Apache Spark ストリーミングの概要
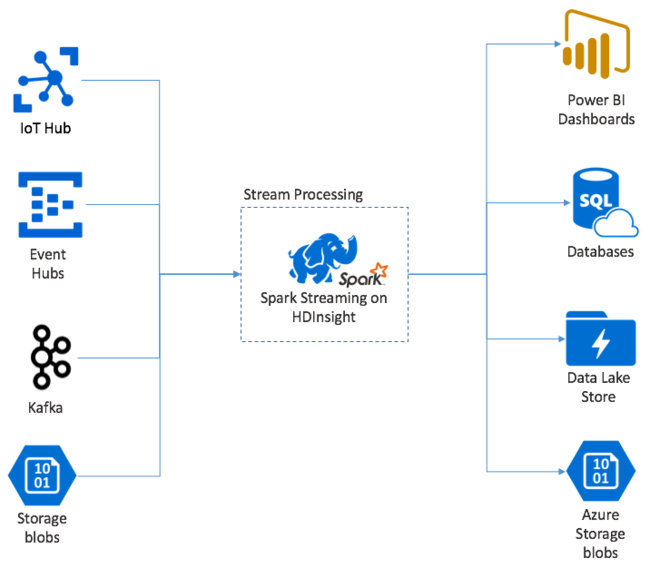
Apache Spark Streaming では、HDInsight Spark クラスターのデータ ストリームを処理します。 ノード障害が発生しても、すべての入力イベントは厳密に 1 回処理されることが保証されています。 Spark Stream は、Azure Event Hubs を含むさまざまなソースから入力データを受け取る、長時間実行されるジョブです。 その他のソース: Azure IoT Hub、Apache Kafka、Apache Flume、X、ZeroMQ、生の TCP ソケット、Apache Hadoop YARN ファイルシステムの監視。 Spark Stream では、単なるイベント ドリブンのプロセスとは異なり、入力データが時間枠にバッチ処理されます。 たとえば、2 秒に短く切り、map、reduce、join、および extract 操作を使用して、各バッチ データが変換されます。 Spark Stream は、次に、変換されたデータをファイルシステム、データベース、ダッシュボード、およびコンソールに書き出します。
Spark Streaming アプリケーションでは、イベントの各 micro-batch を処理のために送信する前に、一瞬待機してそのバッチを収集する必要があります。 これに対し、イベント ドリブンのアプリケーションは各イベントをすぐに処理します。 通常、Spark ストリーミングの待機時間は数秒以内です。 マイクロ バッチのアプローチの利点は、データ処理と集計計算の合理化です。
DStream の概要
Spark ストリーミングは、DStream と呼ばれる分離されたストリームを使用して受信データの継続的なストリームを表します。 DStream は、Event Hubs や Kafka などの入力ソースから作成できます。 または、別の DStream を変換することによっても作成できます。
DStream には、生イベント データの上に抽象化の層を備えています。
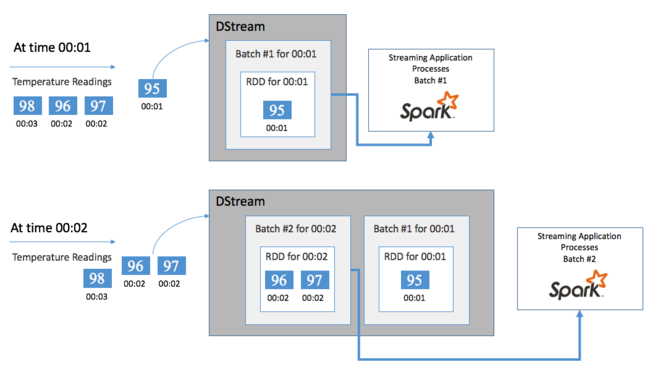
1 つのイベント、たとえば、接続されたサーモスタットからの温度の読み取りから開始するとします。 このイベントが Spark ストリーミング アプリケーションに到達すると、イベントは確実な方法 (複数のノードにレプリケートされる) で格納されます。 このフォールト トレランスにより、単一ノードに障害が発生しても、イベントを損失することはありません。 Spark コアでは、クラスター内の複数のノードにデータを分散するデータ構造を使用しています。 このとき、一般に各ノードは独自のデータをメモリに保持してパフォーマンスを最適化します。 このデータ構造は、Resilient Distributed Dataset (RDD) と呼ばれます。
各 RDD は、バッチ間隔と呼ばれるユーザー定義の期間の経過とともに収集されるイベントを表します。 各バッチ間隔の経過に伴って、その間隔のすべてのデータを含む新しい RDD が生成されます。 この継続的な一連の RDD が DStream に収集されます。 たとえば、バッチ間隔が 1 秒の場合、DStream はその 1 秒間に取り込まれるすべてのデータを含む 1 つの RDD を含む 1 つのバッチを毎秒出力します。 DStream の処理時に、温度のイベントがこれらのバッチのいずれかに出現します。 Spark ストリーミング アプリケーションはイベントを含むバッチを処理し、最終的に各 RDD に格納されているデータを処理します。
Spark ストリーミング アプリケーションの構造
Spark Streaming アプリケーションは、取り込みソースからデータを受け取る、実行時間の長いアプリケーションです。 データを変換して処理し、そのデータを 1 つ以上の宛先にプッシュします。 Spark ストリーミング アプリケーションは、静的な部分と動的な部分から構成されます。 静的な部分では、データの取得元、およびそのデータに対して実行する処理、 結果の宛先を定義します。 動的な部分はアプリケーションを無期限に実行して、停止信号を待機します。
たとえば、次の単純なアプリケーションは、TCP ソケットを介した 1 行のテキストを受信して、各単語が表示される回数をカウントします。
アプリケーションの定義
アプリケーション ロジックを定義するには、次の 4 つの手順を行います。
- StreamingContext を作成します。
- StreamingContext から DStream を作成します。
- 変換を DStream に適用します。
- 結果を出力します。
この定義は静的で、アプリケーションを実行するまでデータは処理されません。
StreamingContext の作成
クラスターを指す SparkContext から StreamingContext を作成します。 StreamingContext を作成する際に、バッチのサイズを秒で指定します。例:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
DStream の作成
StreamingContext インスタンスを使用して、入力ソース用の入力 DStream を作成します。 この場合、アプリケーションは、接続された既定のストレージに新しいファイルが出現するのを待っています。
val lines = ssc.textFileStream("/uploads/Test/")
変換の適用
変換を DStream に適用して、処理を実装します。 このアプリケーションは、ファイルから一度にテキストを 1 行受信し、各行を単語に分割します。 次に、map-reduce パターンを使用して、各単語が出現する回数をカウントします。
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
結果の出力
出力操作を適用して、変換結果を変換先システムにプッシュします。 ここでは、計算の各実行の結果がコンソールに出力されます。
wordCounts.print()
アプリケーションの実行
ストリーミング アプリケーションを起動し、強制終了シグナルを受信するまで実行します。
ssc.start()
ssc.awaitTermination()
Spark Stream の API の詳細については、Apache Spark Streaming プログラミング ガイドを参照してください。
次のサンプル アプリケーションは自己完結型なので、Jupyter Notebook で実行できます。 この例では、カウンターの値と 5 秒おきに現在の時刻 (ミリ秒) を出力するクラス DummySource にモック データ ソースを作成します。 新しい StreamingContext オブジェクトのバッチ間隔は 30 秒です。 バッチが作成されるたびに、ストリーミング アプリケーションでは生成された RDD を調べます。 その後、RDD を Spark DataFrame に変換し、そのデータフレームで一時テーブルを作成します。
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
上記のアプリケーションを起動した後、約 30 秒間待機します。 次に、DataFrame に定期的にクエリを実行して、バッチ内に存在する現在の値のセットを確認できます。たとえば、次の SQL クエリを使用します。
%%sql
SELECT * FROM demo_numbers
結果の出力は次のようになります。
| value | time |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
DummySource は 5 秒ごとに 1 つの値を作成し、アプリケーションは 30 秒ごとに 1 つのバッチを出力するため、値は 6 つになります。
スライディング ウィンドウ
お使いの DStream で一定期間の集計計算を実行するには (最後の 2 秒間の平均温度を取得する場合など)、Spark Streaming に付属する sliding window 操作を使用します。 スライディング ウィンドウには、期間 (ウィンドウの長さ) と、ウィンドウのコンテンツが評価される間隔 (スライド間隔) があります。
スライディング ウィンドウは重複が可能です。たとえば、長さが 2 秒で 1 秒ごとにスライドするウィンドウを定義することができます。 この操作は、集計計算を実行するたびに、前のウィンドウの最後の 1 秒のデータがそのウィンドウに含まれることを意味します。 また、次の 1 秒の新しいデータも含まれます。
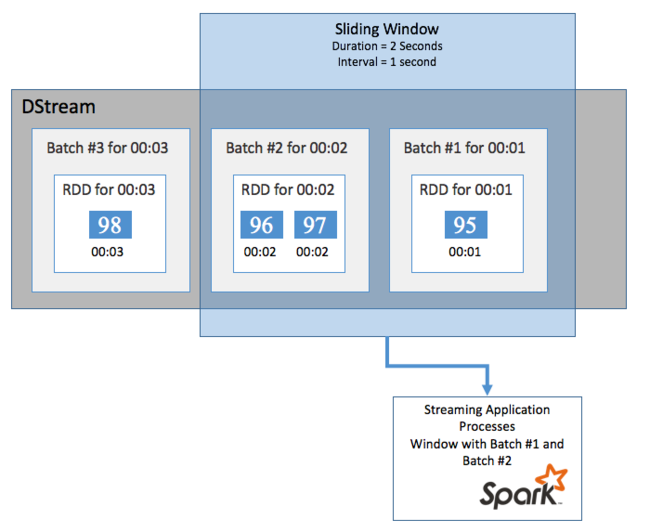
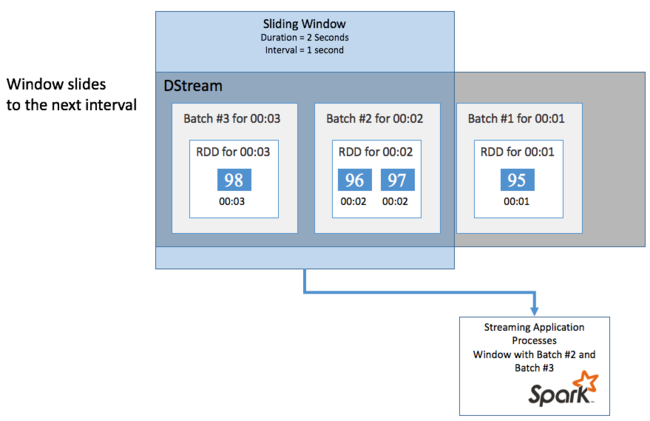
次の例では、DummySource を使うコードを、1 分間の長さと 1 分間のスライドを持つウィンドウにバッチを収集するように更新します。
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
最初の 1 分の後に、12 エントリ (ウィンドウで収集される 2 つのバッチそれぞれから 6 エントリずつ) が生成されます。
| value | time |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
Spark Streaming API で使用できるスライディング ウィンドウ関数には、window、countByWindow、reduceByWindow、countByValueAndWindow などがあります。 これらの関数について詳しくは、DStreams での変換に関する記事をご覧ください。
チェックポイント機能
回復性とフォールト トレランスを実現するために、Spark ストリーミングはチェックポイント機能に依存して、ノード障害が発生した場合でも中断なくストリーム処理を続行できるようにします。 Spark は持続性のあるストレージ (Azure Storage または Data Lake Storage) にチェックポイントを作成します。 これらのチェックポイントには、構成などのストリーミング アプリケーションのメタデータと、そのアプリケーションで定義されている操作が格納されます。 また、まだ処理されていないキューに登録されているバッチも格納されます。 チェックポイントには RDD 内のデータが格納されることもあります。これは、Spark が管理する RDD 内に存在するものからデータの状態を迅速に再構築できるようにするためです。
Spark ストリーミング アプリケーションのデプロイ
Spark Streaming アプリケーションは通常、ローカルの JAR ファイルに構築します。 その後、その JAR ファイルを接続されている既定のストレージにコピーして、HDInsight の Spark にデプロイします。 そのアプリケーションは、POST 操作を使ってクラスターから使用可能な LIVY REST API を使って起動できます。 POST の本文には、ご自分の JAR へのパスが示された JSON ドキュメントが含まれます。 また、ストリーミング アプリケーションを定義して実行する main メソッドのクラス名も含まれます。また、必要に応じてジョブで必要なリソース (Executor、メモリ、コアの数など) も含まれます。 また、お使いのアプリケーションのコードで必要な構成設定も含まれます。
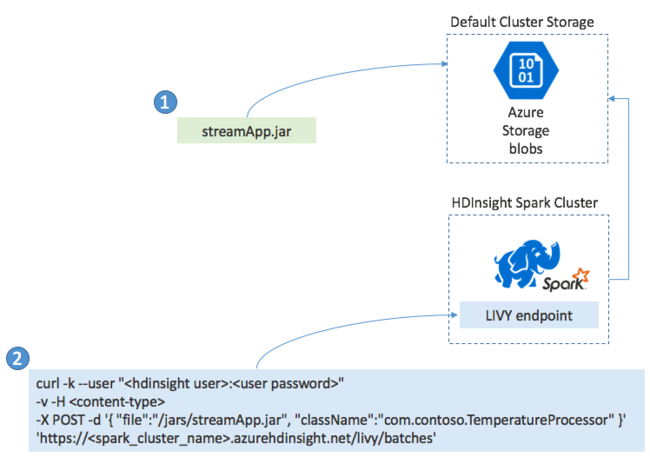
GET 要求を使用して、LIVY エンドポイントに対してすべてのアプリケーションの状態をチェックすることもできます。 最後に、LIVY エンドポイントに対して DELETE 要求を発行して、実行中のアプリケーションを終了できます。 LIVY API の詳細については、Apache LIVY を使用したリモート ジョブに関するページを参照してください