機械学習パイプライン内で (Azure Synapse Analytics で実行される) Apache Spark を使用する方法 (非推奨)
適用対象:  Python SDK azureml v1
Python SDK azureml v1
警告
Python SDK v1 で利用できる Azure Machine Learning との Azure Synapse Analytics の統合は非推奨になっています。 ユーザーは、Azure Machine Learning に登録された Synapse ワークスペースをリンク サービスとして引き続き使用できます。 ただし、新しい Synapse ワークスペースは、リンクされたサービスとして Azure Machine Learning に登録できなくなります。 CLI v2 と Python SDK v2 で利用できるサーバーレス Spark コンピューティングと、アタッチされた Synapse Spark プールの使用をお勧めします。 詳細については、https://aka.ms/aml-spark を参照してください。
この記事では、Azure Synapse Analytics を利用する Apache Spark プールを、Azure Machine Learning パイプラインのデータ準備ステップのコンピューティング先として使う方法を説明します。 データの準備やトレーニングなどの特定のステップに適したコンピューティング リソースを 1 つのパイプラインで使用する方法について説明します。 データを Spark ステップ用に準備する方法と、次のステップに渡す方法についても説明します。
前提条件
すべてのパイプライン リソースを保持するために、Azure Machine Learning ワークスペースを作成します
開発環境を構成して Azure Machine Learning SDK をインストールするか、SDK が既にインストールされている Azure Machine Learning コンピューティング インスタンスを使用します
Azure Synapse Analytics ワークスペースと Apache Spark プールを作成します。 詳しくは、「クイック スタート: Synapse Studio を使用してサーバーレス Apache Spark プールを作成する」をご覧ください。
Azure Machine Learning ワークスペースと Azure Synapse Analytics ワークスペースをリンクする
Apache Spark プールは、Azure Synapse Analytics ワークスペースで作成して管理します。 Apache Spark プールを Azure Machine Learning ワークスペースと統合するには、Azure Synapse Analytics ワークスペースにリンクする必要があります。 Azure Machine Learning ワークスペースと Azure Synapse Analytics ワークスペースをリンクしたら、次のものを使って Apache Spark プールをアタッチできます
Python SDK (後で説明します)
Azure Resource Manager (ARM) テンプレート。 詳しくは、ARM テンプレートの例をご覧ください
- コマンド ラインを使って ARM テンプレートに従い、リンク サービスを追加し、次のコード サンプルを使って Apache Spark プールをアタッチできます。
az deployment group create --name --resource-group <rg_name> --template-file "azuredeploy.json" --parameters @"azuredeploy.parameters.json"
重要
Synapse ワークスペースに正常にリンクするには、ユーザーが Synapse ワークスペースの所有者ロールを付与されている必要があります。 Azure portal でご自身のアクセス権を確認してください。
リンク サービスは、作成時にシステム割り当てマネージド ID (SAI) を取得します。 このリンク サービスの SAI に Synapse Studio から "Synapse Apache Spark 管理者" ロールを割り当てて、それが Spark ジョブを送信できるようにする必要があります (「Synapse Studio で Synapse RBAC ロールの割り当てを管理する方法」をご覧ください)。
また、Azure Machine Learning ワークスペースのユーザーに、Azure portal のリソース管理から "共同作成者" ロールを付与する必要があります。
Azure Synapse Analytics ワークスペースと Azure Machine Learning ワークスペースの間のリンクを取得する
このコードは、ワークスペース内のリンク サービスを取得する方法を示したものです。
from azureml.core import Workspace, LinkedService, SynapseWorkspaceLinkedServiceConfiguration
ws = Workspace.from_config()
for service in LinkedService.list(ws) :
print(f"Service: {service}")
# Retrieve a known linked service
linked_service = LinkedService.get(ws, 'synapselink1')
最初に、Workspace.from_config() は config.json ファイル内の構成を使って Azure Machine Learning ワークスペースにアクセスします。 (詳しくは、ワークスペース構成ファイルの作成に関する記事をご覧ください)。 次に、このコードにより、ワークスペースで利用できるすべてのリンク サービスが出力されます。 最後に、LinkedService.get() によって、'synapselink1' という名前のリンクされたサービスが取得されます。
Azure Machine Learning のコンピューティング先として Apache Spark プールをアタッチする
機械学習パイプラインのステップで Apache Spark プールを利用するには、次のコード サンプルで示すように、それをパイプライン ステップの ComputeTarget としてアタッチする必要があります。
from azureml.core.compute import SynapseCompute, ComputeTarget
attach_config = SynapseCompute.attach_configuration(
linked_service = linked_service,
type="SynapseSpark",
pool_name="spark01") # This name comes from your Synapse workspace
synapse_compute=ComputeTarget.attach(
workspace=ws,
name='link1-spark01',
attach_configuration=attach_config)
synapse_compute.wait_for_completion()
コードは、最初に SynapseCompute を構成します。 linked_service 引数は、前の手順で作成または取得した LinkedService オブジェクトです。 type 引数は SynapseSpark である必要があります。 SynapseCompute.attach_configuration() の pool_name 引数は、Azure Synapse Analytics ワークスペースの既存のプールのそれと一致している必要があります。 Azure Synapse Analytics ワークスペースでの Apache Spark プールの作成について詳しくは、「クイック スタート: Synapse Studio を使用してサーバーレス Apache Spark プールを作成する」をご覧ください。 attach_config の型は ComputeTargetAttachConfiguration。
構成を作成した後、Workspace と ComputeTargetAttachConfiguration の値、および Machine Learning ワークスペース内でコンピューティングの参照に使う名前を渡して、機械学習の ComputeTarget を作成します。 ComputeTarget.attach() の呼び出しは非同期であるため、このサンプルは、呼び出しが完了するまでブロックされます。
リンクされた Apache Spark プールを使用する SynapseSparkStep を作成する
サンプル ノートブックの Apache spark プールの Spark ジョブでは、単純な機械学習パイプラインが定義されています。 このノートブックでは、最初に、前のステップで定義した synapse_compute を利用したデータ準備手順が定義されています。 次に、ノートブックでは、トレーニングにいっそう適したコンピューティング先を利用するトレーニング ステップが定義されます。 サンプル ノートブックでは、タイタニック号の生存者のデータベースを使って、データの入力と出力を示します。 実際にデータをクリーンアップしたり、予測モデルを作成したりすることはありません。 このサンプルではトレーニングが実際に行われることはないため、トレーニング ステップでは安価な CPU ベースのコンピューティング リソースを使います。
データは、DatasetConsumptionConfig オブジェクトを通して機械学習パイプラインに送られます。このオブジェクトは表形式のデータまたはファイルのセットを保持できます。 データは、多くの場合、ワークスペースのデータストア内にある BLOB ストレージのファイルから取得されます。 このコード サンプルでは、機械学習パイプラインに対する入力を作成する一般的なコードを示します。
from azureml.core import Dataset
datastore = ws.get_default_datastore()
file_name = 'Titanic.csv'
titanic_tabular_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, file_name)])
step1_input1 = titanic_tabular_dataset.as_named_input("tabular_input")
# Example only: it wouldn't make sense to duplicate input data, especially one as tabular and the other as files
titanic_file_dataset = Dataset.File.from_files(path=[(datastore, file_name)])
step1_input2 = titanic_file_dataset.as_named_input("file_input").as_hdfs()
このコード サンプルでは、Titanic.csv ファイルが BLOB ストレージにあることが想定されています。 このコードでは、TabularDataset と FileDataset の両方としてファイルを読み取る方法を示します。 このコードはデモだけを目的としたものです。これは、入力を複製したり、単一のデータ ソースを、テーブルを含むリソースと、厳密なファイルの両方として解釈したりすると、ややこしくなるためです。
重要
FileDataset を入力として使うには、azureml-core のバージョン 1.20.0 以降が必要です。 これは、後で説明するように、Environment クラスで指定できます。 ステップが完了したら、次のコード サンプルで示すように、出力データを格納できます。
from azureml.data import HDFSOutputDatasetConfig
step1_output = HDFSOutputDatasetConfig(destination=(datastore,"test")).register_on_complete(name="registered_dataset")
このコード サンプルの datastore は、データを test という名前のファイルに格納します。 データは、Machine Learning ワークスペース内で registered_dataset という名前の Dataset として使用できます。
パイプラインのステップには、データに加えて、ステップごとの Python の依存関係がある場合があります。 さらに、個々の SynapseSparkStep オブジェクトでは、正確な Azure Synapse Apache Spark 構成を指定できます。 これを示すため、次のコード サンプルでは、azureml-core パッケージのバージョンが 1.20.0 以上である必要があることを指定しています。 前に説明したように、FileDataset を入力として使うには、azureml-core パッケージについてのこの要件が必要です。
from azureml.core.environment import Environment
from azureml.pipeline.steps import SynapseSparkStep
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core>=1.20.0")
step_1 = SynapseSparkStep(name = 'synapse-spark',
file = 'dataprep.py',
source_directory="./code",
inputs=[step1_input1, step1_input2],
outputs=[step1_output],
arguments = ["--tabular_input", step1_input1,
"--file_input", step1_input2,
"--output_dir", step1_output],
compute_target = 'link1-spark01',
driver_memory = "7g",
driver_cores = 4,
executor_memory = "7g",
executor_cores = 2,
num_executors = 1,
environment = env)
このコードでは、Azure Machine Learning パイプラインの 1 つのステップが指定されています。 このコードの environment の値では特定の azureml-core バージョンが設定され、必要に応じて他の conda または pip の依存関係をコードで追加できます。
SynapseSparkStep は、ローカル コンピューターの ./code サブディレクトリを ZIP に圧縮してアップロードします。 コンピューティング サーバー上にそのディレクトリが再作成され、ステップによってそのディレクトリから dataprep.py スクリプトが実行されます。 そのステップの inputs と outputs は、前に説明した step1_input1、step1_input2、step1_output オブジェクトです。 dataprep.py スクリプト内でこれらの値にアクセスする最も簡単な方法は、これらを arguments という名前に関連付けることです。
SynapseSparkStep コンストラクターに対する次の引数セットは、Apache Spark を制御します。 compute_target は、以前にコンピューティング先としてアタッチされた 'link1-spark01' です。 その他のパラメーターでは、使用するメモリとコアが指定されます。
サンプル ノートブックでは、dataprep.py に対して次のコードを使います。
import os
import sys
import azureml.core
from pyspark.sql import SparkSession
from azureml.core import Run, Dataset
print(azureml.core.VERSION)
print(os.environ)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--tabular_input")
parser.add_argument("--file_input")
parser.add_argument("--output_dir")
args = parser.parse_args()
# use dataset sdk to read tabular dataset
run_context = Run.get_context()
dataset = Dataset.get_by_id(run_context.experiment.workspace,id=args.tabular_input)
sdf = dataset.to_spark_dataframe()
sdf.show()
# use hdfs path to read file dataset
spark= SparkSession.builder.getOrCreate()
sdf = spark.read.option("header", "true").csv(args.file_input)
sdf.show()
sdf.coalesce(1).write\
.option("header", "true")\
.mode("append")\
.csv(args.output_dir)
この "データ準備" スクリプトでは実際のデータ変換は行われませんが、データの取得、Spark データフレームへの変換、基本的な Apache Spark 操作の方法がわかります。 Azure Machine Learning スタジオで出力を確認するには、次のスクリーンショットで示すように、子ジョブを開き、[出力とログ] タブを選んで、logs/azureml/driver/stdout ファイルを開きます。
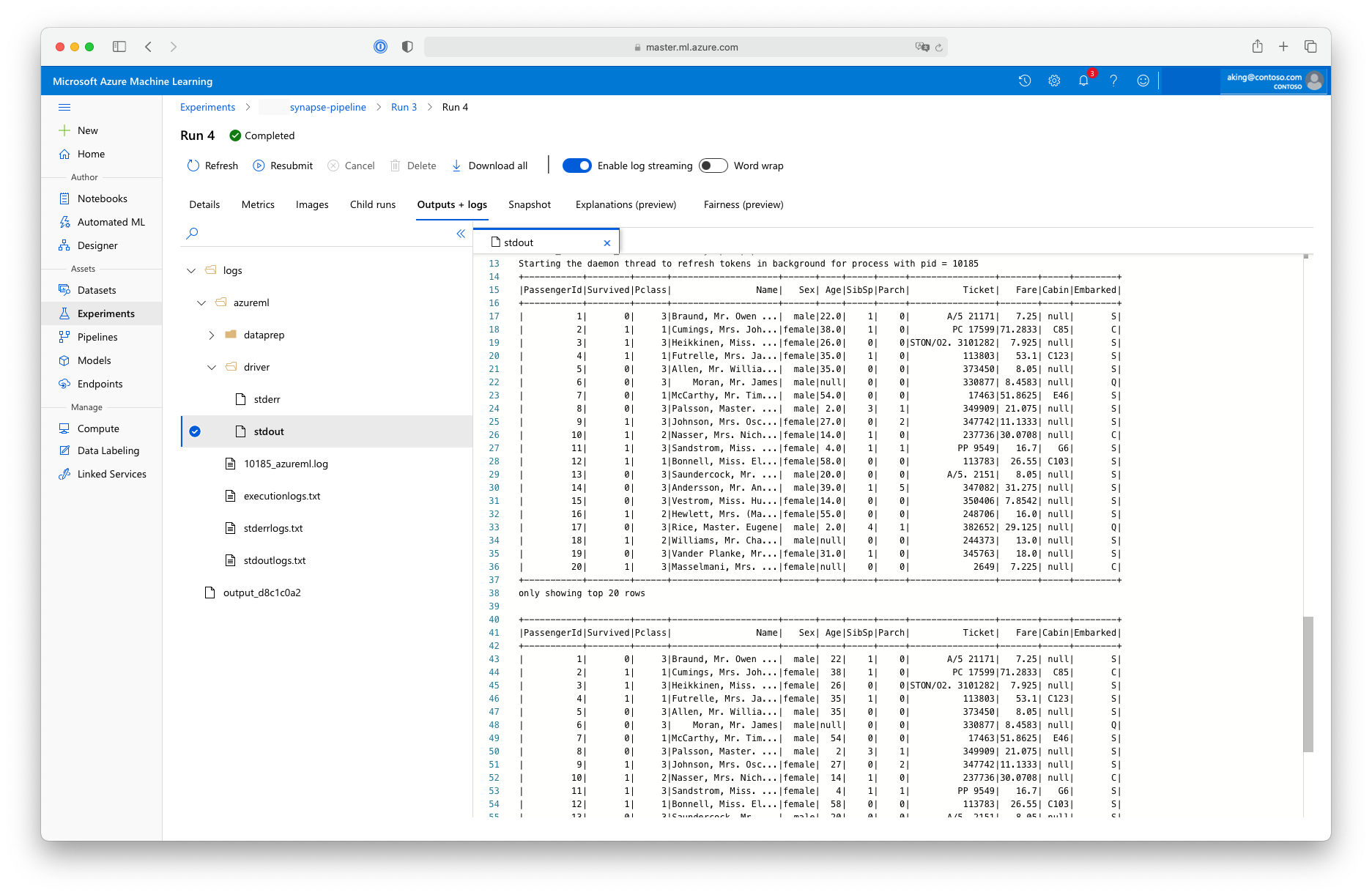
パイプラインで SynapseSparkStep を使用する
次の例では、前のセクションで作成された SynapseSparkStep の出力を使っています。 パイプライン内の他のステップには、それら独自の環境があり、これらは手持ちのタスクに適したさまざまなコンピューティング リソース上で実行される場合があります。 サンプル ノートブックでは、小規模な CPU クラスターで "トレーニング ステップ" が実行されます。
from azureml.core.compute import AmlCompute
cpu_cluster_name = "cpucluster"
if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
else:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=1)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
print('Allocating new CPU compute cluster')
cpu_cluster.wait_for_completion(show_output=True)
step2_input = step1_output.as_input("step2_input").as_download()
step_2 = PythonScriptStep(script_name="train.py",
arguments=[step2_input],
inputs=[step2_input],
compute_target=cpu_cluster_name,
source_directory="./code",
allow_reuse=False)
このコードでは、必要に応じて新しいコンピューティング リソースが作成されます。 その後、step1_output の結果がトレーニング ステップの入力に変換されます。 as_download() オプションは、データがコンピューティング リソースに移動されるため、アクセスが高速になることを意味します。 データが大きすぎてローカル コンピューティングのハード ドライブに収まらない場合は、as_mount() オプションを使って、FUSE ファイル システムでデータをストリーミングする必要があります。 この 2 番目のステップの compute_target は 'cpucluster' で、データ準備ステップで使用した 'link1-spark01' リソースではありません。 このステップでは、前のステップで使った dataprep.py スクリプトの代わりに、簡単な train.py スクリプトを使います。 サンプル ノートブックには、詳細な train.py スクリプトが含まれています。
すべてのステップを定義した後は、パイプラインを作成して実行できます。
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=ws, steps=[step_1, step_2])
pipeline_run = pipeline.submit('synapse-pipeline', regenerate_outputs=True)
このコードでは、Azure Synapse Analytics (step_1) を利用する Apache Spark プール上のデータ準備ステップと、トレーニング ステップ (step_2) で構成されるパイプラインが作成されます。 Azure は、ステップ間のデータの依存関係を調べて、実行グラフを計算します。 この場合は、単純な依存関係が 1 つだけあります。 ここでは、step2_input には step1_output が必ず必要です。
pipeline.submit の呼び出しにより、必要に応じて synapse-pipeline という名前の実験が作成され、その中でジョブが非同期的に開始されます。 パイプライン内の個々のステップは、このメイン ジョブの子ジョブとして実行され、スタジオの [実験] ページでそれらのステップを監視および確認できます。