Azure Machine Learning デザイナーを使用して自動車の価格を予測する線形回帰モデルをトレーニングします。 このチュートリアルは、2 部構成のシリーズのパート 1 です。
このチュートリアルでは、Azure Machine Learning デザイナーを使用します。詳細については、「Azure Machine Learning デザイナーとは」を参照してください。
注意
デザイナーは、従来の事前構築済みコンポーネント (v1) とカスタム コンポーネント (v2) の 2 種類のコンポーネントをサポートします。 これら 2 種類のコンポーネントには互換性がありません。
従来の事前構築済みコンポーネントは、主にデータ処理や、回帰や分類などの従来の機械学習タスク向けの事前構築済みのコンポーネントを提供します。 この種類のコンポーネントは引き続きサポートされますが、新しいコンポーネントは追加されません。
カスタム コンポーネントを使用すると、独自のコードをコンポーネントとしてラップすることができます。 これは、ワークスペース間での共有と、Studio、CLI v2、SDK v2 インターフェイス間でのシームレスなオーサリングをサポートします。
新しいプロジェクトでは、AzureML V2 と互換性があり、新しく更新され続けるカスタム コンポーネントを使用することを強くお勧めします。
この記事は、CLI v2 および SDK v2 と互換性のない、従来の事前構築済みコンポーネントに適用されます。
このチュートリアルのパート 1 では、次の方法について学習します。
- 新しいパイプラインを作成する。
- データをインポートする。
- データを準備する。
- 機械学習モデルをトレーニングする。
- 機械学習モデルを評価する。
チュートリアルのパート 2 では、リアルタイム推論エンドポイントとしてモデルをデプロイし、送信した技術仕様に基づいて任意の自動車の価格を予測します。
Note
このチュートリアルの完成版をサンプル パイプラインとして入手できます。
これを見つけるには、ワークスペースのデザイナーに移動します。 [新しいパイプライン] セクションで [Sample 1 - Regression:Automobile Price Prediction(Basic)](サンプル 1 - 回帰: 自動車価格の予測 (Basic)) を選択してください。
重要
このドキュメントで言及しているグラフィカル要素 (Studio やデザイナーのボタンなど) が表示されない場合は、そのワークスペースに対する適切なレベルのアクセス許可がない可能性があります。 ご自分の Azure サブスクリプションの管理者に連絡して、適切なレベルのアクセス許可があることを確認してください。 詳細については、「ユーザーとロールを管理する」を参照してください。
新しいパイプラインを作成する
Azure Machine Learning パイプラインによって、複数の機械学習ステップとデータ処理ステップが 1 つのリソースに整理されます。 複数のプロジェクトや複数のユーザーにまたがる複雑な機械学習ワークフローをパイプラインで効率的に整理、管理、再利用することができます。
Azure Machine Learning パイプラインを作成するには、Azure Machine Learning ワークスペースが必要です。 このセクションでは、その両方のリソースを作成する方法について説明します。
新しいワークスペースを作成する
デザイナーを使用するには、Azure Machine Learning ワークスペースが必要です。 ワークスペースは、Azure Machine Learning の最上位のリソースで、Azure Machine Learning で作成するすべての成果物を操作するための一元的な場所を提供します。 ワークスペースの作成の手順は、ワークスペース リソースの作成に関するページを参照してください。
Note
ワークスペースで仮想ネットワークを使用する場合、デザイナーを使用するには、追加の構成手順を使用する必要があります。 詳細については、「Azure 仮想ネットワークで Azure Machine Learning スタジオを使用する」を参照してください。
パイプラインを作成する
Note
デザイナーは、従来の事前構築済みコンポーネントとカスタム コンポーネントの 2 種類のコンポーネントをサポートします。 これら 2 種類のコンポーネントには互換性がありません。
従来の事前構築済みコンポーネントは、主にデータ処理や従来の機械学習タスク (回帰や分類など) に事前構築済みのコンポーネントを提供します。 この種類のコンポーネントは引き続きサポートされますが、新しいコンポーネントは追加されません。
カスタム コンポーネントを使用すると、独自のコードをコンポーネントとして提供できます。 ワークスペース間での共有と、Studio、CLI、SDK インターフェイス間でのシームレスな作成ができるようになります。
この記事は、従来の事前構築済みコンポーネントに適用されます。
ml.azure.com にサインインし、使用するワークスペースを選択します。
[デザイナー] ->[Classic prebuilt] (従来の事前構築済み) を選択します。
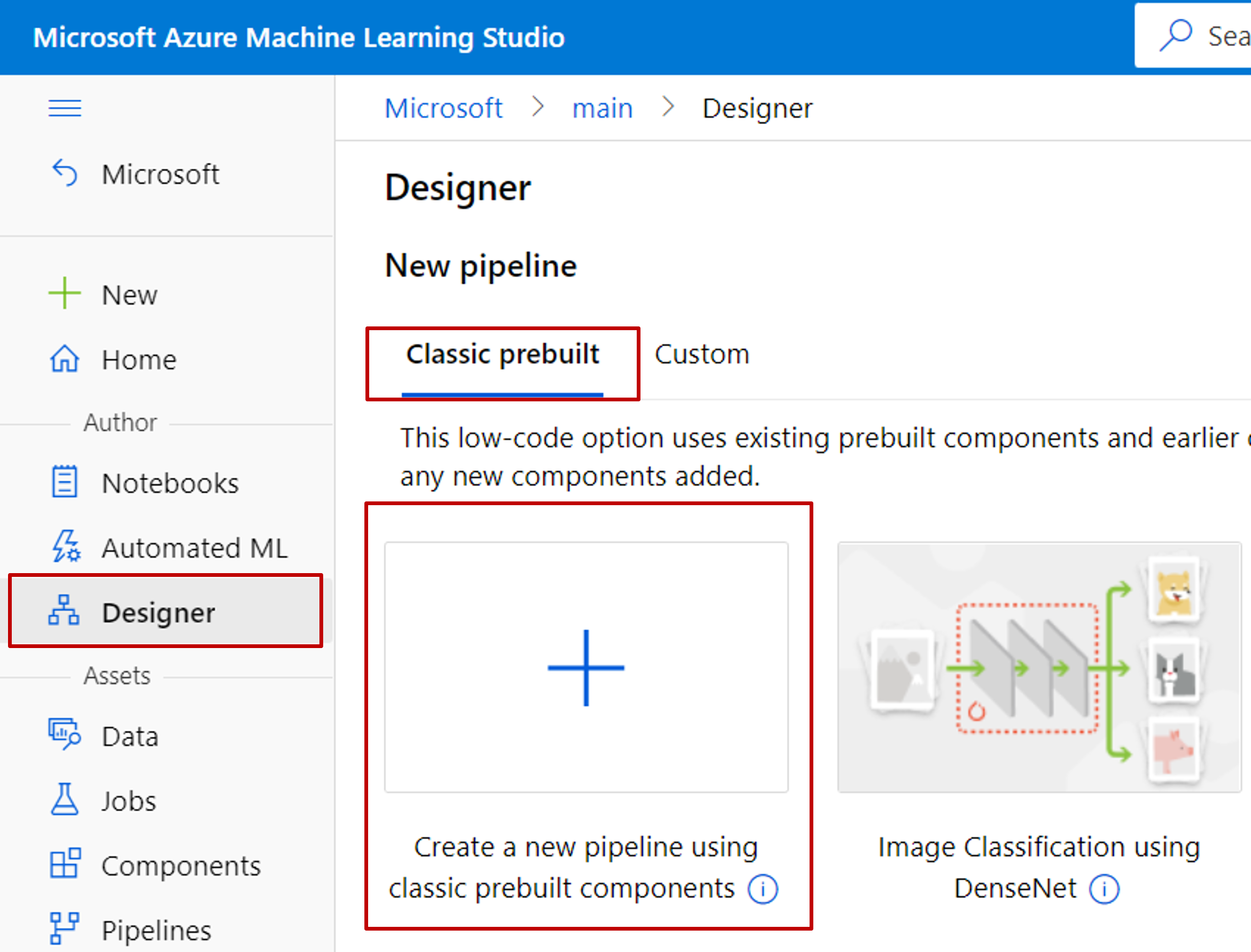
[従来の事前構築済みコンポーネントを使用して新しいパイプラインを作成する] を選択します。
自動生成されたパイプラインのドラフトの名前の横にある鉛筆アイコンをクリックし、"自動車価格の予測" に名前を変更します。 名前は一意でなくてもかまいません。
データのインポート
デザイナーには、実験に利用できるいくつかのサンプル データセットが含まれています。 このチュートリアルでは、Automobile price data (Raw) を使用します。
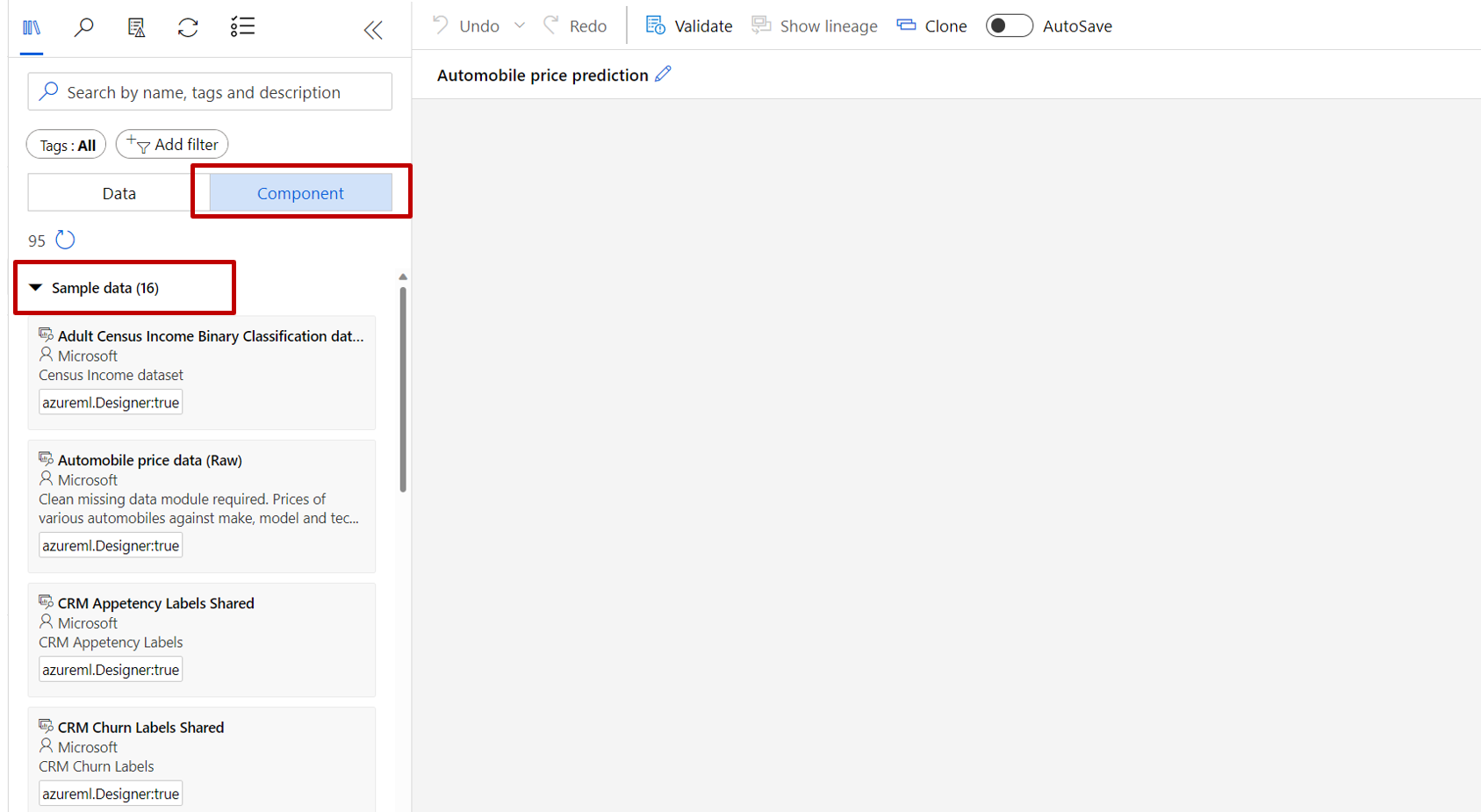
パイプライン キャンバスの左側には、データセットとコンポーネントのパレットがあります。 [コンポーネント] ->[サンプル データ] を選択します。
Automobile price data (Raw) データセットを選択し、キャンバスにドラッグします。
データの視覚化
使用するデータセットを把握するために、データを視覚化することができます。
[Automobile price data (Raw)] を右クリックし、[データのプレビュー] を選択します。
データ ウィンドウで別の列を選択して、それぞれの情報を表示します。
各行は自動車を表していて、各自動車に関連付けられている変数が列として表示されます。 このデータセット内には、205 の行と 26 の列があります。
データを準備する
通常、データセットには、分析前にある程度の前処理が必要です。 データセットを検査したときに、いくつか不足値があることに気付いたかもしれません。 モデルがデータを正しく分析するには、これらの不足値を整理する必要があります。
列の削除
モデルをトレーニングする際は、欠損データに対処する必要があります。 このデータセットでは、normalized-losses 列に多数の欠損値が存在するので、その列全体をモデルから除外します。
キャンバスの左側にあるデータセットとコンポーネント パレットで、[コンポーネント] をクリックし、[Select Columns in Dataset](データセットの列を選択する) コンポーネントを探します。
[Select Columns in Dataset](データセットの列を選択する) コンポーネントをキャンバスにドラッグします。 そのコンポーネントをデータセット コンポーネントの下にドロップします。
Automobile price data (Raw) データセットを、 [Select Columns in Dataset](データセットの列を選択する) コンポーネントに接続します。 データセットの出力ポート (キャンバス上のデータセットの下部にある小さい円) から [Select Columns in Dataset](データセットの列を選択する) の入力ポート (コンポーネントの上部にある小さい円) までドラッグします。
ヒント
1 つのコンポーネントの出力ポートを別のコンポーネントの入力ポートに接続するときに、パイプラインを通じてデータのフローを作成することになります。
![[Automobile price data] コンポーネントを [Select Columns in Dataset] コンポーネントに接続するスクリーンショット。](media/tutorial-designer-automobile-price-train-score/connect-modules.gif?view=azureml-api-1)
[Select Columns in Dataset](データセットの列を選択する) コンポーネントを選択します。
キャンバスの右側にある [設定] の下にある矢印アイコンをクリックして、コンポーネントの詳細ウィンドウを開きます。 または、[Select Columns in Dataset](データセットの列を選択する) コンポーネントをダブルクリックして詳細ウィンドウを開く方法もあります。
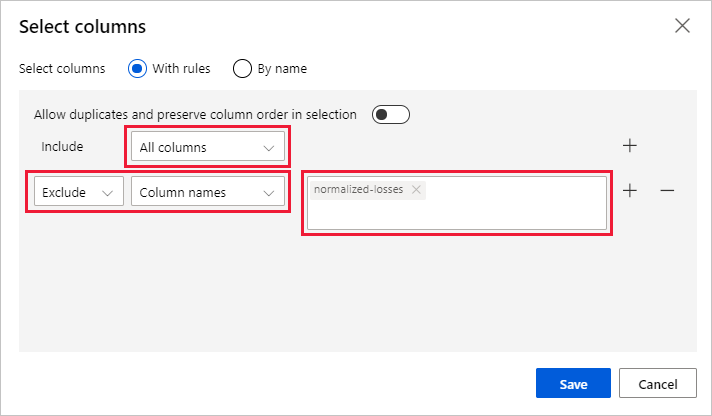
ウィンドウの右側にある [列の編集] を選択します。
[Include](対象) の横にある [列名] ボックスの一覧を展開し、[すべての列] を選びます。
[+] を選択し、新しいルールを追加します。
ドロップダウン メニューから [Exclude](除外) と [列名] を選択します。
テキスト ボックスに「normalized-losses」と入力します。
右下の [保存] を選択して列セレクターを閉じます。
[Select Columns in Dataset](データセットの列を選択する) コンポーネントの詳細ウィンドウで、[ノード情報] を展開します。
[コメント] ボックスを選択し、「Exclude normalized losses」と入力します。
コメントがグラフに表示されることで、パイプラインが整理しやすくなります。
見つからないデータのクリーンアップ
normalized-losses 列を削除した後も、データセットにはまだ欠損値が存在します。 残りの欠損データは [Clean Missing Data](見つからないデータのクリーンアップ) コンポーネントを使用して削除できます。
ヒント
デザイナーでは、欠損値を入力データから取り除くことが、ほとんどのコンポーネントを使用するための前提条件となっています。
キャンバスの左側にあるデータセットとコンポーネント パレットで、[コンポーネント] をクリックし、[Clean Missing Data](見つからないデータのクリーンアップ) コンポーネントを探します。
[Clean Missing Data](見つからないデータのクリーンアップ) コンポーネントをパイプライン キャンバスにドラッグします。 それを [Select Columns in Dataset](データセットの列を選択する) コンポーネントに接続します。
[Clean Missing Data](見つからないデータのクリーンアップ) コンポーネントを選択します。
キャンバスの右側にある [設定] の下にある矢印アイコンをクリックして、コンポーネントの詳細ウィンドウを開きます。 または、[Clean Missing Data](見つからないデータのクリーンアップ) コンポーネントをダブルクリックして詳細ウィンドウを開く方法もあります。
ウィンドウの右側にある [列の編集] を選択します。
表示される [クリーニング対象の列] ウィンドウで、 [含める] の横にあるドロップダウン メニューを展開します。 [すべての列] を選択します
[保存] を選びます。
[Clean Missing Data](見つからないデータのクリーンアップ) コンポーネントの詳細ウィンドウの [クリーニング モード] で、[行全体の削除] を選択します。
[Clean Missing Data](見つからないデータのクリーンアップ) コンポーネントの詳細ウィンドウで、[ノード情報] を展開します。
[コメント] テキスト ボックスを選択し、「Remove missing value rows」と入力します。
これでパイプラインは次のようになっているはずです。
![[Automobile price data] が [Select Columns in Dataset] コンポーネントに接続され、さらに [Clean Missing Data] に接続されているスクリーンショット。](media/tutorial-designer-automobile-price-train-score/pipeline-clean.png?view=azureml-api-1)
機械学習モデルのトレーニング
データを処理するためのコンポーネントが揃ったら、トレーニング コンポーネントを設定することができます。
予測したい価格は数値であるため、回帰アルゴリズムを使用できます。 この例では、線形回帰モデルを使用します。
データを分割する
データの分割は、機械学習における一般的なタスクです。 データを 2 つの独立したデータセットに分割します。 1 つのデータセットでモデルをトレーニングし、もう一方のデータセットでモデルがどれだけ適切に実行されたかをテストします。
キャンバスの左側にあるデータセットとコンポーネント パレットで、[コンポーネント] をクリックし、[Split Data](データの分割) コンポーネントを探します。
[Split Data](データの分割) コンポーネントをパイプライン キャンバスにドラッグします。
[Clean Missing Data](見つからないデータのクリーンアップ) コンポーネントの左側のポートを [Split Data](データの分割) コンポーネントに接続します。
重要
[Split Data](データの分割) には必ず、[Clean Missing Data](見つからないデータのクリーンアップ) の左側の出力ポートを接続してください。 クリーンアップされたデータは、左側のポートに格納されます。 右側のポートには、破棄されたデータが格納されます。
[Split Data](データの分割) コンポーネントを選択します。
キャンバスの右側にある [設定] の下にある矢印アイコンをクリックして、コンポーネントの詳細ウィンドウを開きます。 または、[Split Data](データの分割) コンポーネントをダブルクリックして詳細ウィンドウを開く方法もあります。
[Split Data](データの分割) 詳細ウィンドウで、[Fraction of rows in the first output dataset](最初の出力データセット内の行の割合) を 0.7 に設定します。
このオプションによって、データの 70% をモデルのトレーニング、30% をテストに分割します。 70% のデータセットには、左側の出力ポートからアクセスできます。 残りのデータは、右側の出力ポートから使用できます。
[Split Data](データの分割) の詳細ウィンドウで、[ノード情報] を展開します。
[コメント] テキスト ボックスを選択し、「Split the dataset into training set (0.7) and test set (0.3)」と入力します。
モデルをトレーニングする
価格が含まれたデータセットを指定して、モデルをトレーニングします。 トレーニング データによって提示された価格と特徴との間の関係を説明するモデルがアルゴリズムによって構築されます。
キャンバスの左側にあるデータセットとコンポーネント パレットで、[コンポーネント] をクリックし、[Linear Regression](線形回帰) コンポーネントを探します。
[Linear Regression](線形回帰) コンポーネントをパイプライン キャンバスにドラッグします。
キャンバスの左側にあるデータセットとコンポーネント パレットで、[コンポーネント] をクリックし、[Train Model](モデルのトレーニング) コンポーネントを探します。
[Train Model](モデルのトレーニング) コンポーネントをパイプライン キャンバスにドラッグします。
[Linear Regression](線形回帰) コンポーネントの出力を [Train Model](モデルのトレーニング) コンポーネントの左側の入力に接続します。
[Split Data](データの分割) コンポーネントのトレーニング データ出力 (左側のポート) を [Train Model](モデルのトレーニング) コンポーネントの右側の入力に接続します。
重要
[Train Model](モデルのトレーニング) には必ず、[Split Data](データの分割) の左側の出力ポートを接続してください。 トレーニング セットは、左側のポートに格納されます。 右側のポートには、テスト セットが格納されます。
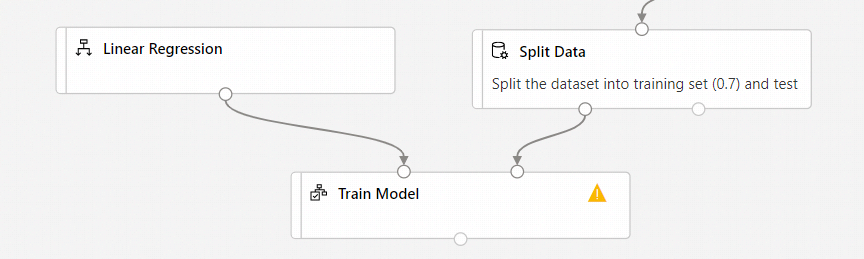
[Train Model](モデルのトレーニング) コンポーネントを選択します。
キャンバスの右側にある [設定] の下にある矢印アイコンをクリックして、コンポーネントの詳細ウィンドウを開きます。 または、[Train Model](モデルのトレーニング) コンポーネントをダブルクリックして詳細ウィンドウを開く方法もあります。
ウィンドウの右側にある [列の編集] を選択します。
表示された [Label column](ラベル列) ウィンドウのドロップダウン メニューを展開して [列名] を選択します。
テキスト ボックスに「price」(価格) を入力して、モデルで予測しようとする値を指定します。
重要
列名を正確に入力してください。 price は大文字にしないでください。
パイプラインは次のようになっているはずです。
![[Train Model]\(モデルのトレーニング\) コンポーネントを追加した後のパイプラインの正しい構成を示すスクリーンショット。](media/tutorial-designer-automobile-price-train-score/pipeline-train-graph.png?view=azureml-api-1)
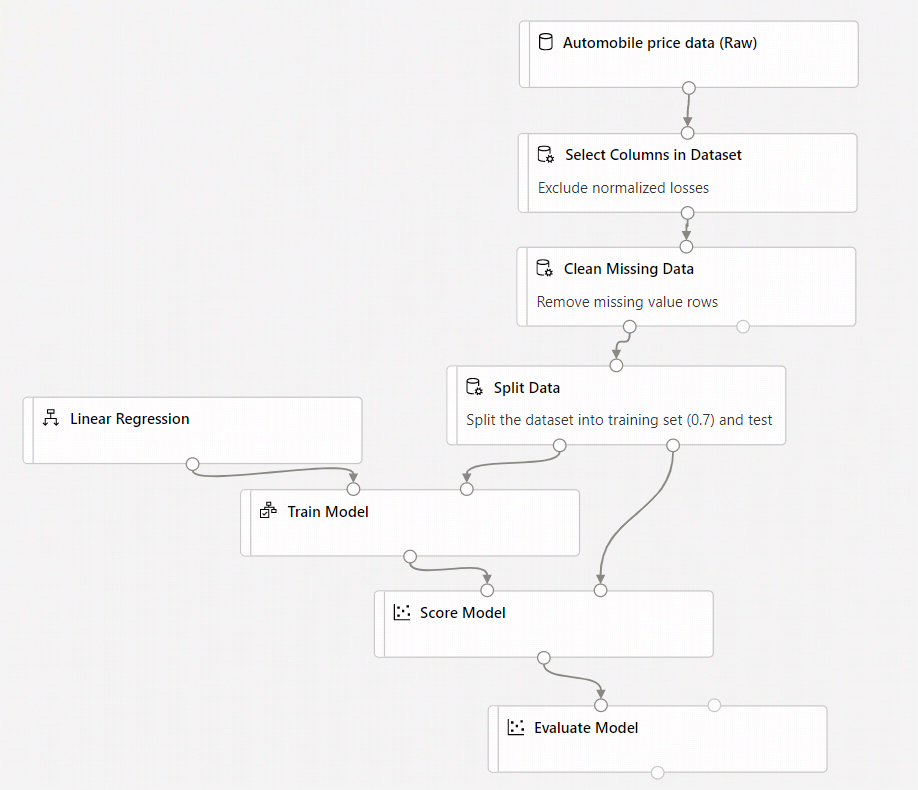
[Score Model](モデルのスコア付け) コンポーネントを追加する
データの 70% を使用してモデルをトレーニングした後で、残りの 30% にスコアを付け、モデルの精度を確認します。
キャンバスの左側にあるデータセットとコンポーネント パレットで、[コンポーネント] をクリックし、[Score Model](モデルのスコア付け) コンポーネントを探します。
[Score Model](モデルのスコア付け) コンポーネントをパイプライン キャンバスにドラッグします。
[Train Model](モデルのトレーニング) コンポーネントの出力を、 [Score Model](モデルのスコア付け) の左側の入力ポートに接続します。 [Split Data](データの分割) コンポーネントのテスト データの出力 (右側のポート) を、 [Score Model](モデルのスコア付け) の右側の入力ポートに接続します。
[Evaluate Model](モデルの評価) コンポーネントを追加する
モデルがどの程度の精度でテスト データセットにスコア付けしたかを、 [Evaluate Model](モデルの評価) コンポーネントを使用して評価します。
キャンバスの左側にあるデータセットとコンポーネント パレットで、[コンポーネント] をクリックし、[Evaluate Model](モデルの評価) コンポーネントを探します。
[Evaluate Model](モデルの評価) コンポーネントをパイプライン キャンバスにドラッグします。
[Score Model](モデルのスコア付け) コンポーネントの出力を、 [Evaluate Model](モデルの評価) の左側の入力に接続します。
最終的なパイプラインは次のようになっているはずです。
パイプラインを送信する
右上隅の [構成と送信] を選択して、パイプラインを送信します。
![[構成と送信] ボタンを示すスクリーンショット。](media/tutorial-designer-automobile-price-train-score/configure-submit.png?view=azureml-api-1)
詳細な手順を案内するウィザードが表示されます。ウィザードに従ってパイプライン ジョブを送信します。


[基本] ステップでは、実験、ジョブの表示名、ジョブの説明などを構成できます。
[入力 & 出力] ステップでは、パイプライン レベルにレベル上げされた入出力に値を割り当てることができます。 この例では、どの入出力もパイプライン レベルに昇格させなかったため、これは空になります。
[ランタイムの設定] では、パイプラインの既定のデータストアと既定のコンピューティングを構成できます。 これは、パイプライン内のすべてのコンポーネントの既定のデータストアまたはコンピューティングです。 ただし、あるコンポーネントに対して別のコンピューティングまたはデータストアを明示的に設定した場合、システムではコンポーネント レベルの設定を考慮します。 そうでない場合は、既定値を使用します。
[レビュー + 送信] ステップは、送信する前にすべての設定を確認するための最後のステップです。 パイプラインを送信した場合は、ウィザードに最後の構成が記憶されます。
パイプライン ジョブを送信すると、ジョブの詳細へのリンクが含まれたメッセージが上部に表示されます。 このリンクを選択して、ジョブの詳細を確認できます。

スコア付けラベルを確認する
ジョブの詳細ページでは、パイプライン ジョブの状態、結果、ログを確認できます。

ジョブが完了したら、パイプライン ジョブの結果を確認できます。 まず、回帰モデルによって生成された予測に注目します。
[モデルのスコア付け] コンポーネントを右クリックし、[データのプレビュー]>[スコアリング済みデータセット] の順に選択してその出力を表示します。
ここでは、予測された価格と、データのテストによる実際の価格を確認できます。
モデルを評価する
テスト データセットに対してトレーニング済みのモデルがどの程度の精度で実行されたかを [Evaluate Model](モデルの評価) を使用して確認します。
- [モデルの評価] コンポーネントを右クリックし、[データのプレビュー]>[評価結果] の順に選択してその出力を表示します。
作成したモデルに対して、以下の統計値が表示されます。
- Mean Absolute Error (MAE、平均絶対誤差):絶対誤差の平均。 誤差とは、予測された値と実際の値との差です。
- Root Mean Squared Error (RMSE、二乗平均平方根誤差):テスト データセットに対して実行した予測の二乗誤差平均の平方根です。
- Relative Absolute Error (相対絶対誤差):実際の値とすべての実際の値の平均との絶対差を基準にした絶対誤差の平均です。
- Relative Squared Error (相対二乗誤差):実際の値とすべての実際の値の平均との二乗差を基準にした二乗誤差の平均です。
- Coefficient of Determination (決定係数):R-2 乗値ともいいます。どの程度モデルが高い精度でデータと適合するかを示す統計指標です。
この誤差の統計情報は、それぞれ小さいほど良いとされます。 値が小さいほど、予測が実際の値により近いことを示します。 決定係数では、値が 1 (1.0) に近づくほど、予測の精度が高くなります。
リソースをクリーンアップする
続けてチュートリアルのパート 2 (モデルのデプロイ) を行う場合は、このセクションはスキップしてください。
重要
作成したリソースは、Azure Machine Learning のその他のチュートリアルおよびハウツー記事の前提条件として使用できます。
すべてを削除する
作成したすべてのものを使用する予定がない場合は、料金が発生しないように、リソース グループ全体を削除します。
Azure portal で、ウィンドウの左側にある [リソース グループ] を選択します。
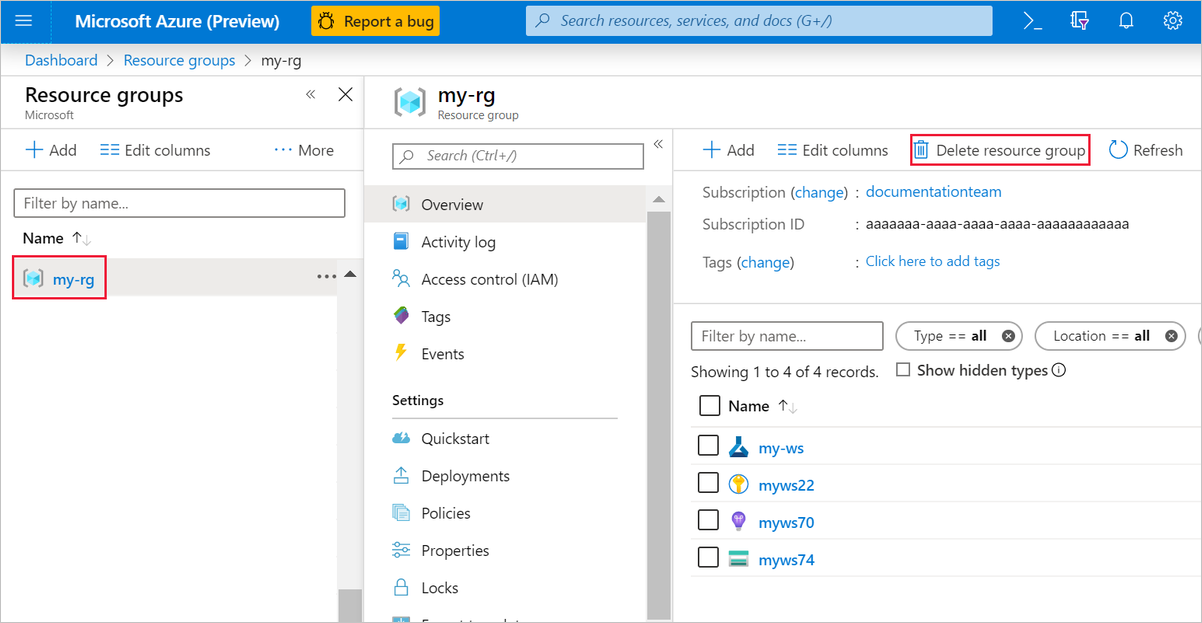
一覧から、作成したリソース グループを選択します。
[リソース グループの削除] を選択します。
リソース グループを削除すると、デザイナーで作成したすべてのリソースも削除されます。
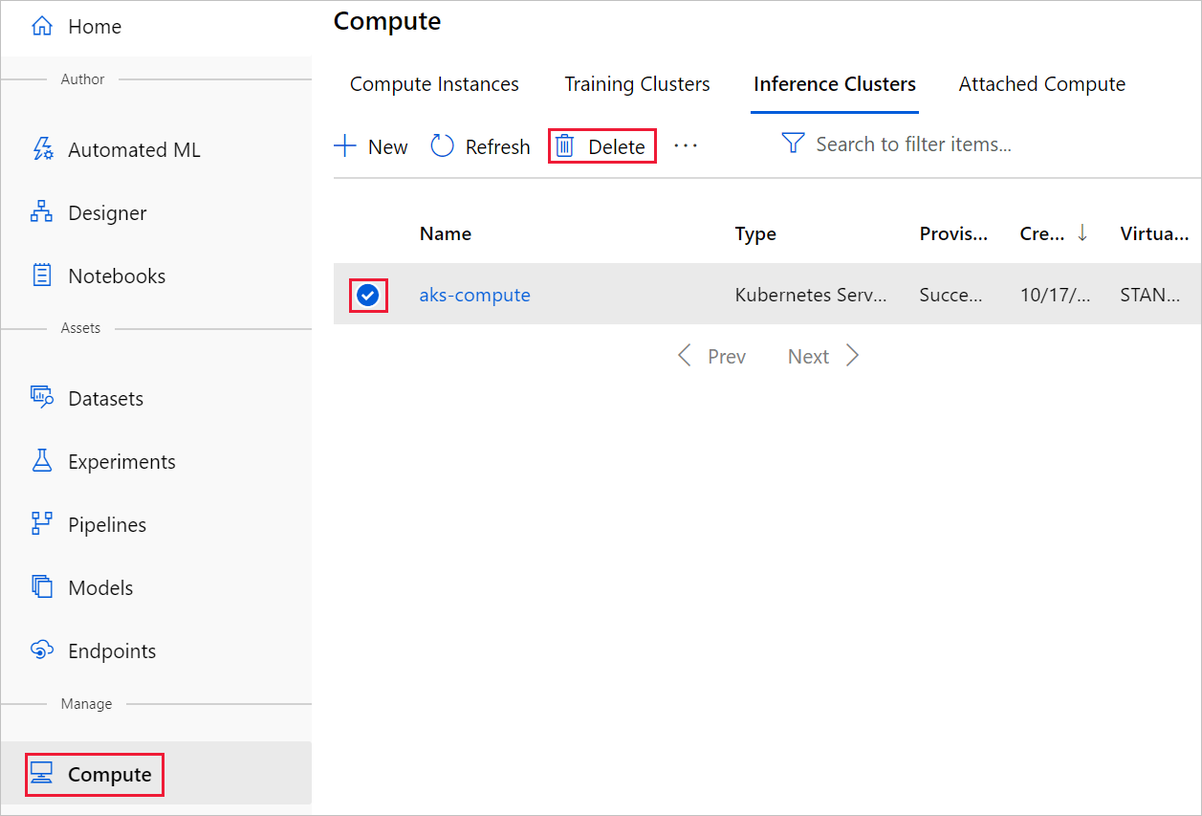
個々の資産を削除する
実験を作成したデザイナーで、個々の資産を選択し、[削除] ボタンを選択してそれらを削除します。
ここで作成したコンピューティング ターゲットは、使用されていない場合、自動的にゼロ ノードに自動スケーリングされます。 このアクションは、料金を最小限に抑えるために実行されます。 コンピューティング ターゲットを削除する場合は、次の手順を実行してください。
各データセットを選択し、[登録解除] を選択することによって、ワークスペースからデータセットを登録解除できます。
データセットを削除するには、Azure portal または Azure Storage Explorer を使用してストレージ アカウントに移動し、これらのアセットを手動で削除します。
次のステップ
パート 2 では、モデルをリアルタイム エンドポイントとしてデプロイする方法を学習します。