エンドツーエンドの HPC リフト アンド シフト アーキテクチャの概要
ハイ パフォーマンス コンピューティング (HPC) のコンテキストにおける "リフト アンド シフト" とは、主にオンプレミス環境とワークロードをクラウドに移行するプロセスを指します。 変更を最小限に抑えるのが理想的です (たとえば、アプリケーション、ジョブ スケジューラ、それらの構成はほとんど変わらないようにします)。 オンプレミスとクラウド プラットフォームではリソースが異なるため、ストレージとハードウェアの調整が発生するのは当然です。 リフト アンド シフト アプローチを使用すると、組織はクラウドの恩恵をより早く受けることができます。
次の図は、運用環境の一般的なオンプレミス HPC クラスターを表しています。これは、ハードウェアの製造元がよく提供するものです。 このようなオンプレミス環境は、仮想マシンのイメージとコンテナーと連携するかどうかに関わらず、一連の計算ノードで構成されています。 このようなノードは、ジョブ スケジューラ (通常は Slurm、PBS、または LSF) によって管理されるワークロードを実行します。 ワークロードは、ID 管理が関連付けられている複数のユーザーから生じます。 通常、ホーム ディレクトリ、スクラッチ ディスク、長期ストレージがあります。 ジョブのパフォーマンスと計算ノードの正常性を確認する何らかの形式の監視も使用できます。 ユーザーは、コマンド ライン、ブラウザー、またはある種のリモート視覚化テクノロジを介して環境にアクセスできます。 環境全体がプライベート ネットワーク内でホストされているため、ユーザーには、VPN またはポータル経由でコンピューティング機能にアクセスできる何らかのメカニズムがあります。
![]()
このドキュメント全体を通して見てきたように、サービスとしてのインフラストラクチャ モデルに従うクラウド内の環境は、概念的には、それほど違いはありません。 一部のテクノロジには何らかの更新が必要であり、オンプレミスからクラウドへの移行時に必要な手順がいくつかあります。
そのため、このドキュメントでは:
- 移行プロセスのオプションを確認します。
- 各コンポーネントの製品とベスト プラクティスへのポインターを示します。
- また、プロセスの落とし穴を回避するための推奨事項を示します。
アーキテクチャの説明に進む前に、このコンテキストにおけるさまざまなペルソナ、そのニーズ、期待を理解することが重要です。
ペルソナとユーザー エクスペリエンス
HPC 環境にアクセスする必要があるさまざまなユーザーがいます。 そのアクティビティと、環境との対話方法は大きく異なります。
エンドユーザー (エンジニア/科学者/研究者)
このペルソナは、実験を実行し (つまり、ジョブを送信し)、結果を分析したいと考えている対象分野の専門家 (生物学者、物理学者、エンジニアなど) を表します。 エンドユーザーは、必要に応じてシステム管理者と対話してコンピューティング環境を微調整します。 CLI ベースのツールの使用経験があるとしても、ジョブを送信し、生成された結果を操作する際に、VDI を介して Web ポータルまたはグラフィカル ユーザー インターフェイスのみを利用する場合があります。
クラウド HPC 環境の新しい責任:
- エンドユーザーは、HPC 管理者とクラウド管理者の両方の作業に基づいて新しい責任を負うことはありません。 オンプレミス環境によっては、エンドユーザーは、より大容量でさまざまなコンピューティング リソースにアクセスして、生産性を高めることができます。
HPC 管理者
このペルソナは、HPC の専門知識を持ち、初期のコンピューティング インフラストラクチャをデプロイし、ビジネスとエンドユーザーのニーズに合わせて適応させる責任を担う人物を表します。 このペルソナは、システムの正常性を確認し、トラブルシューティングを実行する責任も担っています。 HPC 管理者は、CLI、SDK、Web ポータルを介してアーキテクチャとそのコンポーネントに簡単にアクセスできます。 また、エンドユーザーがコンピューティング環境に関する何らかの課題に直面したときの最初の問い合わせ先でもあります。
クラウド HPC 環境の新しい責任:
- クラウド管理プラットフォームを介してクラウド リソースとサービス (仮想マシン、ストレージ、ネットワークなど) を管理する。
- 新しいリソース オーケストレーション ツール (CycleCloud など) を介してクラスターとリソースを実装し、管理する。
- インフラストラクチャの詳細 (つまり、VM の種類、ストレージ、ネットワーク オプション) を理解することで、アプリケーションのデプロイを最適化する。
- 自動スケーリングやスポット インスタンスなどのクラウド固有の機能を使用して、リソースの使用率とコストを最適化する。
クラウド管理者
このペルソナは、HPC 管理者と連携して、コンピューティング インフラストラクチャのデプロイと保守を支援します。 このペルソナは (必ずしも) HPC の専門家ではありませんが、ネットワークの構成やポリシー、ユーザーのアクセス権、ユーザーのデバイスなど、会社の IT インフラストラクチャ全体について深い知識を持つクラウドの専門家です。 場合によっては、HPC 管理者とクラウド管理者が同一人物のことがあります。
クラウド HPC 環境の新しい責任:
- HPC 管理者と連携して、HPC ワークロードとクラウド インフラストラクチャのシームレスな統合を確保する。
- クラウド インフラストラクチャのパフォーマンス、セキュリティ、コンプライアンスを監視し、管理する。
- HPC ワークロードをサポートするクラウドベースのネットワークおよびストレージ ソリューションの構成を支援する。
ビジネス マネージャーと所有者
このペルソナは、組織の目標を達成できるように予算やプロジェクトを管理するなど、ビジネスの責任者を表します。 このペルソナの場合、アーキテクチャの会計コンポーネントは、各プロジェクトのコストを理解するために重要です。 このペルソナは、HPC 管理者やエンドユーザーと連携して、ストレージ、ネットワーク、コンピューティング リソースなどのプラットフォームのニーズを理解します。 また、将来のワークロードについても計画します。
クラウド HPC 環境の新しい責任:
- クラウド サービス プロバイダーが提供する詳細なコスト レポートと使用状況メトリックを分析して、予算を管理し、支出を予測する。
- クラウド リソースの使用状況とコスト最適化の機会に基づいて戦略的な意思決定を行う。
- 将来の HPC ワークロードとビジネス目標をサポートするクラウド インフラストラクチャへの投資を計画し、承認する。
リフト アンド シフト アーキテクチャの概要
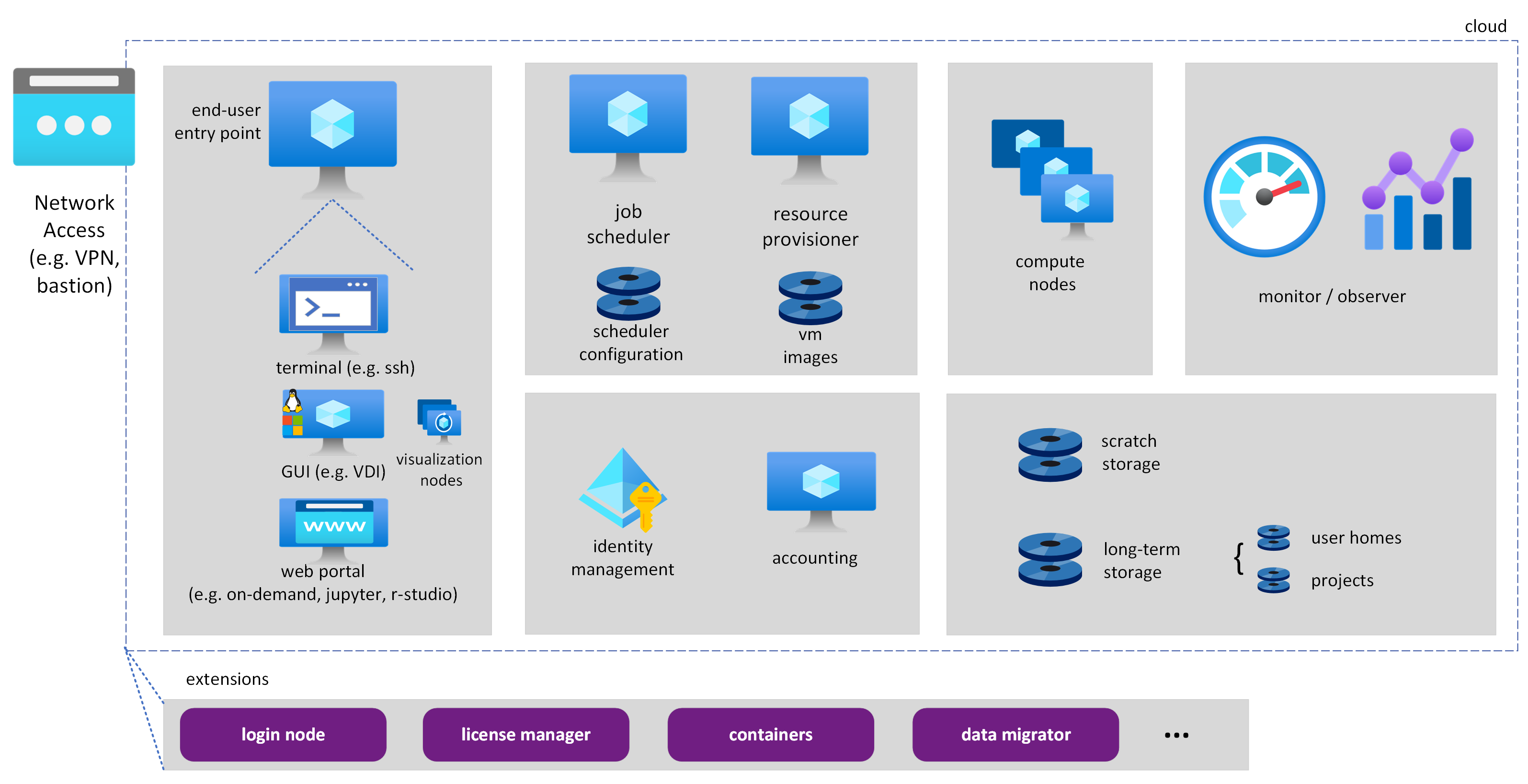
クラウド内の運用 HPC 環境は、いくつかのコンポーネントで構成されます。 環境を構築するコア コンポーネントがいくつかあります。たとえば、ジョブ スケジューラ、リソース プロバイダー、ユーザーが環境にアクセスするためのエントリ ポインター、コンピューティングおよびストレージ デバイスなどです。 環境が運用段階になると、監視、監視可能性、正常性チェック、セキュリティ、ID 管理、アカウンタビリティ、さまざまなストレージ オプションなどのコンポーネントが重要な役割を果たすようになります。
また、サインイン ノード、データ ムーバー、コンテナーの使用、ライセンス マネージャーなど、そのインストールに依存する拡張機能も導入される可能性があります。
この運用レベルの環境には、状況に応じてさまざまなコンポーネントを設定する必要があります。 そのため、環境のデプロイ担当者と管理者が、それぞれ初期デプロイを自動化し、途中でアップグレードするキーとなります。 さらに高度なインストールには、より最適で適切にテストされたソフトウェア バージョンと構成を含む環境テンプレート (または仕様) を含めることもできます。 必要なコンポーネントがすべて揃った状態で環境が運用段階になると、時間の経過と共に、VM の種類、ストレージのオプションや機能の変更など、ユーザーの需要を満たすために調整が必要になる可能性があります。
リフト アンド シフト HPC クラウド アーキテクチャのインスタンス化
ここでは、公式の Azure 製品へのポインター、いくつかのベスト プラクティスが記載された技術ブログ、Git リポジトリ、非運用ソリューションへのリンクなど、各アーキテクチャ コンポーネントの詳細について説明します。
クイック スタート」を参照してください。 基本的な構成要素を使用してクラウド内に HPC 環境を作成するクイック スタート ソリューションの場合、Azure CycleCloud Slurm ワークスペースを使うことをお勧めします。