リアルタイム推論を行うためにマネージド オンライン エンドポイントとしてフローをデプロイする
適切にフローを構築してテストしたら、リアルタイム推論のためにエンドポイントを呼び出せるように、フローをエンドポイントとしてデプロイすることができます。
この記事では、リアルタイム推論を行うためにフローをマネージド オンライン エンドポイントとしてデプロイする方法について説明します。 これを実行する手順は次のとおりです。
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 プレビュー バージョンはサービス レベル アグリーメントなしで提供されています。運用環境のワークロードに使用することはお勧めできません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
前提条件
プロンプト フローでフローを構築してテストする方法を確認します。
マネージド オンライン エンドポイントに関する基本事項を理解している。 マネージド オンライン エンドポイントは、Azure の強力な CPU マシンおよび GPU マシンと連携して、スケーラブルでフル マネージドな方法で動作し、基になるデプロイ インフラストラクチャの設定と管理のオーバーヘッドからユーザーを解放します。 マネージド オンライン エンドポイントの詳細については、「オンライン エンドポイントとリアルタイム推論のデプロイ」 を参照してください。
Azure ロールベースのアクセス制御 (Azure RBAC) は、Azure Machine Learning の操作に対するアクセスを許可するために使用されます。 プロンプト フローでエンドポイントをデプロイできるようにするには、AzureML データ科学者、または Azure Machine Learning ワークスペースに対してさらに多くの特権を持つロールがユーザー アカウントに割り当てられている必要があります。
マネージド ID の基礎知識を習得します。 マネージド ID の詳細を確認してください。
Note
マネージド オンライン エンドポイントがサポートするのは、マネージド仮想ネットワークだけです。 ワークスペースがカスタム VNet 内にある場合は、他のデプロイ オプション (CLI/SDK を使った Kubernetes オンライン エンドポイントへのデプロイや、Docker などの他のプラットフォームへのデプロイなど) を試す必要があります。
フローを構築し、デプロイの準備を整える
基本のチュートリアルを既に完了している場合は、バッチ実行を送信して結果を評価するというフローのテストは適切に完了しています。
このチュートリアルを完了していない場合は、フローを構築する必要があります。 デプロイ前にバッチ実行と評価によってフローを適切にテストすることが推奨されるベスト プラクティスです。
例としてサンプル フロー Web 分類を使ってフローのデプロイ方法を説明します。 このサンプル フローは標準のフローです。 チャット フローのデプロイも同様です。 評価フローはデプロイをサポートしていません。
デプロイで使用される環境を定義する
UI でマネージド オンライン エンドポイントにプロンプト フローをデプロイする場合、既定で、デプロイでは、フローの requirements.txt で指定された最新のプロンプト フロー イメージと依存関係に基づいて作成された環境が使用されます。 requirements.txt で、必要な追加のパッケージを指定できます。 requirements.txt は、フロー フォルダーのルート フォルダーにあります。

Note
Azure DevOps でプライベート フィードを使用している場合は、まずプライベート フィードを使用してイメージをビルドし、UI でデプロイするカスタム環境を選択する必要があります。
オンライン デプロイを作成する
フローを構築し、適切にテストしたら、リアルタイム推論を行うためのオンライン エンドポイントを作成します。
プロンプト フローは、フローまたはバッチ実行からエンドポイントをデプロイすることをサポートします。 デプロイ前にフローをテストすることが推奨されるベスト プラクティスです。
フローの作成ページまたは実行の詳細ページで [デプロイ] を選びます。
フローの作成ページ:

実行の詳細ページ:

エンドポイントを構成するウィザードが表示されます。次の手順があります。
基本設定

この手順では、デプロイの基本設定を構成できます。
| プロパティ | 説明 |
|---|---|
| エンドポイント | 新しいエンドポイントをデプロイするか、既存のエンドポイントを更新するかを選択できます。 [新規] を選択した場合は、エンドポイント名を指定する必要があります。 |
| デプロイ名 | - 同じエンドポイント内では、デプロイ名は一意である必要があります。 - 既存のエンドポイントを選択し、既存のデプロイ名を入力した場合、そのデプロイは新しい構成で上書きされます。 |
| 仮想マシン | デプロイに使用する VM サイズ。 サポートされているサイズの一覧については、マネージド オンライン エンドポイント SKU の一覧に関するページを参照してください。 |
| インスタンス数 | デプロイに使用するインスタンスの数。 想定されるワークロードに値を指定します。 高可用性を実現するために、この値を少なくとも 3 に設定することをお勧めします。 アップグレードを実行するために 20% 余分に予約されています。 詳細については、マネージド オンライン エンドポイントのクォータに関する記事を参照してください。 |
| 推論データの収集 | これを有効にすると、フローの入力と出力が Azure Machine Learning データ資産で自動的に収集され、後で監視するために使用できます。 詳細については、生成 AI アプリケーションを監視する方法に関するページを参照してください。 |
基本設定が完了したら、[確認および作成] を直接選択して作成を完了するか、[次へ] を選択して [詳細設定] を構成できます。
詳細設定 - エンドポイント
エンドポイントに次の設定を指定できます。

認証の種類
エンドポイントの認証方法。 キーベースの認証により、有効期限のない主キーとセカンダリ キーが提供されます。 Azure Machine Learning トークンベースの認証により、定期的に自動更新されるトークンが提供されます。 認証の詳細については、オンライン エンドポイントの認証に関する記事を参照してください。
ID の種類
推論するには、エンドポイントから Azure コンテナー レジストリやワークスペース接続などの Azure リソースにアクセスする必要があります。 マネージド ID にアクセス許可を付与することで、Azure リソースにアクセスできるアクセス許可をエンドポイントに付与することができます。
システム割り当て ID はエンドポイントの作成後に自動作成されますが、ユーザー割り当て ID はユーザーが作成します。 マネージド ID の詳細を確認してください。
システム割り当て
接続シークレットへのアクセスを実施する (プレビュー) かどうかのオプションがあることがわかります。 フローで接続が使用される場合、エンドポイントは推論を実行するために接続にアクセスする必要があります。 このオプションは既定で有効になっています。接続シークレット閲覧者アクセス許可がある場合、接続に自動的にアクセスするための Azure Machine Learning ワークスペース接続シークレット閲覧者ロールがエンドポイントに付与されます。 このオプションを無効にする場合は、自分でシステム割り当て ID にこのロールを手動で付与するか、管理者に支援を求める必要があります。詳しくは、エンドポイント ID にアクセス許可を付与する方法をご覧ください。
ユーザー割り当て
デプロイの作成中に、Azure では、ワークスペースの Azure Container Registry (ACR) からユーザー コンテナー イメージをプルし、ユーザー モデルとコード成果物をワークスペース ストレージ アカウントからユーザー コンテナーにマウントしようとします。
ユーザー割り当て ID に関連付けられたエンドポイントを作成した場合、デプロイの作成前に、次のロールがユーザー割り当て ID に付与されている必要があります。そうしないと、デプロイの作成が失敗します。
| Scope | ロール | 必要な理由 |
|---|---|---|
| Azure Machine Learning ワークスペース | Azure Machine Learning ワークスペース接続シークレット閲覧者ロールまたは "Microsoft.MachineLearningServices/workspaces/connections/listsecrets/action" を持つカスタマイズされたロール | ワークスペース接続の取得 |
| ワークスペース コンテナー レジストリ | ACR のプル | コンテナー イメージのプル |
| ワークスペースの既定のストレージ | ストレージ BLOB データ閲覧者 | ストレージからのモデルの読み込み |
| (省略可能) Azure Machine Learning ワークスペース | ワークスペース メトリック ライター | エンドポイントをデプロイした後、CPU、GPU、ディスク、メモリ使用率などのエンドポイント関連のメトリックを監視する場合は、このアクセス許可を ID に付与する必要があります。 |
エンドポイント ID にアクセス許可を付与する方法の詳細なガイダンスについては、「エンドポイントにアクセス許可を付与する」を参照してください。
重要
フローで Microsoft Entra ID ベース認証の接続を使う場合は、システム割り当て ID を使うかユーザー割り当て ID を使うかに関わらず、常にマネージド ID に対して対応するリソースの適切なロールを付与して、マネージド ID がそのリソースに対する API 呼び出しを行えるようにする必要があります。 たとえば、Azure OpenAI 接続で Microsoft Entra ID ベースの認証を使う場合は、エンドポイント マネージド ID に対して、対応する Azure OpenAI リソースの Cognitive Services OpenAI ユーザーまたは Cognitive Services OpenAI 共同作成者ロールを付与する必要があります。
詳細設定 - デプロイ
この手順では、タグを除き、デプロイで使用される環境を指定することもできます。

現在のフロー定義の環境を使用する
既定のデプロイでは、flow.dag.yaml で指定されている基本イメージと、requirements.txt で指定されている依存関係に基づいて作成された環境が使われます。
フローの
Raw file modeを選ぶと、flow.dag.yamlで基本イメージを指定できます。 イメージが指定されていない場合は、最新のプロンプト フローの基本イメージが既定の基本イメージになります。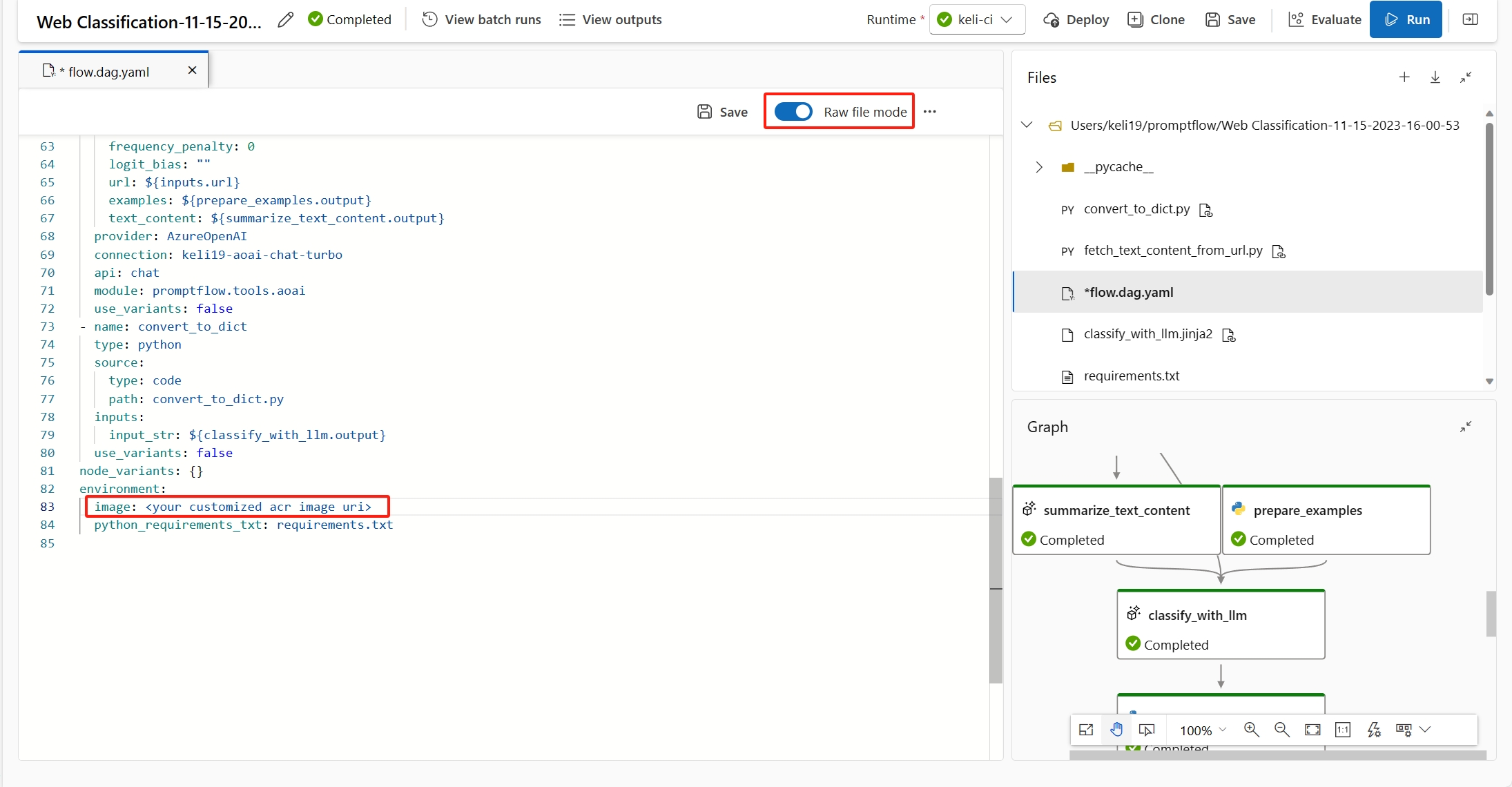
フロー フォルダーのルート フォルダーで
requirements.txtを見つけて、その中の依存関係を追加できます。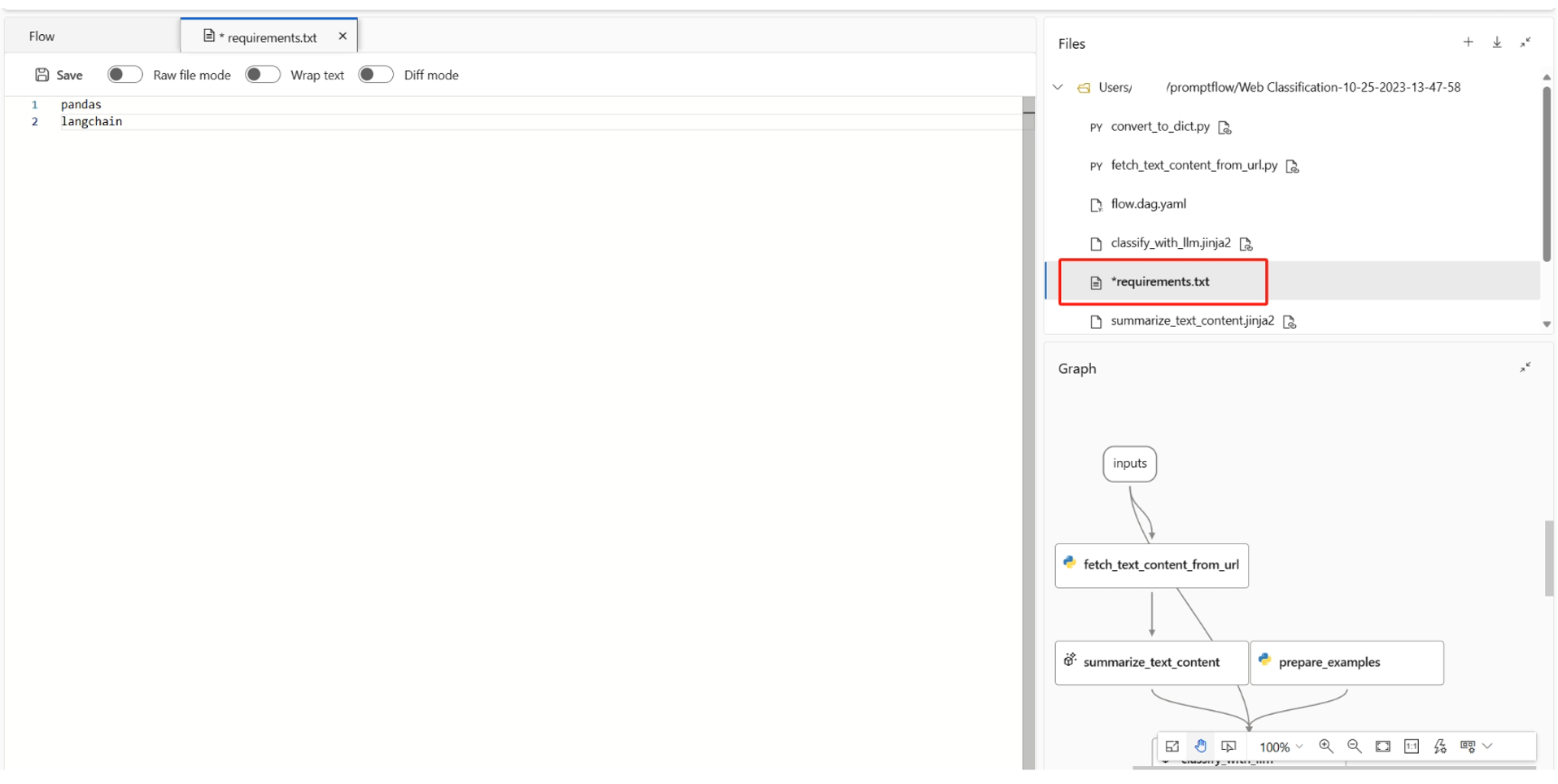

カスタマイズされた環境を使用する
カスタマイズされた環境を作成して、デプロイに使うこともできます。
Note
カスタム環境は、次の要件を満たす必要があります。
- Docker イメージは、プロンプト フローの基本イメージ
mcr.microsoft.com/azureml/promptflow/promptflow-runtime-stable:<newest_version>を基にして作成されている必要があります。 最新バージョンはこちらで入手できます。 - 環境の定義には、
inference_configが含まれている必要があります。
以下は、カスタマイズされた環境の定義の例です。
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
Application Insights 診断 (プレビュー) をオンにすることでトレースを有効にする
これを有効にすると、推論時の (トークン数、フロー待機時間、フロー要求などの) トレース データとシステム メトリックが、ワークスペースにリンクされた Application Insights へと収集されます。 詳細については、「トレース データとメトリックを提供するプロンプト フロー」を参照してください。
ワークスペースにリンクされたものとは別の Application Insights を指定したい場合は、CLI で構成を行うことができます。
詳細設定 - 出力と接続
この手順では、すべてのフロー出力を表示し、デプロイするエンドポイントの応答に含める出力を指定できます。 既定では、すべてのフロー出力が選択されます。
また、推論を実行するときにエンドポイントで使用される接続を指定することもできます。 既定では、フローから継承されます。
上記のすべての手順を構成して確認したら、[確認および作成] を選んで作成を完了できます。
Note
エンドポイントの作成、モデルの登録、デプロイの作成など、いくつかのステージが含まれるため、エンドポイントの作成には約 15 分以上かかります。
通知によるデプロイ作成の進行状況は、プロンプト フローのデプロイから始まることを理解できます。

エンドポイントにアクセス許可を付与する
重要
アクセス許可の付与 (ロールの割り当ての追加) は、特定の Azure リソースの所有者のみ有効です。 IT 管理者に支援を求める必要がある場合があります。 デプロイの作成の前に、ユーザー割り当て ID にロールを付与することをお勧めします。 付与されたアクセス許可が有効になるまでに 15 分以上かかる場合があります。
以下の手順で、Azure portal UI ですべてのアクセス許可を付与できます。
Azure portal の Azure Machine Learning ワークスペースの概要ページに移動します。
[アクセス制御] を選び、[ロール割り当ての追加] を選びます。
![[アクセス制御] のスクリーンショット。[ロールの割り当ての追加] が強調表示されています。](media/how-to-deploy-for-real-time-inference/access-control.png?view=azureml-api-2)
[Azure Machine Learning Workspace Connection Secrets Reader]\(Azure Machine Learning ワークスペース接続シークレット閲覧者\) を選択し、[次へ] に進みます。
Note
Azure Machine Learning ワークスペース接続シークレット閲覧者は、ワークスペース接続を取得するためのアクセス許可がある組み込みロールです。
カスタマイズしたロールを使う場合は、カスタマイズしたロールに "Microsoft.MachineLearningServices/workspaces/connections/listsecrets/action" のアクセス許可があることを確認します。 詳細については、カスタム ロールの作成方法に関する記事を参照してください。
[マネージド ID] を選び、メンバーを選びます。
システム割り当て ID の場合は、[システム割り当てマネージド ID] の [Machine learning online endpoint] (機械学習オンライン エンドポイント) を選び、エンドポイント名で検索します。
ユーザー割り当て ID の場合は、[ユーザー割り当てマネージド ID] を選び、ID 名で検索します。
ユーザー割り当て ID の場合、ワークスペース コンテナー レジストリとストレージ アカウントにもアクセス許可を付与する必要があります。 コンテナー レジストリとストレージ アカウントは、Azure portal のワークスペースの概要ページで確認できます。
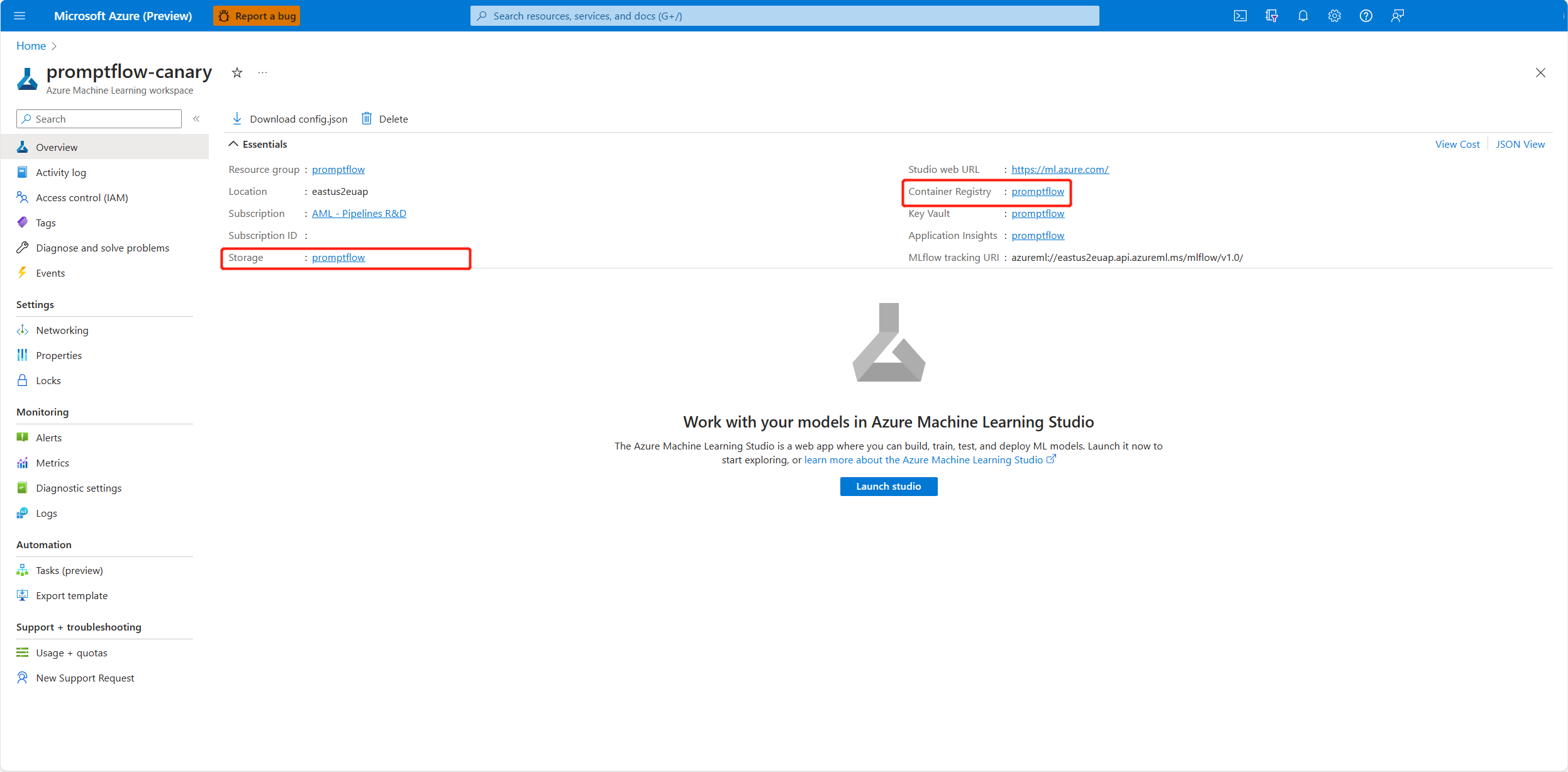
ワークスペース コンテナー レジストリの概要ページに移動し、[アクセス制御] を選び、[ロールの割り当ての追加] を選んで、[ACR pull |Pull container image]\(ACR プル | コンテナー イメージのプル\) をエンドポイント ID に割り当てます。
ワークスペースの既定のストレージの概要ページに移動し、[アクセス制御] を選び、[ロールの割り当ての追加] を選んで、[ストレージ BLOB データ閲覧者] をエンドポイント ID に割り当てます。
(省略可能) ユーザー割り当て ID の場合、CPU、GPU、ディスク、メモリ使用率などのエンドポイント関連のメトリックを監視する場合は、ワークスペースの [ワークスペース メトリック ライター] ロールも ID に付与する必要があります。
![[アクセス制御] のスクリーンショット。[ロールの割り当ての追加] が強調表示されています。](media/how-to-deploy-for-real-time-inference/access-control.png?view=azureml-api-2#lightbox)

エンドポイントの状態を確認する
デプロイ ウィザードが完了すると、通知を受け取ります。 エンドポイントとデプロイが正常に作成されたら、エンドポイントの詳細ページへの通知で [Deploy details] (デプロイの詳細) を選択できます。
また、スタジオの [エンドポイント] ページに直接移動し、デプロイしたエンドポイントの状態を確認することもできます。

サンプル データを使用してエンドポイントをテストする
エンドポイントの詳細ページで [テスト] タブに切り替えます。
値を入力し、[テスト] ボタンを選択できます。
[テスト結果] は次のようになります。
![[テスト] タブのエンドポイントの詳細ページのスクリーンショット。](media/how-to-deploy-for-real-time-inference/test-endpoint.png?view=azureml-api-2#lightbox)
チャット フローからデプロイされたエンドポイントをテストする
チャット フローからデプロイされたエンドポイントの場合は、イマーシブ チャット ウィンドウでテストできます。

chat_input はチャット フローの開発時に設定したものです。 入力ボックスに chat_input のメッセージを入力できます。 右側の [入力] パネルで chat_input 以外の他の入力値を指定することができます。 詳細については、チャット フローの開発方法に関する記事を参照してください。
エンドポイントを使う
エンドポイントの詳細ページで [Consume] (使用) タブに切り替えます。エンドポイントを使うための REST エンドポイントとキー/トークンを確認できます。 さまざまな言語でエンドポイントを使うためのサンプル コードもあります。
フロー入力に従ってデータ値を入力する必要があることに注意してください。 この記事では、例として Web 分類サンプル フローを使います。data = {"url": "<the_url_to_be_classified>"} を指定し、サンプル使用コードにキーまたはトークンを入力する必要があります。

エンドポイントを監視する
Azure Monitor を使用してマネージド オンライン エンドポイントの一般的なメトリックを表示する (省略可能)
スタジオのエンドポイントの [詳細] ページのリンクをたどると、オンライン エンドポイントとそのデプロイのさまざまなメトリック (要求番号、要求の待機時間、ネットワーク バイト、CPU/GPU/ディスク/メモリの使用状況など) を表示できます。 これらのリンクに従うと、エンドポイントまたはデプロイの Azure portal の正確なメトリック ページに移動します。
注意
エンドポイントにユーザー割り当て ID を指定する場合は、必ず Azure Machine Learning ワークスペースの [Workspace metrics writer] (ワークスペース メトリック ライター) をユーザー割り当て ID に割り当ててください。 そうしないと、エンドポイントはメトリックをログできません。

オンライン エンドポイント メトリックを表示する方法の詳細については、「オンライン エンドポイントを監視する」を参照してください。
プロンプト フロー エンドポイント固有のメトリックとトレース データを表示する (省略可能)
UI デプロイ ウィザードで Application Insights 診断を有効にすると、トレース データとプロンプト フロー固有のメトリックが、ワークスペースにリンクされた Application Insights へと収集されます。 デプロイに対するトレースの有効化の詳細を確認してください。
プロンプト フローからデプロイされたエンドポイントをトラブルシューティングする
アクション "Microsoft.MachineLearningService/workspaces/datastores/read" を実行する権限がない
フローにインデックス検索ツールが含まれている場合、フローをデプロイした後に、エンドポイントではワークスペース データストアにアクセスして、チャンクと埋め込みを含む MLIndex yaml ファイルまたは FAISS フォルダーを読み取る必要があります。 そのため、それを行うためのアクセス許可を エンドポイント ID に付与する必要があります。
ワークスペース スコープに対する AzureML データ サイエンティストか、"MachineLearningService/workspace/datastore/reader" アクションを含むカスタム ロールをエンドポイント ID に付与できます。
MissingDriverProgram エラー
カスタム環境を使ってフローをデプロイすると、次のエラーが発生する場合は、カスタム環境の定義で inference_config を指定しなかったためである可能性があります。
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
このエラーを修正するには、2 つの方法があります。
(推奨) カスタム環境の詳細ページでコンテナー イメージの URI を調べて、flow.dag.yaml ファイルでフローの基本イメージとしてそれを設定できます。 UI でフローをデプロイするときは、[現在のフロー定義の環境を使用する] を選ぶだけで、この基本イメージとデプロイに対する
requirement.txtに基づいてカスタマイズされた環境が、バックエンド サービスによって作成されます。 フロー定義で指定された環境についての詳細を理解してください。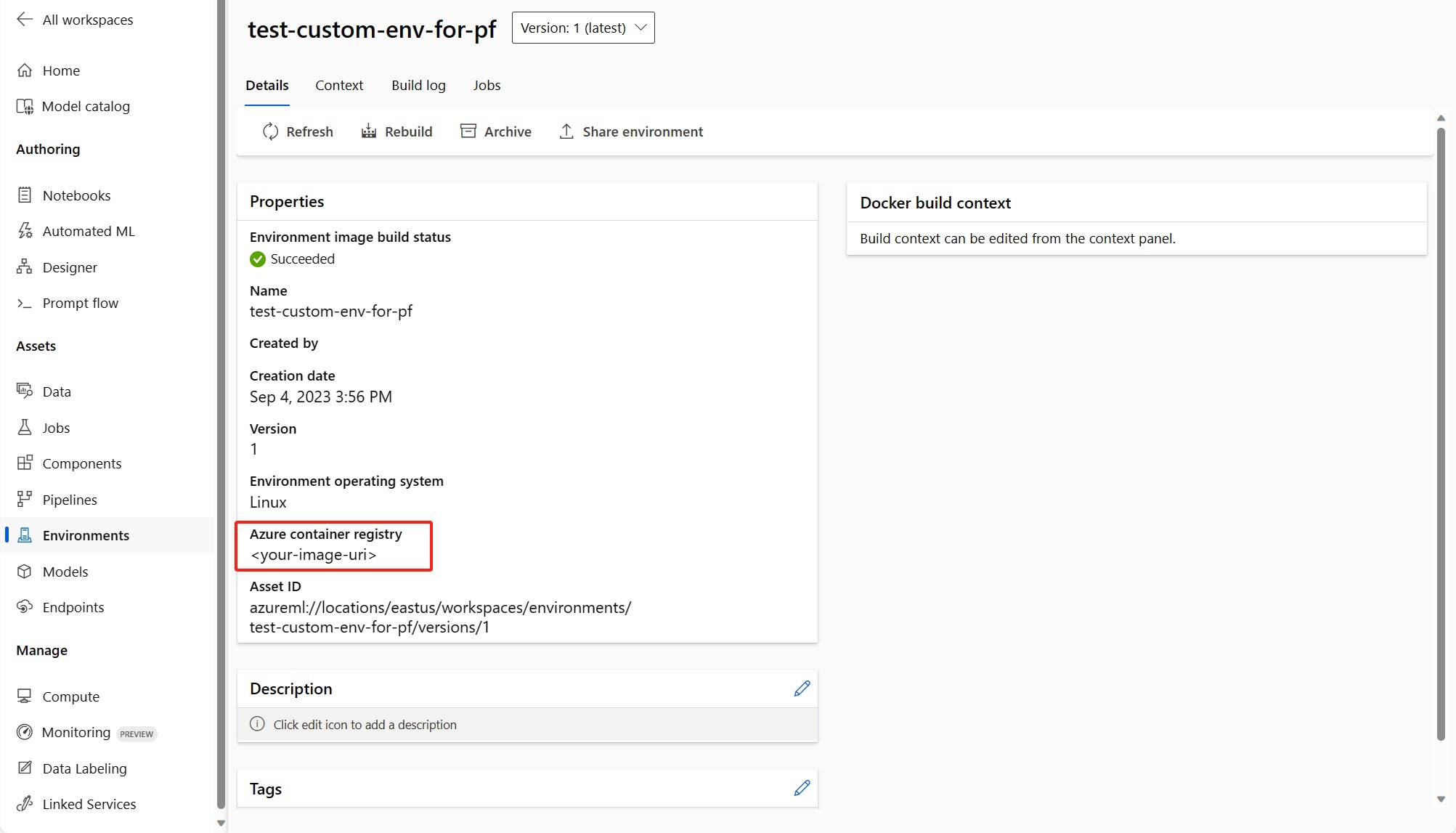
カスタム環境の定義に
inference_configを追加すると、このエラーを修正できます。 カスタマイズされた環境を使う方法の詳細を理解してください。以下は、カスタマイズされた環境の定義の例です。

$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
モデルの応答に時間がかかりすぎる
デプロイの応答に時間がかかりすぎていることに気づく場合があります。 これには、いくつかの発生要因が考えられます。
- モデルが十分に強力ではない (例: text-ada に対して gpt が使用されている)
- インデックス クエリが最適化されておらず、時間がかかりすぎる
- フローに含まれている処理手順が多すぎる
モデルのパフォーマンスを向上するために、上記の考慮事項を使ってエンドポイントを最適化することを検討してください。
デプロイ スキーマをフェッチできません
エンドポイントをデプロイし、エンドポイント詳細ページの [テスト] タブでテストする際、[テスト] タブに次のように [デプロイ スキーマをフェッチできません] と表示される場合は、次の 2 つの方法を試してこの問題を収束できます。
![エンドポイント詳細ページ [テスト] タブに、[デプロイ スキーマをフェッチできません] エラーが表示されているスクリーンショット。](media/how-to-deploy-for-real-time-inference/unable-to-fetch-deployment-schema.png?view=azureml-api-2#lightbox)
- エンドポイント ID に対して正しいアクセス許可が付与されていることを確認します。 詳しくは、「エンドポイント ID にアクセス許可を付与する方法」をご覧ください。
ワークスペース シークレット一覧へのアクセスが拒否されました
"Access denied to list workspace secret" (ワークスペース シークレット一覧へのアクセスが拒否されました) などのエラーが発生した場合は、エンドポイント ID に対して正しいアクセス許可が付与されているかをチェックします。 詳しくは、「エンドポイント ID にアクセス許可を付与する方法」をご覧ください。
リソースをクリーンアップする
このチュートリアルの完了後にエンドポイントを使う予定がない場合は、エンドポイントを削除してください。
Note
完全に削除されるまで約 20 分かかります。