データ資産の作成と管理
適用対象: Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
この記事では、Azure Machine Learning でデータ資産を作成および管理する方法について説明します。
データ資産は、次の場合に役立ちます。
- バージョン管理: データ資産ではデータのバージョン管理がサポートされています。
- 再現性: いったん作成したデータ資産のバージョンは "不変" となります。 変更も削除もできません。 したがって、データ資産を取り込んで使用するトレーニング ジョブやパイプラインを再現できます。
- 監査可能性: データ資産のバージョンは不変であるため、資産のバージョン、バージョンの更新者、更新日時を追跡できます。
- データ系列: 特定のデータ資産について、そのデータを取り込んで使用するジョブやパイプラインを確認することができます。
- 使いやすさ: Azure Machine Learning データ資産は、Web ブラウザーのブックマーク (お気に入り) に似ています。 Azure Storage 上の使用頻度の高いデータを "参照"する長い記憶域パス (URI) を覚えておかなくても、データ資産の "バージョン" を作成しておけば、フレンドリ名 (例:
azureml:<my_data_asset_name>:<version>) でそのバージョンの資産にアクセスできます。
ヒント
対話型セッション (ノートブックなど) やジョブでデータにアクセスする場合、最初にデータ資産を作成する必要はありません。 データストア URI を使用してデータにアクセスできます。 データストア URI を使用すると、簡単にデータにアクセスして、Azure Machine Learning の使用を開始できます。
前提条件
データ資産を作成して操作するには、以下が必要です。
Azure サブスクリプション。 まだ持っていない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning をお試しください。
Azure Machine Learning ワークスペース。 ワークスペース リソースの作成.
データ資産を作成する
データ資産を作成するときに、データ資産の種類を設定する必要があります。 Azure Machine Learning では、次の 3 種類のデータ資産がサポートされています。
| Type | API | 標準シナリオ |
|---|---|---|
| [最近使ったファイル] 1 つのファイルを参照します |
uri_file |
Azure Storage 上の個別のファイルを読み取ります (ファイルの形式は任意)。 |
| フォルダー フォルダーを参照します |
uri_folder |
Parquet/CSV ファイルのフォルダーを Pandas/Spark に読み取ります。 フォルダーに格納されている非構造化データ (画像、テキスト、オーディオなど) を読み取ります。 |
| Table データ テーブルを参照する |
mltable |
頻繁に変更される複雑なスキーマがあるか、大きな表形式データのサブセットが必要です。 テーブルを使用した AutoML。 複数の保存場所にまたがって存在する非構造化データ (画像、テキスト、オーディオなど) を読み取ります。 |
Note
csv ファイルに埋め込まれた改行は、データを MLTable として登録する場合にのみ使用します。 csv ファイルに改行が埋め込まれている場合、データを読み取る際にフィールド値がずれる可能性があります。 MLTable には read_delimited 変換で使用できる support_multi_line パラメーターがあり、引用符で囲まれた改行を 1 つのレコードとして解釈します。
Azure Machine Learning ジョブでデータ資産を取り込んで使用する際は、資産を "マウント" するか、コンピューティング ノードに "ダウンロード" できます。 詳細については、「モデル」を参照してください。
また、データ資産の場所を指す path パラメーターを指定する必要があります。 サポートされているパスは次のとおりです。
| Location | 例 |
|---|---|
| ローカル コンピューター上のパス | ./home/username/data/my_data |
| データストア上のパス | azureml://datastores/<data_store_name>/paths/<path> |
| パブリック HTTP(S) サーバー上のパス | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Azure Storage 上のパス | (BLOB) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Note
ローカル パスからデータ資産を作成すると、既定の Azure Machine Learning クラウド データストアに自動的にアップロードされます。
データ資産を作成する: ファイル タイプ
ファイル (uri_file) タイプのデータ資産は、ストレージ上の 1 つのファイル (CSV ファイルなど) を指します。 ファイル タイプのデータ資産は、以下のようにして作成できます。
YAML ファイルを作成し、次のコード スニペットをコピーして貼り付けます。 <> プレースホルダーは以下の情報に置き換えてください。
- データ資産の名前
- バージョン
- description
- サポートされている場所の 1 つのファイルへのパス
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
次に、CLI で次のコマンドを実行します。 <filename> プレースホルダーは YAML ファイル名に置き換えてください。
az ml data create -f <filename>.yml
![スクリーンショットでは [データ資産] タブの [作成] が強調されています。](media/how-to-create-data-assets/data-assets-create.png?view=azureml-api-2)
![このスクリーンショットでは、[種類] ドロップダウンで [File (uri folder)] (ファイル (uri フォルダー)) を選びます。](media/how-to-create-data-assets/create-data-asset-file-type.png?view=azureml-api-2)
データ資産を作成する: フォルダー タイプ
フォルダー (uri_folder) タイプのデータ資産は、ストレージ リソース上のフォルダー (画像のサブフォルダーを複数格納するフォルダーなど) を指します。 フォルダー タイプのデータ資産は、以下のようにして作成できます。
次のコードをコピーして新しい YAML ファイルに貼り付けます。 <> プレースホルダーは以下の情報に置き換えてください。
- データ資産の名前
- バージョン
- 説明
- サポートされている場所のフォルダーへのパス
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
次に、CLI で次のコマンドを実行します。 <filename> プレースホルダーは YAML ファイル名に置き換えてください。
az ml data create -f <filename>.yml
![このスクリーンショットでは、[種類] ドロップダウンで [Folder (uri_folder)] (フォルダー (uri_folder)) を選びます。](media/how-to-create-data-assets/create-data-asset-folder-type.png?view=azureml-api-2)
データ資産を作成する: テーブル タイプ
Azure Machine Learning テーブル (MLTable) には豊富な機能があります。詳細については、「Azure Machine Learning でのテーブルの操作」で説明しています。 ここではそのドキュメントに記載されている情報については省略し、一般提供されている Azure Blob Storage アカウント上の Titanic データを使用して、テーブル タイプのデータ資産を作成する方法を説明する例を紹介します。
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
まず、data という名前の新しいディレクトリを作成し、MLTable という名前のファイルを作成します。
mkdir data
touch MLTable
次に、以下の YAML をコピーして、前の手順で作成した MLTable ファイルに貼り付けます。
注意事項
MLTable ファイルの名前を MLTable.yaml や MLTable.yml に変更しないでください。 Azure Machine Learning では、MLTable ファイルが必要です。
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
CLI で次のコマンドを実行します。 <> プレースホルダーはデータ資産名とバージョンの値に置き換えてください。
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
重要
path は、有効な MLTable ファイルを含む ''フォルダー'' である必要があります。
ジョブ出力からのデータ資産の作成
Azure Machine Learning ジョブからデータ資産を作成できます。 これを行うには、出力で name パラメーターを設定します。 この例では、パブリック BLOB ストアから既定の Azure Machine Learning データストアにデータをコピーし、job_output_titanic_asset というデータ資産を作成するジョブを送信します。
- Azure CLI
- Python SDK
-
[ スタジオ](#tab/azure-studio)
ジョブ仕様 YAML ファイル (<file-name>.yml) を作成します:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
次に、CLI を使用してジョブを送信します:
az ml job create --file <file-name>.yml
データ資産の管理
データ資産を削除する
重要
"仕様上"、データ資産の削除はサポートされません。
仮に Azure Machine Learning でデータ資産の削除が許可されている場合、次のような悪影響が生じます。
- 後で削除されたデータ資産を使用する実稼働ジョブが失敗します。
- ML 実験を再現することが難しくなります。
- 削除されたデータ資産のバージョンを確認できなくなるため、ジョブのデータ系列が破綻します。
- バージョンが見つからない場合があるため、正しく追跡および監査することができません。
このように、チームで協働して運用環境のワークロードを作成する際、データ資産の不変性によって一定の保護が確保されています。
データ資産が正しく作成されなかった場合 (名前、種類、パスが正しくないなど) でも、Azure Machine Learning には、削除による悪影響を受けずに状況に対処するためのソリューションがあります。
| "データ資産の削除を希望する理由" | 解決策 |
|---|---|
| 名前が正しくない | データ資産をアーカイブする |
| データ資産がチームに不要になった | データ資産をアーカイブする |
| データ資産が増えて困っている | データ資産をアーカイブする |
| パスが正しくない | 正しいパスを使用して、"新しいバージョン" のデータ資産を (同じ名前で) 作成します。 詳細については、「データ資産を作成する」を参照してください。 |
| 種類が正しくない | 現時点の Azure Machine Learning では、最初のバージョンと比較して種類の異なる新しいバージョンを作成することはできません。 (1) データ資産をアーカイブする (2) 別の名前で正しい種類のデータ資産を新たに作成します。 |
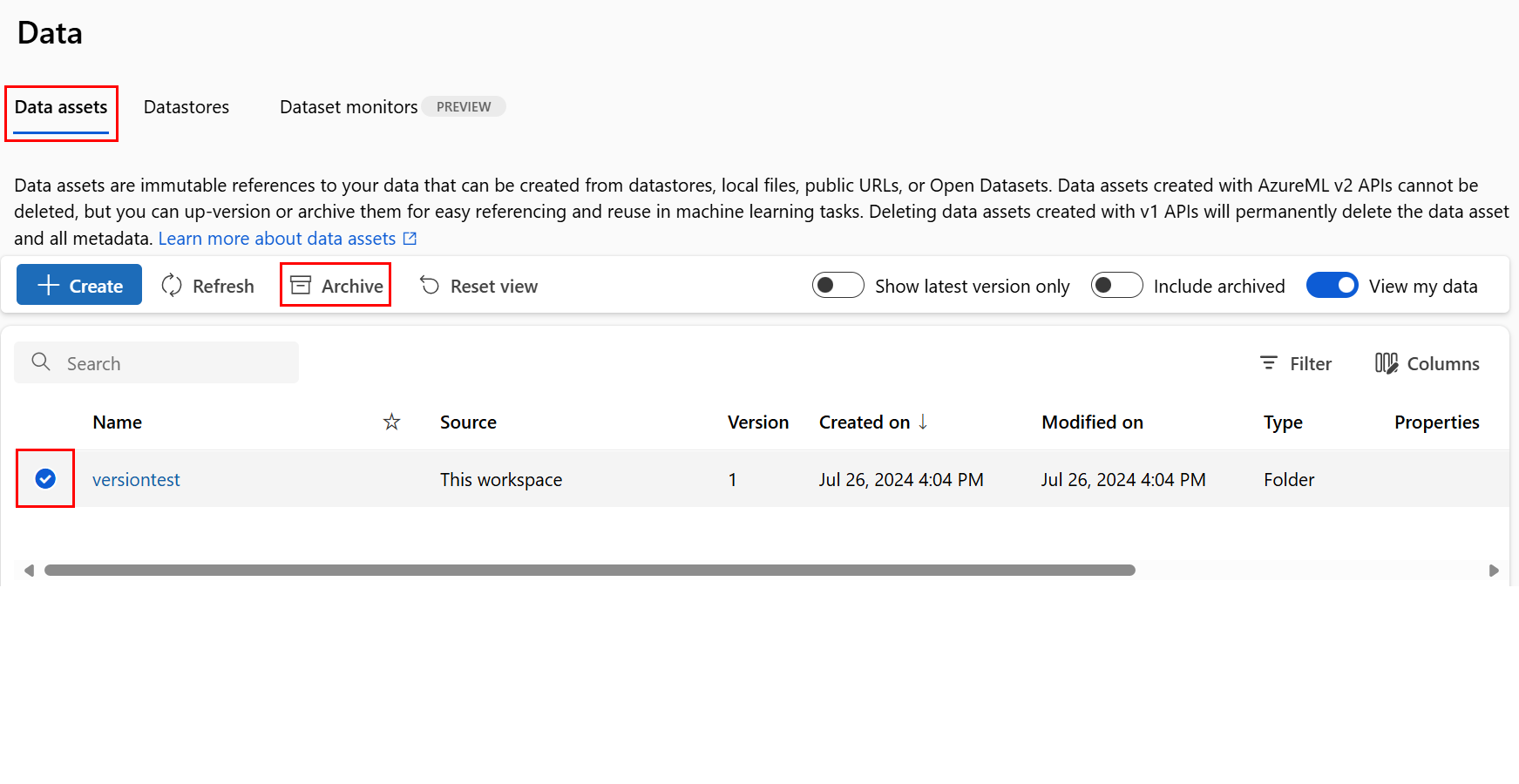
データ資産をアーカイブする
データ資産をアーカイブすると、両方のリスト クエリ (CLI の az ml data listなど) やスタジオ UI のデータ資産一覧から既定で非表示になります。 アーカイブされたデータ資産は、引き続きワークフローから参照し、使用することができます。 次のいずれかをアーカイブできます。
- 特定の名前の全バージョンのデータ資産
または
- 特定のバージョンのデータ資産
特定のデータ資産の全バージョンをアーカイブする
特定の名前のデータ資産の "全バージョン" をアーカイブするには、次のようにします。
次のコマンドを実行します。 <> プレースホルダーは実際の情報に置き換えてください。
az ml data archive --name <NAME OF DATA ASSET>
特定のバージョンのデータ資産をアーカイブする
特定のバージョンのデータ資産をアーカイブするには、次のようにします。
次のコマンドを実行します。 <> プレースホルダーは、データ資産の名前とバージョンに置き換えてください。
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
アーカイブされたデータ資産を復元する
アーカイブされたデータ資産は復元することができます。 データ資産の全バージョンがアーカイブされている場合、データ資産のバージョンを個別に復元することはできません。すべてのバージョンを復元する必要があります。
特定のデータ資産の全バージョンを復元する
特定の名前のデータ資産の "全バージョン" を復元するには、次のようにします。
次のコマンドを実行します。 <> プレースホルダーはデータ資産の名前に置き換えてください。
az ml data restore --name <NAME OF DATA ASSET>
![[アーカイブ済みを含める] が選択された画面のスクリーンショット。](media/how-to-create-data-assets/data-asset-restore-incarc.png?view=azureml-api-2)
![[復元] が選択された画面のスクリーンショット。](media/how-to-create-data-assets/data-asset-restore.png?view=azureml-api-2)
特定のバージョンのデータ資産を復元する
重要
データ資産の全バージョンがアーカイブされている場合、データ資産のバージョンを個別に復元することはできません。すべてのバージョンを復元する必要があります。
特定のバージョンのデータ資産を復元するには、次のようにします。
次のコマンドを実行します。 <> プレースホルダーは、データ資産の名前とバージョンに置き換えてください。
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
データ系列
データ系列は、データの起源から始まり、時間の経過と共にストレージ上を移動するライフサイクルとして広く認識されています。 以下のような、さまざまな種類の回顧的なシナリオで使用されます。
- トラブルシューティング
- ML パイプラインでの根本原因のトレース
- デバッグ
また、データ系列は、データ品質分析、コンプライアンス、"What-If" シナリオにも使用されます。 系列は、移動元から移動先へのデータを表示するために視覚的に表現され、さらにデータの変換方法も示します。 ほとんどのエンタープライズ データ環境は複雑であるため、これらのビューは、周辺機器データ ポイントの統合やマスキングを行わないと理解しづらくなる場合があります。
Azure Machine Learning パイプラインでは、データの起源とその処理方法がデータ資産からわかります。以下はその例です。
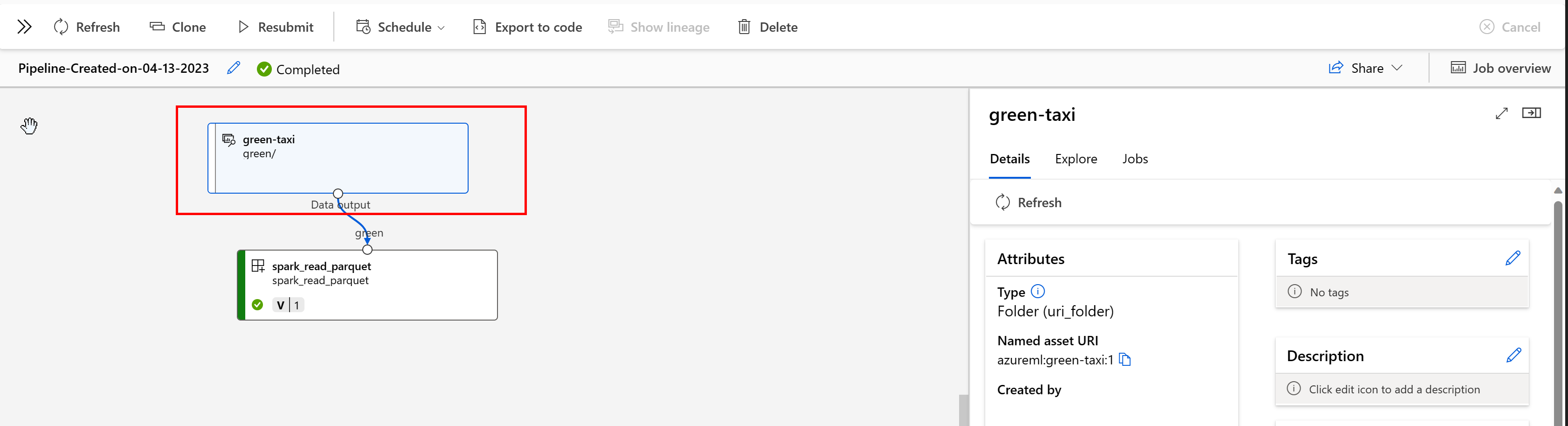
データ資産を取り込んで使用するジョブをスタジオ UI で表示できます。 まず、左側のメニューから [データ] を選択し、データ資産の名前を選択します。 データ資産を使用しているジョブに注目してください。
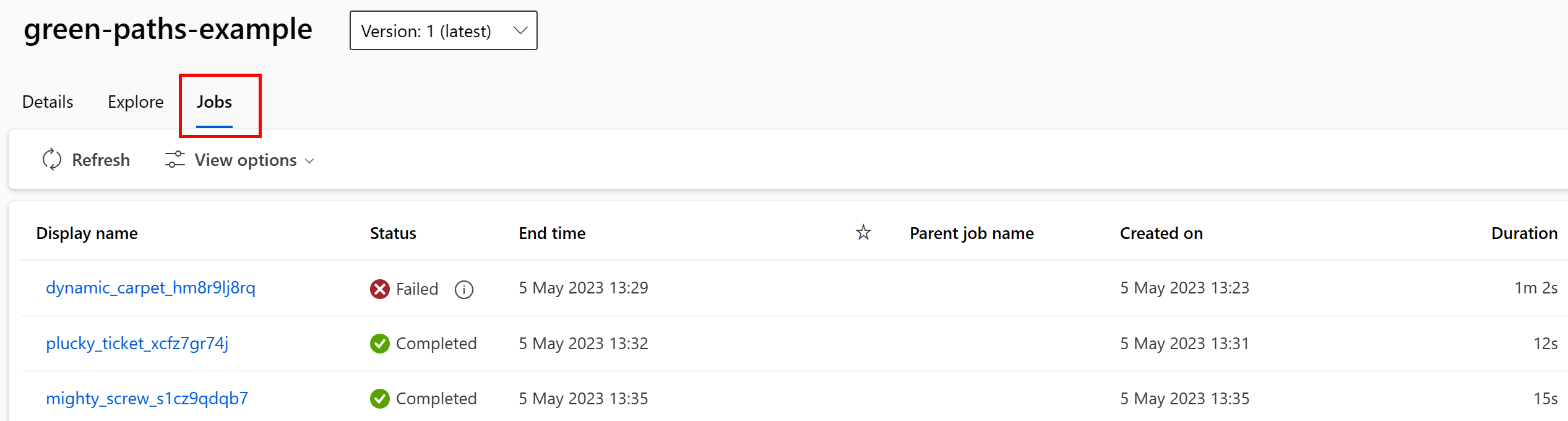
ジョブの失敗を見つけたり ML パイプラインやデバッグで根本原因分析を行ったりする作業は、データ資産のジョブ ビューで容易に行うことができます。
データ資産のタグ付け
データ資産ではタグ付けがサポートされています。タグは追加のメタデータで、キーと値のペアとしてデータ資産に適用されます。 データのタグ付けには次のような多くの利点があります。
- データの品質に関する説明。 たとえば、組織で "メダリオン レイクハウス アーキテクチャ" を使っている場合、
medallion:bronze(未処理)、medallion:silver(検証済み)、medallion:gold(エンリッチ済み) で資産にタグを付けることができます。 - データの効率的な検索とフィルター処理により、データを検出しやすくする。
- 機密性の高い個人データを特定し、データへのアクセスを適切に管理、統制できるようにする。 たとえば、
sensitivity:PII/sensitivity:nonPIIのようにします。 - 責任ある AI (RAI) 監査によってデータが承認されているかどうかを判断する。 たとえば、
RAI_audit:approved/RAI_audit:todoのようにします。
データ資産の作成フローの過程でタグを追加することも、既存のデータ資産にタグを追加することもできます。 このセクションでは、その両方について説明します。
データ資産作成フローの過程でタグを追加する
YAML ファイルを作成し、次のコードをコピーしてその YAML ファイルに貼り付けます。 <> プレースホルダーは以下の情報に置き換えてください。
- データ資産の名前
- バージョン
- description
- タグ (キーと値のペア)
- サポートされている場所の 1 つのファイルへのパス
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
CLI で次のコマンドを実行します。 <filename> プレースホルダーは YAML ファイル名に置き換えてください。
az ml data create -f <filename>.yml
既存のデータ資産にタグを追加する
Azure CLI で次のコマンドを実行します。 <> プレースホルダーは以下の情報に置き換えてください。
- データ資産の名前
- バージョン
- タグのキーと値のペア
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

バージョン管理のベスト プラクティス
通常、ETL プロセスでは、Azure Storage 上のフォルダー構造が時間別に整理されています。次に例を示します。
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
時間とバージョンで構造化されたフォルダーおよび Azure Machine Learning テーブル (MLTable) の組み合わせによって、バージョン管理されたデータセットの作成が可能になります。 Azure Machine Learning テーブルでデータのバージョン管理を実現する方法を仮定の例で示します。 毎週、次の構造でカメラの画像を Azure Blob Storage にアップロードするプロセスがあるとします。
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Note
画像 (jpeg) データをバージョン管理する方法を示していますが、どのファイルの種類 (Parquet、CSV など) でも同じ方法が機能します。
Azure Machine Learning テーブル (mltable) を使用して、2023 年の最初の週の終わりまでのデータを含むパスのテーブルを作成します。 次に、データ資産を作成します。
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
翌週の終わりには、ETL によってデータが更新され、さらに多くのデータが追加されています。
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
最初のバージョン (20230108) では、パスが MLTable ファイル内で宣言されているため、year=2022/week=52 と year=2023/week=1 のファイルのマウントとダウンロードのみが続行されます。 これによって実験の "再現性" が確保されています。 year=2023/week2 を含む新しいバージョンのデータ資産を作成するには、次のコードを使用します。
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
これで 2 つのバージョンのデータが作成されました。バージョンの名前は、画像がストレージにアップロードされた日付に対応しています。
- 20230108: 2023 年 1 月 8 日までの画像。
- 20230115: 2023 年 1 月 15 日までの画像。
どちらの場合も、各日付までの画像のみを含むパスのテーブルが MLTable によって構築されます。
Azure Machine Learning ジョブでは、eval_download または eval_mount モードを使用して、バージョン管理された MLTable 内のパスをマウントしたりコンピューティング先にダウンロードしたりすることができます。
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
注意
eval_mountモードと eval_download モードは MLTable に固有です。 この場合、AzureML データ ランタイム機能によって MLTable ファイルが評価され、コンピューティング先でパスがマウントされます。