レジストリを使用してワークスペース間でモデル、コンポーネント、環境を共有する
Azure Machine Learning レジストリを使うと、組織内のワークスペース間で共同作業を行うことができます。 レジストリを使うと、モデル、コンポーネント、環境を共有できます。
複数のワークスペースで同じモデル、コンポーネント、環境のセットを使うことが必要になるシナリオは 2 つあります。
-
クロスワークスペース MLOps:
devワークスペースでモデルをトレーニングしており、それをtestとprodワークスペースにデプロイする必要があります。 この場合は、testまたはprodワークスペースのモデルがデプロイされるエンドポイントと、devワークスペースでモデルのトレーニングに使われたトレーニング ジョブ、メトリック、コード、データ、環境の間に、エンドツーエンドの系列が存在する必要があります。 - 異なるチーム間でモデルとパイプラインを共有および再利用する: 共有と再利用により、コラボレーションと生産性が向上します。 このシナリオでは、トレーニング済みのモデルと、そのトレーニングに使われた関連するコンポーネントと環境を、中央カタログに発行できます。 他のチームの同僚は、そこから、共有されている資産を検索し、自分の実験で再利用できます。
この記事では、次の方法について学習します。
- レジストリに環境とコンポーネントを作成します。
- レジストリのコンポーネントを使って、ワークスペースのモデル トレーニング ジョブを送信します。
- トレーニング済みのモデルをレジストリに登録します。
- レジストリからワークスペース内のオンライン エンドポイントにモデルをデプロイした後、推論要求を送信します。
前提条件
この記事の手順に従う前に、次の前提条件が満たされていることをご確認ください。
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning をお試しください。
モデル、コンポーネント、環境を共有するための Azure Machine Learning レジストリ。 レジストリの作成については、レジストリの作成方法に関する記事をご覧ください。
Azure Machine Learning ワークスペース。 所有していない場合は、クイック スタート: ワークスペース リソースの作成に関する記事の手順に従って作成してください。
重要
ワークスペースを作成する Azure リージョン (場所) は、Azure Machine Learning レジストリがサポートされているリージョンの一覧に含まれている必要があります
Azure CLI と
ml拡張機能または Azure Machine Learning Python SDK v2:Azure CLI と拡張機能をインストールするには、「CLI (v2) のインストール、セットアップ、および使用」を参照してください。
重要
この記事の CLI の例では、Bash (または互換性のある) シェルを使用していることを前提としています。 たとえば、Linux システムや Linux 用 Windows サブシステムなどです。
また、この例では、サブスクリプション、ワークスペース、リソース グループ、または場所のパラメーターを指定する必要がないように、Azure CLI の既定値を構成してあることを前提としています。 既定の設定にするには、次のコマンドを使います。 次のパラメーターを、実際の構成の値に置き換えてください。
-
<subscription>は、Azure サブスクリプション ID に置き換えてください。 -
<workspace>は、ご利用の Azure Machine Learning ワークスペース名に置き換えます。 -
<resource-group>は、ワークスペースが含まれている Azure リソース グループに置き換えます。 -
<location>は、ワークスペースが含まれている Azure リージョンに置き換えます。
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>az configure -lコマンドを使用すると、現在の既定値を確認できます。-
examples リポジトリを複製する
この記事のコード例は、nyc_taxi_data_regression例のリポジトリの サンプルに基づいています。 開発環境でこれらのファイルを使うには、次のコマンドを使ってリポジトリをクローンし、ディレクトリを example に変更します。
git clone https://github.com/Azure/azureml-examples
cd azureml-examples
CLI の例の場合は、例のリポジトリのローカル クローンでディレクトリを cli/jobs/pipelines-with-components/nyc_taxi_data_regression に変更します。
cd cli/jobs/pipelines-with-components/nyc_taxi_data_regression
SDK の接続を作成する
ヒント
このステップは、Python SDK を使うときにのみ必要です。
Azure Machine Learning ワークスペースとレジストリの両方へのクライアント接続を作成します。
ml_client_workspace = MLClient( credential=credential,
subscription_id = "<workspace-subscription>",
resource_group_name = "<workspace-resource-group",
workspace_name = "<workspace-name>")
print(ml_client_workspace)
ml_client_registry = MLClient(credential=credential,
registry_name="<REGISTRY_NAME>",
registry_location="<REGISTRY_REGION>")
print(ml_client_registry)
レジストリで環境を作成する
環境で、トレーニング ジョブの実行またはモデルのデプロイに必要な Docker コンテナーと Python の依存関係を定義します。 環境について詳しくは、次の記事をご覧ください。
- 環境の概念
- 環境の作成方法 (CLI) に関する記事。
ヒント
同じ CLI コマンド az ml environment create を使用して、ワークスペースまたはレジストリに環境を作成できます。
--workspace-name を指定してコマンドを実行するとワークスペースに環境が作成され、--registry-name でコマンドを実行するとレジストリに環境が作成されます。
ここでは、python:3.8 Docker イメージを使う環境を作成し、SciKit Learn フレームワークを使ってトレーニング ジョブを実行するために必要な Python パッケージをインストールします。 サンプル リポジトリをクローンしてあり、cli/jobs/pipelines-with-components/nyc_taxi_data_regression フォルダーにいる場合は、Docker ファイル env_train/Dockerfile を参照する環境定義ファイル env_train.yml を確認できるはずです。 参照できるよう env_train.yml を以下に示します。
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: SKLearnEnv
version: 1
build:
path: ./env_train
次のように az ml environment create を使って環境を作成します
az ml environment create --file env_train.yml --registry-name <registry-name>
この名前とバージョンの環境がレジストリに既に存在するというエラーが発生する場合は、env_train.yml の version フィールドを編集するか、CLI で別のバージョンを指定して env_train.yml のバージョンの値をオーバーライドすることができます。
# use shell epoch time as the version
version=$(date +%s)
az ml environment create --file env_train.yml --registry-name <registry-name> --set version=$version
ヒント
version=$(date +%s) は Linux でのみ動作します。 これが機能しない場合は、$version をランダムな番号に置き換えてください。
az ml environment create コマンドの出力から環境の name と version を記録しておき、次のようにそれらを az ml environment show コマンドで使います。 次のセクションでレジストリにコンポーネントを作成するときに、name と version が必要になります。
az ml environment show --name SKLearnEnv --version 1 --registry-name <registry-name>
ヒント
使用した環境の名前またはバージョンが異なる場合は、それに応じて --name と --version パラメーターを置き換えます。
az ml environment list --registry-name <registry-name> を使って、レジストリ内のすべての環境の一覧を表示することもできます。
Azure Machine Learning スタジオですべての環境を参照できます。 グローバル UI に移動して、[レジストリ] エントリを探します。

レジストリにコンポーネントを作成する
コンポーネントは、Azure Machine Learning の Machine Learning パイプラインの再利用可能な構成要素です。 個々のパイプライン ステップのコード、コマンド、環境、入力インターフェイス、出力インターフェイスをコンポーネントにパッケージ化できます。 その後、異なるパイプラインを記述するたびに、依存関係とコードの移植について心配することなく、複数のパイプライン間でコンポーネントを再利用できます。
ワークスペースにコンポーネントを作成すると、そのワークスペース内の任意のパイプライン ジョブでコンポーネントを使用できます。 レジストリにコンポーネントを作成すると、組織内の任意のワークスペース内の任意のパイプラインでコンポーネントを使用できます。 レジストリにコンポーネントを作成することは、モジュール式の再利用可能なユーティリティや、組織内の異なるチームによる実験に使用できる共有トレーニング タスクを構築するための、優れた方法です。
コンポーネントについて詳しくは、次の記事をご覧ください。
-
重要
レジストリは、名前付きの資産 (データ/モデル/コンポーネント/環境) のみをサポートしています。 レジストリ内の資産を参照する場合は、まずレジストリ内にそれを作成する必要があります。 特にパイプライン コンポーネントの場合、パイプライン コンポーネント内に参照コンポーネントまたは環境が必要な場合は、まずレジストリにコンポーネントまたは環境を作成する必要があります。
cli/jobs/pipelines-with-components/nyc_taxi_data_regression フォルダーにいることを確認します。 Scikit Learn トレーニング スクリプト train_src/train.py とキュレーションされた環境AzureML-sklearn-0.24-ubuntu18.04-py37-cpu をパッケージ化したコンポーネント定義ファイル train.yml が見つかります。 キュレーションされた環境ではなく、前のステップで作成した Scikit Learn 環境を使います。 Scikit Learn 環境を参照するように、train.yml の environment フィールドを編集できます。 結果のコンポーネント定義ファイル train.yml は、次の例のようになります。
# <component>
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_linear_regression_model
display_name: TrainLinearRegressionModel
version: 1
type: command
inputs:
training_data:
type: uri_folder
test_split_ratio:
type: number
min: 0
max: 1
default: 0.2
outputs:
model_output:
type: mlflow_model
test_data:
type: uri_folder
code: ./train_src
environment: azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1`
command: >-
python train.py
--training_data ${{inputs.training_data}}
--test_data ${{outputs.test_data}}
--model_output ${{outputs.model_output}}
--test_split_ratio ${{inputs.test_split_ratio}}
これとは異なる名前またはバージョンを使用した場合、より一般的な表現は environment: azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version> のようになります。したがって、それに応じて <registry-name>、<sklearn-environment-name>、<sklearn-environment-version> を置き換えてください。 その後、次のように az ml component create コマンドを実行してコンポーネントを作成します。
az ml component create --file train.yml --registry-name <registry-name>
ヒント
同じ CLI コマンド az ml component create を使って、ワークスペースまたはレジストリにコンポーネントを作成できます。
--workspace-name を指定してコマンドを実行するとワークスペースにコンポーネントが作成され、--registry-name でコマンドを実行するとレジストリにコンポーネントが作成されます。
train.yml を編集したくない場合は、次のように CLI で環境名をオーバーライドできます。
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1
# or if you used a different name or version, replace `<sklearn-environment-name>` and `<sklearn-environment-version>` accordingly
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>
ヒント
コンポーネントの名前がレジストリに既に存在するというエラーが発生する場合は、train.yml でバージョンを編集するか、CLI でバージョンをランダムなバージョンにオーバーライドできます。
az ml component create コマンドの出力からコンポーネントの name と version を記録しておき、次のようにそれらを az ml component show コマンドで使います。 次のセクションでワークスペースにトレーニング ジョブを作成して送信するときに、name と version が必要になります。
az ml component show --name <component_name> --version <component_version> --registry-name <registry-name>
az ml component list --registry-name <registry-name> を使って、レジストリ内のすべてのコンポーネントの一覧を表示することもできます。
Azure Machine Learning スタジオですべてのコンポーネントを参照できます。 グローバル UI に移動して、[レジストリ] エントリを探します。

レジストリのコンポーネントを使用してワークスペースでパイプライン ジョブを実行する
レジストリのコンポーネントを使うパイプライン ジョブを実行するときは、"コンピューティング" リソースと "トレーニング データ" はワークスペースに対してローカルになります。 ジョブの実行について詳しくは、次の記事をご覧ください。
前のセクションで作成した Scikit Learn トレーニング コンポーネントを使ってパイプライン ジョブを実行し、モデルをトレーニングします。
cli/jobs/pipelines-with-components/nyc_taxi_data_regression フォルダーにいることを確認します。 トレーニング データセットは data_transformed フォルダーにあります。
single-job-pipeline.yml ファイルの train_job セクションの下にある component セクションを、前のセクションで作成したトレーニング コンポーネントを参照するように編集します。 結果の single-job-pipeline.yml は次のようになります。
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: nyc_taxi_data_regression_single_job
description: Single job pipeline to train regression model based on nyc taxi dataset
jobs:
train_job:
type: command
component: azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
compute: azureml:cpu-cluster
inputs:
training_data:
type: uri_folder
path: ./data_transformed
outputs:
model_output:
type: mlflow_model
test_data:
重要なのは、このパイプラインが特定のワークスペースにないコンポーネントを使ってワークスペースで実行されるということです。 コンポーネントは、組織内の任意のワークスペースで使用できるレジストリ内にあります。 このトレーニング ジョブは、ユーザーがアクセスできる任意のワークスペースで実行できます。そのワークスペースでトレーニング コードと環境を使用できるようにすることを心配する必要はありません。
警告
- パイプライン ジョブを実行する前に、ジョブを実行するワークスペースが、コンポーネントを作成したレジストリでサポートされている Azure リージョン内にあることを確認します。
- ワークスペースに
cpu-clusterという名前のコンピューティング クラスターがあることを確認するか、jobs.train_job.computeの下のcomputeフィールドをお使いのコンピューティングの名前で編集します。
az ml job create コマンドを使ってパイプライン ジョブを実行します。
az ml job create --file single-job-pipeline.yml
ヒント
前提条件のセクションで説明されているように、既定のワークスペースとリソース グループを構成していない場合、az ml job create を実行するには --workspace-name と --resource-group パラメーターを指定する必要があります。
または、single-job-pipeline.yml の編集をスキップし、train_job によって使われるコンポーネント名を CLI でオーバーライドすることもできます。
az ml job create --file single-job-pipeline.yml --set jobs.train_job.component=azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
トレーニング ジョブで使われるコンポーネントはレジストリを介して共有されるため、異なるサブスクリプション間でも、組織内でユーザーがアクセスできる任意のワークスペースにジョブを送信できます。 たとえば、dev-workspace、test-workspace、prod-workspace がある場合、az ml job create コマンドを 3 回実行するだけで、これら 3 つのワークスペースでトレーニング ジョブを簡単に実行できます。
az ml job create --file single-job-pipeline.yml --workspace-name dev-workspace --resource-group <resource-group-of-dev-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name test-workspace --resource-group <resource-group-of-test-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name prod-workspace --resource-group <resource-group-of-prod-workspace>
Azure Machine Learning スタジオで、ジョブ出力のエンドポイント リンクを選んでジョブを表示します。 ここでは、トレーニング メトリックを分析し、ジョブでレジストリのコンポーネントと環境が使われていることを確認し、トレーニング済みのモデルを確認できます。 出力からジョブの name を記録しておくか、Azure Machine Learning スタジオのジョブの概要から同じ情報を見つけます。 次のセクションでレジストリにモデルを作成するときに、トレーニング済みのモデルをダウンロードするためにこの情報が必要になります。

レジストリにモデルを作成する
このセクションでは、レジストリにモデルを作成する方法について説明します。 Azure Machine Learning でのモデルの管理について詳しくは、モデルの管理に関する記事をご覧ください。 ここでは、レジストリでモデルを作成する 2 つの異なる方法について説明します。 1 つ目はローカル ファイルからです。 2 つ目は、ワークスペースに登録されているモデルをレジストリにコピーします。
どちらのオプションでも、MLflow 形式のモデルを作成します。これは、推論コードを記述せずに推論のためにこのモデルをデプロイするのに役立ちます。
ローカル ファイルからレジストリにモデルを作成する
モデルをダウンロードします。これは、<job-name> を前のセクションのジョブからの名前に置き換えることで、train_job の出力として使用できます。 モデルと MLflow メタデータ ファイルは、./artifacts/model/ にあります。
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --query [0].name | sed 's/\"//g')
# download the default outputs of the train_job
az ml job download --name $train_job_name
# review the model files
ls -l ./artifacts/model/
ヒント
前提条件のセクションで説明されているように、既定のワークスペースとリソース グループを構成していない場合、az ml model create を実行するには --workspace-name と --resource-group パラメーターを指定する必要があります。
警告
az ml job list の出力が sed に渡されます。 これは Linux シェルでのみ機能します。 Windows を使っている場合は、az ml job list --parent-job-name <job-name> --query [0].name を実行し、トレーニング ジョブ名に含まれる引用符を除去します。
モデルをダウンロードできない場合は、前のセクションでトレーニング ジョブによってトレーニングされたサンプル MLflow モデルを cli/jobs/pipelines-with-components/nyc_taxi_data_regression/artifacts/model/ フォルダーで見つけることができます。
レジストリでモデルを作成します。
# create model in registry
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path ./artifacts/model/ --registry-name <registry-name>
ヒント
- モデル名とバージョンが存在するというエラーが発生する場合は、
versionパラメーターにランダムな値を使います。 - 同じ CLI コマンド
az ml model createを使って、ワークスペースまたはレジストリにモデルを作成できます。--workspace-nameを指定してコマンドを実行するとワークスペースにモデルが作成され、--registry-nameでコマンドを実行するとレジストリにモデルが作成されます。
ワークスペースからレジストリに対してモデルを共有する
このワークフローでは、最初にワークスペースでモデルを作成してから、それをレジストリに対して共有します。 このワークフローは、モデルを共有する前にワークスペースでそれをテストする場合に便利です。 たとえば、エンドポイントにデプロイし、いくつかのテスト データを使用して推論を試した後、すべてが問題なければモデルをレジストリにコピーします。 このワークフローは、異なる手法、フレームワーク、またはパラメーターを使って一連のモデルを開発していて、そのうちの 1 つだけを運用候補としてレジストリにレベル上げする場合にも役立ちます。
前のセクションのパイプライン ジョブの名前があることを確認し、コマンドでそれを置き換えて、以下のトレーニング ジョブ名をフェッチします。 次に、トレーニング ジョブの出力からワークスペースにモデルを登録します。
--path パラメーターで、azureml://jobs/$train_job_name/outputs/artifacts/paths/model という構文を使って train_job の出力を参照する方法に注意してください。
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --workspace-name <workspace-name> --resource-group <workspace-resource-group> --query [0].name | sed 's/\"//g')
# create model in workspace
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path azureml://jobs/$train_job_name/outputs/artifacts/paths/model
ヒント
- モデル名とバージョンが存在するというエラーが発生する場合は、
versionパラメーターにランダムな値を使います。 - 前提条件のセクションで説明されているように、既定のワークスペースとリソース グループを構成していない場合、
az ml model createを実行するには--workspace-nameと--resource-groupパラメーターを指定する必要があります。
モデル名とバージョンを記録しておきます。 スタジオの UI で参照するか、az ml model show --name nyc-taxi-model --version $model_version コマンドを使うことによって、モデルがワークスペースに登録されているかどうかを検証できます。
次に、ワークスペースからレジストリに対してモデルを共有します。
# share model registered in workspace to registry
az ml model share --name nyc-taxi-model --version 1 --registry-name <registry-name> --share-with-name <new-name> --share-with-version <new-version>
ヒント
-
az ml model createコマンドでモデル名とバージョンを変更した場合は、適切な値を使っていることを確認してください。 - 上記のコマンドには、"--share-with-name" と "--share-with-version" という 2 つの省略可能なパラメーターがあります。 これらが指定されていない場合、新しいモデルの名前とバージョンは、共有されているモデルと同じになります。
az ml model createコマンドの出力からモデルのnameとversionを記録しておき、次のようにそれらをaz ml model showコマンドで使います。 次のセクションで推論のためにモデルをオンライン エンドポイントにデプロイするときに、nameとversionが必要になります。
az ml model show --name <model_name> --version <model_version> --registry-name <registry-name>
また、az ml model list --registry-name <registry-name> を使ってレジストリ内のすべてのモデルを一覧表示したり、Azure Machine Learning スタジオの UI ですべてのコンポーネントを参照したりすることもできます。 グローバル UI に移動して、レジストリ ハブを探します。
次のスクリーンショットは、Azure Machine Learning スタジオでのレジストリのモデルを示しています。 ジョブの出力からモデルを作成し、ワークスペースからレジストリにモデルをコピーした場合、モデルにはモデルをトレーニングしたジョブへのリンクが含まれていることがわかります。 そのリンクを使ってトレーニング ジョブに移動し、モデルのトレーニングに使われたコード、環境、データを確認できます。
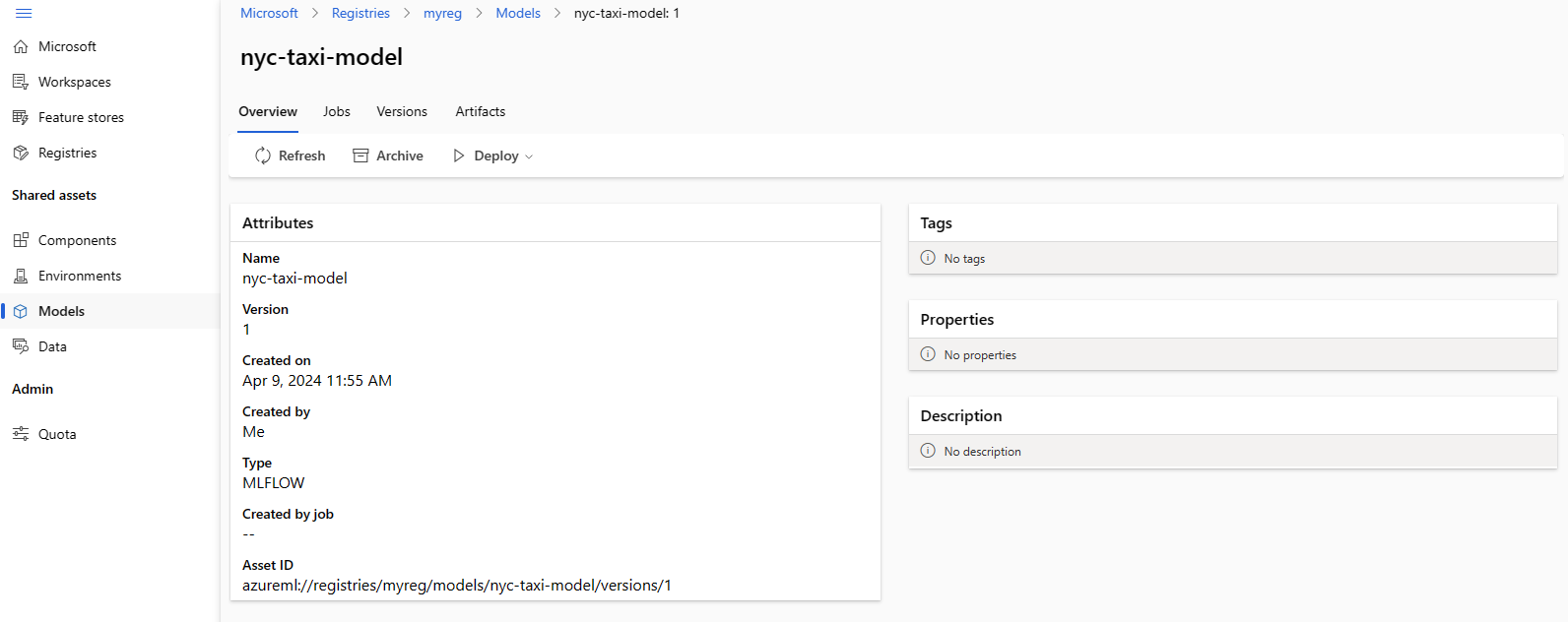
レジストリからワークスペースのオンライン エンドポイントにモデルをデプロイする
最後のセクションでは、レジストリからワークスペースのオンライン エンドポイントにモデルをデプロイします。 ワークスペースの場所がレジストリでサポートされている場所の 1 つである場合は、ユーザーが組織内でアクセスできる任意のワークスペースにデプロイできます。 この機能は、dev ワークスペースでモデルをトレーニングした後、モデルのトレーニングに使われたコード、環境、データに関する系列情報を保持しながら、モデルを test または prod ワークスペースにデプロイする必要がある場合に役立ちます。
オンライン エンドポイントを使うと、REST API を使って、モデルをデプロイして推論要求を送信できます。 詳しくは、オンライン エンドポイントを使用して機械学習モデルのデプロイとスコアリングを行う方法に関する記事をご覧ください。
オンライン エンドポイントを作成します。
az ml online-endpoint create --name reg-ep-1234
cli/jobs/pipelines-with-components/nyc_taxi_data_regression フォルダーにある deploy.yml の model: 行を、前のステップのモデル名とバージョンを参照するように更新します。 オンライン エンドポイントへのオンライン デプロイを作成します。 参照できるよう deploy.yml を以下に示します。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: demo
endpoint_name: reg-ep-1234
model: azureml://registries/<registry-name>/models/nyc-taxi-model/versions/1
instance_type: Standard_DS2_v2
instance_count: 1
オンライン デプロイを作成します。 デプロイが完了するまで、数分間かかります。
az ml online-deployment create --file deploy.yml --all-traffic
スコアリング URI をフェッチし、サンプルのスコアリング要求を送信します。 スコアリング要求のサンプル データは、cli/jobs/pipelines-with-components/nyc_taxi_data_regression フォルダーの scoring-data.json にあります。
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n reg-ep-1234 -o tsv --query primaryKey)
SCORING_URI=$(az ml online-endpoint show -n reg-ep-1234 -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @./scoring-data.json
ヒント
-
curlコマンドは Linux だけで機能します。 - 前提条件のセクションで説明されているように、既定のワークスペースとリソース グループを構成していない場合、
az ml online-endpointおよびaz ml online-deploymentコマンドを実行するには--workspace-nameと--resource-groupパラメーターを指定する必要があります。
リソースをクリーンアップする
デプロイを使う予定がない場合は、コスト削減のために削除する必要があります。 次の例では、エンドポイントと基になるすべてのデプロイを削除します。
az ml online-endpoint delete --name reg-ep-1234 --yes --no-wait