、Well-Architected フレームワークの他の柱全体にわたって各 Azure サービスを構成する方法の詳細を確認します。
- ディザスター リカバリー計画の詳細については、「ディザスター リカバリー戦略の設計に関する推奨事項」を参照してください。