Azure Database for PostgreSQL - フレキシブル サーバーで実行速度が遅いクエリをトラブルシューティングして特定する
適用対象:  Azure Database for PostgreSQL - フレキシブル サーバー
Azure Database for PostgreSQL - フレキシブル サーバー
この記事では、実行速度が遅いクエリの根本原因を特定して診断する方法について説明します。
この記事では、次の内容について説明します。
- 実行速度が遅いクエリを特定する方法。
- それと併せて実行速度が遅いプロシージャを識別する方法。 実行速度が遅い同じストアド プロシージャに属するクエリのリストから、低速クエリを特定します。
前提条件
トラブルシューティング ガイドの使用に関する記事で説明されている手順に従って、トラブルシューティング ガイドを有効にします。
auto_explain拡張機能を構成した後、拡張機能の動作を制御する次のサーバー パラメーターを変更します。auto_explain.log_analyzeからON。auto_explain.log_buffersからON。auto_explain.log_min_duration: 実際のシナリオに従って妥当な値。auto_explain.log_timingからON。auto_explain.log_verboseからON。


Note
auto_explain.log_min_duration を 0 に設定すると、拡張機能はサーバー上で実行されるすべてのクエリのログを開始します。 これは、データベースのパフォーマンスに影響する可能性があります。 サーバーで低速と見なされる値に対して適切なデュー デリジェンスを行う必要があります。 たとえば、すべてのクエリが 30 秒未満で完了し、それがアプリケーションで許容される場合は、パラメーターを 3,0000 ミリ秒に更新することをお勧めします。 このようにすると、完了するまでに 30 秒より長くかかったすべてのクエリがログされます。
遅いクエリを特定する
トラブルシューティング ガイドと auto_explain 拡張機能を使えるようにしたので、例を使ってシナリオを説明します。
このシナリオでは、CPU の使用率が 90% に急上昇することがあり、急上昇の原因を明らかにする必要があります。 このシナリオのデバッグは、次の手順に従って行います。
CPU のシナリオによるアラートを受け取ったらすぐに、Azure Database for PostgreSQL フレキシブル サーバーの影響を受けたインスタンスのリソース メニューの [監視] セクションで、[トラブルシューティング ガイド] を選びます。
![[トラブルシューティング ガイド] メニュー オプションのスクリーンショット。](media/how-to-identify-slow-queries/troubleshooting-guides-blade.png)
[CPU] タブを選びます。[高い CPU 使用率の最適化] トラブルシューティング ガイドが開きます。
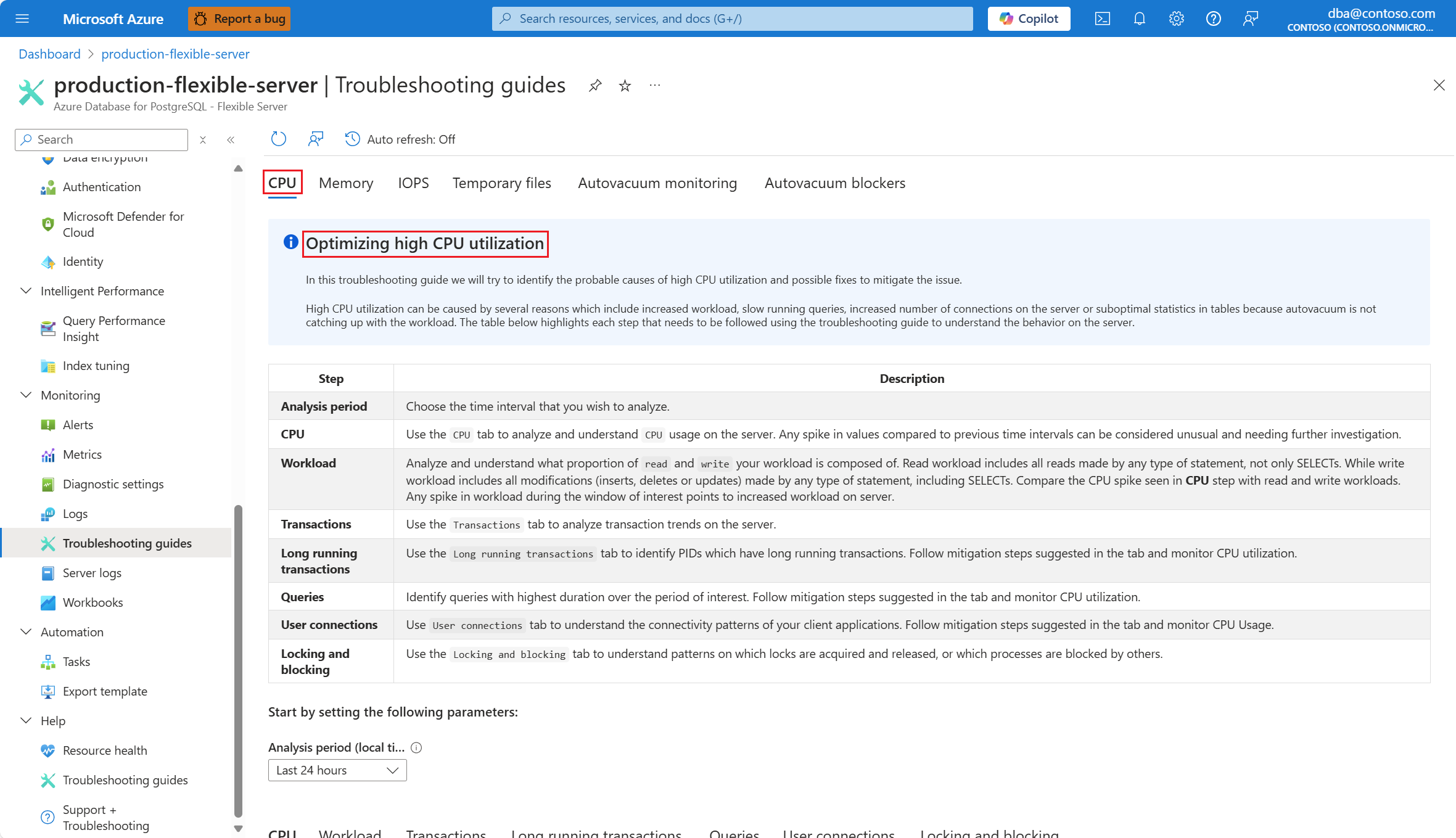
[分析期間 (ローカル時刻)] ドロップダウンから、分析対象の時間範囲を選びます。
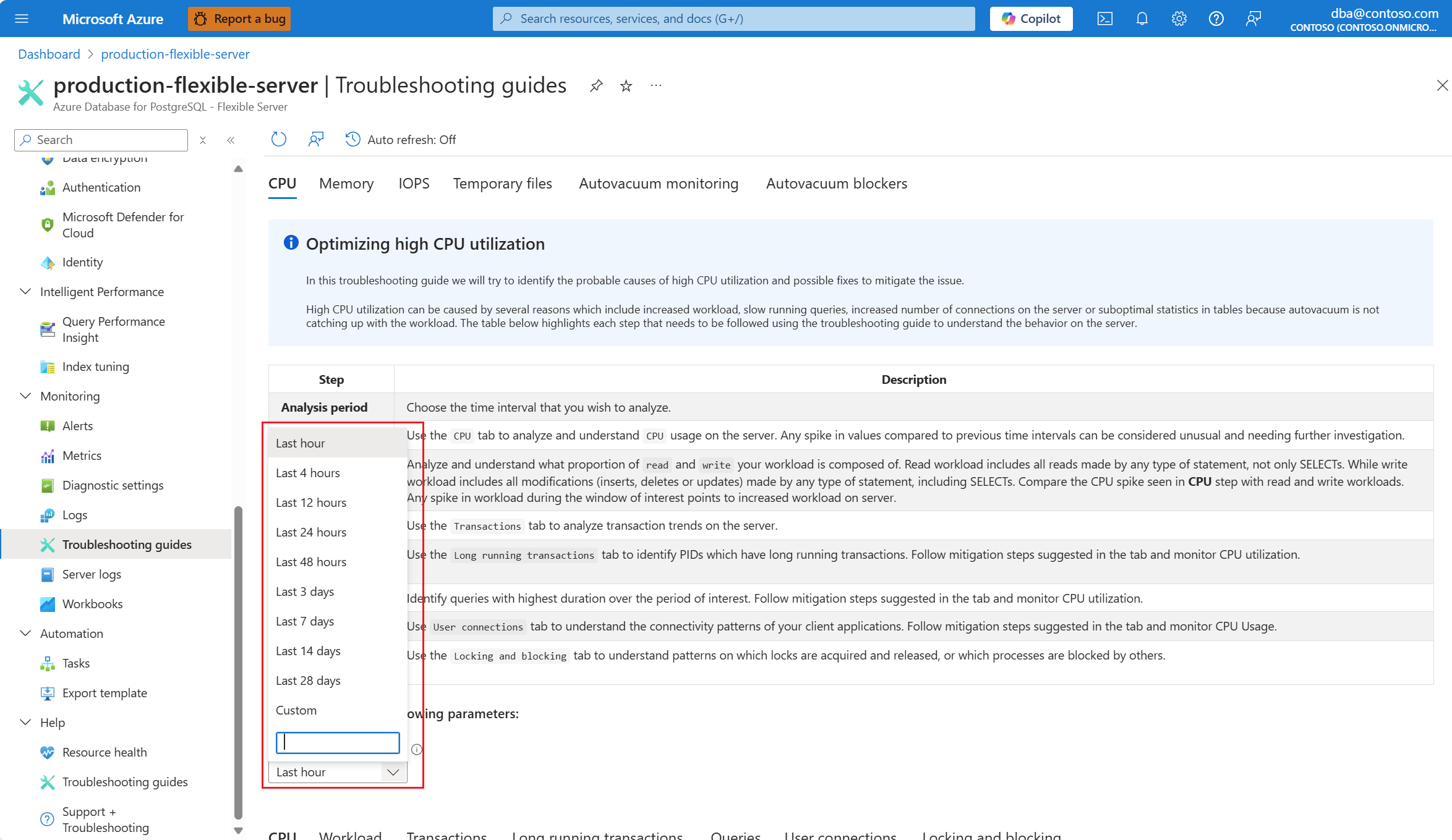
[クエリ] タブを選びます。ここには、CPU の使用率が 90% になった期間に実行されていすべてのクエリの詳細が示されます。 スナップショットから、期間中に平均実行時間が最も遅かったクエリは約 2.6 分で、そのクエリは期間中に 22 回実行されたことがわかります。 それが、CPU の急上昇の原因である可能性が最も高いクエリです。
実際のクエリ テキストを取得するには、
azure_sysデータベースに接続して、次のクエリを実行します。
![[トラブルシューティング ガイド] メニュー オプションのスクリーンショット。](media/how-to-identify-slow-queries/troubleshooting-guides-blade.png#lightbox)



psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- ここで検討している例では、次のクエリが遅かったことがわかりました。
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
生成された正確な説明プランを把握するには、Azure Database for PostgreSQL フレキシブル サーバーのログを使います。 その期間中にクエリの実行が完了するたびに、
auto_explain拡張機能によってログにエントリが書き込まれているはずです。 リソース メニューの [監視] セクションで、[ログ] を選びます。
90% の CPU 使用率が見つかった時間範囲を選択します。
次のクエリを実行して、特定されたクエリに対する EXPLAIN ANALYZE の出力を取得します。

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
メッセージ列には、次の出力で示すような実行プランが格納されています。
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
トラブルシューティング ガイドで示されているように、クエリは約 2.5 分間実行されました。 フェッチされた実行プランの出力に含まれる 150692.864 ミリ秒という duration の値によってそれが確認されます。 EXPLAIN ANALYZE の出力を使ってさらにトラブルシューティングを行い、クエリを調整します。
Note
クエリは期間中に 22 回実行され、示されているログには期間中にキャプチャされたそのようなエントリの 1 つが含まれることに注意してください。
ストアド プロシージャで実行が遅いクエリを特定する
トラブルシューティング ガイドと auto_explain 拡張機能を有効にしたので、例を用いてシナリオを説明します。
このシナリオでは、CPU の使用率が 90% に急上昇することがあり、急上昇の原因を明らかにする必要があります。 このシナリオのデバッグは、次の手順に従って行います。
CPU のシナリオによるアラートを受け取ったらすぐに、Azure Database for PostgreSQL フレキシブル サーバーの影響を受けたインスタンスのリソース メニューの [監視] セクションで、[トラブルシューティング ガイド] を選びます。
[CPU] タブを選びます。[高い CPU 使用率の最適化] トラブルシューティング ガイドが開きます。
[分析期間 (ローカル時刻)] ドロップダウンから、分析対象の時間範囲を選びます。
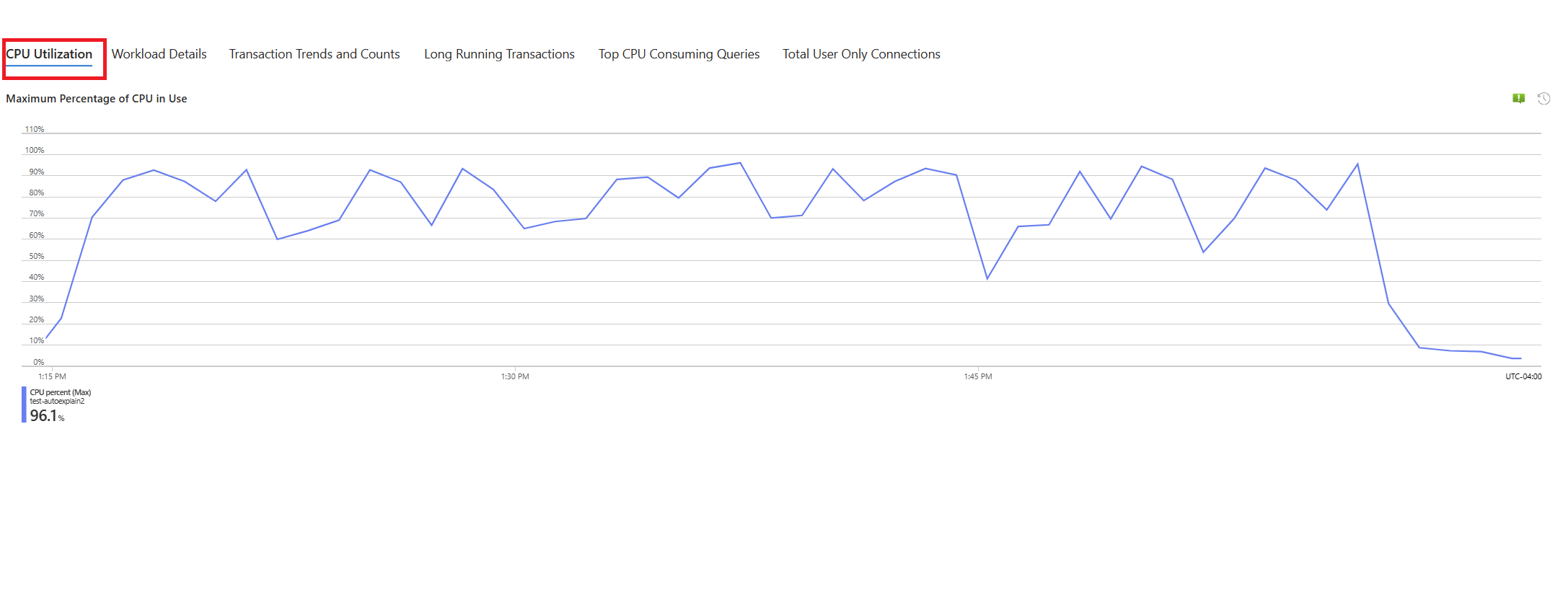
[クエリ] タブを選びます。ここには、CPU の使用率が 90% になった期間に実行されていすべてのクエリの詳細が示されます。 スナップショットから、期間中に平均実行時間が最も遅かったクエリは約 2.6 分で、そのクエリは期間中に 22 回実行されたことがわかります。 それが、CPU の急上昇の原因である可能性が最も高いクエリです。
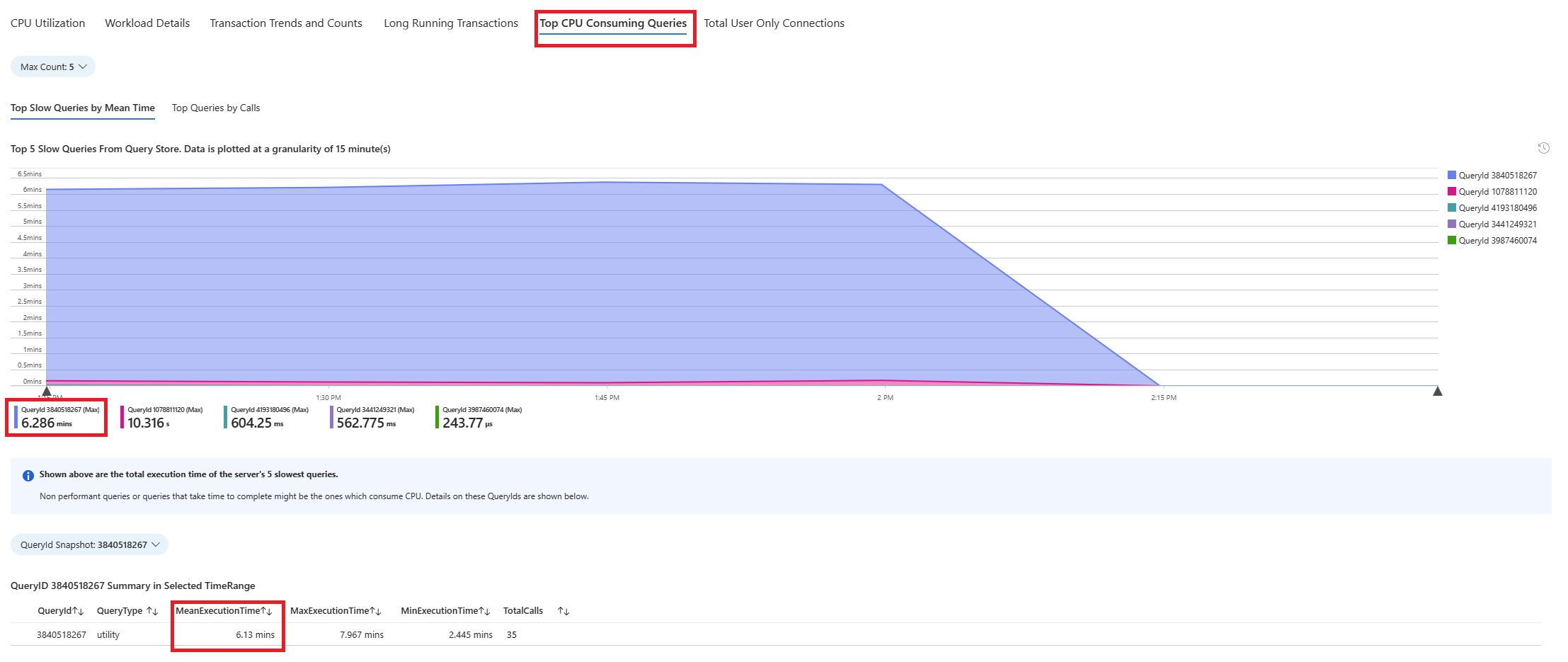
次のスクリプトを使用して、azure_sys データベースに接続し、クエリを実行して実際のクエリ テキストを取得します。


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- この検討例では、遅いことがわかったクエリはストアド プロシージャでした。
call autoexplain_test ();
- 生成された正確な説明プランを把握するには、Azure Database for PostgreSQL フレキシブル サーバーのログを使います。 その期間中にクエリの実行が完了するたびに、
auto_explain拡張機能によってログにエントリが書き込まれているはずです。 リソース メニューの [監視] セクションで、[ログ] を選びます。 次に、[時間範囲:] で分析対象の期間を選びます。

- 次のクエリを実行して、特定したクエリの説明分析出力を取得します。
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
このプロシージャにはクエリが複数あり、以下に強調表示されています。 ストアド プロシージャで使用されるすべてのクエリの説明分析出力が、さらに分析し、トラブルシューティングするためにログに記録されます。 ログに記録されるクエリの実行時間を使用して、ストアド プロシージャの一部である最も遅いクエリを特定できます。
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
Note
デモが目的のため、プロシージャで使われているいくつかのクエリについてだけ EXPLAIN ANALYZE の出力が示されています。 このようにすると、ログからすべてのクエリの EXPLAIN ANALYZE の出力を収集し、その中で最も遅いものを特定して調整を試みることができます。
関連するコンテンツ
- Azure Database for PostgreSQL の CPU 使用率が高い場合のトラブルシューティング - フレキシブル サーバー。
- Azure Database for PostgreSQL - フレキシブル サーバーで IOPS 使用率が高い場合のトラブルシューティング。
- Azure Database for PostgreSQL - フレキシブル サーバーの高いメモリ使用率のトラブルシューティング。
- Azure Database for PostgreSQL - フレキシブル サーバーのサーバー パラメーター。
- Azure Database for PostgreSQL - フレキシブル サーバーでの自動バキュームのチューニング。