Azure Database for MySQL - フレキシブル サーバーのデータイン レプリケーションを構成する方法
適用対象:  Azure Database for MySQL - フレキシブル サーバー
Azure Database for MySQL - フレキシブル サーバー
この記事では、ソースとレプリカのサーバーを構成することによって、Azure Database for MySQL フレキシブル サーバーでデータイン レプリケーションを設定する方法について説明します。 この記事は、MySQL サーバーとデータベースに関して、ある程度の使用経験があることを前提としています。
Note
この記事には、Microsoft が使用しなくなった "スレーブ" という用語への言及が含まれています。 ソフトウェアからこの用語が削除された時点で、この記事から削除します。
Azure Database for MySQL フレキシブル サーバー インスタンスでレプリカを作成するために、データイン レプリケーションによって、オンプレミス、仮想マシン (VM)、またはクラウド データベース サービスのソース MySQL サーバーからデータが同期されます。 データイン レプリケーションは、バイナリ ログ (binlog) ファイルの位置ベースのレプリケーションまたは GTID ベースのレプリケーションを使用して構成できます。 binlog レプリケーションの詳細については、MySQL レプリケーションに関するページを参照してください。
この記事の手順を実行する前に、データイン レプリケーションの制限事項と要件を確認してください。
レプリカとして使用する Azure Database for MySQL フレキシブル サーバー インスタンスを作成する
Azure Database for MySQL フレキシブル サーバーの新しいインスタンスを作成します (例:
replica.mysql.database.azure.com)。 サーバーの作成については、Azure portal を使用して Azure Database for MySQL フレキシブル サーバー インスタンスを作成する方法に関するページを参照してください。 このサーバーは、データイン レプリケーション用の "レプリカ" サーバーです。同じユーザー アカウントとそれに対応する権限を作成します。
レプリカ サーバーにソース サーバーのユーザー アカウントはレプリケートされません。 レプリカ サーバーへのアクセス権をユーザーに与えることを検討している場合、この新しく作成した Azure Database for MySQL フレキシブル サーバー インスタンスに、すべてのアカウントとそれらに対応する権限を手動で作成する必要があります。
ソース MySQL サーバーを構成する
次の手順では、仮想マシンでオンプレミスでホストされる MySQL サーバーを準備して構成するか、データイン レプリケーションのために他のクラウド プロバイダーによってホストされるデータベース サービスを準備して構成します。 このサーバーは、データイン レプリケーション用の "ソース" となります。
続行する前に、ソース サーバーの要件をご確認ください。
ネットワーク要件
ソース サーバーでポート 3306 での受信と送信の両方のトラフィックが許可されていて、それに対してパブリック IP アドレスが割り当てられている、または DNS にパブリックにアクセス可能である、あるいは完全修飾ドメイン名 (FQDN) があることを確かめます。
プライベート アクセス (VNet 統合) が使用されている場合は、ソース サーバーと、レプリカ サーバーがホストされている VNet との間に接続が確立されていることを確認します。
ExpressRoute または VPN のどちらかを使用して、オンプレミスのソース サーバーへのサイト間接続が提供されていることを確認します。 仮想ネットワークの作成方法の詳細については、Virtual Network のドキュメントを参照してください。特に、詳細な手順が記載されたクイックスタートの記事を参照してください。
レプリカ サーバーでプライベート アクセス (VNet 統合) が使用され、ソースが Azure VM の場合は、VNet 間接続が確立されていることを確認します。 VNet 間のピアリングがサポートされています。 異なるリージョンにわたる VNet 間で通信するために、VNet 間接続など他の接続方法を使用することもできます。 詳細については、VNet 間 VPN ゲートウェイに関するページを参照してください
仮想ネットワークのネットワーク セキュリティ グループ規則で、送信ポート 3306 がブロックされていないことを確認します (MySQL が Azure VM で実行されている場合は受信ポートも)。 仮想ネットワークの NSG トラフィックのフィルター処理の詳細については、ネットワーク セキュリティ グループによるネットワーク トラフィックのフィルター処理に関する記事を参照してください。
レプリカ サーバーの IP アドレスを許可するようにソース サーバーのファイアウォール規則を構成します。
bin-log の位置または GTID ベースのデータイン レプリケーションのどちらを使用するかに基づいて、適切な手順に従います。
ソースでバイナリ ログが有効になっているかどうかを、次のコマンドを実行してチェックします。
SHOW VARIABLES LIKE 'log_bin';変数
log_binの戻り値が "ON" であった場合、サーバーでバイナリ ログが有効になっています。値 "オフ" で
log_binが返されたとき、構成ファイル (my.cnf) にアクセスするオンプレミスまたは仮想マシン上でソース サーバーが実行されている場合、以下の手順をご利用いただけます。ソース サーバーで MySQL 構成ファイル (my.cnf) を見つけます。 例: /etc/my.cnf
構成ファイルを開いて編集し、ファイル内の mysqld セクションを見つけます。
mysqld セクションで、次の行を追加します。
log-bin=mysql-bin.log変更を有効にするには、ソース サーバーで MySQL サービスを再起動します (または [再起動])。
サーバーが再起動された後、前と同じクエリを実行して、バイナリ ログが有効になっていることを確認します。
SHOW VARIABLES LIKE 'log_bin';
ソース サーバーの設定を構成します。
データイン レプリケーションでは、ソース サーバーとレプリカ サーバー間でパラメーター
lower_case_table_namesが一貫している必要があります。 Azure Database for MySQL フレキシブル サーバーでは、このパラメーターが既定で 1 になっています。SET GLOBAL lower_case_table_names = 1;新しいレプリケーション ロールを作成し、権限を設定します。
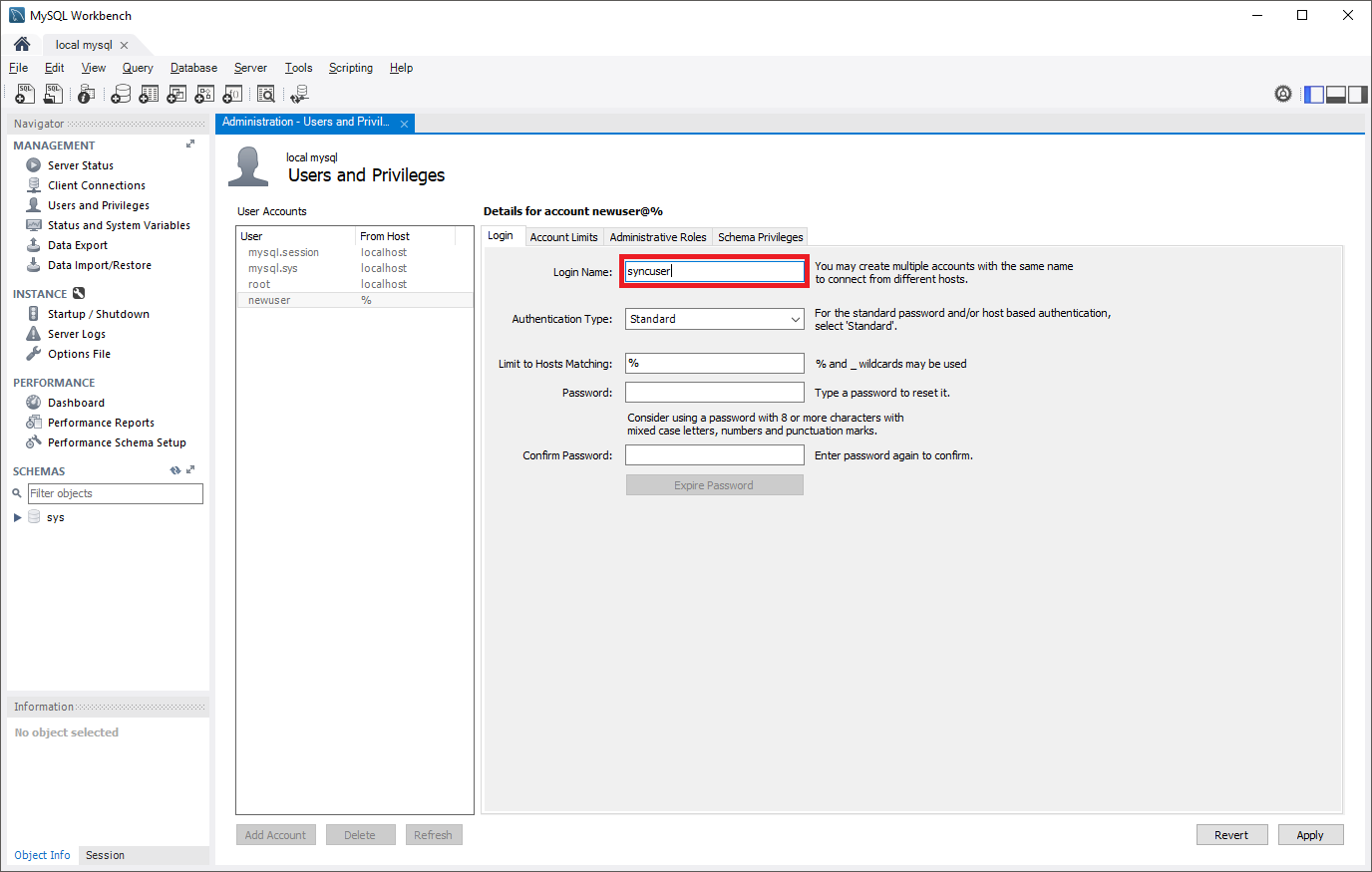
レプリケーションの権限を持つように構成されたユーザー アカウントをソース サーバーに作成します。 この作業は、SQL コマンド、または MySQL Workbench などのツールを使用して行うことができます。 SSL を使用するレプリケートを計画するかどうかを検討してください。これはユーザーを作成するときに指定する必要があります。 ソース サーバーにユーザー アカウントを追加する方法については、MySQL のドキュメントを参照してください。
次のコマンドでは、作成した新しいレプリケーション ロールを使用すると、ソース自体をホストするマシンだけでなく、任意のマシンからソースにアクセスできます。 そのため、create user コマンドには "syncuser@'%'" を指定しています。 アカウント名の指定について詳しくは、MySQL のドキュメントをご覧ください。
SSL を使用したレプリケーション
すべてのユーザー接続に SSL を要求するには、次のコマンドを使用してユーザーを作成します。
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword'; GRANT REPLICATION SLAVE ON *.* TO ' syncuser'@'%' REQUIRE SSL;SSL を使用しないレプリケーション
必ずしもすべての接続に SSL が必要でない場合は、次のコマンドを使用してユーザーを作成します。
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword'; GRANT REPLICATION SLAVE ON *.* TO ' syncuser'@'%';ソース サーバーを読み取り専用モードに設定します。
データベースのダンプを開始する前に、サーバーを読み取り専用モードにする必要があります。 読み取り専用モードの間、ソースは書き込みトランザクションを一切処理できなくなります。 業務への影響を見積もり、必要であればピーク時を外して読み取り専用の時間帯をスケジュールしてください。
FLUSH TABLES WITH READ LOCK; SET GLOBAL read_only = ON;バイナリ ログ ファイルの名前とオフセットを取得します。
show master statusコマンドを実行して、現在のバイナリ ログ ファイルの名前とオフセットを調べます。show master status;結果は次のようになります。 バイナリ ファイルの名前はこの後の手順で使用するため、必ずメモしておいてください。

![[Users and Privileges]\(ユーザーと権限\)](media/how-to-data-in-replication/users-privileges.png)
![[Replication Slave]\(レプリケーション スレーブ\)](media/how-to-data-in-replication/replication-slave.png)
ソース サーバーのダンプと復元
Azure Database for MySQL フレキシブル サーバーにレプリケートするデータベースとテーブルを決定し、ソース サーバーからダンプを実行します。
mysqldump を使用して、プライマリ サーバーからデータベースをダンプすることができます。 詳細については、「ダンプと復元」を参照してください。 MySQL ライブラリとテスト ライブラリをダンプする必要はありません。
ソース サーバーを読み取り/書き込みモードに設定します。
データベースのダンプ後、ソース MySQL サーバーを読み取り/書き込みモードに戻します。
SET GLOBAL read_only = OFF; UNLOCK TABLES;Note
サーバーが読み取りまたは書き込みモードに戻る前に、グローバル変数 GTID_EXECUTED を使用して GTID 情報を取得できます。 レプリカ サーバーで GTID を設定するために、後のステージでもこれが使用されます。
ダンプ ファイルを新しいサーバーに復元します。
Azure Database for MySQL フレキシブル サーバーに作成したサーバーにダンプ ファイルを復元します。 ダンプ ファイルを MySQL サーバーに復元する方法については、「ダンプと復元」を参照してください。 大きいダンプ ファイルは、レプリカ サーバーと同じリージョンにある Azure 内の仮想マシンにアップロードしてください。 そのファイルを仮想マシンから Azure Database for MySQL フレキシブル サーバー インスタンスに復元します。
Note
ダンプと復元を行うときにデータベースを読み取り専用に設定したくない場合は、mydumper/mydumper を使用できます。
レプリカ サーバーで GTID を設定する
bin-log の位置ベースのレプリケーションを使用する場合は、この手順をスキップします
ターゲット (レプリカ) サーバーの GTID 履歴をリセットするには、ソースから取得されたダンプ ファイルの GTID 情報が必要です。
ソースのこの GTID 情報を使用してレプリカ サーバーで GTID リセットを実行するには、次の CLI コマンドを使用します。
az mysql flexible-server gtid reset --resource-group <resource group> --server-name <replica server name> --gtid-set <gtid set from the source server> --subscription <subscription id>
詳細については、GTID リセットに関するページを参照してください。
Note
geo 冗長バックアップが有効なサーバーでは、GTID リセットを実行できません。 サーバーで GTID リセットを実行するには、geo 冗長を無効にしてください。 GTID リセット後に geo 冗長オプションを再度有効にできます。 GTID リセット アクションにより、利用できるすべてのバックアップが無効になるため、geo 冗長を再度有効にしたとき、geo 復旧をサーバーで実行できるまで 1 日かかることがあります。
ソースとレプリカのサーバーをリンクしてデータイン レプリケーションを開始する
ソース サーバーを設定します。
データイン レプリケーションの機能は、すべてストアド プロシージャによって実現されています。 「データイン レプリケーションのストアド プロシージャ」で、すべてのプロシージャをご覧いただけます。 これらのストアド プロシージャは、MySQL シェルまたは MySQL Workbench で実行できます。
2 つのサーバーをリンクさせてレプリケーションを開始するには、Azure Database for MySQL サービスにあるレプリケーション先のレプリカ サーバーにログインし、外部インスタンスをソース サーバーとして設定します。 この設定は、Azure Database for MySQL サーバーで
mysql.az_replication_change_masterまたはmysql.az_replication_change_master_with_gtidストアド プロシージャを使用して行います。CALL mysql.az_replication_change_master('<master_host>', '<master_user>', '<master_password>', <master_port>, '<master_log_file>', <master_log_pos>, '<master_ssl_ca>');CALL mysql.az_replication_change_master_with_gtid('<master_host>', '<master_user>', '<master_password>', <master_port>,'<master_ssl_ca>');- master_host: ソース サーバーのホスト名
- master_user: ソース サーバーのユーザー名
- master_password: ソース サーバーのパスワード
- master_port: ソース サーバーで接続をリッスンしているポート番号 (3306 は MySQL でリッスンする既定のポートです)。
- master_log_file:
show master statusを実行することによって得たバイナリ ログ ファイルの名前 - master_log_pos:
show master statusを実行することによって得たバイナリ ログの位置 - master_ssl_ca:CA 証明書のコンテキスト。 SSL を使用していない場合は、空の文字列を渡します。
このパラメーターは変数で渡すことをお勧めします。 詳しくは、次の例をご覧ください。
注意
- ソース サーバーが Azure VM にホストされる場合は、[Azure サービスへのアクセスを許可] を [有効] に設定して、ソースとレプリカのサーバーが相互に通信できるようにします。 この設定は、 [接続のセキュリティ] オプションから変更できます。 詳細については、ポータルを使用したファイアウォール規則の管理に関する記事を参照してください。
- mydumper/mydumper を使用してデータベースをダンプした場合は、 /backup/metadata ファイルから master_log_file と master_log_pos を取得できます。
使用例
SSL を使用したレプリケーション
変数
@certは、次の MySQL コマンドを実行して作成します。SET @cert = '-----BEGIN CERTIFICATE----- PLACE YOUR PUBLIC KEY CERTIFICATE'`S CONTEXT HERE -----END CERTIFICATE-----'SSL を使用したレプリケーションを、ドメイン "companya.com" にホストされたソース サーバーと Azure Database for MySQL フレキシブル サーバーにホストされたレプリカ サーバーとの間で設定します。 このストアド プロシージャはレプリカで実行します。
CALL mysql.az_replication_change_master('master.companya.com', 'syncuser', 'P@ssword!', 3306, 'mysql-bin.000002', 120, @cert);CALL mysql.az_replication_change_master_with_gtid('master.companya.com', 'syncuser', 'P@ssword!', 3306, @cert);SSL を使用しないレプリケーション
SSL を使用しないレプリケーションを、ドメイン "companya.com" にホストされたソース サーバーと Azure Database for MySQL フレキシブル サーバーにホストされたレプリカ サーバーとの間で設定します。 このストアド プロシージャはレプリカで実行します。
CALL mysql.az_replication_change_master('master.companya.com', 'syncuser', 'P@ssword!', 3306, 'mysql-bin.000002', 120, '');CALL mysql.az_replication_change_master_with_gtid('master.companya.com', 'syncuser', 'P@ssword!', 3306, '');レプリケーションを開始します。
mysql.az_replication_startストアド プロシージャを呼び出してレプリケーションを開始します。CALL mysql.az_replication_start;レプリケーションの状態を確認します。
レプリカ サーバーで
show slave statusコマンドを呼び出して、レプリケーションの状態を確認します。show slave status;レプリケーションの正しい状態を確認するには、監視ページのレプリケーション メトリックである [Replica IO Status](レプリカ IO の状態) と [Replica SQL Status](レプリカ SQL の状態) を参照します。
Seconds_Behind_Masterが "0" の場合、レプリケーションは正常に機能しています。Seconds_Behind_Masterは、レプリカの遅れの程度を示しています。 この値が "0" 以外である場合、レプリカで更新処理が実行されていることを意味します。
データイン レプリケーション操作のためのその他の便利なストアド プロシージャ
レプリケーションの停止
ソースとレプリカのサーバー間でレプリケーションを停止するには、次のストアド プロシージャを使用します。
CALL mysql.az_replication_stop;
レプリケーション関係の解除
ソースとレプリカのサーバーの関係を解除するには、次のストアド プロシージャを使用します。
CALL mysql.az_replication_remove_master;
レプリケーション エラーのスキップ
レプリケーション エラーをスキップして、レプリケーションを続行できるようにするには、次のストアド プロシージャを使用します。
CALL mysql.az_replication_skip_counter;
SHOW BINLOG EVENTS [IN 'log_name'] [FROM pos][LIMIT [offset,] row_count]

次のステップ
- Azure Database for MySQL フレキシブル サーバーのデータイン レプリケーションについて確認します。