エージェントレス型移行アーキテクチャ
この記事では、移行およびモダン化ツールのエージェントレス移行方法を使用して VMware 仮想マシンを移行する際のレプリケーションの概念について説明します。
Note
このエンドツーエンドの VMware 移行シナリオのドキュメントは現在プレビュー段階です。 Azure Migrate の使用方法の詳細については、「Azure Migrate のドキュメント」を参照してください。
レプリケーション プロセス
エージェントレス レプリケーション オプションは、VMware スナップショットと VMware 変更ブロック追跡 (CBT) テクノロジを使用して、仮想マシン ディスクからデータをレプリケートして機能します。 次のブロック図は、移行およびモダン化ツールを使用して仮想マシンを移行する際のさまざまな手順を示しています。
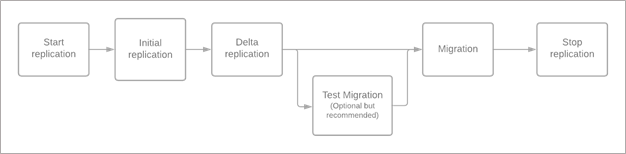
仮想マシンに対してレプリケーションが構成されている場合、最初に初期レプリケーション フェーズが実行されます。 初期レプリケーション中に、VM スナップショットが作成され、スナップショット ディスクからのデータの完全なコピーがターゲット サブスクリプション内のマネージド ディスクにレプリケートされます。
VM の初期レプリケーションが完了すると、レプリケーション プロセスは増分レプリケーション (差分レプリケーション) フェーズに移行します。 増分レプリケーション フェーズでは、最後に完了したレプリケーション サイクルの開始時以降に発生したデータ変更がレプリケートされて、レプリカ マネージド ディスクに書き込まれるため、レプリケーションは VM 上で発生する変更と同期した状態に保たれます。
レプリケーション サイクル間の変更を追跡するために、VMware の変更ブロック追跡 (CBT) テクノロジが使用されます。 レプリケーション サイクルの開始時に、VM スナップショットが作成され、変更ブロック追跡を使用して、現在のスナップショットと最後に正常にレプリケートされたスナップショットの間の変更が取得されます。 前回に完了したレプリケーション サイクル以降に変更されたデータのみをレプリケートして、VM のレプリケーションを同期した状態に保ちます。各レプリケーション サイクルの最後に、スナップショットが解放され、仮想マシンに対してスナップショットの統合が実行されます。
レプリケートする仮想マシンで移行操作を実行する際、前回のレプリケーション サイクル以降の残りの変更をレプリケートするオンデマンド差分レプリケーション サイクルがあります。 オンデマンドのサイクルが完了すると、仮想マシンに対応するレプリカ マネージド ディスクが Azure での仮想マシンの作成に使用されます。 移行またはフェールオーバーをトリガーする直前に、オンプレミスの仮想マシンをシャットダウンする必要があります。 仮想マシンをシャットダウンすると、移行中のデータ損失がゼロになります。
移行が成功し、Azure で VM が起動したら、VM のレプリケーションを停止してください。 レプリケーションを停止すると、データ レプリケーション中に作成された中間ディスク (シード ディスク) が削除され、これらのディスク上のストレージ トランザクションに関連する追加料金が発生しないようにすることもできます。
レプリケーション サイクル
Note
以前のレプリケーション試行や他のサード パーティ製アプリから作成されたスナップショットがあるか、必ず確認します。 VM のスナップショットが既に存在する場合は、VM で変更の追跡を有効にできません。 既存のスナップショットを削除するか、VM でブロック変更の追跡を有効にします。
レプリケーション サイクルとは、オンプレミス環境から Azure マネージド ディスクにデータを転送する定期的なプロセスを表します。 完全なレプリケーション サイクルは、次の手順で構成されます。
- VM に関連付けられているディスクごとに VMware スナップショットを作成する
- Azure のログ ストレージ アカウントにデータをアップロードする
- スナップショットをリリースする
- VMware ディスクを統合する
サイクルは、ディスクが統合されると完了します。
レプリケーションに関係するコンポーネント
オンプレミス コンポーネント: Azure Migrate アプライアンスには、レプリケーションを実行する次のコンポーネントがあります
- DRA エージェント
- ゲートウェイ エージェント
Azure コンポーネント: 次の表は、VMware VM 移行のエージェントレス方法を使用する際に作成される、さまざまな Azure Artifacts をまとめたものです。
| コンポーネント | リージョン | サブスクリプション | 説明 |
|---|---|---|---|
| Recovery Services コンテナー | Azure Migrate プロジェクトのリージョン | Azure Migrate プロジェクトのサブスクリプション | データ レプリケーションを調整するために使用されます |
| Service Bus | ターゲット リージョン | Azure Migrate プロジェクトのサブスクリプション | クラウド サービスと Azure Migrate アプライアンス間の通信に使用されます |
| ログ ストレージ アカウント | ターゲット リージョン | Azure Migrate プロジェクトのサブスクリプション | レプリケーション データを格納するために使用されます。これはサービスによって読み取られ、顧客のマネージド ディスクに適用されます |
| ゲートウェイ ストレージ アカウント | ターゲット リージョン | Azure Migrate プロジェクトのサブスクリプション | レプリケーション中にマシンの状態を格納するために使用されます |
| Key Vault | ターゲット リージョン | Azure Migrate プロジェクトのサブスクリプション | サービス バスの接続文字列と、ログ ストレージ アカウントのアクセス キーを管理します |
| Azure Virtual Machine | ターゲット リージョン | ターゲット サブスクリプション | 移行時に Azure で作成された VM |
| Azure Managed Disks | ターゲット リージョン | ターゲット サブスクリプション | Azure VM に接続されているマネージド ディスク |
| ネットワーク インターフェイス カード | ターゲット リージョン | ターゲット サブスクリプション | Azure で作成された VM に接続されている NIC |
必要なアクセス許可
初めてレプリケーションを開始する場合は、ログインしているユーザーに次のロールを割り当てる必要があります。
- Azure Migrate プロジェクトのリソース グループおよびターゲット リソース グループの所有者または共同作成者およびユーザー アクセス管理者
以降のレプリケーションでは、ログインしているユーザーに次のロールを割り当てる必要があります。
- Azure Migrate プロジェクトのリソース グループおよびターゲット リソース グループの所有者または共同作成者
上記のロールに加えて、ログインしているユーザーには、サブスクリプション レベルで Microsoft.Resources/subscriptions/resourceGroups/read のアクセス許可が必要です。
データ整合性
オンプレミス ディスク (ソース ディスク) と Azure のレプリカ ディスク (ターゲット ディスク) の間のデータ整合性を確保するため、各レプリケーション サイクルには 2 つの段階があります。
最初に、ソース ディスクで変更された各セクターがターゲット ディスクにレプリケートされたかどうかを検証します。 検証はビットマップを使用して実行されます。 ソース ディスクは 512 バイトのセクターに分割されます。 ソース ディスク内のすべてのセクターは、ビットマップ内のビットにマップされます。 データ レプリケーションが開始されると、レプリケートする必要があるソース ディスク内のすべての変更されたブロック (差分サイクル) に対してビットマップが作成されます。 同様に、データがターゲット Azure ディスクに転送されると、ビットマップが作成されます。 データ転送が正常に完了すると、クラウド サービスは 2 つのビットマップを比較して、変更されたブロックが不足していないか確認します。 ビットマップ間に不一致がある場合には、サイクルは失敗と見なされます。 すべてのサイクルが再同期されるため、不一致は次のサイクルで修正されます。
次に、Azure ディスクに転送されるデータが、ソース ディスクからレプリケートされたデータと同じであることを確認します。 アップロードされる変更されたブロックは、ログ ストレージ アカウントに BLOB として書き込まれる前に圧縮および暗号化されます。 圧縮前に、このブロックのチェックサムを計算します。 このチェックサムは、圧縮されたデータと共にメタデータとして格納されます。 圧縮解除時に、データのチェックサムが計算され、ソース環境で計算されたチェックサムと比較されます。 不一致がある場合、データは Azure ディスクに書き込まれず、サイクルは失敗と見なされます。 すべてのサイクルが再同期されるため、不一致は次のサイクルで修正されます。
セキュリティ
Azure Migrate アプライアンスは、アップロード前にデータを圧縮および暗号化します。 データはセキュリティで保護された通信チャネルを介して HTTPS で送信され、TLS 1.2 以降を使用します。 さらに、Azure Storage では、データはクラウドに永続化されるときに自動的に暗号化されます (保存時暗号化)。
レプリケーションの状態
VM でレプリケーション (データ コピー) が実行されているときの状態として、可能性があるのは次のものです。
- 初期レプリケーションはキューに登録済み: (レプリケーションまたは移行中に) 他の VM がオンプレミス リソースを消費している可能性があるため、VM はレプリケーション (または移行) のためにキューに登録されています。 リソースが解放されると、この VM が処理されます。
- 初期レプリケーション進行中: VM は初期レプリケーション用にスケジュールされています。
- 初期レプリケーション: VM の初期レプリケーションが進行中です。 VM で初期レプリケーションが実行されている間は、テスト移行や移行を進めることはできません。 この段階では、レプリケーションの停止のみが可能です。
- 初期レプリケーション (x%): 初期レプリケーションはアクティブであり、x% 進行しています。
- 差分同期: VM では最後のレプリケーション サイクル以降の残りのデータ チャーンをレプリケートする差分レプリケーション サイクルが実行されている可能性があります。
- Pause in progress (一時停止中): VM はアクティブな差分レプリケーション サイクルを実行中であり、しばらくすると一時停止されます。
- Paused (一時停止中): レプリケーション サイクルは一時停止されました。 レプリケーションの再開操作を実行すると、レプリケーション サイクルを再開できます。
- Resume queued (再開 (キューに登録済み)): 現在オンプレミス リソースを消費している他の VM があるため、VM はレプリケーションの再開のためにキューに登録されています。
- 再開進行中 (x%): VM のレプリケーション サイクルは再開中であり、x% 進行しています。
- レプリケーションの停止進行中: レプリケーションのクリーンアップが進行中です。 レプリケーションを停止すると、レプリケーション中に作成された中間マネージド ディスク (シードディスク) が削除されます。 詳細情報 を参照してください。
- 移行の完了が進行中: 移行のクリーンアップが進行中です。 移行を完了すると、レプリケーション中に作成された中間マネージド ディスク (シードディスク) が削除されます。 詳細情報 を参照してください。
- –: VM が正常に移行されるか、レプリケーションを停止すると、状態が "-" に変わります。 レプリケーションを停止するか移行が完了して、操作が正常に終了すると、レプリケートしているマシンの一覧から VM が削除されます。 VM は、レプリケート ウィザードの [仮想マシン] タブで見つけることができます。
他の状態
- 初期レプリケーションに失敗しました: VM の初期データをコピーできませんでした。 修復ガイダンスに従って解決してください。
- 修復保留中: レプリケーション サイクルに問題が発生しました。 リンクを選択すると、考えられる原因や修復するためのアクションを把握できます (該当する場合)。 VM のレプリケーションをトリガーしたときに [はい] を選択して [Automatically repair replication](レプリケーションの自動修復) を選択した場合は、ツールによって修復が試行されます。 または、VM を選択し、[レプリケーションの修復] を選択します。 [レプリケーションの自動修復] を選択しなかった場合、または上記の手順が機能しなかった場合は、仮想マシンのレプリケーションを停止し、仮想マシン上の変更されたブロック追跡をリセットして、レプリケーションを再構成します。
- Repair replication queued (レプリケーションの修復 (キューに登録済み)): オンプレミス リソースを消費している他の VM があるため、VM はレプリケーションの修復のためにキューに登録されています。 リソースが解放されると、VM はレプリケーションの修復に進みます。
- 再同期 (x%): VM でデータの再同期が実行されています。 これは、データのレプリケーション中に何らかの問題や不一致があった場合に発生する可能性があります。
- レプリケーションを停止できませんでした/complete migration failed (移行を完了できませんでした): リンクを選択して、考えられるエラーの原因や修復するためのアクションを把握してください (該当する場合)。
Note
ストレージ IOPS の消費に起因するソース環境への影響を最小限に抑えるために、一部の VM はキューに置かれた状態になります。 これらの VM は、次のセクションで説明するように、スケジュール ロジックに基づいて処理されます。
移行/テスト移行の状態
- テスト移行が保留中: VM は差分レプリケーション フェーズにあり、テスト移行 (または移行) を実行できるようになりました。
- Test migration clean up pending (テスト移行のクリーンアップが保留中): テスト移行が完了したら、Azure の料金が発生しないようにするためにテスト移行のクリーンアップを実行してください。
- 移行準備完了: VM を Azure に移行する準備ができました。
- Migration in progress queued (移行が進行中 (キューに登録済み)): レプリケーション (または移行) 中にオンプレミス リソースを消費している他の VM があるため、VM は移行のためにキューに登録されています。 リソースが解放されると、この VM が処理されます。
- テスト移行が進行中/移行が進行中: VM でテスト移行/移行が実行されています。 リンクを選択して、進行中の移行ジョブを確認できます。
- Date, timestamp (日付、タイムスタンプ): 移行/テスト移行の日付とタイムスタンプ。
- –: 初期レプリケーションが進行中です。 レプリケーション プロセスが差分同期 (増分レプリケーション) フェーズに移行した後、移行またはテスト移行を実行できます。
他の状態
- 完了 (情報あり): 移行/テスト移行ジョブが完了しました (情報あり)。 リンクを選択すると、考えられる原因や修復するためのアクションに関して、最後の移行ジョブを確認できます (該当する場合)。
- 失敗: 移行/テスト移行ジョブが失敗しました。 リンクを選択すると、考えられる原因や修復するためのアクションに関して、最後の移行ジョブを確認できます。
スケジュール ロジック
VM のレプリケーションが構成されている場合は、初期レプリケーションがスケジュールされます。 その後、増分レプリケーション (差分レプリケーション) が行われます。
差分レプリケーション サイクルは、次のようにスケジュールされます。
- 最初の差分レプリケーション サイクルは、初期レプリケーション サイクルが完了した直後にスケジュールされます
- 次の差分レプリケーション サイクルは、最小[最大 [1 時間、(以前の差分レプリケーションサイクル時間/2)]、12 時間] のロジックに従ってスケジュールされます
つまり、次の差分レプリケーションは 1 時間後以降、12 時間経過までにスケジュールされます。 たとえば、VM で差分サイクルに 4 時間かかる場合、次回のサイクルは 1 時間後ではなく、2 時間後にスケジュールされます。
Note
スケジュール ロジックは、初期レプリケーションが完了した後では異なります。 最初の差分サイクルは、初期レプリケーションが完了した直後にスケジュールされ、それ以降のサイクルは、前述のスケジュール ロジックに従います。
- 移行をトリガーすると、移行前に、オンデマンドの差分レプリケーション サイクル (フェールオーバー前の差分レプリケーション サイクル) が VM に対して実行されます。
レプリケーションのさまざまな段階での VM の優先順位付け
- 進行中の VM レプリケーションは、スケジュールされたレプリケーション (新しいレプリケーション) より優先されます。
- 事前フェールオーバー (オンデマンド差分レプリケーション) サイクルは優先順位が最も高く、その次に初期レプリケーションサイクルが続きます。 差分レプリケーション サイクルの優先順位は最も低くなります。
つまり、移行操作がトリガーされるたびに、VM のオンデマンド レプリケーション サイクルがスケジュールされ、リソースの競合が発生した場合には、その他の進行中のレプリケーションは後回しにされます。
制約:
SAN の IOPS 制限を超えないようにするため、次の制約を使用します。
- 各 Azure Migrate アプライアンスは、同時に 52 個のディスクのレプリケーションをサポートします。
- 各 ESXi ホストは、8 個のディスクをサポートします。 すべての ESXi ホストには 32 MB の NFC バッファーがあります。 よって、ホスト上で 8 個のディスクをスケジュールすることができます (各ディスクは IR、DR 用に 4 MB のバッファーを使用)。
- 各データストアは、最大で 15 のディスク スナップショットを持つことができます。 唯一の例外は、VM に接続されているディスクが 15 個を超えている場合です。
スケールアウト レプリケーション
Azure Migrate は、500 の仮想マシンの同時レプリケーションをサポートしています。 300 を超える仮想マシンをレプリケートする予定の場合は、スケールアウト アプライアンスをデプロイする必要があります。 スケールアウト アプライアンスは Azure Migrate プライマリ アプライアンスに似ていますが、Azure へのデータ転送を支援するゲートウェイ エージェントのみで構成されています。 次の図は、スケールアウト アプライアンスを使用する際に推奨される方法を示しています。

プライマリ アプライアンスを構成したら、スケールアウト アプライアンスはいつでも展開できますが、300 の VM が同時にレプリケートされるまでは不要です。 同時にレプリケートされる VM の数が 300 に達したら、続行するするためにはスケールアウト アプライアンスを展開する必要があります。
レプリケーションの停止/移行の完了
レプリケーションを停止すると、レプリケーション中に作成された中間マネージド ディスク (シードディスク) が削除されます。 レプリケーションを停止できるのは、アクティブなレプリケーション中のみです。 [移行の完了] を選択すると、VM の移行後にレプリケーションを停止できます。
レプリケーションを停止した VM は、レプリケーションを再度有効にするとレプリケートできます。 VM を移行した場合は、レプリケーションと移行をもう一度再開できます。
ベスト プラクティスとして、VM が Azure に正常に移行された後は、常に移行を完了し、中間マネージド ディスク (シードディスク) でのストレージ トランザクションに対する追加料金が発生しないようにします。 場合によっては、レプリケーションの停止に時間がかかることがあります。 これは、レプリケーションを停止するたび、成果物の削除の前に、実行中のレプリケーション サイクルが完了されるためです (VM が差分同期の場合のみ)。
チャーンの影響
各レプリケーション サイクルのデータ転送量を最小限に抑えるために、次のサイクルをスケジュールする前に、データを可能な限り折りたたむことができるようにします。 エージェントレス レプリケーションでは日付が折りたたまれるため、チャーン レートよりチャーン パターンが重要です。 ファイルが繰り返し書き込まれる場合、そのレートはあまり影響を与えません。 ただし、セクターが 1 つおきに書き込まれるパターンでは、次回のサイクルでチャーンが高くなります。
レプリケーションの管理
調整
NetQosPolicy を使って、レプリケーションの帯域幅を増減することができます。NetQosPolicy で使う AppNamePrefix は "GatewayWindowsService.exe" です。
Azure Migrate アプライアンスで次のようなポリシーを作成することによって、アプライアンスからのレプリケーション トラフィックを調整できます:
New-NetQosPolicy -Name "ThrottleReplication" -AppPathNameMatchCondition "GatewayWindowsService.exe" -ThrottleRateActionBitsPerSecond 1MB
Note
これは、Azure Migrate アプライアンスから同時にレプリケートするすべての VM に適用されます。
また、サンプル スクリプトを使用して、スケジュールに基づいてレプリケーションの帯域幅を増減することもできます。
ブラックアウト期間
Azure Migrate には、レプリケーションを続行しない期間を顧客が指定できる構成ベースのメカニズムが用意されています。 この期間は、ブラックアウト期間と呼ばれます。 ブラックアウト期間の必要性は、ソース環境のリソースに制約がある場合や、顧客がレプリケーションを業務時間外のみに実行したい場合など、複数のシナリオで発生する可能性があります。
Note
- ブラックアウト期間の開始時に存在するレプリケーション サイクルは、レプリケーションが一時停止する前に完了します。
- ブラックアウト期間中に開始された移行の場合、最終的なレプリケーションは実行されず、移行は失敗します。
C:\ProgramData\Microsoft Azure\Config でファイル GatewayDataWorker.json を作成または更新することで、アプライアンスのブラックアウト期間を指定できます。一般的なファイルの形式は次のとおりです。
{
"BlackoutWindows": "List of blackout windows"
}
ブラックアウト期間の一覧は、"DayOfWeek;StartTime;Duration" という形式の "|" で区切られた文字列です。 期間は日、時間、分で指定できます。 たとえば、ブラックアウト期間は次のように指定できます。
{
"BlackoutWindows": "Monday;7:00;7h | Tuesday;8:00;1d7h | Wednesday;16:00;1d | Thursday;18:00;5h | Friday;13:00;8m"
}
上の例で、最初の値は、毎週月曜日の午前 7 時 (アプライアンスでの時間) に開始され、7 時間継続するブラックアウト期間を示しています。
これらのコンテンツを使用して GatewayDataWorker.json を作成または更新したら、アプライアンスのゲートウェイ サービスを再起動して、これらの変更を有効にする必要があります。
スケールアウト シナリオでは、プライマリ アプライアンスとスケールアウト アプライアンスは、それぞれ個別にブラックアウト期間に従います。 ベストプラクティスとして、複数のアプライアンス間でこの期間を同じにすることをお勧めします。
次のステップ
エージェントレス移行で VMware VM を移行する。