Azure HDInsight を使用した Apache Hadoop HDFS のトラブルシューティング
Hadoop 分散ファイル システム (HDFS) を操作する際の主な問題と解決策について説明します。 コマンドの完全な一覧については、HDFS コマンド ガイドとファイル システム シェル ガイドを参照してください。
クラスター内からローカルの HDFS にアクセスする方法
問題
HDInsight クラスター内から Azure Blob Storage または Azure Data Lake Storage を使用するのではなく、コマンド ラインおよびアプリケーション コードからローカル HDFS にアクセスする。
解決手順
コマンド プロンプトでは、次のコマンドのように
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...をそのまま使います。hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /userソース コードでは、次のサンプル アプリケーションのように URI
hdfs://mycluster/をそのまま使います。import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }HDInsight クラスターで次のコマンドを使ってコンパイル済みの .jar ファイル (例:
java-unit-tests-1.0.jarという名前のファイル) を実行します。hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
BLOB への書き込みに関するストレージ例外
問題
hadoop または hdfs dfs コマンドを使って HBase クラスターで 12 GB 以上のファイルを書き込むと、次のエラーが発生する可能性があります。
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
原因
HDInsight クラスター上の HBase では、Azure Storage に書き込むときに既定のブロック サイズは 256 KB です。 HBase API または REST API では問題ありませんが、hadoop または hdfs dfs コマンドライン ユーティリティを使うとエラーになります。
解決方法
fs.azure.write.request.size を使ってさらに大きいブロック サイズを指定します。 この変更は、-D パラメーターを使うことで、利用状況に応じて指定できます。 hadoop コマンドでこのパラメーターを使う例を次に示します。
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
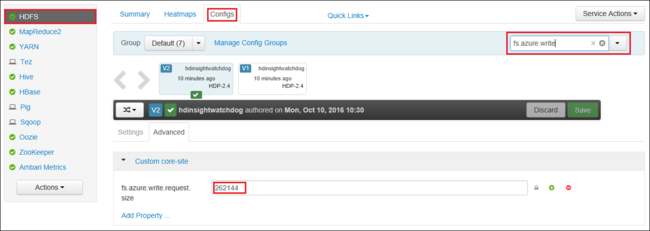
Apache Ambari を使うことで、fs.azure.write.request.size の値をグローバルに増やすこともできます。 Ambari Web UI で値を変更するには、次の手順を使えます。
ブラウザーで、クラスターの Ambari Web UI に移動します。 URL は
https://CLUSTERNAME.azurehdinsight.netです。CLUSTERNAMEはクラスターの名前です。 プロンプトが表示されたら、クラスターの管理者名とパスワードを入力します。画面の左側にある [HDFS] を選び、 [Configs (構成)] を選びます。
[Filter... (フィルター...)] フィールドに「
fs.azure.write.request.size」と入力します。値を 262144 (256 KB) から新しい値に変更します。 たとえば、4194304 (4 MB) に変更します。
Ambari の使用について詳しくは、「Apache Ambari Web UI を使用した HDInsight クラスターの管理」をご覧ください。
du
-du コマンドを実行すると、指定のディレクトリに含まれるファイルとディレクトリのサイズが表示されます。ファイルだけの場合、ファイルの長さが表示されます。
-s オプションを指定すると、再生されているファイルの長さが手短に集計されます。
-h オプションを指定すると、ファイル サイズがフォーマットされます。
例:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
rm
-rm コマンドを指定すると、引数として指定されているファイルが削除されます。
例:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
次のステップ
問題がわからなかった場合、または問題を解決できない場合は、次のいずれかのチャネルでサポートを受けてください。
Azure コミュニティのサポートを通じて Azure エキスパートから回答を得る。
カスタマー エクスペリエンスを向上させるための Microsoft Azure の公式アカウントの @AzureSupport に連絡する。 Azure コミュニティで適切なリソース (回答、サポート、エキスパートなど) につながる。
さらにヘルプが必要な場合は、Azure portal からサポート リクエストを送信できます。 メニュー バーから [サポート] を選択するか、 [ヘルプとサポート] ハブを開いてください。 詳細については、「Azure サポート要求を作成する方法」を参照してください。 サブスクリプション管理と課金サポートへのアクセスは、Microsoft Azure サブスクリプションに含まれていますが、テクニカル サポートはいずれかの Azure のサポート プランを通して提供されます。