機械学習パイプラインのトラブルシューティング
適用対象:  Python SDK azureml v1
Python SDK azureml v1
この記事では、Azure Machine Learning SDK および Azure Machine Learning デザイナーで機械学習パイプラインの実行時にエラーが発生した場合にトラブルシューティングを行う方法について説明します。
トラブルシューティングのヒント
次の表に、パイプライン開発時の一般的な問題と、考えられる解決策を示します。
| 問題 | 考えられる解決策 |
|---|---|
PipelineData ディレクトリにデータを渡せない |
パイプラインがステップの出力データを想定する場所に、スクリプトでディレクトリを作成したことを確認してください。 ほとんどの場合、入力引数によって出力ディレクトリが定義され、ディレクトリが明示的に作成されます。 出力ディレクトリを作成するには、os.makedirs(args.output_dir, exist_ok=True) を使用します。 この設計パターンを示すスコアリング スクリプトの例については、こちらのチュートリアルを参照してください。 |
| 依存関係のバグ | ローカルでのテスト時には発生しなかった依存関係エラーがリモート パイプラインで発生する場合は、リモート環境の依存関係とバージョンがテスト環境のものと一致していることを確認します。 (「環境のビルド、キャッシュ、再利用」を参照してください。) |
| コンピューティング ターゲットでのあいまいなエラー | コンピューティング先を削除してから再作成してみてください。 コンピューティング先は簡単に再作成でき、いくつかの一時的な問題を解決できます。 |
| ステップを再利用しないパイプライン | ステップの再利用は既定で有効になっていますが、パイプライン ステップで無効にしていないか確認してください。 再利用が無効になっている場合は、ステップの allow_reuse パラメーターが False に設定されています。 |
| パイプラインが不必要に再実行される | 基になるデータまたはスクリプトが変更されたときにのみステップが再実行されるようにするには、各ステップのソース コード ディレクトリを分離します。 複数のステップに同じソース ディレクトリを使用すると、不要に再実行される可能性があります。 パイプライン ステップ オブジェクトで source_directory パラメーターを使用して、そのステップの分離されたディレクトリを指定し、複数のステップで同じ source_directory パスを使用しないようにします。 |
| トレーニング エポックや他のループ動作よりもステップが遅くなる | ログを含め、すべてのファイルの書き込みを as_mount() から as_upload() に切り替えてみてください。 マウント モードでは、リモートの仮想化ファイルシステムを使用し、ファイルが追加されるたびにファイル全体がアップロードされます。 |
| コンピューティング先の起動に時間がかかる | コンピューティング先の Docker イメージは、Azure Container Registry (ACR) から読み込まれます。 既定では、Azure Machine Learning により、"basic" サービス レベルを使用する ACR が作成されます。 ワークスペースの ACR を standard または premium レベルに変更すると、イメージの構築と読み込みにかかる時間が短縮される場合があります。 詳細については、「Azure Container Registry サービス階層」を参照してください。 |
認証エラー
リモート ジョブからコンピューティング ターゲットの管理操作を実行すると、次のいずれかのエラーが発生します。
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
たとえば、リモート実行のために送信される ML パイプラインからコンピューティング ターゲットを作成またはアタッチしようとすると、エラーが発生します。
ParallelRunStep のトラブルシューティング
ParallelRunStep スクリプトには、2 つの関数が "含まれている必要があります"。
init():この関数は、後で推論するためのコストのかかる準備、または一般的な準備を行うときに使用します。 たとえば、これを使って、モデルをグローバル オブジェクトに読み込みます。 この関数は、プロセスの開始時に 1 回だけ呼び出されます。run(mini_batch): この関数は、mini_batchインスタンスごとに実行されます。mini_batch:ParallelRunStepは run メソッドを呼び出して、そのメソッドに、リストまたは PandasDataFrameのいずれかを引数として渡します。 mini_batch のエントリはそれぞれ、ファイル パス (入力がFileDatasetの場合) または PandasDataFrame(入力がTabularDatasetの場合) になります。response: run() メソッドは、PandasDataFrameまたは配列を返します。 append_row output_action の場合、これらの返される要素は、共通の出力ファイルに追加されます。 summary_only の場合、要素のコンテンツは無視されます。 すべての出力アクションについて、返される出力要素はそれぞれ、入力ミニバッチ内で成功した 1 つの入力要素の実行を示します。 入力を実行出力結果にマップできるだけの十分なデータが実行結果に含まれていることを確認してください。 実行の出力は出力ファイルに書き込まれますが、順序どおりであることは保証されません。出力でいずれかのキーを使って、入力にマップする必要があります。
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
推論スクリプトと同じディレクトリに他のファイルまたはフォルダーがある場合、現在の作業ディレクトリを特定することでそれらを参照することができます。
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
ParallelRunConfig のパラメーター
ParallelRunConfig は、Azure Machine Learning パイプライン内にある ParallelRunStep インスタンスの主要な構成です。 これは、お使いのスクリプトをラップし、必要なパラメーターを構成するときに使用します。たとえば、次のようなエントリです。
entry_script: 複数のノード上で並列で実行されるローカル ファイル パスとしてのユーザー スクリプト。source_directoryが存在する場合は、相対パスを使用します。 それ以外の場合は、マシンでアクセス可能な任意のパスを使用します。mini_batch_size:1 つのrun()呼び出しに渡されたミニバッチのサイズ (省略可能。既定値は、FileDatasetの場合は10ファイルで、TabularDatasetの場合は1MBです。)FileDatasetの場合、これはファイル数を示し、最小値は1です。 複数のファイルを 1 つのミニバッチに結合できます。TabularDatasetの場合は、データのサイズです。 サンプル値は、1024、1024KB、10MB、および1GBです。 推奨値は1MBです。TabularDatasetのミニバッチは、ファイル境界を超えません。 たとえば、さまざまなサイズの .csv ファイルがある場合、ファイルの最小サイズは 100 KB で、最大サイズは 10 MB です。mini_batch_size = 1MBを設定すると、サイズが 1 MB より小さいファイルは 1 つのミニバッチとして処理されます。 サイズが 1 MB を超えるファイルは、複数のミニバッチに分割されます。
error_threshold:処理中に無視する必要のあるエラーの数。TabularDatasetの場合はレコード エラー数、FileDatasetの場合はファイル エラー数を示します。 入力全体に対するエラーの数がこの値を超えると、ジョブは中止されます。 エラーのしきい値は入力全体を対象としています。run()メソッドに送信された個々のミニバッチを対象にしているものではありません。 範囲は[-1, int.max]です。-1部分は、処理中にすべてのエラーを無視することを示します。output_action: 次のいずれかの値が、出力がどのように構成されるかを示しています:summary_only: ユーザー スクリプトが出力を保存します。ParallelRunStepは、エラーしきい値の計算に出力のみを使用します。append_row: すべての入力について、出力フォルダーにファイルが 1 つだけ作成され、行で区切られたすべての出力が追加されます。
append_row_file_name:append_row output_action の出力ファイル名をカスタマイズします (省略可能。既定値はparallel_run_step.txtです)。source_directory:コンピューティング ターゲットで実行されるすべてのファイルを含むフォルダーへのパス (省略可能)。compute_target:サポートされるのはAmlComputeのみです。node_count:ユーザー スクリプトの実行に使用されるコンピューティング ノードの数。process_count_per_node:ノードあたりのプロセスの数。 ベスト プラクティスとして、ノードあたりの GPU または CPU の数に設定します (省略可能。既定値は1です)。environment:Python 環境定義。 既存の Python 環境が使用されるように、または一時的な環境が設定されるように構成できます。 定義で、必要なアプリケーションの依存関係を設定することもできます (省略可能)。logging_level:ログの詳細。 値は詳細度が低い順にWARNING、INFO、DEBUGです。 (省略可能。既定値はINFOです)run_invocation_timeout:run()メソッド呼び出しのタイムアウト (秒単位)。 (省略可能、既定値は60です)run_max_try:ミニバッチに対するrun()の最大試行回数。 例外がスローされた場合、run()は失敗します。run_invocation_timeoutに到達した場合は何も返されません (省略可能。既定値は3です)。
mini_batch_size、node_count、process_count_per_node、logging_level、run_invocation_timeout、run_max_try を PipelineParameter として指定すると、パイプラインの実行を再送信するときに、パラメーターの値を微調整できます。 この例では、mini_batch_size と Process_count_per_node に PipelineParameter を使用し、後で実行を再送信するときに、これらの値を変更します。
ParallelRunStep を作成するためのパラメーター
スクリプト、環境構成、およびパラメーターを使用して、ParallelRunStep を作成します。 お使いの推論スクリプトの実行の対象としてご自身のワークスペースに関連付けたコンピューティング ターゲットを指定します。 ParallelRunStep を使用して、バッチ推論パイプラインのステップを作成します。このステップでは、次のすべてのパラメーターが使用されます。
name: ステップの名前。3 文字以上 32 文字以内で、一意の名前にする必要があります。また、正規表現 ^[a-z]([-a-z0-9]*[a-z0-9])?$ を使用できます。parallel_run_config:ParallelRunConfigオブジェクト (前述にて定義)。inputs:並列処理のためにパーティション分割される 1 つ以上の single 型の Azure Machine Learning データセット。side_inputs:パーティション分割する必要のないサイド入力として使用される 1 つ以上の参照データまたはデータセット。output:OutputFileDatasetConfigオブジェクト (出力ディレクトリに対応)。arguments:ユーザー スクリプトに渡された引数の一覧。 それらを実際のエントリ スクリプト内で取得するには、unknown_args を使用します (省略可能)。allow_reuse:同じ設定/入力で実行されたときに、ステップで前の結果を再利用するかどうか。 このパラメーターがFalseの場合、パイプラインの実行中に、このステップに対して新しい実行が生成されます。 (省略可能。既定値はTrueです)。
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
デバッグ手法
パイプラインのデバッグには 3 つの主要な手法があります。
- ローカル コンピューター上で個々のパイプライン ステップをデバッグする
- ログと Application Insights を使用して問題の原因を分離し、診断する
- Azure で実行しているパイプラインにリモート デバッガーをアタッチする
スクリプトをローカルでデバッグする
パイプラインにおける最も一般的な失敗の 1 つは、ドメイン スクリプトが意図したとおりに実行されないこと、またはリモート コンピューティングのコンテキストではデバッグが困難なランタイム エラーが含まれていることです。
パイプライン自体をローカルで実行することはできません。 ローカル マシン上の分離環境でスクリプトを実行すると、コンピューティングと環境のビルド プロセスを待つ必要がないため、より早くデバッグを行えます。 これを行うには、いくつかの開発作業が必要です。
- データがクラウド データストアにある場合は、データをダウンロードして、スクリプトで使用できるようにする必要があります。 小さなデータのサンプルの使用は、実行時間を短縮して、スクリプトの動作に関するフィードバックをすぐに得るために有効な方法です
- 中間パイプラインの手順をシミュレートしようとしている場合、その特定のスクリプトが前のステップから受け取ることを想定しているオブジェクトの種類を手動で構築しなければならない場合があります
- 独自の環境を定義し、リモート コンピューティング環境で定義されている依存関係をレプリケートする必要があります
ローカル環境で実行するスクリプトのセットアップが完了すると、次のようなデバッグ タスクの実行が容易になります。
- カスタム デバッグ構成のアタッチ
- 実行の停止とオブジェクトの状態の確認
- 実行時まで確認できない型や論理エラーの把握
ヒント
スクリプトが想定どおりに実行されることを確認したら、次の手順として、複数ステップのパイプラインで実行する前に、単一ステップのパイプラインでスクリプトを実行することをお勧めします。
パイプライン ログの構成、書き込み、および確認
スクリプトをローカルでテストすることは、パイプラインの構築を開始する前に、主要なコード フラグメントと複雑なロジックをデバッグするための優れた方法です。 特にパイプライン ステップの間の相互作用中に起こる動作を診断するときなど、いずれは実際のパイプライン自体の実行中にスクリプトをデバッグする必要があります。 JavaScript コードをデバッグする場合と同様に、リモート実行時にオブジェクトの状態と予期される値を確認できるように、ステップ スクリプトで print() ステートメントを適宜使用することをお勧めします。
ログ オプションと動作
次の表は、パイプラインのさまざまなデバッグ オプションに関する情報を示しています。 これは完全なリストではありません。ここに示されている Azure Machine Learning や Python のオプションの他にもオプションはあります。
| ライブラリ | Type | 例 | 宛先 | リソース |
|---|---|---|---|---|
| Azure Machine Learning SDK | メトリック | run.log(name, val) |
Azure Machine Learning ポータル UI | 実験を追跡する方法 azureml.core.Run クラス |
| Python の印刷とログ | ログ | print(val)logging.info(message) |
ドライバー ログ、Azure Machine Learning デザイナー | 実験を追跡する方法 Python のログ |
ログ オプションの例
import logging
from azureml.core.run import Run
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
Azure Machine Learning デザイナー
デザイナーで作成されたパイプラインの場合、作成ページまたはパイプラインの実行の詳細ページで、70_driver_log ファイルが確認できます。
リアルタイム エンドポイントのログ記録を有効にする
デザイナーでリアルタイム エンドポイントのトラブルシューティングとデバッグを行うには、SDK を使用して Application Insight のログ記録を有効にする必要があります。 ログ記録を使用すると、モデル デプロイと使用に関する問題のトラブルシューティングとデバッグを行うことができます。 詳細については、デプロイ済みモデルのログ記録に関する記事をご覧ください。
作成ページからログを取得する
パイプライン実行を送信し、作成ページを表示したままにしておくと、各コンポーネントの実行が終了した時点で、ログ ファイルがコンポーネントごとに生成されるのを確認できます。
作成キャンバスでの実行が終了したコンポーネントを選択します。
コンポーネントの右ペインで、[Outputs + logs](出力 + ログ) タブに移動します。
右ペインを展開して 70_driver_log.txt を選択し、ブラウザーにファイルを表示します。 また、ログをローカルにダウンロードすることもできます。
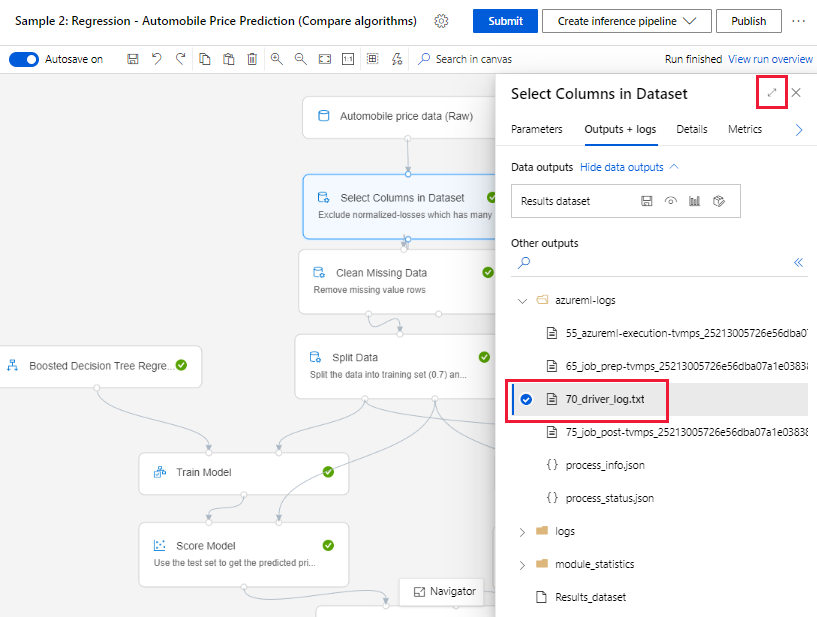
パイプラインの実行からログを取得する
パイプラインの実行の詳細ページで特定の実行のためのログ ファイルを見つけることもできます。Studio の [パイプライン] または [実験] セクションどちらかで確認できます。
デザイナーで作成されたパイプラインの実行を選択します。
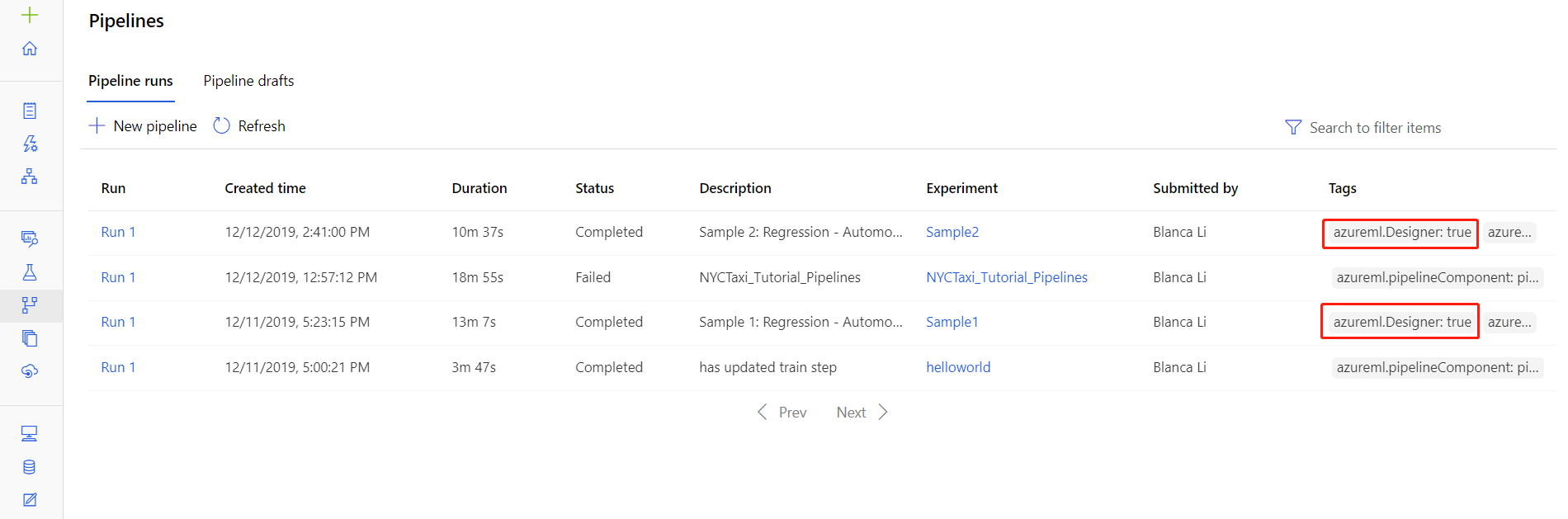
プレビュー ペインでコンポーネントを選択します。
コンポーネントの右ペインで、[Outputs + logs](出力 + ログ) タブに移動します。
右側ペインを展開して、ブラウザーで std_log.txt ファイルを表示するか、またはファイルを選択してログをローカルにダウンロードします。
重要
パイプラインの実行の詳細ページからパイプラインを更新するには、新しいパイプライン ドラフトにパイプラインの実行を複製する必要があります。 パイプラインの実行は、パイプラインのスナップショットです。 ログ ファイルに似ており、変更することはできません。
Visual Studio Code を使用した対話型デバッグ
場合によっては、ML パイプラインで使用される Python コードを対話的にデバッグする必要が生じることがあります。 Visual Studio Code (VS Code) と debugpy を使用すると、トレーニング環境で実行されているコードにアタッチできます。 詳細については、VS Code での対話型デバッグのガイドを参照してください。
HyperdriveStep と AutoMLStep がネットワークの分離で失敗する
HyperdriveStep と AutoMLStep を使用した後、モデルを登録しようとするとエラーが発生する場合があります。
Azure Machine Learning SDK v1 を使用しています。
Azure Machine Learning ワークスペースがネットワークの分離 (VNet) 用に構成されています。
パイプラインで、前の手順を行って生成したモデルを登録しようとしています。 たとえば、次のコードでは、
inputsパラメーターは HyperdriveStep からの saved_model です。register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
回避策
重要
この動作は、Azure Machine Learning SDK v2 を使用する場合は起こりません。
このエラーを回避するには、Run クラスを使用して、HyperdriveStep または AutoMLStep から作成されたモデルを取得します。 HyperdriveStep から出力モデルを取得するスクリプトの例を、次に示します。
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
このファイルはこれで PythonScriptStep から使用できるようになります。
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
次のステップ
ParallelRunStepの使用に関する完全なチュートリアルについては、「チュートリアル:バッチ スコアリング用の Azure Machine Learning パイプラインを作成する」に従います。ML パイプラインでの自動機械学習を示す完全な例については、「Python の Azure Machine Learning パイプラインで自動 ML を使用する」を参照してください。
azureml-pipelines-core パッケージおよび azureml-pipelines-steps パッケージについては、SDK リファレンスを参照してください。
デザイナーの例外とエラー コードの一覧を参照してください。