Azure Machine Learning で Spark ジョブを送信する
適用対象: Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure Machine Learning は、スタンドアロンの機械学習ジョブの送信、複数の機械学習ワークフロー手順を伴う機械学習パイプラインの作成をサポートしています。 Azure Machine Learning は、スタンドアロンの Spark ジョブの作成と、Azure Machine Learning パイプラインが使用できる再利用可能な Spark コンポーネントの作成の両方を処理します。 この記事では、以下を使って Spark ジョブを送信する方法について説明します。
- Azure Machine Learning スタジオ UI
- Azure Machine Learning CLI
- Azure Machine Learning SDK
Azure Machine Learning での Apache Spark の概念の詳細については、こちらのリソースを参照してください。
前提条件
適用対象: Azure CLI ml 拡張機能 v2 (現行)
- Azure サブスクリプション。Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
- Azure Machine Learning ワークスペース。 詳細については、ワークスペース リソースの作成に関する記事を参照してください。
- Azure Machine Learning コンピューティング インスタンスを作成してください。
- Azure Machine Learning CLI をインストールしてください。
- (省略可能): Azure Machine Learning ワークスペースにアタッチされた Synapse Spark プール。
Note
- Azure Machine Learning サーバーレス Spark コンピューティングおよびアタッチされている Synapse Spark プールを使用する際のリソース アクセスの詳細については、「Spark ジョブのリソース アクセスを確認する」を参照してください。
- Azure Machine Learning には、共有クォータ プールが用意されています。すべてのユーザーは、ここからコンピューティング クォータにアクセスして、限られた時間テストを実行できます。 サーバーレス Spark コンピューティングを使用する場合、Azure Machine Learning では、この共有クォータに短時間アクセスできます。
CLI v2 を使ってユーザー割り当てマネージド ID をアタッチする
- ワークスペースにアタッチする必要があるユーザー割り当てマネージド ID が定義されている YAML ファイルを作成します。
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} az ml workspace updateコマンドで--fileパラメーターを指定して YAML ファイルを使い、ユーザー割り当てマネージド ID をアタッチします。az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
ARMClient を使ってユーザー割り当てマネージド ID をアタッチする
ARMClientをインストールします。これは、Azure Resource Manager API を呼び出すシンプルなコマンド ライン ツールです。- ワークスペースにアタッチする必要があるユーザー割り当てマネージド ID が定義されている JSON ファイルを作成します。
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - ユーザー割り当てマネージド ID をワークスペースにアタッチするには、PowerShell プロンプトまたはコマンド プロンプトで次のコマンドを実行します。
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Note
- Spark ジョブが正常に実行されるようにするには、データの入力と出力に使われる Azure ストレージ アカウントでの共同作成者と Storage Blob データ共同作成者のロールを、Spark ジョブに使われる ID に割り当てる必要があります。
- アタッチされた Synapse Spark プールを使用して Spark ジョブが正常に実行されるようにするには、Azure Synapse ワークスペースでパブリック ネットワーク アクセスを有効にする必要があります。
- マネージド仮想ネットワークが関連付けられている Azure Synapse ワークスペースでは、アタッチされた Synapse Spark プールが Synapse Spark プールを指している場合、データ アクセスを確保するために、ストレージ アカウントへのマネージド プライベート エンドポイントを構成する必要があります。
- サーバーレス Spark コンピューティングでは、Azure Machine Learning マネージド仮想ネットワークがサポートされます。 サーバーレス Spark コンピューティング用にマネージド ネットワークがプロビジョニングされている場合は、データ アクセスを確保するために、ストレージ アカウントの対応するプライベート エンドポイントもプロビジョニングする必要があります。
スタンドアロン Spark ジョブを送信する
Python スクリプトのパラメーター化に必要な変更を加えた後、対話型データ ラングリングで開発された Python スクリプトを使用して、大量のデータを処理するバッチ ジョブを送信できます。 データ ラングリング バッチ ジョブをスタンドアロンの Spark ジョブとして送信できます。
Spark ジョブには、引数を受け取る Python スクリプトが必要です。 このスクリプトを開発するために、対話型データ ラングリングから開発された Python コードを変更できます。 サンプルの Python スクリプトを次に示します。
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Note
この Python コード サンプルでは、pyspark.pandas を使用します。 これは、Spark ランタイム バージョン 3.2 以降でのみサポートされます。
このスクリプトは、入力データと出力フォルダーのパスを渡す 2 つの引数を受け取ります。
--titanic_data--wrangled_data
適用対象: Azure CLI ml 拡張機能 v2 (現行)
ジョブを作成するには、スタンドアロンの Spark ジョブを YAML 仕様ファイルとして定義します。これを az ml job create コマンドの --file パラメーターで使用できます。 YAML ファイルでこれらのプロパティを定義します。
Spark ジョブ仕様での YAML プロパティ
type-sparkに設定します。code- このジョブのソース コードとスクリプトを含むフォルダーの場所を定義します。entry- ジョブのエントリ ポイントを定義します。 次のプロパティのいずれかを含む必要があります。file- ジョブのエントリ ポイントとして機能する Python スクリプトの名前を定義します。class_name- ジョブのエントリ ポイントとして機能するクラスの名前を定義します。
py_files- ジョブを正常に実行するためにPYTHONPATHに配置する、.zip、.egg、または.pyファイルの一覧を定義します。 このプロパティは省略可能です。jars- ジョブを正常に実行するために、Spark ドライバーに含める.jarファイルの一覧と、Executor のCLASSPATHを定義します。 このプロパティは省略可能です。files- ジョブの実行を成功させるために、各 Executor の作業ディレクトリにコピーする必要があるファイルの一覧を定義します。 このプロパティは省略可能です。archives- ジョブの実行を成功させるために、各 Executor の作業ディレクトリに抽出する必要があるアーカイブの一覧を定義します。 このプロパティは省略可能です。conf- Spark ドライバーと Executor の次のプロパティを定義します。spark.driver.cores: Spark ドライバー用のコアの数。spark.driver.memory: Spark ドライバー用に割り当てるメモリ (ギガバイト (GB) 単位)。spark.executor.cores: Spark Executor 用のコアの数。spark.executor.memory: Spark Executor 用のメモリの割り当て (ギガバイト (GB) 単位)。spark.dynamicAllocation.enabled- Executor を動的に割り当てる必要があるかどうか。値はTrueまたはFalse。- Executor の動的割り当てを有効にする場合は、次のプロパティを定義します。
spark.dynamicAllocation.minExecutors- 動的割り当て用の Spark Executor インスタンスの最小数。spark.dynamicAllocation.maxExecutors- 動的割り当て用の Spark Executor インスタンスの最大数。
- Executor の動的割り当てを無効にする場合は、次のプロパティを定義します。
spark.executor.instances- Spark Executor インスタンスの数。
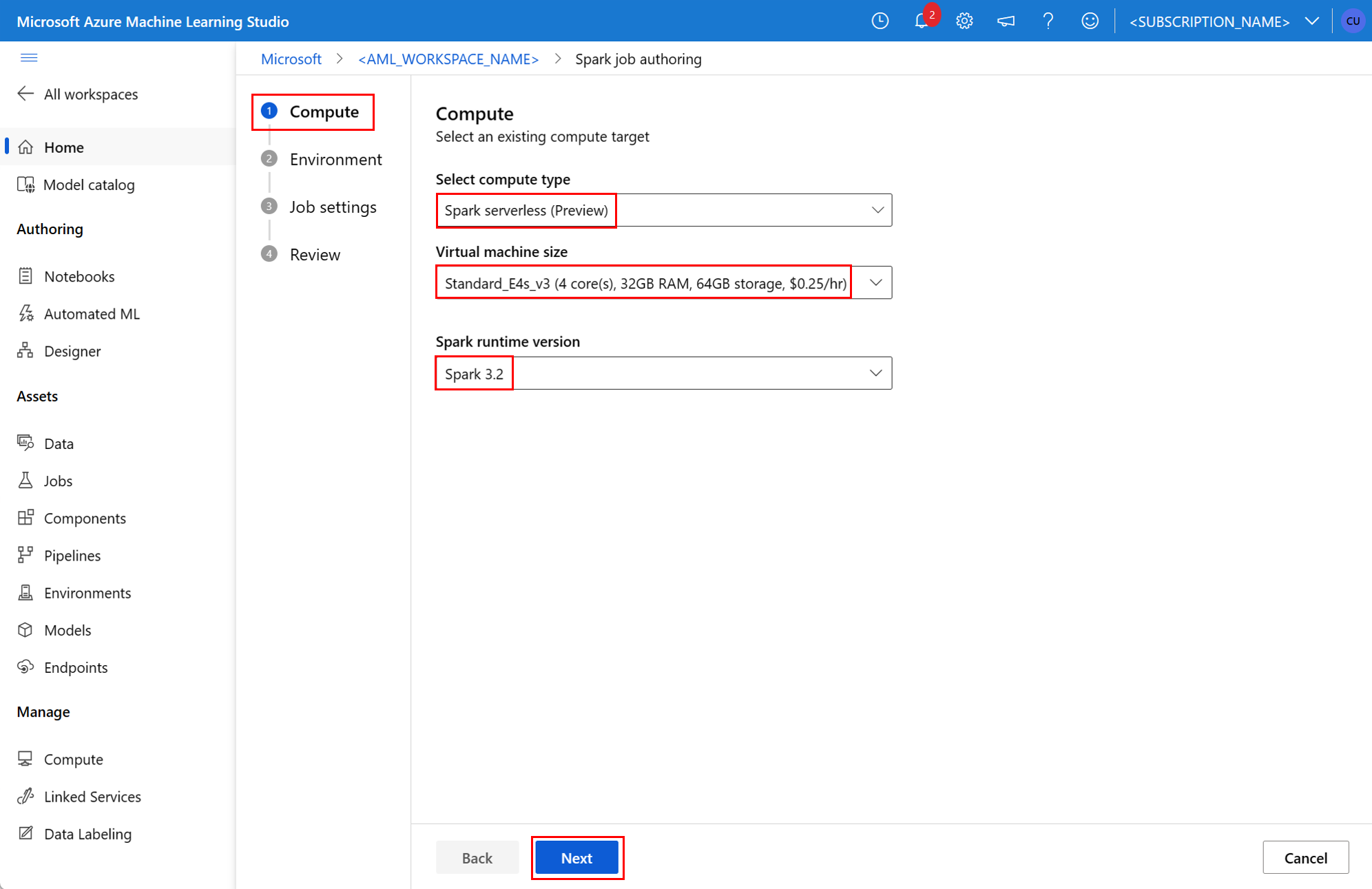
environment- ジョブを実行するための Azure Machine Learning 環境。args- ジョブのエントリ ポイントの Python スクリプトまたはクラスに渡す必要があるコマンド ライン引数。 例については、以下に示す YAML 仕様ファイルを参照してください。resources- このプロパティでは、Azure Machine Learning サーバーレス Spark コンピューティングで使われるリソースを定義します。 次のプロパティを使います。instance_type- Spark プールに使われるコンピューティング インスタンスの種類。 現在は、次のインスタンスの種類がサポートされています。standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version- Spark ランタイムのバージョンを定義します。 現在は、次の Spark ランタイムのバージョンがサポートされています。3.33.4重要
Azure Synapse Runtime for Apache Spark: お知らせ
- Azure Synapse Runtime for Apache Spark 3.3:
- EOLA のお知らせ日: 2024 年 7 月 12 日
- サポート終了日: 2025 年 3 月 31 日。 この日付を過ぎると、ランタイムは無効になります。
- 継続的なサポートと最適なパフォーマンスを得るには、Apache Spark 3.4 への移行をお勧めします。
- Azure Synapse Runtime for Apache Spark 3.3:
次に、YAML ファイルの例を示します。
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute- このプロパティでは、次の例に示すように、アタッチされる Synapse Spark プールの名前を定義します。compute: mysparkpoolinputs- このプロパティでは、Spark ジョブに対する入力を定義します。 Spark ジョブに入力できるのは、リテラル値、またはファイルやフォルダーに格納されているデータです。- リテラル値には、数値、ブール値、または文字列を指定できます。 いくつかの例を次に示します。
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - ファイルまたはフォルダーに格納されているデータは、次のプロパティを使って定義する必要があります。
type- 入力データがファイルまたはフォルダーに含まれる場合は、このプロパティをそれぞれuri_fileまたはuri_folderに設定します。path- 入力データの URI (azureml://、abfss://、wasbs://など)。mode- このプロパティをdirectに設定します。 このサンプルでは、$${inputs.titanic_data}}として参照できるジョブ入力の定義を示します。inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- リテラル値には、数値、ブール値、または文字列を指定できます。 いくつかの例を次に示します。
outputs- このプロパティでは、Spark ジョブの出力を定義します。 Spark ジョブの出力は、次の 3 つのプロパティを使って定義される、ファイルまたはフォルダーの場所に書き込むことができます。type- このプロパティをuri_fileまたはuri_folderに設定して、出力データをそれぞれファイルまたはフォルダーに書き込むことができます。path- このプロパティでは、出力場所の URI を定義します (azureml://、abfss://、wasbs://など)。mode- このプロパティをdirectに設定します。 このサンプルでは、${{outputs.wrangled_data}}として参照できるジョブ出力の定義を示します。outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity- この省略可能なプロパティでは、このジョブの送信に使われる ID を定義します。 指定できる値はuser_identityまたはmanagedです。 YAML 仕様で ID が定義されていない場合、Spark ジョブでは既定の ID が使用されます。
スタンドアロン Spark ジョブ
この YAML 仕様の例では、スタンドアロンの Spark ジョブを示します。 Azure Machine Learning サーバーレス Spark コンピューティングを使用します。
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Note
アタッチされた Synapse Spark プールを使用するには、resources プロパティではなく、前述のサンプル YAML 仕様ファイルで compute プロパティを定義します。
次のように、前述の YAML ファイルを az ml job create コマンドの --file パラメーターで使用して、スタンドアロン Spark ジョブを作成できます。
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
上のコマンドは以下から実行できます。
- Azure Machine Learning コンピューティング インスタンスのターミナル。
- Azure Machine Learning コンピューティング インスタンスに接続された Visual Studio Code ターミナル。
- Azure Machine Learning CLI がインストールされているローカル コンピューター。
パイプライン ジョブ内の Spark コンポーネント
Spark コンポーネントには、複数の Azure Machine Learning パイプラインのパイプライン ステップとして同じコンポーネントを使用できる柔軟性があります。
適用対象: Azure CLI ml 拡張機能 v2 (現行)
Spark コンポーネントの YAML 構文のほとんどは、Spark ジョブ仕様の YAML 構文に似ています。 次のプロパティは、Spark コンポーネントの YAML 仕様では定義が異なります。
name- Spark コンポーネントの名前。version- Spark コンポーネントのバージョン。display_name- UI や他の場所に表示する Spark コンポーネントの名前。description- Spark コンポーネントの説明。inputs- このプロパティは、Spark ジョブ仕様の YAML 構文で記述されるinputsプロパティに似ていますが、pathプロパティが定義されない点が異なります。 次のコード スニペットでは、Spark コンポーネントのinputsプロパティの例を示します。inputs: titanic_data: type: uri_file mode: directoutputs- このプロパティは、Spark ジョブ仕様の YAML 構文で記述されるoutputsプロパティに似ていますが、pathプロパティが定義されない点が異なります。 次のコード スニペットでは、Spark コンポーネントのoutputsプロパティの例を示します。outputs: wrangled_data: type: uri_folder mode: direct
Note
Spark コンポーネントでは、identity、compute、または resources プロパティは定義されません。 パイプラインの YAML 仕様ファイルにはこれらのプロパティが定義されています。
次に示す YAML 仕様ファイルは、Spark コンポーネントの例です。
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
上記の YAML 仕様ファイルで定義されている Spark コンポーネントは、Azure Machine Learning パイプライン ジョブで使用できます。 パイプライン ジョブを定義する YAML 構文の詳細については、パイプライン ジョブの YAML スキーマに関する参照資料を参照してください。 この例は、Spark コンポーネントと、Azure Machine Learning サーバーレス Spark コンピューティングを使った、パイプライン ジョブの YAML 仕様ファイルを示しています。
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
注意
アタッチされた Synapse Spark プールを使うには、前述のサンプル YAML 仕様ファイルで resources プロパティではなく compute プロパティを定義します。
上記の YAML 仕様ファイルは、次のように az ml job create コマンドで --file パラメーターを使用してパイプライン ジョブを作成するために使用できます。
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
上のコマンドは以下から実行できます。
- Azure Machine Learning コンピューティング インスタンスのターミナル。
- Azure Machine Learning コンピューティング インスタンスに接続された Visual Studio Code のターミナル。
- Azure Machine Learning CLI がインストールされているローカル コンピューター。
Spark ジョブのトラブルシューティング
Spark ジョブのトラブルシューティングを行うために、Azure Machine Learning スタジオでそのジョブに対して生成されたログにアクセスできます。 Spark ジョブのログを表示するには、次のようにします。
- Azure Machine Learning スタジオ UI の左側のパネルから [Jobs] (ジョブ) に移動します
- [すべてのジョブ] タブを選択します
- そのジョブの [表示名] の値を選択します
- ジョブの詳細ページで、[Output + logs] (出力 + ログ) タブを選択します
- エクスプローラーで [ログ] フォルダーを展開し、[azureml] フォルダーを展開します
- [ドライバー] および[ライブラリ マネージャー] のフォルダー内の Spark ジョブ ログにアクセスします
Note
ノートブック セッションで対話型データ ラングリング中に作成された Spark ジョブのトラブルシューティングを行うには、ノートブック UI の右上隅付近にある [ジョブの詳細] を選択します。 対話型ノートブック セッションの Spark ジョブが notebook-runs という実験名で作成されます。