モデルをオンライン エンドポイントにデプロイする
適用対象:  Python SDK azure-ai-ml v2 (現行)
Python SDK azure-ai-ml v2 (現行)
Azure Machine Learning Python SDK v2 を使用してオンライン エンドポイントにモデルをデプロイする方法について説明します。
このチュートリアルでは、クレジット カード支払いで顧客が不履行になる可能性を予測するモデルをデプロイし、使用します。
これを実行する手順は次のとおりです。
- モデルを登録する
- エンドポイントと最初のデプロイを作成する
- 試験的な実行をデプロイする
- テスト データをデプロイに手動で送信する
- デプロイの詳細を取得する
- 2 つめのデプロイを作成する
- 2 つめのデプロイを手動でスケーリングする
- 両方のデプロイ間の運用トラフィックの割り当てを更新する
- 2 つめのデプロイの詳細を取得する
- 新しいデプロイをロールアウトし、最初のデプロイを削除する
この動画では、Azure Machine Learning スタジオでチュートリアルの手順を実行できるように準備する方法について説明します。 この動画では、ノートブックの作成、コンピューティング インスタンスの作成、ノートブックの複製を行う方法について説明します。 それらの手順については、以下のセクションでも説明します。
前提条件
-
Azure Machine Learning を使用するには、ワークスペースが必要です。 まだない場合は、作業を開始するために必要なリソースの作成を完了し、ワークスペースを作成してその使用方法の詳細を確認してください。
重要
Azure Machine Learning ワークスペースがマネージド仮想ネットワークを使用して構成されている場合、パブリック Python パッケージ リポジトリへのアクセスを許可するアウトバウンド規則の追加が必要になることがあります。 詳細については、「シナリオ: パブリック機械学習パッケージにアクセスする」を参照してください。
-
スタジオにサインインして、ワークスペースを選択します (まだ開いていない場合)。
-
ワークスペースでノートブックを開くか作成します。
- コードをコピーしてセルに貼り付ける場合は、新しいノートブックを作成します。
- または、スタジオの [サンプル] セクションから tutorials/get-started-notebooks/deploy-model.ipynb を開きます。 次に、[複製] を選択してノートブックをファイルに追加します。 サンプル ノートブックを見つけるには、「サンプル ノートブックから学習する」を参照してください。
VM クォータを表示し、オンライン デプロイを作成するのに十分なクォータを使用できることを確認します。 このチュートリアルでは、少なくとも
STANDARD_DS3_v2の 8 コアとSTANDARD_F4s_v2の 12 コアが必要です。 VM クォータの使用量と要求クォータの増加を表示するには、リソース クォータの管理に関する記事を参照してください。
カーネルを設定して Visual Studio Code (VS Code) で開く
コンピューティング インスタンスがまだない場合は、開いているノートブックの最上部のバーで作成します。

コンピューティング インスタンスが停止している場合は、[コンピューティングの開始] を選択して、実行されるまで待ちます。

コンピューティング インスタンスが実行中になるまで待ちます。 次に、右上にあるカーネルが
Python 3.10 - SDK v2であることを確認します。 そうでない場合は、ドロップダウン リストを使用してこのカーネルを選択します。
このカーネルが表示されない場合は、コンピューティング インスタンスが実行中であることを確認します。 そうである場合は、ノートブックの右上にある [更新] ボタンを選択します。
認証が必要であることを示すバナーが表示された場合は、[認証] を選択します。
ここでノートブックを実行するか、それを VS Code で開いて、Azure Machine Learning リソースの機能を備えた完全な統合開発環境 (IDE) を使用することができます。 [VS Code で開く] を選択し、Web またはデスクトップのオプションを選択します。 この方法で起動すると、コンピューティング インスタンス、カーネル、ワークスペース ファイル システムに VS Code がアタッチされます。
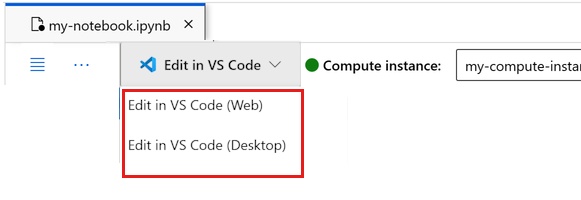




重要
このチュートリアルの残りの部分には、チュートリアル ノートブックのセルが含まれています。 それらをコピーして新しいノートブックに貼り付けるか、複製した場合はここでそのノートブックに切り替えます。
Note
- サーバーレス Spark コンピューティングでは、既定では
Python 3.10 - SDK v2がインストールされません。 このチュートリアルに進む前に、コンピューティング インスタンスを作成して選択することをお勧めします。
ワークスペースへのハンドルを作成する
コードについて詳しく説明する前に、ワークスペースを参照する方法が必要です。 ワークスペースに対するハンドルとして ml_client を作成し、ml_client を使ってリソースとジョブを管理します。
次のセルに、サブスクリプション ID、リソース グループ名、ワークスペース名を入力します。 これらの値を見つけるには:
- 右上隅の Azure Machine Learning スタジオ ツール バーで、ワークスペース名を選びます。
- ワークスペース、リソース グループ、サブスクリプション ID の値をコードにコピーします。
- 1 つの値をコピーし、領域を閉じて貼り付けてから、戻って次のものを処理する必要があります。
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Note
MLClient を作成しても、ワークスペースに接続はされません。 クライアントの初期化は遅延型であり、初めて呼び出す (これは、次のコード セルで行われます) 必要が生じるまで待機します。
モデルを登録する
前のトレーニング チュートリアルである「モデルをトレーニングする」を既に完了している場合は、トレーニング スクリプトの一部として MLflow モデルを登録しているため、次のセクションまでスキップできます。
トレーニング チュートリアルを完了していない場合は、モデルを登録する必要があります。 デプロイ前にモデルを登録することをお勧めします。
次のコードは、path (ファイルのアップロード元) インラインを指定します。
tutorials フォルダーを複製した場合は、次のコードをそのまま実行します。 それ以外の場合は、credit_defaults_model フォルダーからモデルのファイルとメタデータをダウンロードします。 ダウンロードしたファイルをコンピューターの credit_defaults_model フォルダーのローカル バージョンに保存し、次のコードのパスをダウンロードしたファイルの場所に更新します。
SDK がファイルを自動的にアップロードして、モデルを登録します。
モデルを資産として登録する方法の詳細については、「SDK を使用して、Machine Learning でモデルを資産として登録する」を参照してください。
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
モデルが登録されていることを確認する
Azure Machine Learning スタジオの [モデル] ページを確認して、登録したモデルの最新バージョンを特定できます。
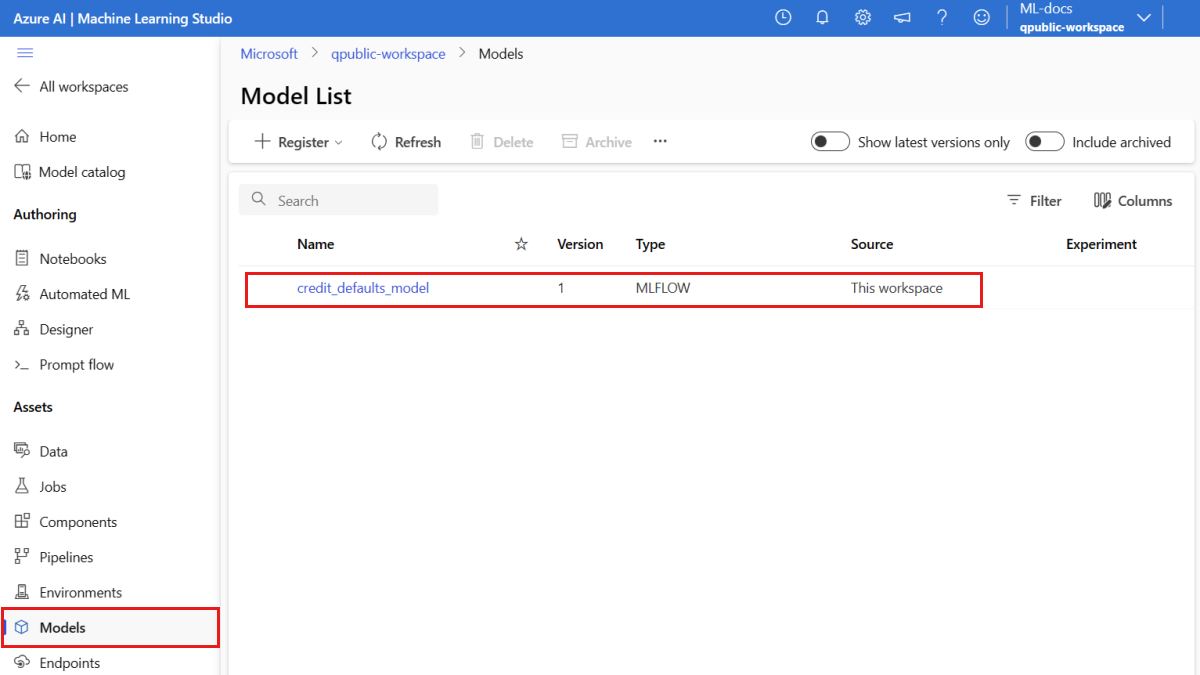
また、次のコードで、使う最新のバージョン番号を取得することもできます。
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
モデルが登録されたので、エンドポイントとデプロイを作成できます。 次のセクションでは、これらのトピックに関するいくつかの重要な詳細について簡単に説明します。
エンドポイントとデプロイ
機械学習モデルをトレーニングしたら、他のユーザーがそのモデルを使用して推論を実行できるようにするために、それをデプロイする必要があります。 この目的のために、Azure Machine Learning を使用してエンドポイントを作成し、それらにデプロイを追加できます。
この文脈でのエンドポイントは、クライアントがトレーニングされたモデルに要求 (入力データ) を送信し、モデルから推論 (スコアリング) 結果を受信するためのインターフェイスを提供する HTTPS パスです。 エンドポイントから提供されるもの:
- "キーまたはトークン" ベースの認証を使用する認証
- TLS(SSL) 終端
- 安定したスコアリング URI (endpoint-name.region.inference.ml.azure.com)
デプロイは、実際の推論を実行するモデルをホストするのに必要なリソースのセットです。
1 つのエンドポイントに複数のデプロイを含めることができます。 エンドポイントとデプロイは、Azure portal に表示される、独立した Azure Resource Manager リソースです。
Azure Machine Learning を使用すると、クライアント データに対するリアルタイム推論用のオンライン エンドポイントと、大量のデータを一定期間にわたって推論するためのバッチ エンドポイントを実装できます。
このチュートリアルでは、マネージド オンライン エンドポイントを実装する手順について順を追って説明します。 マネージド オンライン エンドポイントは、Azure の強力な CPU マシンおよび GPU マシンと連携して、スケーラブルでフル マネージドな方法で動作し、基になるデプロイ インフラストラクチャの設定と管理のオーバーヘッドからユーザーを解放します。
オンライン エンドポイントの作成
登録されたモデルができたので、次はオンライン エンドポイントを作成します。 エンドポイント名は、Azure リージョン全体で一意である必要があります。 このチュートリアルでは、汎用一意識別子 UUID を使用して一意の名前を作成します。 エンドポイントの名前付け規則の詳細については、エンドポイントの制限に関する記事を参照してください。
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
まず、ManagedOnlineEndpoint クラスを使用してエンドポイントを定義します。
ヒント
auth_mode: キーベースの認証にkeyを使用します。 Azure Machine Learning のトークン ベースの認証にaml_tokenを使用します。keyには有効期限がありませんが、aml_tokenには有効期限があります。 認証の詳細については、オンライン エンドポイントのクライアントを認証するに関する記事を参照してください。必要に応じて、エンドポイントに説明やタグを追加できます。
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
先ほど作成した MLClient を使用して、今度はワークスペースにエンドポイントを作成します。 このコマンドでは、エンドポイントの作成を開始し、エンドポイントの作成が続行されている間に確認応答を返します。
Note
エンドポイントの作成には約 2 分かかります。
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
エンドポイントを作成したら、次のようにして取得できます:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
オンライン デプロイについて
デプロイの主な側面には次のようなものがあります。
-
name- デプロイの名前。 -
endpoint_name- デプロイを含むエンドポイントの名前。 -
model- デプロイに使用するモデル。 この値は、ワークスペース内の既存のバージョン管理されたモデルへの参照またはインライン モデルの仕様のいずれかです。 -
environment- デプロイに使用する (またはモデルを実行する) 環境。 この値は、ワークスペース内の既存のバージョン管理された環境への参照、またはインライン環境仕様のいずれかになります。 この環境には、Conda 依存関係がある Docker イメージか、または Dockerfile のいずれかを使用できます。 -
code_configuration- ソース コードとスコアリング スクリプトの構成。-
path- モデルをスコアリングするためのソース コード ディレクトリへのパス。 -
scoring_script- ソース コード ディレクトリ内のスコアリング ファイルへの相対パス。 このスクリプトは、指定した入力要求に対してモデルを実行します。 スコアリング スクリプトの例については、オンライン エンドポイントで ML モデルをデプロイする方法に関する記事の「スコアリング スクリプトを理解する」を参照してください。
-
-
instance_type- デプロイに使用する VM サイズ。 サポートされているサイズの一覧については、マネージド オンライン エンドポイント SKU の一覧に関するページを参照してください。 -
instance_count- デプロイに使用するインスタンスの数。
MLflow モデルを使用したデプロイ
Azure Machine Learning は、MLflow で作成および記録したモデルのコードなしのデプロイをサポートしています。 つまり、MLflow モデルのトレーニング時にスコアリング スクリプトと環境が自動的に生成されるため、モデルのデプロイ中にスコアリング スクリプトや環境を提供する必要はありません。 ただし、カスタム モデルを使用していた場合は、デプロイ時に環境とスコアリング スクリプトを指定する必要があります。
重要
通常、スコアリング スクリプトとカスタム環境を使用してモデルをデプロイしていて、MLflow のモデルを使用して同じ機能を実現するには、MLflow モデルをデプロイするためのガイドラインに関する記事をご覧ください。
モデルをエンドポイントにデプロイする
まず、受信トラフィックの 100% を処理する 1 つのデプロイを作成します。 デプロイに任意の色名 (blue) を選択します。 エンドポイントのデプロイを作成するために、ManagedOnlineDeployment クラスを使用します。
Note
デプロイするモデルが MLflow モデルであるため、環境やスコアリング スクリプトを指定する必要はありません。
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
先ほど作成した MLClient を使用して、今度はワークスペースにデプロイを作成します。 このコマンドでは、デプロイの作成を開始し、デプロイの作成が続行されている間に確認応答を返します。
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
エンドポイントの状態を確認する
エンドポイントの状態をチェックして、モデルがエラーなしでデプロイされたかどうかを確認できます。
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
サンプル データを使用してエンドポイントをテストする
モデルがエンドポイントにデプロイされたので、これを使って推論を実行できます。 まず、スコアリング スクリプトの run メソッドで想定される設計に従って、サンプル要求ファイルを作成します。
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
次に、デプロイ ディレクトリにファイルを作成します。 次のコード セルでは、IPython マジックを使用して、先ほど作成したディレクトリにファイルを書き込みます。
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
先ほど作成した MLClient を使用して、エンドポイントへのハンドルを取得します。 エンドポイントは、次のパラメーターを指定した invoke コマンドを使用して呼び出すことができます:
-
endpoint_name- エンドポイントの名前 -
request_file- 要求データを含むファイル -
deployment_name- エンドポイント内のテストする特定のデプロイの名前
サンプル データを使用して blue デプロイをテストします。
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
デプロイのログを取得する
ログを確認して、エンドポイント/デプロイが正常に呼び出されたかどうかを確認します。 エラーが発生した場合、「オンライン エンドポイントのデプロイのトラブルシューティング」を参照してください。
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
2 つめのデプロイを作成する
green という名前の 2 つめのデプロイとしてモデルをデプロイします。 実際には、複数のデプロイを作成し、そのパフォーマンスを比較できます。 これらのデプロイに、同じモデルの異なるバージョン、異なるモデル、またはより強力なコンピューティング インスタンスを使用できます。
この例では、パフォーマンスを向上させる可能性のあるより強力なコンピューティング インスタンスを使用して、同じモデル バージョンをデプロイします。
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
より多くのトラフィックを処理できるようにデプロイをスケーリングする
先ほど作成した MLClient を使用して、green デプロイへのハンドルを取得します。 デプロイは、instance_count を増減することでスケーリングできます。
次のコードでは、VM インスタンスを手動で増やします。 ただし、オンライン エンドポイントを自動スケーリングすることもできます。 自動スケールでは、アプリケーションの負荷を処理するために適切な量のリソースが自動的に実行されます。 マネージド オンライン エンドポイントでは、Azure Monitor 自動スケーリング機能との統合によって、自動スケーリングをサポートします。 自動スケールを構成するには、「オンライン エンドポイントを自動スケーリングする」をご覧ください。
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
デプロイのトラフィック割り当てを更新する
運用環境のトラフィックをデプロイ間で分割できます。 まず、blue デプロイで行ったのと同様に、サンプル データを使って green デプロイをテストできます。 green デプロイをテストしたら、それにトラフィックのごく一部を割り当てます。
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
エンドポイントを数回呼び出して、トラフィックの割り当てをテストします。
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
green デプロイのログを表示して、受信要求があり、モデルが正常にスコア付けされたことを確認します。
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Azure Monitor を使用してメトリックを表示する
スタジオのエンドポイントの [詳細] ページのリンクをたどると、オンライン エンドポイントとそのデプロイのさまざまなメトリック (要求番号、要求の待機時間、ネットワーク バイト、CPU/GPU/ディスク/メモリの使用状況など) を表示できます。 これらのリンクのいずれかに従うと、エンドポイントまたはデプロイの Azure portal の正確なメトリック ページに移動します。
![オンライン エンドポイントとデプロイのメトリックを表示するためのエンドポイントの [詳細] ページのリンクを示すスクリーンショット。](media/tutorial-deploy-model/deployment-metrics-from-endpoint-details-page.png?view=azureml-api-2#lightbox)
オンライン エンドポイントのメトリックを開くと、次の図に示すように、要求の平均待機時間などのメトリックを表示するようにページを設定できます。

オンライン エンドポイント メトリックを表示する方法の詳細については、「オンライン エンドポイントを監視する」を参照してください。
すべてのトラフィックを新しいデプロイに送信する
green デプロイに問題がなければ、すべてのトラフィックをそのデプロイに切り替えます。
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
古いデプロイを削除する
次のように古い (blue) デプロイを削除します。
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
リソースをクリーンアップする
このチュートリアルの完了後にエンドポイントとデプロイを使用する予定がない場合は、削除してください。
Note
完全な削除には約 20 分かかります。
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
すべてを削除する
Azure Machine Learning ワークスペースとすべてのコンピューティング リソースを削除するには、次の手順を使用します。
重要
作成したリソースは、Azure Machine Learning に関連したその他のチュートリアルおよびハウツー記事の前提条件として使用できます。
作成したどのリソースも今後使用する予定がない場合は、課金が発生しないように削除します。
Azure portal の検索ボックスに「リソース グループ」と入力し、それを結果から選択します。
一覧から、作成したリソース グループを選択します。
[概要] ページで、[リソース グループの削除] を選択します。
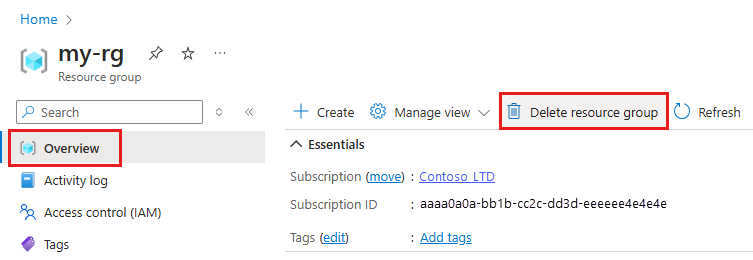
リソース グループ名を入力します。 次に、 [削除] を選択します。