機械学習パイプラインをトリガーする
適用対象:  Python SDK azureml v1
Python SDK azureml v1
この記事では、Azure で実行するパイプラインをプログラムでスケジュールする方法について説明します。 経過時間またはファイルシステムの変更に基づいてスケジュールを作成することができます。 時間ベースのスケジュールを使用すると、データの誤差の監視などの日常的なタスクを行うことができます。 変更ベースのスケジュールを使用すると、新しいデータがアップロードされたり古いデータが編集されたりといった、不規則な変更や予期しない変更に対処できます。 スケジュールを作成する方法を説明した後、それらを取得して非アクティブ化する方法を説明します。 最後に、他の Azure サービス (Azure ロジック アプリおよび Azure Data Factory) を使用してパイプラインを実行する方法について説明します。 Azure ロジック アプリを使用すると、より複雑なトリガー ロジックまたは動作が可能になります。 Azure Data Factory パイプラインを使用すると、機械学習パイプラインを、より大きなデータ オーケストレーション パイプラインの一部として呼び出すことができます。
前提条件
Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、無料アカウントを作成してください。
Azure Machine Learning SDK for Python がインストールされた Python 開発環境。 詳細については、「Azure Machine Learning を使用してトレーニングとデプロイのための再利用可能な環境を作成および管理します」を参照してください。
公開されたパイプラインがある Machine Learning のワークスペース。 「Azure Machine Learning SDK で機械学習パイプラインを作成して管理する」で組み込まれたものを使用できます。
Azure Machine Learning SDK for Python を使用してパイプラインをトリガーする
パイプラインをスケジュールするには、ワークスペースへの参照、公開されたパイプラインの識別子、およびスケジュールを作成する実験の名前が必要です。 これらの値は次のコードを使用して取得できます。
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
スケジュールを作成する
パイプラインを定期的に実行するには、スケジュールを作成します。 Schedule によって、パイプライン、実験、およびトリガーが関連付けられます。 トリガーには、ジョブの待機時間を示す ScheduleRecurrence、または変更を監視するディレクトリを指定するデータストア パスを指定できます。 どちらの場合も、パイプライン識別子と、スケジュールを作成する実験の名前が必要になります。
Python ファイルの先頭に、Schedule クラスと ScheduleRecurrence クラスをインポートします。
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
時刻ベースのスケジュールを作成する
ScheduleRecurrence コンストラクターには、次のいずれかの文字列である必要な frequency 引数があります。"Minute"、"Hour"、"Day"、"Week"、または "Month"。 また、スケジュールの開始から次の開始までの経過時間の frequency 単位を指定する整数の interval 引数も必要です。 省略可能な引数を使用すると、ScheduleRecurrence SDK に関するドキュメントで詳しく説明されているように、開始時間をより具体的に指定できます。
15 分ごとにジョブを開始する Schedule を作成します。
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
変更ベースのスケジュールを作成する
ファイルの変更によってトリガーされるパイプラインは、時間ベースのスケジュールよりも効率的な場合があります。 ファイルが変更される前に何かを行いたい場合、または新しいファイルがデータ ディレクトリに追加される場合は、そのファイルを前処理することができます。 データストアまたはデータストア内の特定のディレクトリ内の変更に対する変更を監視できます。 特定のディレクトリを監視する場合、そのディレクトリのサブディレクトリ内の変更は、ジョブをトリガーしません。
Note
変更ベースのスケジュールでは、Azure Blob Storage の監視のみがサポートされます。
ファイルに対応する Schedule を作成するには、Schedule.create の呼び出しに datastore パラメーターを設定する必要があります。 フォルダーを監視するには、path_on_datastore 引数を設定します。
polling_interval 引数を使用すると、データストアが変更されたかどうかを確認する頻度を分単位で指定できます。
パイプラインが DataPath PipelineParameter を使用して構築されている場合は、data_path_parameter_name 引数を設定することによって、その変数を変更されたファイルの名前に設定できます。
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
スケジュールを作成するときの省略可能な引数
前に説明した引数に加えて、status 引数を "Disabled" に設定して、非アクティブなスケジュールを作成することもできます。 最後に、continue_on_step_failure を使用すると、パイプラインの既定のエラー動作をオーバーライドするブール値を渡すことができます。
スケジュールされたパイプラインを表示する
Web ブラウザーで Azure Machine Learning に移動します。 ナビゲーション パネルの [エンドポイント] セクションで、 [Pipeline endpoints]/(パイプラインのエンドポイント/) を選択します。 これにより、ワークスペースで発行されたパイプラインの一覧が表示されます。
![AML の [パイプライン] ページ](media/how-to-trigger-published-pipeline/scheduled-pipelines.png?view=azureml-api-1)
このページでは、ワークスペース内のすべてのパイプラインに関する概要情報 (名前、説明、状態など) を確認できます。 パイプラインをクリックすると、詳細を詳しく見ることができます。 結果のページには、パイプラインの詳細が表示され、個々のジョブについて確認することもできます。
パイプラインを非アクティブ化する
発行されているがスケジュールされていない Pipeline がある場合は、次の方法で無効にできます。
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
パイプラインがスケジュールされている場合は、まずスケジュールを取り消す必要があります。 ポータルから、または次のように実行して、スケジュールの識別子を取得します。
ss = Schedule.list(ws)
for s in ss:
print(s)
無効にする schedule_id がある場合は、次のように実行します。
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
その後 Schedule.list(ws) を再度実行すると、空の一覧が表示されます。
複雑なトリガーに Azure Logic Apps を使用する
Azure Logic App を使用して、より複雑なトリガーのルールまたは動作を作成することができます。
Azure Logic App を使用して Machine Learning パイプラインをトリガーするには、発行された Machine Learning パイプラインの REST エンドポイントが必要です。 パイプラインを作成して発行します。 次に、パイプライン ID を使用して、PublishedPipeline の REST エンドポイントを見つけます。
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Azure でロジック アプリを作成する
ここで Azure ロジック アプリ インスタンスを作成します。 ロジック アプリがプロビジョニングされたら、次の手順に従ってパイプラインのトリガーを構成します。
システム割り当てマネージド ID を作成し、アプリに Azure Machine Learning ワークスペースへのアクセス権を付与します。
ロジック アプリ デザイナー ビューに移動し、[空の Logic Apps] テンプレートを選択します。
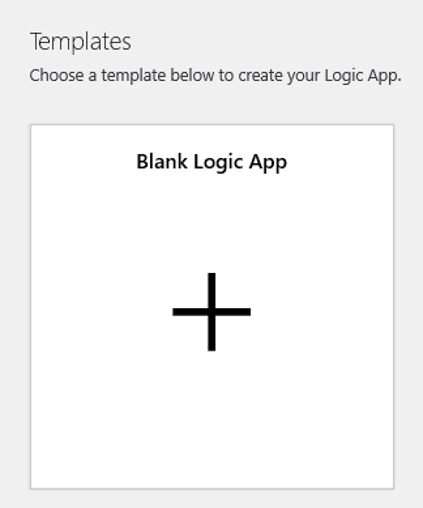
デザイナーで BLOB を検索します。 [BLOB が追加または変更されたとき (プロパティのみ)] トリガーを選択して、このトリガーをロジック アプリに追加します。
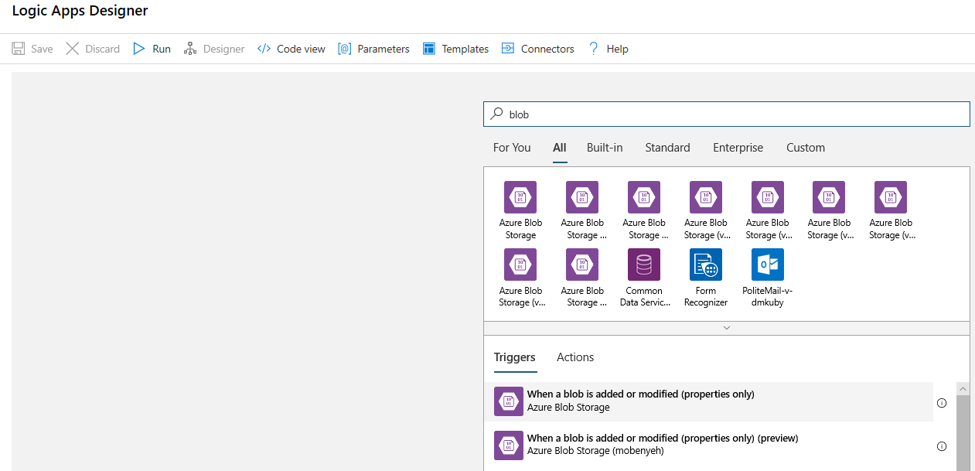
BLOB の追加または変更を監視するための BLOB ストレージ アカウントの接続情報を入力します。 監視するコンテナーを選択します。
自動で機能する、更新をポーリングする間隔と頻度を選択します。
Note
このトリガーによって、選択したコンテナーは監視されますが、サブフォルダーは監視されません。
新しい BLOB または変更された BLOB が検出されたときに実行される HTTP アクションを追加します。 [+ 新しいステップ] を選択してから、HTTP アクションを検索して選択します。
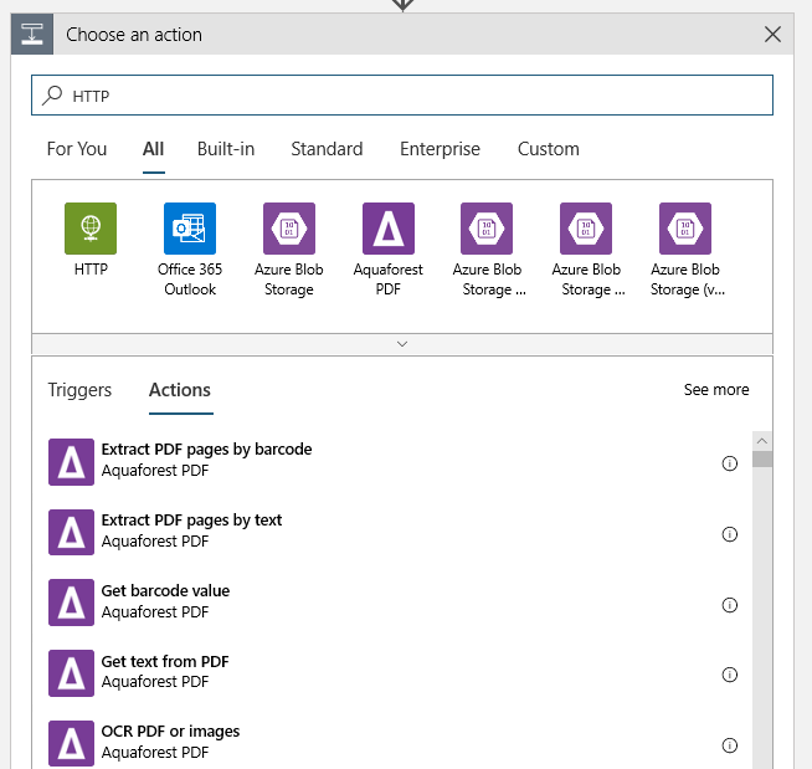
以下の設定を使用してアクションを構成します。
| 設定 | 値 |
|---|---|
| HTTP アクション | POST |
| URI | 前提条件として確認した、発行されたパイプラインへのエンドポイント |
| 認証モード | マネージド ID |
使用する可能性のあるすべての DataPath PipelineParameters の値を設定するためのスケジュールを設定します。
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }ワークスペースに追加した
DataStoreNameを前提条件として使用します。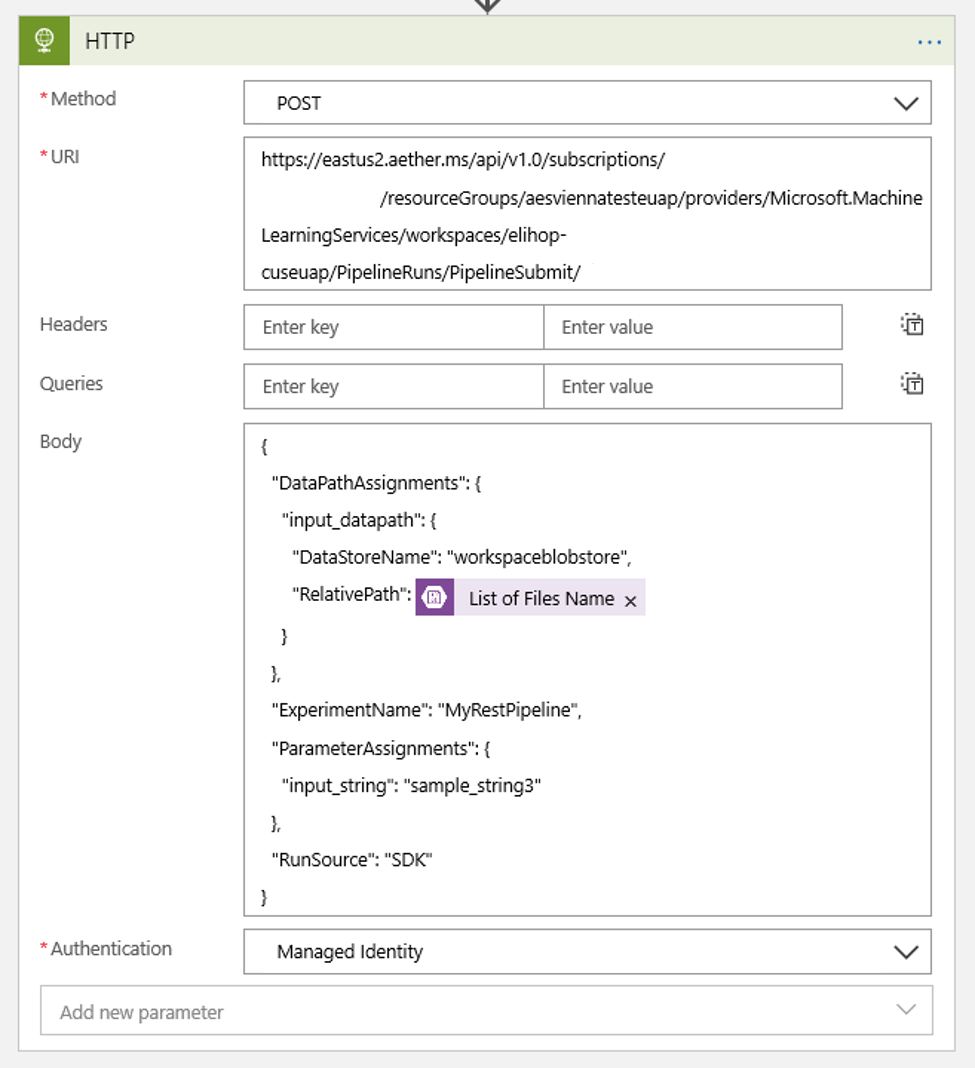
[保存] を選択するとスケジュールの準備ができます。
重要
Azure ロールベースのアクセス制御 (Azure RBAC) を使用してパイプラインへのアクセスを管理している場合は、パイプライン シナリオ (トレーニングまたはスコアリング) のアクセス許可を設定します。
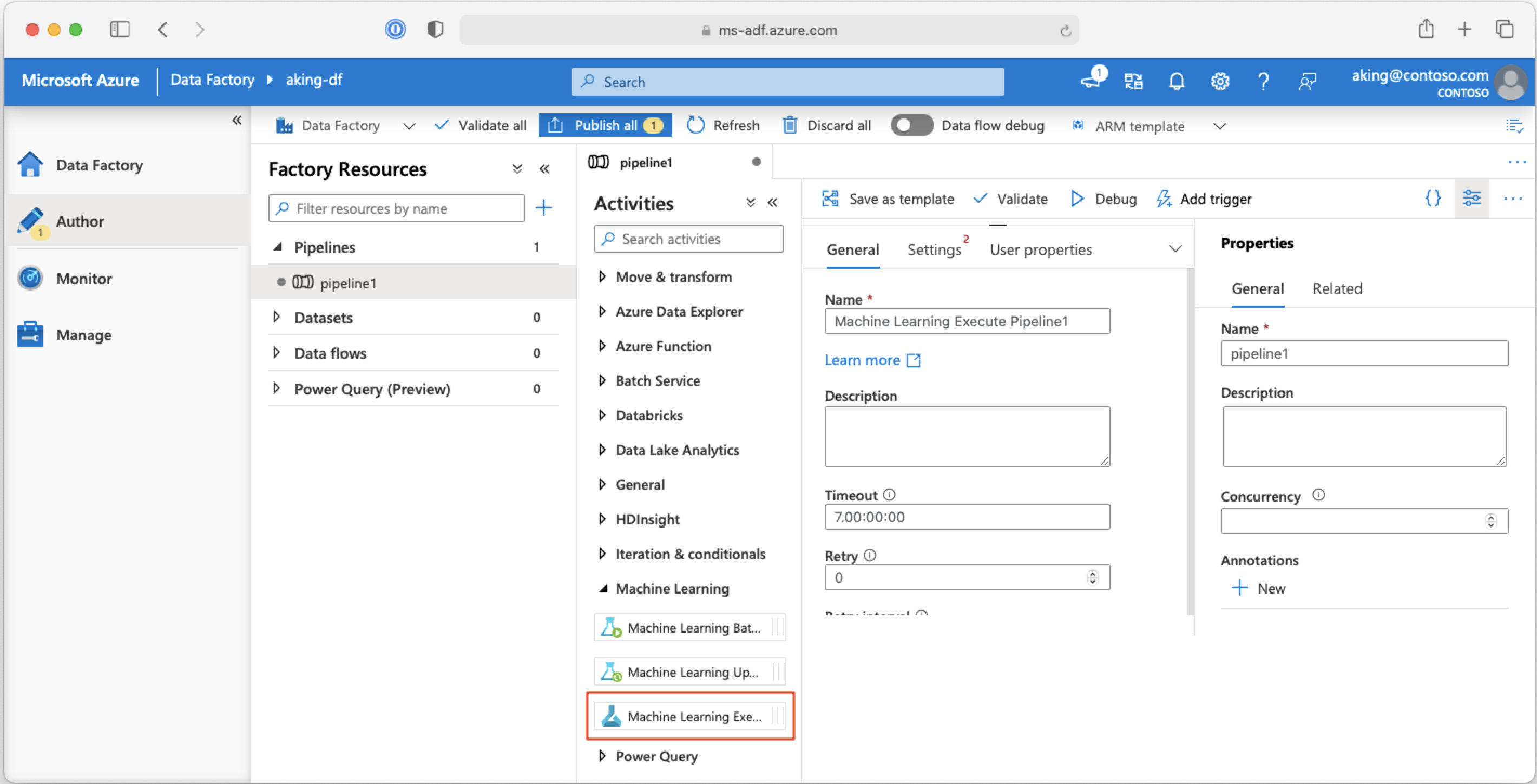
Azure Data Factory パイプラインから機械学習パイプラインを呼び出す
Azure Data Factory パイプラインでは、Machine Learning Execute Pipeline アクティビティによって Azure Machine Learning パイプラインが実行されます。 このアクティビティは、Data Factory の作成ページの [Machine Learning] カテゴリで確認できます。
次のステップ
この記事では、Python 用の Azure Machine Learning SDK を使用して、2 つの異なる方法でパイプラインをスケジュールしています。 一方のスケジュールは、経過時間に基づいて繰り返されます。 もう一方のスケジュールは、指定された Datastore で、またはそのストアのディレクトリ内でファイルが変更された場合に実行されます。 ポータルを使用して、パイプラインと個々のジョブを確認する方法について説明しました。 パイプラインによって実行が停止されるように、スケジュールを無効にする方法を学習しました。 最後に、パイプラインをトリガーするための Azure Logic App を作成しました。
詳細については、次を参照してください。
- パイプラインに関する詳細情報
- Jupyter を使用した Azure Machine Learning の探索に関する詳細情報