R スクリプトの実行コンポーネント
この記事では、R スクリプトの実行コンポーネントを使用して、Azure Machine Learning デザイナー パイプラインで R コードを実行する方法について説明します。
R を使用すると、既存のコンポーネントではサポートされていない次のようなタスクを実行できます。
- カスタム データ変換を作成する
- 独自のメトリックを使用して予測を評価する
- デザイナーでスタンドアロン コンポーネントとして実装されていないアルゴリズムを使用してモデルをビルドする
R バージョンのサポート
Azure Machine Learning デザイナーでは、R の CRAN (包括的な R アーカイブ ネットワーク) ディストリビューションが使用されます。現在使用されているバージョンは CRAN 3.5.1 です。
サポートされる R パッケージ
100 以上のパッケージを含む R 環境がプレインストールされています。 完全な一覧については、「プレインストールされている R パッケージ」セクションを参照してください。
また、次のコードを任意の R スクリプトの実行コンポーネントに追加して、インストールされているパッケージを表示することもできます。
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
注意
プレインストール一覧に含まれていないパッケージを必要とする R スクリプトの実行コンポーネントがパイプラインに複数含まれている場合は、それぞれのコンポーネントにそれらのパッケージをインストールしてください。
R パッケージのインストール
追加の R パッケージをインストールするには、install.packages() メソッドを使用します。 パッケージは、R スクリプトの実行コンポーネントごとにインストールされます。 それらは他の R スクリプトの実行コンポーネント間で共有されません。
注意
スクリプト バンドルから R パッケージをインストールすることは推奨されていません。 スクリプト エディターで直接、パッケージをインストールすることをお勧めします。
install.packages("zoo",repos = "https://cloud.r-project.org") などのパッケージをインストールするときは、CRAN リポジトリを指定します。
警告
R スクリプトの実行コンポーネントでは、JAVA を必要とする qdap パッケージや、C++ を必要とする drc パッケージなど、ネイティブ コンパイルを必要とするパッケージのインストールはサポートしていません。 これは、このコンポーネントが、管理者以外のアクセス許可でプレインストールされた環境で実行されるためです。
デザイナー コンポーネントは Ubuntu で実行されるため、Windows で事前構築されている、または Windows 用のパッケージはインストールしないでください。 パッケージが Windows で事前構築されているかを確認するには、CRAN に移動し、自分のパッケージを検索し、自分の OS に合わせてバイナリ ファイルを 1 つダウンロードし、DESCRIPTION ファイルの Built: 部分を確認します。 たとえば次のようになります。
このサンプルは、Zoo のインストール方法を示しています。
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
注意
パッケージをインストールする前に、パッケージが既に存在するかどうかを確認して、インストールを繰り返さないようにします。 インストールを繰り返すと、Web サービス要求がタイムアウトする可能性があります。
登録済みデータセットへのアクセス
ワークスペースに登録されているデータセットにアクセスするには、次のサンプル コードを参照してください。
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
R スクリプトの実行を構成する方法
R スクリプトの実行コンポーネントには、出発点として利用できるサンプル コードが含まれています。
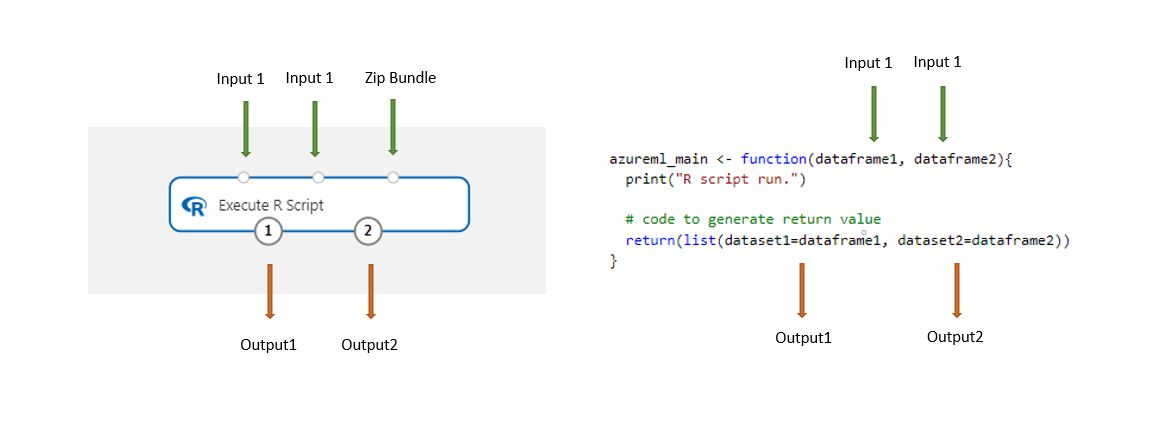
デザイナーに保存されたデータセットは、このコンポーネントで読み込まれると自動的に R データ フレームに変換されます。
R スクリプトの実行コンポーネントをパイプラインに追加します。
スクリプトに必要なすべての入力を接続します。 入力は、任意指定であり、データと追加の R コードを含めることができます。
Dataset1:
dataframe1として 1 番目の入力を参照します。 入力データセットは、CSV、TSV、または ARFF ファイル形式にする必要があります。 または、Azure Machine Learning データセットを接続することもできます。Dataset2:
dataframe2として 2 番目の入力を参照します。 このデータセットも、CSV、TSV、ARFF ファイル形式、または Azure Machine Learning データセット形式にする必要があります。スクリプト バンドル:3 つ目の入力には、.zip ファイルを指定できます。 ZIP ファイルには、複数のファイルと複数のファイルの種類を含めることができます。
[R script](R スクリプト) テキストボックスに、有効な R スクリプトを入力するか貼り付けます。
注意
スクリプトを記述するときは注意が必要です。 宣言されていない変数やインポートされていないコンポーネントまたは関数の使用など、構文エラーがないことを確認してください。 この記事の最後に記載したプレインストールされているパッケージの一覧には特に注意してください。 一覧に記載されていないパッケージを使用するには、スクリプトでインストールします。 たとえば
install.packages("zoo",repos = "https://cloud.r-project.org")です。作業を支援するために、 [R Script](R スクリプト) テキスト ボックスにはサンプル コードが事前に入力されており、編集または置換することができます。
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }Param<dataframe1>とParam<dataframe2>の入力引数が関数で使用されていない場合でも、エントリ ポイント関数にはこれらの引数が必要です。注意
R スクリプトの実行コンポーネントに渡されるデータは、
dataframe1およびdataframe2として参照されます。これは、Azure Machine Learning デザイナーとは異なります (デザイナーでは、dataset1、dataset2として参照されます)。 スクリプトで入力データが正しく参照されていることを確認します。注意
既存の R コードは、デザイナー パイプラインで実行するために、多少の変更が必要な場合があります。 たとえば、CSV 形式で指定した入力データは、コードで使用する前に、データセットに明示的に変換する必要があります。 また、R 言語で使用されるデータ型および列型は、デザイナーで使用されるデータ型および列型とはいくつかの点で異なります。
スクリプトが 16 KB を超える場合は、スクリプト バンドル ポートを使用すると、 [CommandLine exceeds the limit of 16597 characters] (CommandLine が上限の 16,597 文字を超えています) などのエラーを回避できます。
- スクリプトとその他のカスタム リソースを zip ファイルにバンドルます。
- この zip ファイルを [ファイル データセット] として Studio にアップロードします。
- [デザイナー作成] ページの左側のコンポーネント ペインにある [データセット] の一覧から、データセット コンポーネントをドラッグします。
- データセット コンポーネントを R スクリプトの実行コンポーネントのスクリプト バンドル ポートに接続します。
スクリプト バンドルでスクリプトを使用するサンプル コードを次に示します。
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }[Random Seed](ランダム シード) には、ランダム シード値として R 環境内で使用する値を入力します。 このパラメーターは、R コードで
set.seed(value)を呼び出すのと同じです。パイプラインを送信します。
結果
R スクリプトの実行コンポーネントからは複数の出力を返すことができますが、それらは R データ フレームとして提供する必要があります。 デザイナーでは、他のコンポーネントとの互換性を保つために、データ フレームがデータセットに自動的に変換されます。
R からの標準メッセージとエラーはコンポーネントのログに返されます。
R スクリプトで結果を出力する必要がある場合は、コンポーネントの右側のパネルにある [Outputs+logs](出力とログ) タブの下にある 70_driver_log で出力された結果を確認できます。
サンプルのスクリプト
カスタム R スクリプトを使用してパイプラインを拡張する方法は多数あります。 このセクションでは、一般的なタスクのためのサンプル コードを示します。
入力として R スクリプトを追加する
R スクリプトの実行コンポーネントは、入力として任意の R スクリプト ファイルをサポートします。 それらを使用するには、.zip ファイルの一部としてワークスペースにアップロードする必要があります。
R コードを含む .zip ファイルをワークスペースにアップロードするには、 [データセット] 資産ページに移動します。 [データセットの作成] を選択し、 [ローカル ファイルから] と [ファイル] のデータセットの種類オプションを選択します。
左側のコンポーネント ツリーで、 [データセット] カテゴリの [My Datasets](マイ データセット) に ZIP ファイルが表示されていることを確認します。
そのデータセットをスクリプト バンドル入力ポートに接続します。
.zip ファイル内のすべてのファイルは、パイプラインの実行時に使用できます。
スクリプト バンドル ファイルにディレクトリ構造が含まれる場合、その構造が保持されます。 ただし、コードを変更して、ディレクトリ ./Script Bundle をパスの先頭に追加する必要があります。
データを処理する
次の例は、入力データをスケーリングおよび正規化する方法を示しています。
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
入力として .zip ファイルを読み取る
この例は、R スクリプトの実行コンポーネントへの入力として .zip ファイル内のデータセットを使用する方法を示しています。
- CSV 形式でデータ ファイルを作成し、「mydatafile.csv」という名前を付けます。
- .zip ファイルを作成し、CSV ファイルをアーカイブに追加します。
- ZIP ファイルを Azure Machine Learning ワークスペースにアップロードします。
- 結果として得られるデータセットを、R スクリプトの実行コンポーネントの ScriptBundle 入力に接続します。
- ZIP ファイルから CSV データを読み取るには、次のコードを使用します。
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
行をレプリケートする
このサンプルは、サンプルのバランスを調整するために、データセット内のポジティブ レコードをレプリケートする方法を示しています。
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
R スクリプトの実行コンポーネント間で R オブジェクトを渡す
内部のシリアル化メカニズムを使用することで、R スクリプトの実行コンポーネントのインスタンス間で R オブジェクトを渡すことができます。 この例は、2 つの R スクリプトの実行コンポーネント間で A という名前の R オブジェクトを移動することを想定しています。
最初の R スクリプトの実行コンポーネントをパイプラインに追加します。 次に [R スクリプト] テキスト ボックスに次のコードを入力し、コンポーネントの出力データ テーブルの列としてシリアル化されたオブジェクト
Aを作成します。azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }シリアル化関数からはデータが R
Raw形式で出力されますが、これはデザイナーではサポートされていないため、整数型への明示的な変換が行われます。R スクリプトの実行コンポーネントの 2 番目のインスタンスを追加し、それを前のコンポーネントの出力ポートに接続します。
[R Script](R スクリプト) テキスト ボックスに次のコードを入力して、入力データ テーブルからオブジェクト
Aを抽出します。azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
プレインストールされている R パッケージ
現在、次のプレインストールされた R パッケージを使用できます。
| Package | Version |
|---|---|
| askpass | 1.1 |
| assertthat | 0.2.1 |
| backports | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| boot | 1.3-22 |
| broom | 0.5.2 |
| callr | 3.2.0 |
| caret | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| class | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| cluster | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| compiler | 3.5.1 |
| crayon | 1.3.4 |
| curl | 3.3 |
| data.table | 1.12.2 |
| datasets | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| evaluate | 0.14 |
| fansi | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| foreign | 0.8-71 |
| fs | 1.3.1 |
| gdata | 2.18.0 |
| generics | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| glue | 1.3.1 |
| gower | 0.2.1 |
| gplots | 3.0.1.1 |
| graphics | 3.5.1 |
| grDevices | 3.5.1 |
| grid | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| highr | 0.8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| iterators | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| knitr | 1.23 |
| labeling | 0.3 |
| lattice | 0.20-38 |
| lava | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| markdown | 1 |
| MASS | 7.3-51.4 |
| Matrix | 1.2-17 |
| メソッド | 3.5.1 |
| mgcv | 1.8-28 |
| mime | 0.7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| pillar | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| progress | 1.2.2 |
| ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quantmod | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| recipes | 0.1.5 |
| rematch | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| reticulate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0.1 |
| rvest | 0.3.4 |
| scales | 1.0.0 |
| selectr | 0.4-1 |
| 空間 | 7.3-11 |
| splines | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| stats4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| survival | 2.44-1.1 |
| sys | 3.2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| timeDate | 3043.102 |
| tinytex | 0.13 |
| ツール | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| utils | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| whisker | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0.8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoo | 1.8-6 |
次のステップ
Azure Machine Learning で使用できる一連のコンポーネントを参照してください。