Azure Machine Learning スタジオでコンポーネントを使用して機械学習パイプラインを作成して実行する
適用対象:  Azure CLI ml 拡張機能 v2 (現行)
Azure CLI ml 拡張機能 v2 (現行)
この記事では、Azure Machine Learning スタジオとコンポーネントを使用して、機械学習パイプラインを作成して実行する方法について説明します。 コンポーネントを使用せずにパイプラインを作成することはできますが、コンポーネントによって柔軟性と再利用性が向上します。 Azure Machine Learning パイプラインは、YAML に定義して CLI から実行したり、Python で作成したり、ドラッグアンドドロップ UI を使って Azure Machine Learning スタジオ デザイナーで作成したりできます。 このドキュメントでは、Azure Machine Learning スタジオ デザイナーの UI に焦点を当てています。
前提条件
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning をお試しください。
Azure Machine Learning ワークスペース。ワークスペース リソースを作成します。
examples リポジトリをクローンします。
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
Note
デザイナーは、従来の事前構築済みコンポーネント (v1) とカスタム コンポーネント (v2) の 2 種類のコンポーネントをサポートします。 これら 2 種類のコンポーネントには互換性がありません。
従来の事前構築済みコンポーネントは、主にデータ処理や、回帰や分類などの従来の機械学習タスク向けの事前構築済みのコンポーネントを提供します。 従来の事前構築済みコンポーネントは引き続きサポートされますが、新しいコンポーネントは追加されません。 また、従来の事前構築済み (v1) コンポーネントのデプロイでは、マネージド オンライン エンドポイント (v2) はサポートされません。
カスタム コンポーネントを使用すると、独自のコードをコンポーネントとしてラップすることができます。 これは、ワークスペース間での共有と、Studio、CLI v2、SDK v2 インターフェイス間でのシームレスな作成をサポートします。
新しいプロジェクトでは、AzureML V2 と互換性があり、新しく更新され続けるカスタム コンポーネントを使用することを強くお勧めします。
この記事は、カスタム コンポーネントに適用されます。
ワークスペースにコンポーネントを登録する
UI のコンポーネントを使用してパイプラインを構築するには、まずコンポーネントをワークスペースに登録する必要があります。 UI、CLI、または SDK を使用してコンポーネントをワークスペースに登録し、ワークスペース内でコンポーネントを共有および再利用できるようにします。 登録済みコンポーネントは自動バージョン管理に対応しており、コンポーネントを更新できる一方、古いバージョンを必要とするパイプラインの動作も引き続き維持されます。
次の例では、UI を使用してコンポーネントを登録します。コンポーネントのソース ファイルは azureml-examples リポジトリの cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components ディレクトリにあります。 最初にリポジトリをローカルにクローンする必要があります。
- Azure Machine Learning ワークスペースで、[コンポーネント] ページに移動し、[新しいコンポーネント] を選択します (2 つのスタイル ページのいずれかが表示されます)。
![[コンポーネント] ページの登録エントリ ボタンを示すスクリーンショット。](media/how-to-create-component-pipelines-ui/register-component-entry-button-2.png?view=azureml-api-2#lightbox)
![アーカイブを含めることができる [コンポーネント] ページの登録エントリ ボタンを示すスクリーンショット。](media/how-to-create-component-pipelines-ui/register-component-entry-button.png?view=azureml-api-2#lightbox)
この例では、ディレクトリ内の train.yml を使用します。 この YAML ファイルでは、このコンポーネントの名前、種類、インターフェイス (入力と出力、コード、環境、コマンドをなど) を定義します。 このコンポーネントの train.py のコードは ./train_src フォルダーの下にあり、このコンポーネントの実行ロジックを記述しています。 コンポーネントのスキーマの詳細については、コマンド コンポーネントの YAML スキーマのリファレンスを参照してください。
注意
UI でコンポーネントを登録する際は、コンポーネントの YAML ファイルに定義されている code は、YAML ファイルがある現在のフォルダーまたはサブフォルダーのみをポイントできます。つまり、UI で親ディレクトリを認識できないため、code には ../ を指定できません。
additional_includes でポイントできるのは、現在のフォルダーまたはサブフォルダーのみです。
現在、UI では、command 型のコンポーネントの登録のみがサポートされています。
- [フォルダー] からのアップロード を選択し、アップロードする
1b_e2e_registered_componentsフォルダーを選択します。 ドロップダウン リストからtrain.ymlを選択します。

下部にある [次へ] を選択すると、このコンポーネントの詳細を確認できます。 確認したら、[作成] を選択して登録プロセスを完了します。
前の手順を繰り返し、
score.ymlとeval.ymlを使用して Score および Eval コンポーネントも登録します。3 つのコンポーネントを正常に登録したら、スタジオ UI でコンポーネントを確認できます。

登録済みコンポーネントを使用してパイプラインを作成する
デザイナーで新しいパイプラインを作成します。 [カスタム] オプションを必ず選択してください。

自動生成された名前の横にある鉛筆アイコンを選択し、パイプラインにわかりやすい名前を付けます。
デザイナー アセット ライブラリに、[データ]、[モデル]、[コンポーネント] のタブが表示されます。 [コンポーネント] タブに切り替えると、前のセクションで登録したコンポーネントを確認できます。 コンポーネントが多すぎて見つからない場合は、コンポーネント名で検索できます。
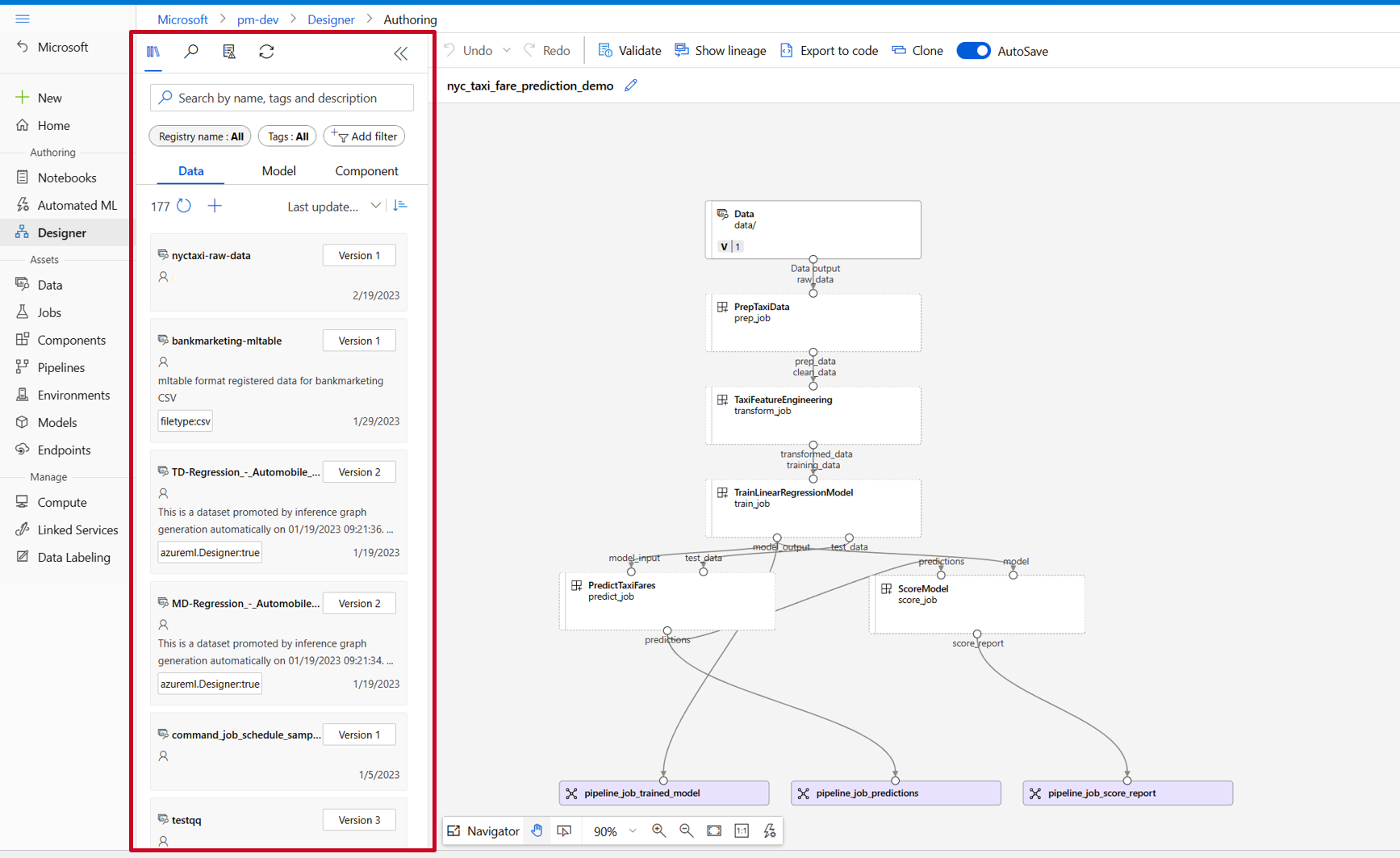
前のセクションで登録した train、score、eval の各コンポーネントを見つけ、キャンバスにドラッグ アンド ドロップします。 既定では、コンポーネントの既定バージョンが使用されますが、コンポーネントの右側のペインで特定のバージョンに変更できます。 コンポーネントの右ペインは、コンポーネントをダブルクリックすると表示されます。

この例では、このパスの下にあるサンプル データを使用します。 ワークスペースにデータを登録するには、デザイナー アセット ライブラリの > [データ] タブで、[追加] アイコンを選択します。Type = Folder(uri_folder) を設定した後、ウィザードに従ってデータを登録します。 データ型は、train コンポーネントの定義に合わせて uri_folder にする必要があります。

次に、データをキャンバスにドラッグ アンド ドロップします。 パイプライン全体の表示は次のスクリーンショットのようになります。
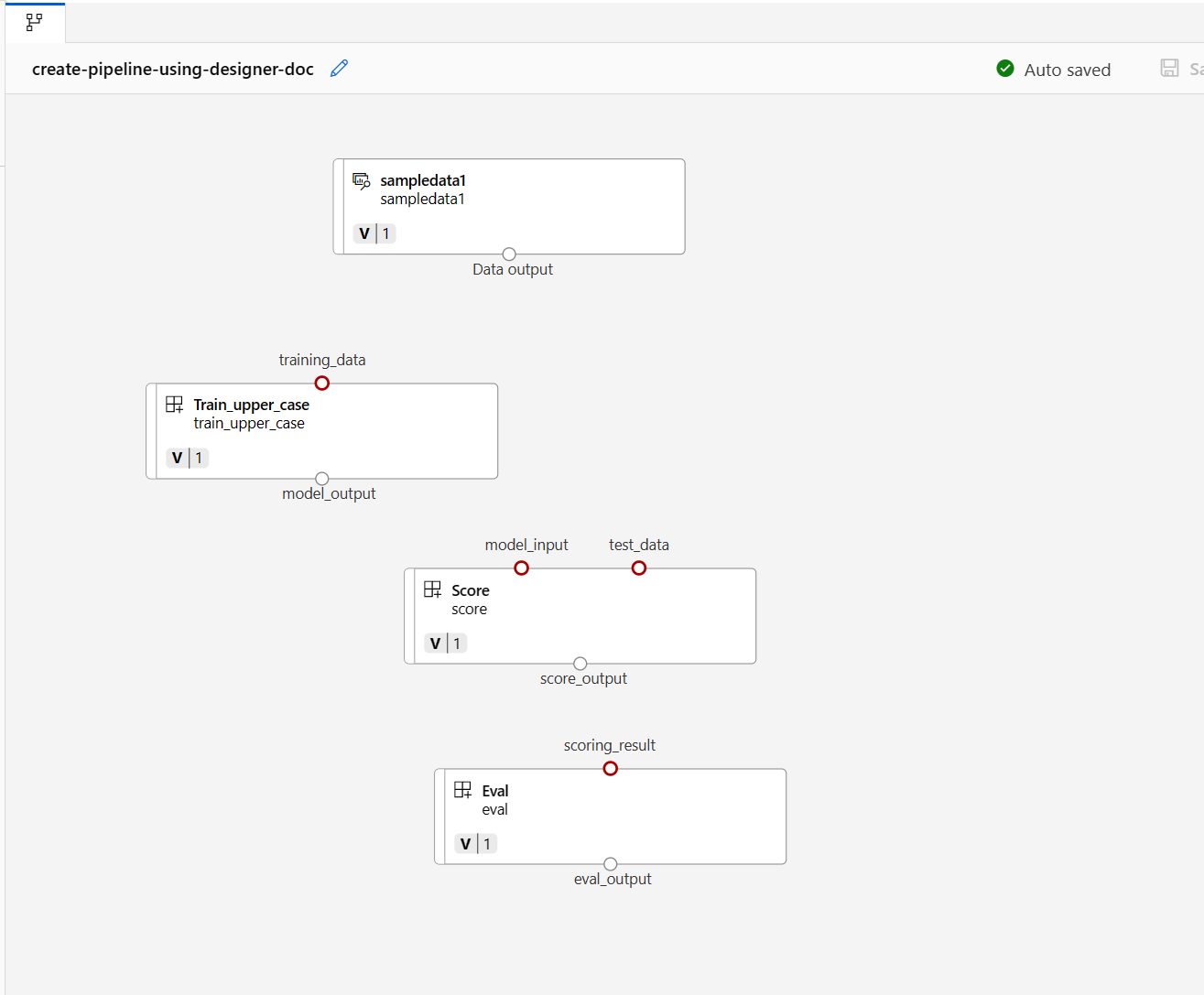
キャンバス内で、接続をドラッグし、データとコンポーネントの間を接続します。

コンポーネントの 1 つをダブルクリックすると、そのコンポーネントの構成操作を行う右側のペインが表示されます。
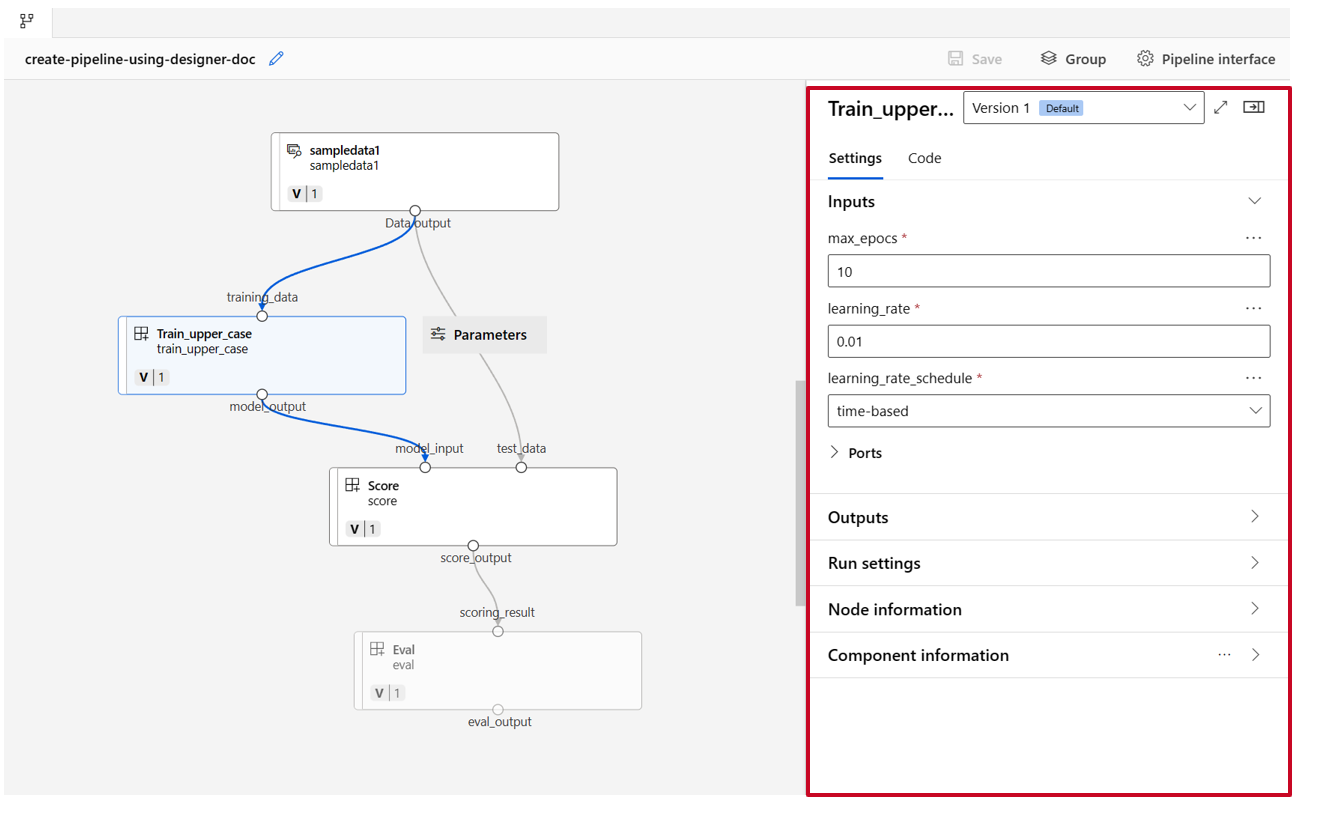
数値、整数、文字列、ブールなどのプリミティブ型の入力を持つコンポーネントの場合は、コンポーネントの詳細ペインの [入力] セクションで、そのような入力値を変更できます。
また、出力設定 (コンポーネントの出力を格納する場所) と実行設定 (コンポーネントを実行するコンピューティング先) も右側のペインで変更できます。
次に、train コンポーネントの max_epocs 入力をパイプライン レベルの入力に昇格させます。 そうすると、毎回異なる値をこの入力に割り当ててからパイプラインを送信できるようになります。










注意
カスタム コンポーネントとデザイナーの従来の事前構築済みコンポーネントを一緒に使用することはできません。
パイプラインを送信する
右上隅の [構成と送信] を選択して、パイプラインを送信します。
![[構成と送信] ボタンを示すスクリーンショット。](media/how-to-create-component-pipelines-ui/configure-submit.png?view=azureml-api-2)
詳細な手順を案内するウィザードが表示されます。ウィザードに従ってパイプライン ジョブを送信します。

[基本] ステップでは、実験、ジョブの表示名、ジョブの説明などを構成できます。
[入力と出力] ステップでは、パイプライン レベルに昇格させた入出力を構成できます。 前の手順で train コンポーネントの max_epocs をパイプライン入力に昇格させたので、ここでは、max_epocs の値の確認と割り当てができます。
[ランタイムの設定] では、パイプラインの既定のデータストアと既定のコンピューティングを構成できます。 これは、パイプライン内のすべてのコンポーネントに適用される既定のデータストアとコンピューティングです。 ただし、個別のコンポーネントに対して異なるコンピューティングまたはデータストアを明示的に設定した場合は、そのコンポーネント レベルの設定が優先されます。 それ以外の場合はパイプラインの既定値が使用されます。
[レビュー + 送信] ステップは、送信する前にすべての構成を確認するための最後のステップです。 このパイプラインを既に送信したことがある場合は、前回の構成がウィザードに記憶されています。
パイプライン ジョブを送信すると、ジョブの詳細情報のリンクを記載したメッセージが上部に表示されます。 このリンクを選択して、ジョブの詳細を確認できます。

パイプライン ジョブで ID を指定する
パイプライン ジョブを送信するときに、[Run settings] でデータにアクセスする ID を指定できます。 既定の ID は AMLToken であり、ID を使っていませんでしたが、UserIdentity と Managed の両方をサポートしています。 UserIdentity の場合、ジョブ送信者の ID を使って入力データにアクセスし、結果を出力フォルダーに書き込みます。 Managed を指定すると、システムはマネージド ID を使って入力データにアクセスし、結果を出力フォルダーに書き込みます。

次のステップ
- GitHub 上のこれらの Jupyter notebook を使用して、機械学習パイプラインをさらに調べます
- CLI v2 を使用して、コンポーネントを使用するパイプラインを作成する方法について確認します。
- SDK v2 を使用して、コンポーネントを使用するパイプラインを作成する方法について確認します