Azure Machine Learning 推論ルーターは、Kubernetes クラスターを使用したリアルタイム推論に不可欠なコンポーネントです。 この記事では、次の内容について説明します。
- Azure Machine Learning 推論ルーターとは
- 自動スケーリングのしくみ
- 推論要求のパフォーマンス (1 秒あたりの要求数と待機時間) を構成して満たす方法
- AKS 推論クラスターの接続要件
Azure Machine Learning 推論ルーターとは
Azure Machine Learning 推論ルーターは、Azure Machine Learning 拡張機能のデプロイ時に AKS または Arc Kubernetes クラスターにデプロイされるフロントエンド コンポーネント (azureml-fe) です。 これには次の機能があります。
- クラスター ロード バランサーまたはイングレス コントローラーからの受信推論要求を、対応するモデル ポッドにルーティングします。
- スマート調整ルーティングを使用して、すべての受信推論要求を負荷分散します。
- モデル ポッドの自動スケーリングを管理します。
- フォールト トレラントとフェールオーバーの機能により、推論要求は常に重要なビジネス アプリケーションに対して提供されます。
次の手順は、要求がフロントエンドによって処理される方法です。
- クライアントはロード バランサーに要求を送信します。
- ロード バランサーは、いずれかのフロントエンドに送信します。
- フロントエンドはサービスのサービス ルーター (コーディネーターとして機能するフロントエンド インスタンス) を見つけます。
- サービス ルーターはバックエンドを選択し、フロントエンドに返します。
- フロントエンドは、要求をバックエンドに転送します。
- 要求が処理されると、バックエンドはフロントエンド コンポーネントに応答を送信します。
- フロントエンドは、応答をクライアントに伝達します。
- フロントエンドは、バックエンドが処理を終了して他の要求で使用可能であることをサービス ルーターに通知します。
次の図は、このフローを示しています。
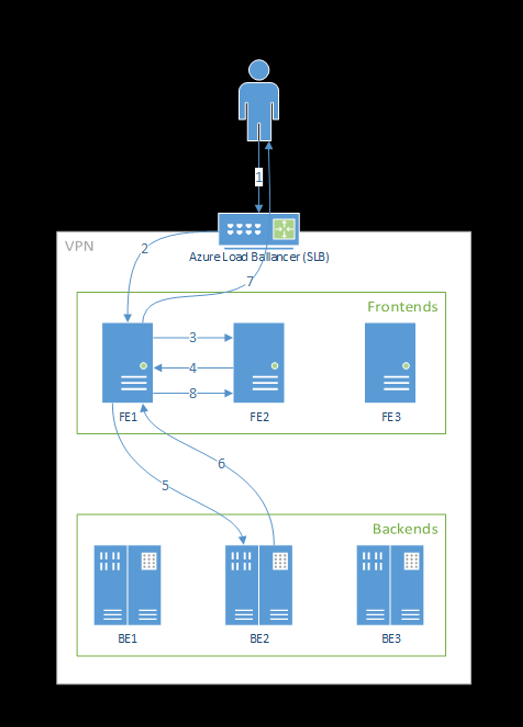
上の図からわかるように、Azure Machine Learning 拡張機能のデプロイ中に既定で 3 つの azureml-fe インスタンスが作成され、1 つのインスタンスが調整ロールとして機能し、別のインスタンスは受信推論要求を処理します。 調整インスタンスには、モデル ポッドに関するすべての情報が含まれており、どのモデル ポッドが受信要求を処理するかに関する決定が行われます。一方、サービスを提供する azureml-fe インスタンスは、選択したモデル ポッドに要求をルーティングし、応答を元のユーザーに伝達する役割を担います。
自動スケール
Azure Machine Learning 推論ルーターでは、Kubernetes クラスターのすべてのモデル デプロイのための自動スケーリングが処理されます。 すべての推論要求が通過するため、ここには、デプロイされたモデルを自動的にスケーリングするために必要なデータが保持されます。
重要
モデル デプロイでは、Kubernetes のポッドの水平オートスケーラー (HPA) を有効にしないでください。 有効にすると、2 つの自動スケール コンポーネントが互いに競合します。 azureml-fe は、Azure Machine Learning によってデプロイされたモデルを自動スケールするように設計されています。この設計では、HPA が CPU 使用率やカスタム メトリック構成などの汎用メトリックから、モデルの使用率を推測または概算する必要があります。
azureml-fe によって、AKS クラスターのノードの数はスケーリングされません。これは、予期しないコストの増加につながる可能性があるからです。 その代わりに、物理クラスターの境界内でモデルのレプリカの数をスケーリングします。 クラスター内のノードの数をスケーリングする必要がある場合は、手動でクラスターをスケーリングするか、AKS クラスター オートスケーラーを構成することができます。
自動スケールは、デプロイ YAML の scale_settings プロパティによって制御できます。 自動スケールを有効にする方法を次の例に示します。
# deployment yaml
# other properties skipped
scale_setting:
type: target_utilization
min_instances: 3
max_instances: 15
target_utilization_percentage: 70
polling_interval: 10
# other deployment properties continue
スケールアップまたはダウンの決定は、utilization of the current container replicas に基づきます。
utilization_percentage = (The number of replicas that are busy processing a request + The number of requests queued in azureml-fe) / The total number of current replicas
この数が target_utilization_percentage を超えると、さらにレプリカが作成されます。 これが下回ると、レプリカが減少します。 既定では、ターゲット使用率は 70% です。
レプリカの追加は、集中的かつ迅速に決定されます (約 1 秒)。 レプリカの削除は慎重に決定されます (約 1 分)。
たとえば、モデル サービスをデプロイするとき、ターゲットとする 1 秒あたりの要求数 (RPS) と応答時間にするために、いくつのインスタンス (ポッド数/レプリカ数) を構成する必要があるかを知りたい場合があります。 必要なレプリカの数は、次のコードを使用して計算できます。
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
azureml-fe のパフォーマンス
azureml-fe は 5000 件/秒 (QPS) の要求数に到達でき、待機時間も良好、オーバーヘッドが平均で 3 ミリ秒を、99% パーセンタイルで 15 ミリ秒を超えません。
Note
RPS 要件が 10,000 件を超える場合は、次のオプションを検討してください。
-
azureml-feポッドのリソース要求/制限を増やします。既定では、2 つの vCPU と 1.2 G のメモリ リソース制限があります。 -
azureml-feのインスタンスの数を増やします。 既定では、Azure Machine Learning が 3 つまたは 1 つのazureml-feインスタンスをクラスターごとに作成します。- このインスタンス数は、Azure Machine Learning 拡張機能の
inferenceRouterHAの構成によって異なります。 - 増加したインスタンス数は、拡張機能がアップグレードされると、構成された値で上書きされるため、持続できません。
- このインスタンス数は、Azure Machine Learning 拡張機能の
- Microsoft のエキスパートにお問い合わせください。
AKS 推論クラスターの接続要件を理解する
AKS クラスターは、次の 2 つのネットワーク モデルのいずれかでデプロイされます。
- Kubenet ネットワーク - AKS クラスターのデプロイ時に、通常はネットワーク リソースが作成され、構成されます。
- Azure Container Networking Interface (CNI) ネットワーク - AKS クラスターは、既存の仮想ネットワーク リソースと構成に接続されます。
Kubenet ネットワークでは、ネットワークが作成され、Azure Machine Learning service 用に適切に構成されます。 CNI ネットワークでは、接続要件を理解し、AKS 推論のための DNS 解決と送信接続を確認する必要があります。 たとえば、ファイアウォールを使用してネットワーク トラフィックをブロックする場合は、追加の手順が必要になる場合があります。
次の図は、AKS 推論の接続要件を示しています。 黒い矢印は実際の通信を表し、青い矢印はドメイン名を表します。 これらのホストのエントリをファイアウォールまたはカスタム DNS サーバーに追加することが必要になる場合があります。
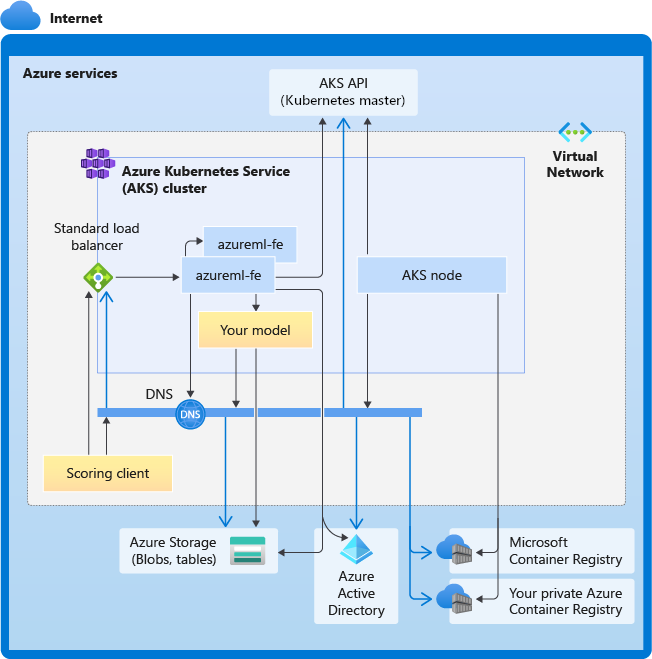
一般的な AKS 接続要件については、「Azure Kubernetes Service (AKS) でクラスター ノードに対するエグレス トラフィックを制御する」を参照してください。
ファイアウォールの向こう側にある Azure Machine Learning サービスにアクセスする方法については、「ネットワークの着信トラフィックおよび送信トラフィックを構成する」を参照してください。
全体的な DNS 解決の要件
既存の VNet 内の DNS 解決は、お客様の管理下にあります。 たとえば、ファイアウォールやカスタム DNS サーバーなどです。 次のホストに到達できる必要があります。
| ホスト名 | 使用者 |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
AKS API サーバー |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Azure Container Registry (ACR) |
<account>.blob.core.windows.net |
Azure Storage アカウント (BLOB ストレージ) |
api.azureml.ms |
Microsoft Entra 認証 |
ingest-vienna<region>.kusto.windows.net |
利用統計情報をアップロードするための Kusto エンドポイント |
クラスターの作成からモデル デプロイまで、時系列順の接続要件
azureml-fe はデプロイされるとすぐに開始しようとしますが、これには次の処理を行う必要があります。
- AKS API サーバーの DNS を解決する
- AKS API サーバーにそれ自体の他のインスタンスを検出するためにクエリを実行する (マルチポッド サービス)
- それ自体の他のインスタンスに接続する
azureml-fe が開始されると、正常に機能するために次の接続が必要になります。
- Azure Storage に接続して動的構成をダウンロードする
- デプロイされたサービスが Microsoft Entra 認証を使ってる場合は、Microsoft Entra 認証サーバー api.azureml.ms の DNS を解決して、それと通信します。
- デプロイされたモデルを検出するために AKS API サーバーにクエリを実行する
- デプロイされたモデル POD と通信する
モデルのデプロイ時に、モデル デプロイが成功すると、AKS ノードでは次の操作が可能になります。
- お客様の ACR の DNS を解決する
- お客様の ACR からイメージをダウンロードする
- モデルが格納されている Azure BLOB の DNS を解決する
- Azure BLOB からモデルをダウンロードする
モデルがデプロイされ、サービスが開始されると、azureml-fe は AKS API を使用してモデルを自動的に検出して、要求をそこにルーティングできるようになります。 モデル POD と通信できる必要があります。
注意
デプロイされたモデルに接続が必要な場合 (外部データベースやその他の REST サービスへのクエリの実行や BLOB のダウンロードなど)、これらのサービスの DNS 解決と送信通信の両方を有効にする必要があります。