Azure HDInsight でクラスター パフォーマンスを監視する
HDInsight クラスターの正常性とパフォーマンスを監視することは、最適なパフォーマンスとリソースの使用率を維持するために重要です。 監視は、クラスター構成エラーとユーザー コードの問題を検出し、対応するために役立つ場合もあります。
以下のセクションでは、クラスター、Apache Hadoop YARN キューの負荷を監視して、最適化し、ストレージの調整の問題を検出する方法について説明します。
クラスター負荷の監視
Hadoop クラスターでは、クラスターの負荷がすべてのノードに均等に分散している場合に、最適なパフォーマンスが発揮されます。 これにより、個々のノードの RAM、CPU、またはディスク リソースによって制限されることなく、実行するタスクの処理が可能になります。
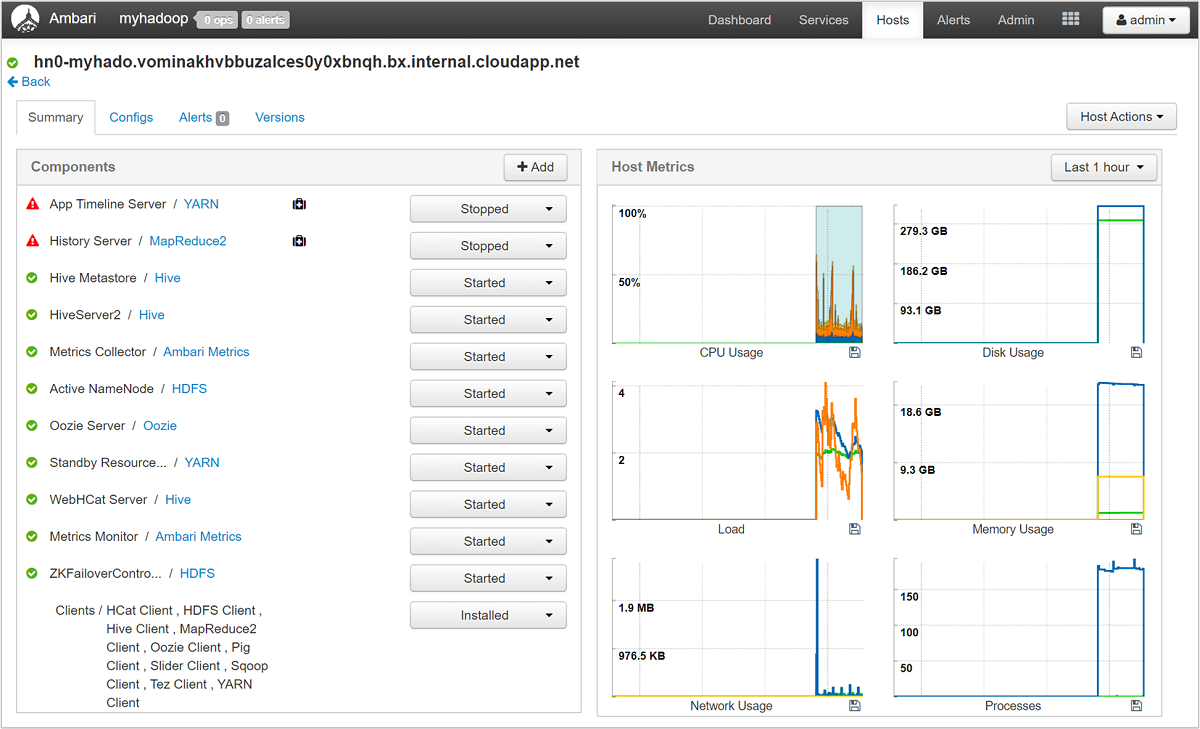
クラスターのノードとその負荷の概要を把握するには、Ambari Web UI にサインインし、 [Hosts] タブを選択します。ホストの一覧が完全修飾ドメイン名で表示されます。 各ホストの動作状態は、色付きの正常性インジケーターで示されます。
| Color | 説明 |
|---|---|
| [赤] | ホスト上の少なくとも 1 つのマスター コンポーネントがダウンしています。 カーソルを移動すると、ツールヒントに影響を受けるコンポーネントの一覧が表示されます。 |
| オレンジ | ホスト上の少なくとも 1 つのセカンダリ コンポーネントがダウンしています。 カーソルを移動すると、ツールヒントに影響を受けるコンポーネントの一覧が表示されます。 |
| 黄 | Ambari サーバーが、ホストから 3 分以上ハートビートを受信していません。 |
| [緑] | 通常の実行状態です。 |
各ホストのコア数と RAM 合計の列と、ディスク使用量と負荷の平均の列も表示されます。
![Apache Ambari の [ホスト] タブの概要。](media/hdinsight-key-scenarios-to-monitor/apache-ambari-hosts-tab.png)
そのホストで実行されているコンポーネントとそのメトリックの詳細を確認するには、いずれかのホスト名を選択します。 メトリックは、CPU 使用量、負荷、ディスク使用率、メモリ使用量、ネットワーク使用量、およびプロセス数の選択可能なタイムラインとして表示されます。
アラートの設定とメトリックの表示の詳細については、「Apache Ambari Web UI を使用した HDInsight クラスターの管理」を参照してください。
YARN キューの構成
Hadoop には、分散プラットフォーム全体で実行される多様なサービスがあります。 YARN (Yet Another Resource Negotiator) により、これらのサービスが調整され、クラスター リソースが割り当てられ、負荷が確実にクラスター全体で均等に分散されます。
YARN は、リソース管理とジョブのスケジュール設定/監視という JobTracker の 2 つの役割を、グローバルな Resource Manager とアプリケーションごとの ApplicationMaster (AM) という 2 つのデーモンに分割します。
ResourceManager は純粋なスケジューラであり、すべての競合アプリケーション間で使用可能なリソースの判別のみを行います。 ResourceManager は、すべてのリソースが常に使用中になり、SLA、容量の保証などの多様な定数に対して最適化されるように確保します。 ApplicationMaster は、ResourceManager のリソースをネゴシエートし、NodeManager と連携してコンテナーとそのリソース消費の実行と監視を行います。
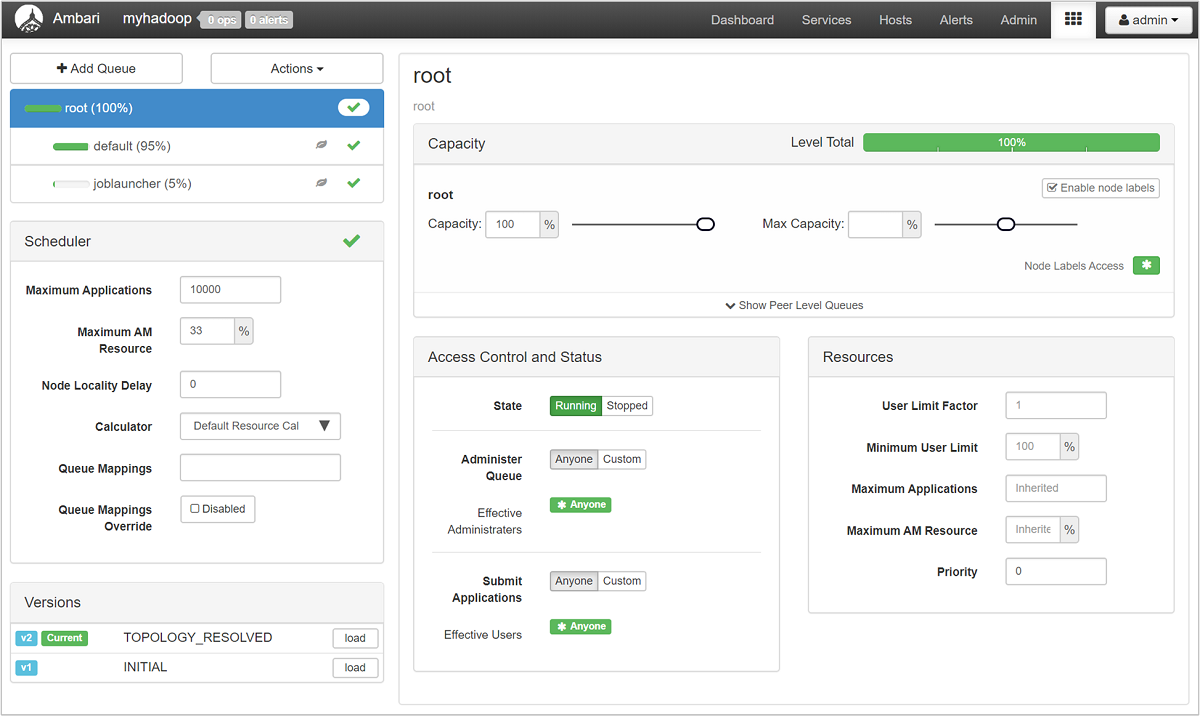
複数のテナントで 1 つの大きなクラスターを共有する場合、クラスターのリソースに競合が発生します。 CapacityScheduler は、要求のキューを処理してリソース共有を支援する接続可能なスケジューラです。 CapacityScheduler も、他のアプリケーションのキューに空きリソースが使用される前に、組織のサブキュー間でリソースを共有するために階層キューをサポートしています。
YARN を使用すると、これらのキューにリソースを割り当てることができます。また、使用できるすべてのリソースが割り当てられているかどうかがわかります。 キューに関する情報を確認するには、Ambari Web UI にサインインし、上部のメニューから [YARN Queue Manager] を選択します。
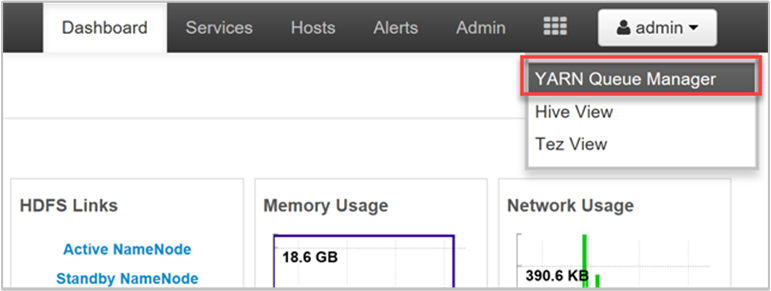
[YARN Queue Manager]\(YARN キュー マネージャー\) ページの左側にはキュー一覧と、それぞれに割り当てられている容量の割合が表示されます。
キューの詳細を確認するには、Ambari ダッシュボードの左側の一覧から [YARN] を選択します。 [Quick Links] ドロップダウン メニューで、アクティブ ノードの下にある [Resource Manager UI] を選択します。
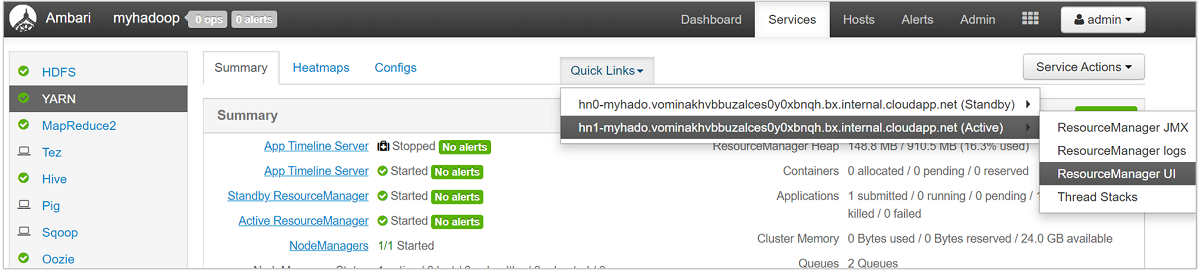
ResourceManager UI の左側のメニューから [Scheduler] を選択します。 [Application Queues]\(アプリケーション キュー\) の下にキューの一覧が表示されます この一覧では、各キューに使用される容量、キュー間のジョブの分散状況、ジョブのリソースに制約があるかどうかを確認できます。
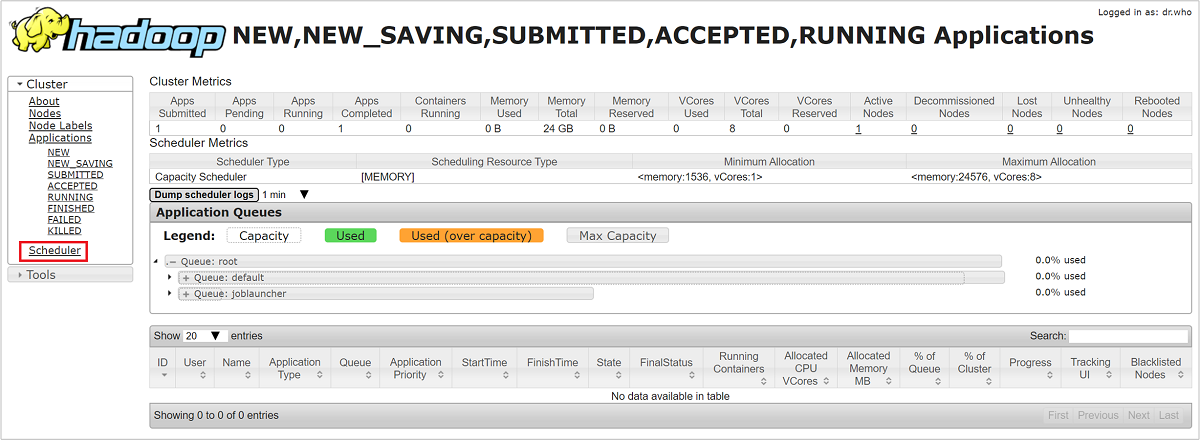
ストレージの調整
クラスターのパフォーマンスのボトルネックはストレージ レベルで生じる可能性があります。 この種類のボトルネックは、多くの場合、入力/出力 (IO) 操作のブロックが原因です。この問題は、実行中のタスクから送信される IO が、ストレージ サービスで処理できる量を超えるときに発生します。 このブロックによって、現在の IO 処理が完了するまで処理を待機する IO 要求のキューが作成されます。 このブロックは、ストレージ調整が原因です。このストレージ調整は物理的な制限ではなく、サービス レベル アグリーメント (SLA) でストレージ サービスから課せられる制限です。 この制限によって、単一のクライアントまたはテナントがサービスを独占することができないように確保されます。 SLA は、Azure Storage の IO 数/秒 (IOPS) を制限します。詳細については、Standard ストレージ アカウントのスケーラビリティおよびパフォーマンスのターゲットに関するページを参照してください。
Azure Storage を使用している場合、ストレージに関連する問題の監視の詳細については、「Microsoft Azure Storage の監視、診断、およびトラブルシューティング」を参照してください。
クラスターのバッキング ストアが Azure Data Lake Storage (ADLS) の場合、帯域幅の制限が原因で調整が発生する可能性が最も高くなります。 このような調整は、タスク ログの調整エラーを監視することで確認できます。 ADLS については、以下の記事の適切なサービスの調整セクションを参照してください。
- HDInsight の Apache Hive と Azure Data Lake Storage のパフォーマンス チューニング ガイダンス
- HDInsight の MapReduce と Azure Data Lake Storage のパフォーマンス チューニング ガイダンス
ノードの動作が遅い場合のトラブルシューティング
場合によっては、クラスターのディスク領域不足が原因で動作が遅くなる可能性があります。 次の手順で調査します。
各ノードに接続するには ssh コマンドを使用します。
次のいずれかのコマンドを実行して、ディスク使用量を確認します。
df -h du -h --max-depth=1 / | sort -h出力を確認し、
mntフォルダーまたはその他のフォルダーに大きなファイルがあるかどうかを確認します。 通常、usercache、およびappcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) フォルダーには大きなファイルが含まれています。大きなファイルがある場合、現在のジョブによってファイルの拡張が発生しているか、失敗した前のジョブがこの問題の一因になっている可能性があります。 この動作が現在のジョブによって発生しているかどうかを確認するには、次のコマンドを実行します。
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/このコマンドで特定のジョブが示される場合は、次のようなコマンドを使用してジョブを終了できます。
yarn application -kill -applicationId <application_id>application_idをアプリケーション ID で置き換えます。 特定のジョブが示されない場合は、次の手順に進んでください。上記のコマンドが完了した後、または特定のジョブが指定されていない場合は、次のようなコマンドを実行して、特定したサイズの大きなファイルを削除します。
rm -rf filecache usercache
ディスク領域の問題の詳細については、「ディスク領域の不足」を参照してください。
Note
保持したい大きなファイルがあるが、それがディスク領域不足の問題の一因になっている場合は、HDInsight クラスターをスケールアップしてサービスを再起動する必要があります。 この手順を完了して数分待つと、ストレージが解放され、ノードの通常のパフォーマンスに戻ることがわかります。
次のステップ
クラスターのトラブルシューティングと監視の詳細については、以下のリンクを参照してください。