Azure Machine Learning の Index Lookup ツール (プレビュー)
プロンプト フローの Index lookup ツール を使用すると、プロンプト フローで一般的なベクター インデックス (Azure AI Search、FAISS、Pinecone など) を使用して、拡張生成 (RAG) を取得できます。 このツールは、ワークスペース内のインデックスを自動的に検出し、フローで使用するインデックスの選択を許可します。
重要
Index Lookup ツールは現在、パブリック プレビュー段階にあります。 このプレビュー版はサービス レベル アグリーメントなしで提供されています。運用環境のワークロードに使用することはお勧めできません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
Index Lookup ツールを使用したビルド
Azure Machine Learning スタジオでフローを作成または開きます。 詳細については、「フローの作成」を参照してください。
[+ その他のツール]>[Index Lookup] の順に選択し、Index Lookup ツールをフローに追加します。
![Azure Machine Learning スタジオの Index Lookup ツールを示す [More tools] (その他のツール) ボタンとドロップダウンのスクリーンショット。](media/index-lookup-tool/more-tools.png?view=azureml-api-2)
必要に応じて、他のツールをフローに追加するか、[実行] を選択してフローを実行します。
返される出力の詳細については、「出力」を参照してください。

入力
使用できる入力パラメーターを次に示します。
| Name | 種類 | 内容 | 必須 |
|---|---|---|---|
| mlindex_content | string | 使用するインデックスの種類。 入力はインデックスの種類によって異なります。 Azure Cog Search Index JSON の例は、次の表に示されています* | はい |
| Query | string, Union[string, List[String]] | クエリ対象となるテキスト。 | はい |
| query_type | string | 実行するクエリの種類。 オプションには、キーワード、セマンティック、ハイブリッドなどがあります。 | はい |
| top_k | 整数 (integer) | 返される上位スコアのエンティティ数。 既定値は 3 です。 | いいえ |
*ACS JSON の使用例:
embeddings:
api_base: <api_base>
api_type: azure
api_version: 2023-07-01-preview
batch_size: '1'
connection:
id: /subscriptions/<subscription>/resourceGroups/<resource_group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace> /connections/<AOAI_connection>
connection_type: workspace_connection
deployment: <embedding_deployment>
dimension: <embedding_model_dimension>
kind: open_ai
model: <embedding_model>
schema_version: <version>
index:
api_version: 2023-07-01-Preview
connection:
id: /subscriptions/<subscription>/resourceGroups/<resource_group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace> /connections/<cogsearch_connection>
connection_type: workspace_connection
endpoint: <cogsearch_endpoint>
engine: azure-sdk
field_mapping:
content: id
embedding: content_vector_open_ai
metadata: id
index: <index_name>
kind: acs
semantic_configuration_name: azureml-default
出力
ツールによって返される JSON 形式の応答の例を次に示します。この応答にはスコアが上位 k 個のエンティティが含まれています。 エンティティは、promptflow-vectordb SDK で提供されるベクトル検索結果の汎用スキーマに従います。 Vector Index Search では、次のフィールドに値が入力されます。
| フィールド名 | Type | 説明 |
|---|---|---|
| metadata | dict | ユーザーがインデックス作成時に提供する、カスタマイズされたキーと値のペア |
| page_content | string | 参照で使用されているベクター チャンクの内容 |
| score | float | Vector Index で定義されたインデックス タイプに依存します。 インデックスの種類が Faiss の場合、スコアは L2 距離です。 インデックスの種類が Azure AI Search の場合、スコアはコサインの類似度です。 |
[
{
"metadata":{
"answers":{},
"captions":{
"highlights":"sample_highlight1",
"text":"sample_text1"
},
"page_number":44,
"source":{
"filename":"sample_file1.pdf",
"mtime":1686329994,
"stats":{
"chars":4385,
"lines":41,
"tiktokens":891
},
"url":"sample_url1.pdf"
},
"stats":{
"chars":4385,"lines":41,"tiktokens":891
}
},
"page_content":"vector chunk",
"score":0.021349556744098663
},
{
"metadata":{
"answers":{},
"captions":{
"highlights":"sample_highlight2",
"text":"sample_text2"
},
"page_number":44,
"source":{
"filename":"sample_file2.pdf",
"mtime":1686329994,
"stats":{
"chars":4385,
"lines":41,
"tiktokens":891
},
"url":"sample_url2.pdf"
},
"stats":{
"chars":4385,"lines":41,"tiktokens":891
}
},
"page_content":"vector chunk",
"score":0.021349556744098663
},
]
従来のツールからインデックス参照ツールに移行する方法
インデックス参照ツールは、非推奨となっているベクター インデックス参照ツール、ベクター DB 参照ツール、Faiss インデックス参照ツールという 3 つの従来のインデックス ツールを置き換えます。 これらのツールのいずれかを含むフローがある場合は、次の手順に従ってフローをアップグレードします。
ツールのアップグレード
フローに移動します。 これを行うには、[作成] の [Prompt flow] (プロンプト フロー) タブを選択し、[フロー] ピボット タブを選択し、さらにフローの名前を選択します。
フロー内で、ウィンドウの上部付近にある [+ More tools] (+ その他のツール) ボタンを選択します。 ドロップダウンが開いたら、[Index Lookup [Preview]] (Index Lookup [プレビュー]) を選択して、Index Lookup ツールのインスタンスを追加します。
![プロンプト フローの [More Tools] (その他のツール) ドロップダウンのスクリーンショット。](media/index-lookup-tool/index-dropdown.png?view=azureml-api-2)
新しいノードに名前を付け、[追加] を選択します。

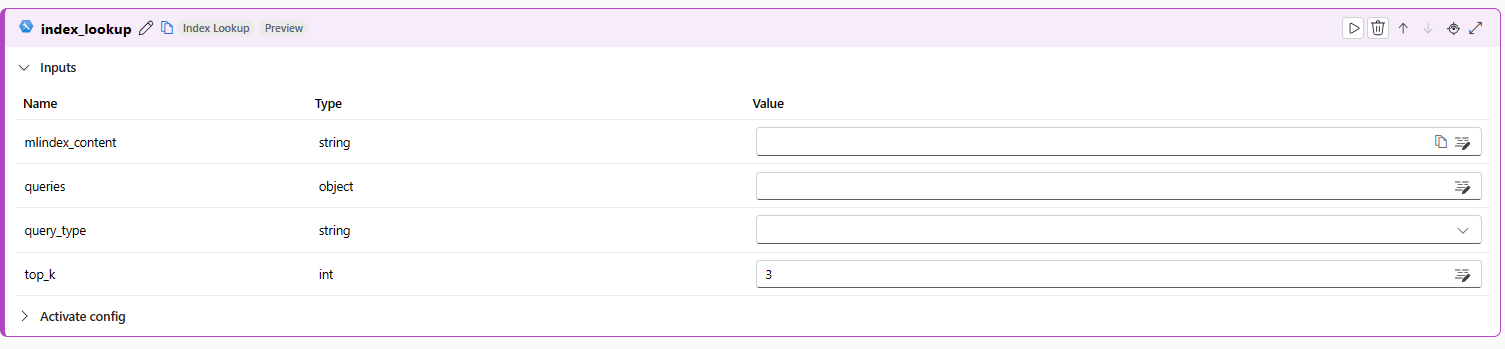
新しいノードで、[mlindex_content] テキスト ボックスを選択します。 これは、リスト内の最初のテキスト ボックスです。
![[mlindex_content] ボックスが赤で囲まれた展開されたインデックス参照ノードのスクリーンショット。](media/index-lookup-tool/mlindex-box.png?view=azureml-api-2)
表示される Generate ドロワーで、次の手順に従って、3 つの従来のツールからアップグレードします。
- 従来のベクター インデックス参照 ツールを使用している場合は、[index_type] ドロップダウンで [登録済みインデックス] を選択します。 [mlindex_asset_id] ドロップダウンからベクター インデックス アセットを選択します。
- 従来の Faiss インデックス参照ツールを使用している場合は、[index_type] ドロップダウンで [Faiss] を選択し、従来のツールと同じパスを指定します。
- 従来のベクター DB 参照ツールを使用している場合は、[index_type] ドロップダウンで DB の種類に応じて [AI Search] または [Pinecone] を選択し、必要な情報を入力します。
必要な情報を入力したら、[保存] を選択します。
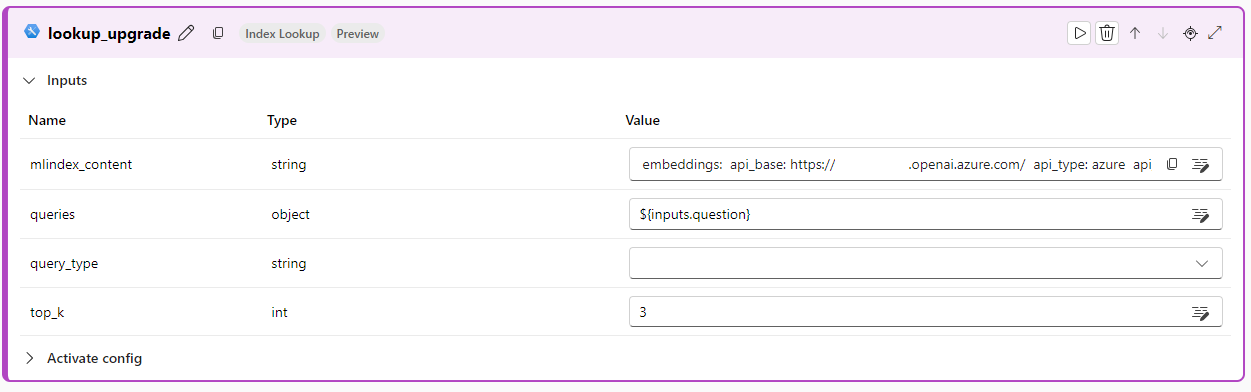
ノードに戻ると、[mlindex_content] テキスト ボックスに情報が入力された状態になります。 次の [queries] テキスト ボックスを選択し、クエリを行う検索語句を選択します。 “embed_the_question” ノードへの入力と同じ値 (通常は ”${inputs.question}” または “${modify_query_with_history.output}”) を選択します (標準フローの場合は前者、チャット フローの場合は後者)。
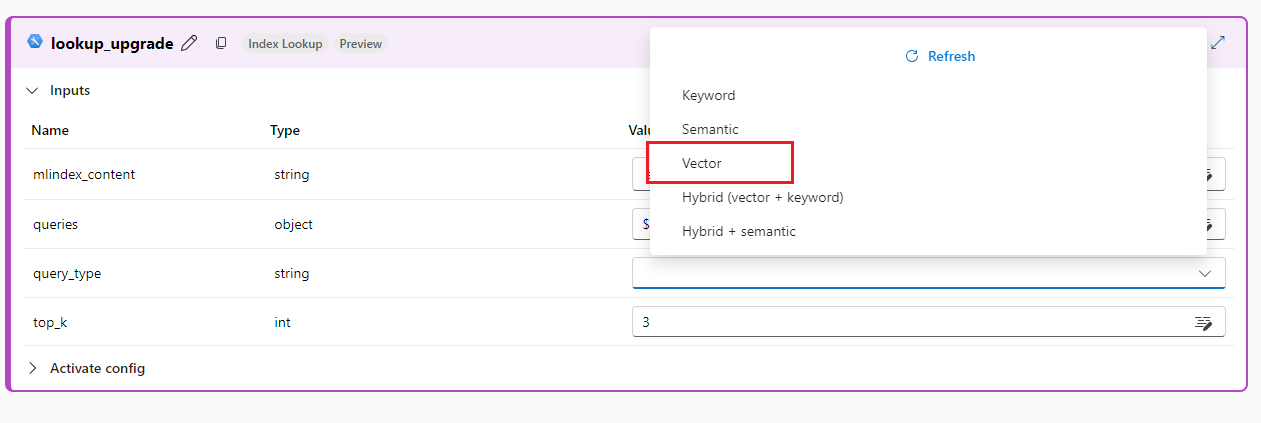
[query_type] の横にあるドロップダウンをクリックして、クエリの種類を選択します。 “Vector” では従来のフローと同じ結果が生成されますが、インデックスの構成によっては、"Hybrid" や "Semantic" などの他のオプションを使用できる場合があります。
ダウンストリーム コンポーネントを編集して、従来のベクター インデックス参照ノードの出力ではなく、新しく追加されたノードの出力を使用します。
ベクター インデックス参照ノードとその親埋め込みノードを削除します。
![プロンプト フローの [More Tools] (その他のツール) ドロップダウンのスクリーンショット。](media/index-lookup-tool/index-dropdown.png?view=azureml-api-2#lightbox)

![[mlindex_content] ボックスが赤で囲まれた展開されたインデックス参照ノードのスクリーンショット。](media/index-lookup-tool/mlindex-box.png?view=azureml-api-2#lightbox)

