チュートリアル: 初めての機械学習モデルをトレーニングする (SDK v1、パート 2/3)
適用対象:  Python SDK azureml v1
Python SDK azureml v1
このチュートリアルでは、Azure Machine Learning で機械学習モデルをトレーニングする方法について説明します。 このチュートリアルは、2 部構成のチュートリアル シリーズのパート 2 です。
シリーズの "Hello world!" の実行に関する「パート 1」では、コントロール スクリプトを使ってクラウドでジョブを実行する方法について学習しました。
このチュートリアルでは、機械学習モデルをトレーニングするスクリプトを送信して、次のステップに進みます。 この例は、Azure Machine Learning を使用することで、ローカル デバッグとリモート実行との間で一貫した動作がどのように容易になるかを理解するのに役立ちます。
このチュートリアルでは、次の作業を行いました。
- トレーニング スクリプトを作成します。
- Conda を使用して Azure Machine Learning 環境を定義する。
- コントロール スクリプトを作成する。
- Azure Machine Learning クラス (
Environment、Run、Metrics) について理解する。 - トレーニング スクリプトを送信して実行する。
- クラウドでのコード出力を表示する。
- メトリックを Azure Machine Learning にログする。
- クラウドのメトリックを表示する。
前提条件
- このシリーズの第 1 部を完了している。
トレーニング スクリプトを作成する
まず、model.py ファイルでニューラル ネットワーク アーキテクチャを定義します。 すべてのトレーニング コードは、src サブディレクトリ (model.py を含む) に入ります。
トレーニング コードは、PyTorch のこの入門の例からの抜粋です。 Azure Machine Learning の概念は、PyTorch だけでなく、機械学習コードにも適用されます。
src サブフォルダーに model.py ファイルを作成します。 そのファイルにこのコードをコピーします。
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xツール バーの [保存] を選択してファイルを保存します。 必要に応じてタブを閉じます。
次に、同じ src サブフォルダーに、トレーニング スクリプトを定義します。 このスクリプトは、PyTorch
torchvision.datasetAPI を使用して CIFAR10 データセットをダウンロードし、model.py で定義されているネットワークを設定して、標準の SGD とクロスエントロピ損失を使用して 2 つのエポックに対してトレーニングを行います。src サブフォルダーに train.py スクリプトを作成します。
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")フォルダー構造は次のようになります。
ローカルでテストする
[Save and run script in terminal](スクリプトを保存してターミナルで実行する) を選択して、コンピューティング インスタンス上で直接 train.py スクリプトを実行します。
スクリプトの完了後、ファイル フォルダーの上にある [Refresh](最新の情報に更新) を選択します。 get-started/data という新しいデータ フォルダーが表示されます。このフォルダーを展開すると、ダウンロードしたデータが表示されます。
Python 環境の作成
Azure Machine Learning では、実験を実行するための、再現可能でバージョン管理された Python 環境を表す環境の概念が提供されます。 ローカルの Conda 環境または pip 環境から環境を簡単に作成できます。
まず、パッケージの依存関係を示したファイルを作成します。
get-started フォルダーに、
pytorch-env.ymlという新しいファイルを作成します。name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionツール バーの [保存] を選択してファイルを保存します。 必要に応じてタブを閉じます。
コントロール スクリプトを作成する
下のコントロール スクリプトと "Hello World!" の送信に使ったコントロール スクリプトとの違いは、環境を設定するための行をいくつか追加することです。
get-started フォルダーに、run-pytorch.py という新しい Python ファイルを作成します。
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
ヒント
コンピューティング クラスターの作成時に別の名前を使用した場合は、compute_target='cpu-cluster' コード内の名前も調整してください。
コードの変更を理解する
env = ...
上で作成した依存関係ファイルを参照します。
config.run_config.environment = env
ScriptRunConfig に環境を追加します。
Azure Machine Learning に実行を送信する
[Save and run script in terminal](スクリプトを保存してターミナルで実行する) を選択して run-pytorch.py スクリプトを実行します。
開いたターミナル ウィンドウにリンクが表示されます。 リンクを選択してジョブを表示します。
Note
azureml_run_type_providers の読み込み中にエラーが発生し... から始まるいくつかの警告が表示される場合があります。これらの警告は無視してかまいません。 これらの警告の下部にあるリンクを使用して、出力を表示してください。
出力を表示する
- 開いたページに、ジョブの状態が表示されます。 このスクリプトを初めて実行すると、Azure Machine Learning によって PyTorch 環境から新しい Docker イメージが構築されます。 ジョブ全体が完了するまでに 10 分程度かかる場合があります。 このイメージは、今後のジョブで再利用され、実行がさらに高速化されます。
- Docker ビルド ログは、Azure Machine Learning スタジオで確認できます。 ビルド ログを表示するには、次のようにします。
- [出力 + ログ] タブを選択します。
- azureml-logs フォルダー 選択します。
- 20_image_build_log.txt を選択します。
- ジョブの状態が [完了済み] の場合、[出力とログ] を選択します。
- user_logs、std_log.txt の順に選択して、ジョブの出力を表示します。
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
"Your total snapshot size exceeds the limit (合計スナップショット サイズが上限を超えました)" というエラーが表示された場合、ScriptRunConfig で使用されている値 source_directory に data フォルダーが存在します。
フォルダーの末尾にある [...] を選択し、 [移動] を選択して、data を get-started フォルダーに移動します。
トレーニング メトリックをログする
これで Azure Machine Learning でのモデル トレーニングが完了したので、いくつかのパフォーマンス メトリックの追跡を開始します。
現在のトレーニング スクリプトは、メトリックをターミナルに出力します。 Azure Machine Learning には、より多くの機能を備えたメトリックをログするためのメカニズムが用意されています。 数行のコードを追加することで、スタジオでメトリックを視覚化したり、複数のジョブ間でメトリックを比較したりできるようになります。
train.py にログ機能を追加する
train.py スクリプトに 2 行のコードを追加します。
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')このファイルを保存し、必要に応じてタブを閉じます。
追加する 2 行のコードを理解する
train.py で、Run.get_context() メソッドを使用してトレーニング スクリプト自体の "内部" から実行オブジェクトにアクセスし、それを使用してメトリックをログします。
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Azure Machine Learning のメトリックは次のとおりです。
- 実験ごとに整理されて実行されるため、メトリックの追跡と比較が簡単です。
- UI を備えているため、スタジオでトレーニングのパフォーマンスを視覚化できます。
- スケーリングするように設計されているため、数百回の実験を実行してもこれらのベネフィットを維持できます。
Conda 環境ファイルを更新する
train.py スクリプトにより、azureml.core に対して新しい依存関係が作成されました。 この変更を反映するように pytorch-env.yml を更新します。
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
実行を送信する前に、必ずこのファイルを保存してください。
Azure Machine Learning に実行を送信する
run-pytorch.py スクリプトのタブを選択し、[Save and run script in terminal]\(スクリプトを保存してターミナルで実行する\) を選択して、run-pytorch.py スクリプトを再実行します。 まず、変更を pytorch-env.yml に保存したことを確認します。
今回は、スタジオにアクセスしたら、 [メトリック] タブに移動します。このタブで、モデル トレーニングの損失に関するライブ更新を確認できます。 トレーニングが開始されるまでに 1 分から 2 分かかる場合があります。
![[メトリック] タブのトレーニング損失グラフ](media/tutorial-1st-experiment-sdk-train/logging-metrics.png?view=azureml-api-1)
リソースをクリーンアップする
引き続き別のチュートリアルを行う場合や、独自のトレーニング ジョブを始める場合は、「関連リソース」に進んでください。
コンピューティング インスタンスを停止する
コンピューティング インスタンスをすぐに使用しない場合は、停止してください。
- スタジオの左側にある [コンピューティング] を選択します。
- 上部のタブで、 [コンピューティング インスタンス] を選択します
- 一覧からコンピューティング インスタンスを選択します。
- 上部のツールバーで、 [停止] を選択します。
すべてのリソースの削除
重要
作成したリソースは、Azure Machine Learning に関連したその他のチュートリアルおよびハウツー記事の前提条件として使用できます。
作成したどのリソースも今後使用する予定がない場合は、課金が発生しないように削除します。
Azure portal の検索ボックスに「リソース グループ」と入力し、それを結果から選択します。
一覧から、作成したリソース グループを選択します。
[概要] ページで、[リソース グループの削除] を選択します。
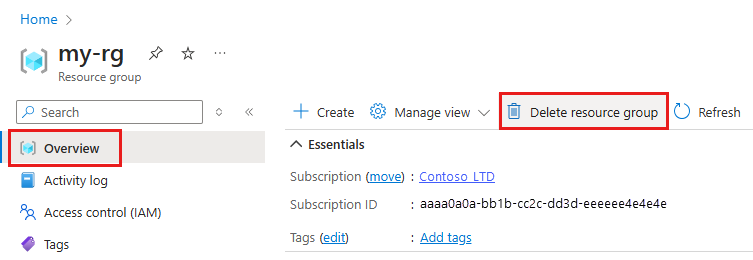
リソース グループ名を入力します。 次に、 [削除] を選択します。
リソース グループは保持しつつ、いずれかのワークスペースを削除することもできます。 ワークスペースのプロパティを表示し、 [削除] を選択します。
関連リソース
このセッションでは、基本的な "Hello world!" スクリプトから、特定の Python 環境を実行する必要があるより現実的なトレーニング スクリプトにアップグレードしました。 キュレーションされた Azure Machine Learning 環境を使用する方法について確認しました。 最後に、数行のコードでメトリックを Azure Machine Learning にログする方法を確認しました。
Azure Machine Learning 環境を作成する方法は他にもあります。たとえば、pip requirements.txt ファイルから、または既存のローカル Conda 環境から作成することができます。