Apache Hadoop で Apache Oozie を使用して Linux ベースの Azure HDInsight でワークフローを定義して実行する
Azure HDInsight で Apache Oozie と Apache Hadoop を使用する方法を説明します。 Oozie は Hadoop ジョブを管理するワークフローおよび調整システムです。 Oozie は Hadoop スタックと統合されており、次のジョブをサポートしています。
- Apache Hadoop MapReduce の使用
- Apache Pig
- Apache Hive
- Apache Sqoop
Oozie を使って、Java プログラムやシェル スクリプトなどの、システムに固有のジョブをスケジュールすることもできます。
Note
HDInsight でワークフローを定義するもう 1 つのオプションは、Azure Data Factory を使う方法です。 Data Factory について詳しくは、Data Factory での Apache Pig と Apache Hive の使用に関するページを参照してください。 Enterprise セキュリティ パッケージを使用したクラスターで Oozie を使用するには、「Enterprise セキュリティ パッケージを使用する HDInsight Hadoop クラスターで Apache Oozie を実行する」を参照してください。
前提条件
HDInsight 上の Hadoop クラスター。 Linux での HDInsight の概要に関するページを参照してください。
SSH クライアント。 「SSH を使用して HDInsight (Apache Hadoop) に接続する」を参照してください。
Azure SQL Database。 Azure portal での Azure SQL Database のデータベースの作成に関するページを参照してください。 この記事では、oozietest という名前のデータベースを使用します。
クラスターのプライマリ ストレージの URI スキーム。 Azure Storage の場合は
wasb://、Azure Data Lake Storage Gen2 の場合はabfs://、Azure Data Lake Storage Gen1 の場合はadl://です。 Azure Storage で安全な転送が有効になっている場合、URI はwasbs://になります。 安全な転送に関するページも参照してください。
ワークフローの例
このドキュメントで使用されるワークフローには、2 つのアクションが含まれています。 アクションは、タスク (Hive、Sqoop、MapReduce、または他のプロセスの実行など) の定義です。
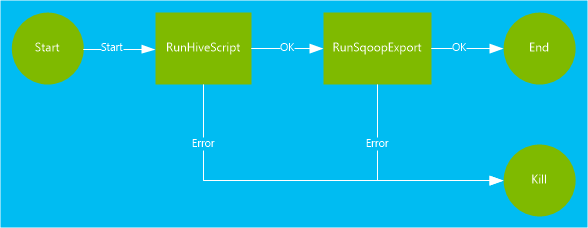
Hive アクションは、HiveQL スクリプトを実行して、HDInsight に含まれている
hivesampletableからレコードを抽出します。 各データ行は、特定のモバイル デバイスからのアクセスを表します。 レコードの形式は次のテキストのようになります。8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1このドキュメントで使う Hive スクリプトは、プラットフォームごと (Android や iPhone など) の合計アクセス数をカウントし、カウントしたアクセス数を新しい Hive テーブルに保存します。
Hive の詳細については、[HDInsight での Hive の使用]\(hdinsight-use-hive) に関するページをご覧ください。
Sqoop アクションは、新しい Hive テーブルの内容を Azure SQL Database で作成されたテーブルにエクスポートします。 Sqoop の詳細については、HDInsight での Apache Sqoop の使用に関するページを参照してください。
注意
HDInsight クラスターでサポートされている Oozie のバージョンについては、「HDInsight で提供される Hadoop クラスター バージョンの新機能」を参照してください。
作業ディレクトリの作成
Oozie では、ジョブに必要なすべてのリソースを同じディレクトリに保存する必要があります。 この例では、wasbs:///tutorials/useoozie を使用します。 このディレクトリを作成するには、次の手順のようにします。
次のコードを編集して、
sshuserをクラスターの SSH ユーザー名に置き換えます。また、CLUSTERNAMEをクラスター名に置き換えます。 それから、SSH を使用して HDInsight クラスターに接続するコードを入力します。ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netディレクトリを作成するには、次のコマンドを使用します。
hdfs dfs -mkdir -p /tutorials/useoozie/data注意
-pパラメーターを指定すると、すべてのディレクトリがこのパスに作成されます。dataディレクトリは、useooziewf.hqlスクリプトが使うデータを保持するために使われます。次のコードを編集して、
sshuserを SSH ユーザー名に置き換えます。 Oozie がユーザー アカウントを偽装できるようにするには、次のコマンドを使用します。sudo adduser sshuser users注意
ユーザーが既に
usersグループのメンバーであることを示すエラーは無視できます。
データベース ドライバーの追加
このワークフローでは、Sqoop を使用して SQL データベースにデータをエクスポートします。 そのため、SQL データベースとの対話に使用する JDBC ドライバーのコピーを提供する必要があります。 JDBC ドライバーを作業ディレクトリにコピーするには、SSH セッションから次のコマンドを使用します。
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
重要
/usr/share/java/ にある実際の JDBC ドライバーを確認します。
ワークフローで他のリソース (MapReduce アプリケーションを含む jar など) を使っている場合は、これらのリソースも追加する必要があります。
Hive クエリの定義
次の手順を使って、クエリを定義する Hive クエリ言語 (HiveQL) スクリプトを作成します。 このドキュメントで後述する Oozie ワークフローの中で、このクエリを使用します。
SSH 接続から、次のコマンドを使用して、
useooziewf.hqlという名前のファイルを作成します。nano useooziewf.hqlGNU nano エディターが開いたら、ファイルの内容として次のクエリを使います。
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;このスクリプトでは、次の 2 つの変数を使用しています。
${hiveTableName}:作成されるテーブルの名前が格納されます。${hiveDataFolder}:テーブルのデータ ファイルを保存する場所が格納されます。ワークフロー定義ファイル (この記事では workflow.xml) は、実行時にこの HiveQL スクリプトにこれらの値を渡します。
ファイルを保存するには、Ctrl+X を選択し、Y キーを押してから、Enter キーを選択します。
次のコマンドを使用して、
useooziewf.hqlをwasbs:///tutorials/useoozie/useooziewf.hqlにコピーします。hdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hqlこのコマンドは、クラスターの HDFS 互換ストレージに
useooziewf.hqlファイルを保存します。
ワークフローの定義
Oozie ワークフローの定義は、XML プロセス定義言語である Hadoop プロセス定義言語 (hPDL) を使って記述します。 次の手順に従ってワークフローを定義します。
次のステートメントを使用して、新しいファイルを作成し、編集します。
nano workflow.xmlnano エディターが開いたら、ファイルの内容として次の XML を入力します。
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>このワークフローでは、2 つのアクションが定義されています。
RunHiveScript:開始アクションであり、useooziewf.hqlHive スクリプトを実行します。RunSqoopExport: Sqoop を使って、作成されたデータを Hive スクリプトから SQL データベースにエクスポートします。 このアクションは、RunHiveScriptアクションが正常に実行された場合にのみ実行されます。このワークフローには、
${jobTracker}などのいくつかのエントリがあります。 これらのエントリは、ジョブ定義で使う値に置き換えます。 ジョブ定義は、このドキュメント内で後ほど作成します。また、Sqoop セクションの
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>エントリにも注意してください。 このエントリは、このアクションの実行時にこのアーカイブを Sqoop で使用できるようにすることを Oozie に指示します。
ファイルを保存するには、Ctrl+X を選択し、Y キーを押してから、Enter キーを選択します。
次のコマンドを使用して、
workflow.xmlファイルを/tutorials/useoozie/workflow.xmlにコピーします。hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
テーブルを作成する
注意
SQL Database に接続してテーブルを作成するには、多くの方法があります。 次の手順では、HDInsight クラスターから FreeTDS を使用します。
次のコマンドを使用して、FreeTDS を HDInsight クラスターにインストールします。
sudo apt-get --assume-yes install freetds-dev freetds-bin次のコードを編集して、
<serverName>をご利用の論理 SQL サーバー名に置き換え、<sqlLogin>をサーバー ログインに置き換えます。 コマンドを入力して、前提条件の SQL データベースに接続します。 プロンプトでパスワードを入力します。TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietest出力は次のテキストのようになります。
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>1>プロンプトで、以下の行を入力します。CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GOGOステートメントを入力すると、前のステートメントが評価されます。 これらのステートメントにより、ワークフローで使われるmobiledataという名前のテーブルが作成されます。テーブルが作成されたことを確認するには、次のコマンドを使います。
SELECT * FROM information_schema.tables GO次のようなテキストが出力されます。
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLE1>プロンプトで「exit」と入力して、tsql ユーティリティを終了します。
ジョブ定義の作成
ジョブ定義には、workflow.xml の検索場所を記述します。 ワークフローで使われる他のファイル (useooziewf.hql など) の検索場所についても記述します。 また、ワークフローおよび関連するファイル内で使われるプロパティの値も定義します。
既定のストレージの完全なアドレスを取得するには、次のコマンドを使います。 このアドレスは、次のステップで作成する構成ファイルで使います。
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xmlこのコマンドでは、次の XML のような情報が返されます。
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value>Note
HDInsight クラスターで既定のストレージとして Azure Storage を使用する場合、
<value>要素の内容はwasbs://で始まります。 Azure Data Lake Storage Gen1 を使用する場合は、adl://で始まります。 Azure Data Lake Storage Gen2 を使用する場合は、abfs://で始まります。以下の手順で使うため、
<value>要素の内容を保存します。次の xml を以下のように編集します。
プレースホルダーの値 置き換えられた値 wasbs://mycontainer@mystorageaccount.blob.core.windows.net 手順 1 で受け取った値。 admin admin ではない場合、HDInsight クラスターの自分のログイン名。 serverName Azure SQL Database サーバー名。 sqlLogin Azure SQL Database サーバー ログイン。 sqlPassword Azure SQL Database サーバー ログインのパスワード。 <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.windows.net;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property> </configuration>このファイル内のほとんどの情報は、workflow.xml ファイルまたは ooziewf.hql ファイルで使われる値 (
${nameNode}など) を設定するために使われます。 パスがwasbsパスの場合は、完全パスを使用する必要があります。wasbs:///だけに短縮しないでください。oozie.wf.application.pathエントリでは、workflow.xml ファイルの検索場所を定義します。 このファイルには、このジョブで実行されたワークフローが格納されます。Oozie ジョブ定義構成を作成するには、次のコマンドを使います。
nano job.xmlnano エディターが開いたら、編集した XML をファイルの内容として貼り付けます。
ファイルを保存するには、Ctrl+X を選択し、Y キーを押してから、Enter キーを選択します。
ジョブの送信と管理
次の手順では、Oozie コマンドを使用して、クラスターで Oozie ワークフローを送信および管理します。 Oozie コマンドは、 Oozie REST APIの使いやすいインターフェイスです。
重要
Oozie コマンドを使うときは、HDInsight ヘッドノードの FQDN を使う必要があります。 この FQDN にはクラスターからのみアクセスできます。クラスターが Azure 仮想ネットワーク上にある場合は、同じネットワークの他のマシンからアクセスできます。
Oozie サービスの URL を取得するには、次のコマンドを使います。
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xmlこのコマンドでは、次の XML のような情報が返されます。
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie</value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozieの部分が Oozie コマンドで使用する URL です。コードを編集して、URL を前に返された URL に置き換えます。 URL の環境変数を作成するには次のコマンドを使うので、すべてのコマンドでこれを入力する必要はありません。
export OOZIE_URL=http://HOSTNAMEt:11000/oozieジョブを送信するには、次のコードを使用します。
oozie job -config job.xml -submitこのコマンドでは、
job.xmlからジョブ情報を読み込んで Oozie に送信しますが、実行はしません。コマンドが完了すると、ジョブの ID が返されます (例:
0000005-150622124850154-oozie-oozi-W)。 この ID はジョブの管理に使用されます。次のコードを編集して、
<JOBID>を前の手順で返された ID に置き換えます。 ジョブのステータスを表示するには、次のコマンドを使います。oozie job -info <JOBID>次のテキストのような情報が返されます。
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------このジョブの状態は
PREPです。 この状態は、ジョブが作成されたが開始されていないことを示します。次のコードを編集して、
<JOBID>を前に返された ID に置き換えます。 ジョブを開始するには、次のコマンドを使います。oozie job -start <JOBID>このコマンドの実行後に状態を確認すると、ジョブが実行中状態になり、ジョブのアクションに関する情報が返されます。 このジョブは完了までに数分かかります。
次のコードを編集して、
<serverName>をご利用のサーバー名に置き換え、<sqlLogin>をサーバー ログインに置き換えます。 正常に "タスクが完了したら"、次のコマンドを使って、データが生成され、SQL データベース テーブルにエクスポートされたことを確認できます。 プロンプトでパスワードを入力します。TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietest1>プロンプトで、次のクエリを入力します。SELECT * FROM mobiledata GO次のテキストのような情報が返されます。
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
Oozie コマンドの詳細については、Apache Oozie コマンドライン ツールに関するページをご覧ください。
Oozie REST API
Oozie REST API を使うと、Oozie で動く独自のツールを作成できます。 Oozie REST API の使用に関する HDInsight 固有の情報は次のとおりです。
URI:
https://CLUSTERNAME.azurehdinsight.net/oozieを使うと、クラスターの外部から REST API にアクセスできます。認証:認証を行うには、クラスターの HTTP アカウント (admin) とパスワードで API を使います。 次に例を示します。
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.net/oozie/versions
Oozie REST API の使い方について詳しくは、Apache Oozie Web サービス API のページをご覧ください。
Oozie Web UI
Oozie Web UI は、クラスターでの Oozie ジョブの状態を表示する Web ベースのビューを提供します。 Web UI では、次の情報を表示できます。
- ジョブの状態
- ジョブ定義
- 構成
- ジョブのアクションのグラフ
- ジョブのログ
また、ジョブ内のアクションの詳細を表示することもできます。
Oozie Web UI にアクセスするには、次の手順のようにします。
HDInsight クラスターへの SSH トンネルを作成します。 詳細については、HDInsight での SSH トンネリングの使用に関するページを参照してください。
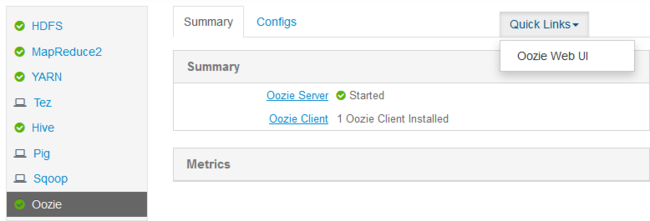
トンネルを作成した後、URI
http://headnodehost:8080を使用して Web ブラウザーで Ambari Web UI を開きます。ページの左側で、 [Oozie]>[クイック リンク]>[Oozie Web UI] の順に選びます。
Oozie Web UI には、実行中のワークフロー ジョブが既定で表示されます。 すべてのワークフロー ジョブを表示するには、 [All Jobs]\(すべてのジョブ\) を選びます。
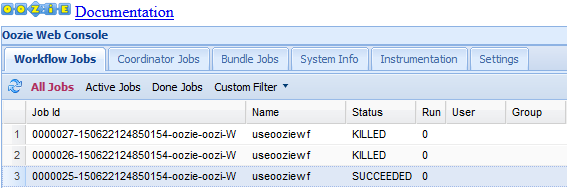
ジョブに関する他の情報を表示するには、ジョブを選びます。
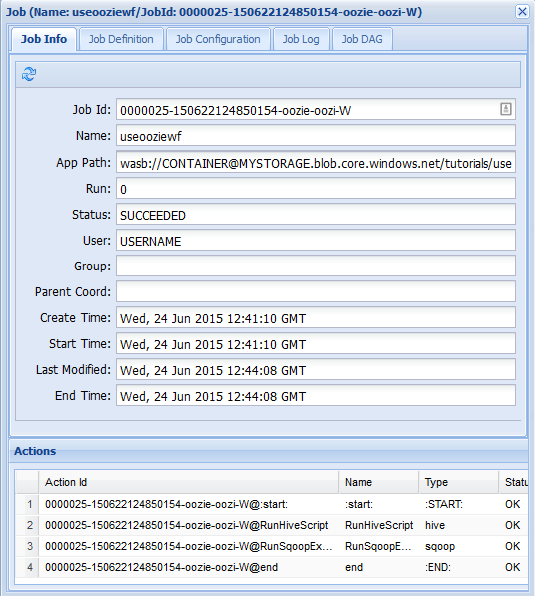
[Job Info]\(ジョブの情報\) タブでは、基本的なジョブ情報とジョブの個々のアクションを確認できます。 上部にあるタブを使って、 [Job Definition]\(ジョブの定義\) の表示、 [Job Configuration]\(ジョブの構成\) の表示、 [Job Log]\(ジョブのログ\) へのアクセス、 [Job DAG]\(ジョブの DAG\) でジョブの有向非巡回グラフ (DAG) の表示を行うことができます。
[Job Log]: [Get Logs] ボタンを選択してジョブのすべてのログを取得するか、
Enter Search Filterフィールドを使用してログをフィルター処理します。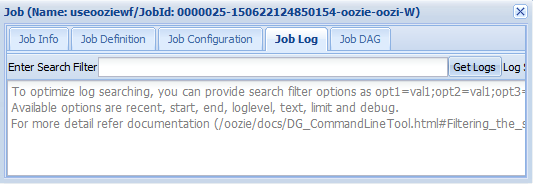
[Job DAG]\(ジョブの DAG) :DAG は、ワークフローで取得されるデータ パスの概要をグラフィックで表したものです。
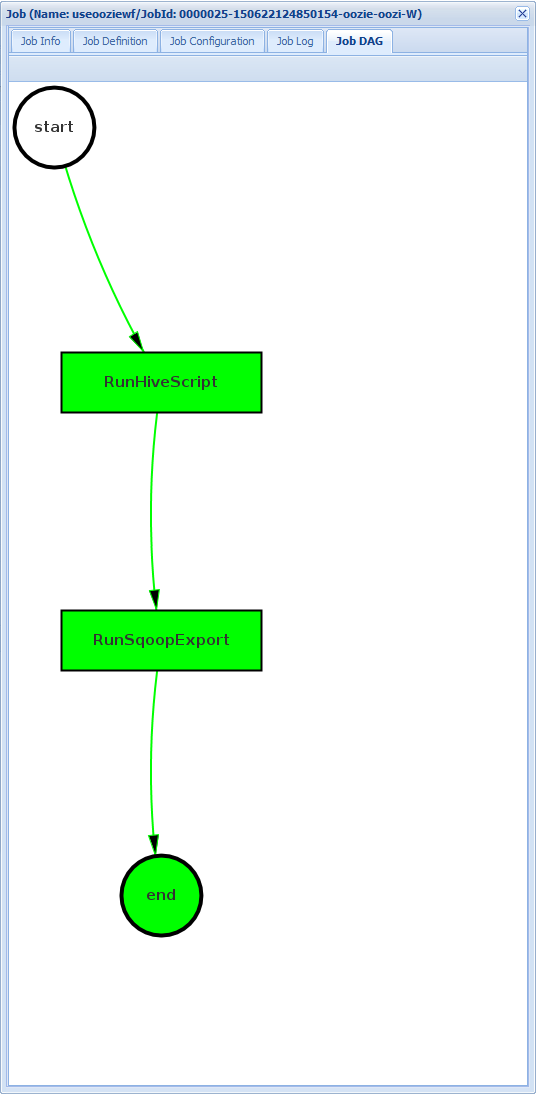
[Job Info]\(ジョブの情報\) タブでアクションのいずれかを選択すると、そのアクションの情報が表示されます。 たとえば、RunHiveScript アクションを選びます。
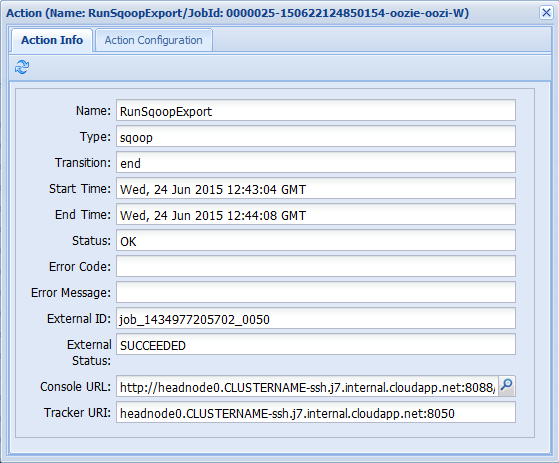
コンソールの URL へのリンクなど、アクションの詳細を確認できます。 このリンクを使うと、ジョブ トラッカーでのジョブの情報が表示されます。
ジョブのスケジュールを設定する
コーディネーターを使うと、ジョブの開始時刻、終了時刻、実行頻度を指定できます。 ワークフローのスケジュールを定義するには、次の手順のようにします。
次のコマンドを使って、coordinator.xml という名前のファイルを作成します。
nano coordinator.xmlこのファイルの内容として、次の XML を使用します。
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>注意
${...}変数は、実行時にジョブ定義の値に置き換えられます。 変数は次のとおりです。${coordFrequency}:ジョブのインスタンスが実行される間隔。${coordStart}:ジョブの開始時刻。${coordEnd}:ジョブの終了時刻。${coordTimezone}:コーディネーター ジョブでは、(通常は UTC を使用して表される) 夏時間なしの固定タイム ゾーンを使用します。 このタイム ゾーンを、"Oozie 処理のタイムゾーン" と呼びます。${wfPath}:workflow.xml のパス。
ファイルを保存するには、Ctrl+X を選択し、Y キーを押してから、Enter キーを選択します。
ファイルをこのジョブの作業ディレクトリにコピーするには、次のコマンドを使います。
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xml以前作成した
job.xmlファイルを変更するには、次のコマンドを使います。nano job.xml次の変更を行います。
ワークフロー ファイルではなく、コーディネーター ファイルを実行するように Oozie に指示するには、
<name>oozie.wf.application.path</name>を<name>oozie.coord.application.path</name>に変更します。コーディネーターが使用する
workflowPath変数を設定するには、次の XML を追加します。<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property>wasbs://mycontainer@mystorageaccount.blob.core.windowsテキストを、job.xml ファイルの他のエントリで使われている値に置き換えます。コーディネーターが使用する開始時刻、終了時刻、頻度を定義するには、次の XML を追加します。
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>これらの値によって、開始時刻が 2018 年 5 月 10 日 12:00 PM に、終了時刻が 2018 年 5 月 12 日 12:00 PM に設定されます。 このジョブの実行間隔は、毎日に設定されます。 頻度は分単位であるため、24 時間 x 60 分 = 1440 分になります。 最後に、タイムゾーンを UTC に設定しています。
ファイルを保存するには、Ctrl+X を選択し、Y キーを押してから、Enter キーを選択します。
ジョブを提出して開始するには、次のコマンドを使います。
oozie job -config job.xml -runOozie Web UI にアクセスし、 [Coordinator Jobs]\(コーディネーター ジョブ\) タブを選ぶと、次の画像のような情報が表示されます。
![Oozie Web コンソールの [Coordinator Jobs] タブ。](media/hdinsight-use-oozie-linux-mac/coordinator-jobs-tab.png)
[Next Materialization (次の実体化)] エントリは、このジョブが次回実行される日時を示しています。
前のワークフロー ジョブと同様に、Web UI でジョブ エントリを選ぶと、そのジョブの情報が表示されます。
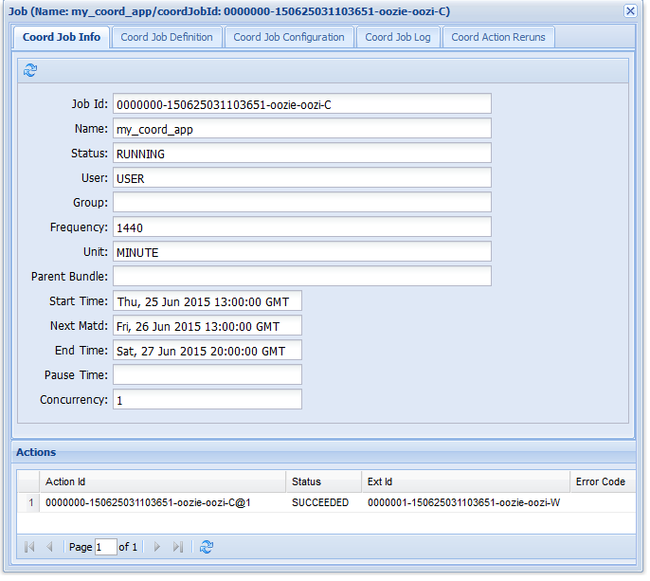
Note
この画像には、正常に実行されたジョブのみが表示されており、スケジュールされたワークフロー内の個々のアクションについては表示されません。 個々のアクションを表示するには、 [Action]\(アクション\) エントリの 1 つを選びます。
![OOzie Web コンソールの [Job Info] タブ。](media/hdinsight-use-oozie-linux-mac/coordinator-action-job.png)
次のステップ
この記事では、Oozie ワークフローを定義する方法と Oozie ジョブを実行する方法について説明しました。 HDInsight の使用方法について詳しくは、次の記事をご覧ください。