チュートリアル:HDInsight で Apache Kafka による Apache Spark 構造化ストリーミングを使用する
このチュートリアルでは、Azure HDInsight で Apache Kafka による Apache Spark 構造化ストリーミングを使用してデータを読み書きする方法について説明します。
Spark 構造化ストリーミングは、Spark SQL を基盤とするストリーム処理エンジンです。 静的データに対してバッチ計算と同様にストリーミング計算を表現できるようになります。
このチュートリアルでは、以下の内容を学習します。
- Azure Resource Manager テンプレートを使用してクラスターを作成する
- Kafka で Spark 構造化ストリーミングを使用する
このドキュメントの手順を完了したら、余分に課金されないようにするためにクラスターを削除してください。
前提条件
jq。コマンド ライン JSON プロセッサです。 「https://stedolan.github.io/jq/」を参照してください。
HDInsight の Spark での Jupyter Notebook の使用方法を熟知していること。 詳細については、HDInsight の Apache Spark を使用したデータの読み込みとクエリの実行に関するドキュメントを参照してください。
Scala プログラミング言語の知識があること。 このチュートリアルで使用するコードは、Scala で記述されています。
Kafka トピックの作成方法を熟知していること。 詳細については、HDInsight の Apache Kafka のクイック スタートに関するドキュメントを参照してください。
重要
このドキュメントの手順には、HDInsight の Spark クラスターと HDInsight の Kafka クラスターの両方を含む Azure リソース グループが必要です。 これらのクラスターは両方とも、Spark クラスターが Kafka クラスターと直接通信できるように、Azure Virtual Network 内に配置します。
利便性のために、このドキュメントは、必要なすべての Azure リソースを作成できるテンプレートにリンクしています。
仮想ネットワークでの HDInsight の使用方法の詳細については、HDInsight 用の仮想ネットワークの計画に関するドキュメントを参照してください。
Apache Kafka での構造化ストリーミング
Spark 構造化ストリーミングは、Spark SQL エンジンを基盤とするストリーム処理エンジンです。 構造化ストリーミングを使用すると、バッチ クエリと同様にストリーミング クエリを記述できます。
次のコード スニペットは、Kafka からの読み取りとファイルへの保存を示しています。 最初のコード スニペットはバッチ操作であり、2 番目はストリーミング操作です。
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
どちらのスニペットでも、データは Kafka から読み取られ、ファイルに書き込まれます。 これらの例の違いは次のとおりです。
| Batch | ストリーミング |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
ストリーミング操作では、30,000 ミリ秒後にストリーミングを停止する、awaitTermination(30000) も使用されています。
Kafka で構造化ストリーミングを使用するには、プロジェクトに org.apache.spark : spark-sql-kafka-0-10_2.11 パッケージの依存関係が必要です。 このパッケージのバージョンは、HDInsight の Spark のバージョンと一致する必要があります。 Spark 2.4 (HDInsight 4.0 で使用可能) の場合、さまざまなプロジェクトの種類の依存関係情報を https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar で確認できます。
このチュートリアルで使用される Jupyter Notebook では、次のセルでこのパッケージの依存関係を読み込みます。
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
クラスターの作成
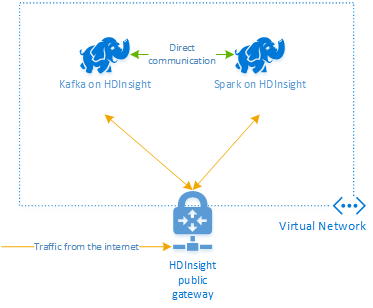
HDInsight 上の Apache Kafka では、パブリック インターネット経由の Kafka ブローカーへのアクセスは提供されません。 Kafka を使用するものは、すべて同じ Azure 仮想ネットワークに属している必要があります。 このチュートリアルでは、Kafka クラスターと Spark クラスターの両方を同じ Azure 仮想ネットワーク内に配置します。
次の図に、Spark と Kafka の間の通信フローを示します。
Note
Kafka サービスは、仮想ネットワーク内の通信に制限されます。 SSH や Ambari など、クラスター上の他のサービスは、インターネット経由でアクセスできます。 HDInsight で使用できるパブリック ポートの詳細については、「HDInsight で使用されるポートと URI」を参照してください。
Azure 仮想ネットワークを作成し、その仮想ネットワーク内に Kafka クラスターと Spark クラスターを作成するには、次の手順に従います。
次のボタンを使用して Azure にサインインし、Azure Portal でテンプレートを開きます。

Azure Resource Manager テンプレートは、 https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json にあります。
このテンプレートでは、次のリソースを作成します。
HDInsight 4.0 または 5.0 クラスター上の Kafka。
HDInsight 4.0 または 5.0 クラスター上の Spark 2.4 または 3.1。
Azure Virtual Network (HDInsight クラスターを含む)
重要
このチュートリアルで使用する構造化ストリーミング Notebook では、HDInsight 4.0 または 5.0 上に Spark 2.4 または 3.1 が必要です。 HDInsight 上で以前のバージョンの Spark を使用している場合は、ノートブックを使用するとエラーを受信します。
次の情報に従って、 [カスタマイズされたテンプレート] セクションの各エントリに入力します。
設定 値 サブスクリプション お使いの Azure サブスクリプション Resource group リソースが含まれるリソース グループ。 場所 リソースが作成される Azure リージョン。 [Spark Cluster Name](Spark クラスター名) Spark クラスターの名前。 最初の 6 文字は、Kafka クラスターの名前と異なるものにする必要があります。 [Kafka Cluster Name](Kafka クラスター名) Kafka クラスターの名前。 最初の 6 文字は、Spark クラスターの名前と異なるものにする必要があります。 [Cluster Login User Name](クラスター ログイン ユーザー名) クラスターの管理者ユーザー名。 [クラスター ログイン パスワード] クラスターの管理者ユーザー パスワード。 [SSH ユーザー名] クラスター用に作成する SSH ユーザー。 [SSH パスワード] SSH ユーザーのパスワード。 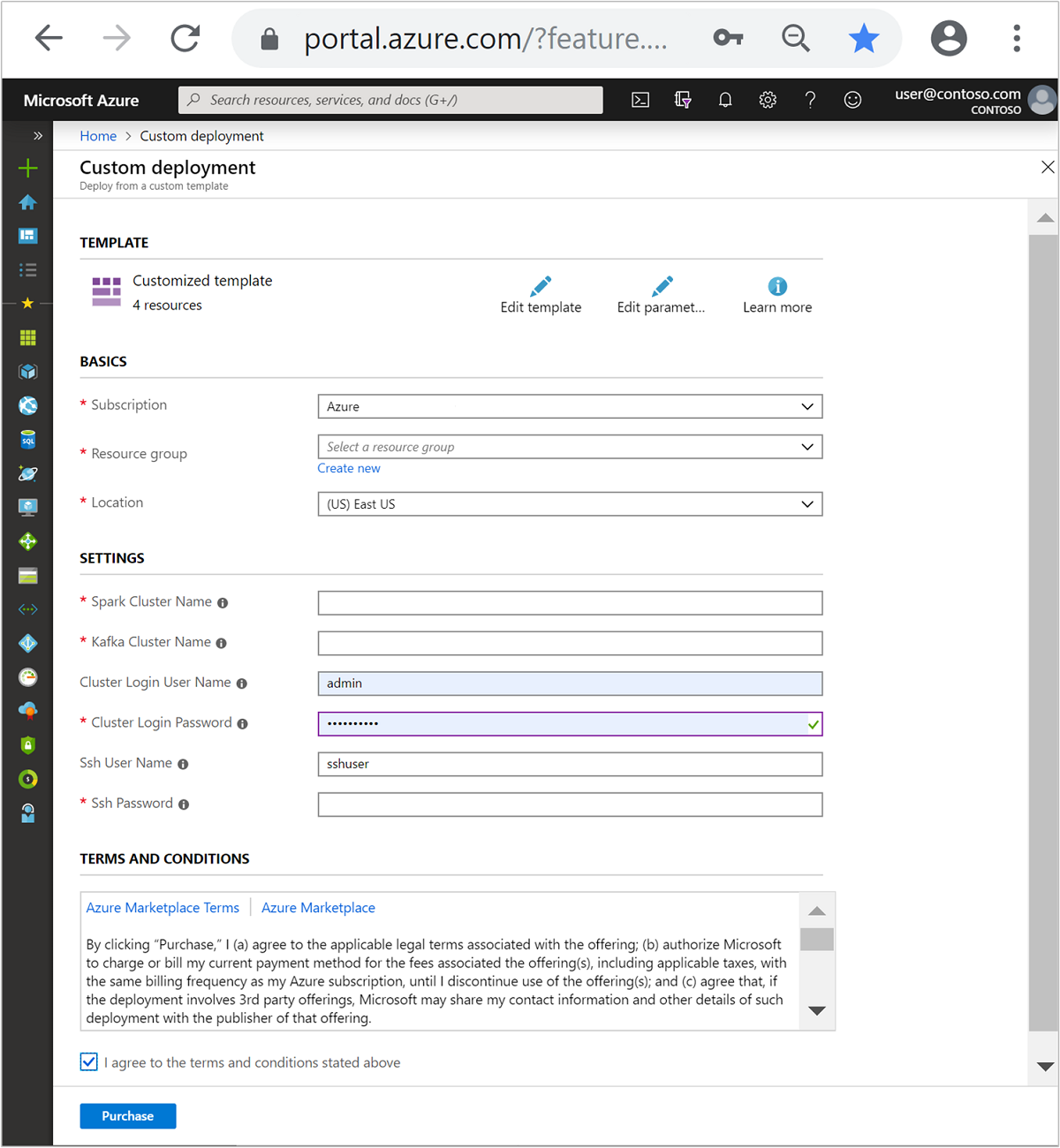
使用条件を読み、 [上記の使用条件に同意する] をオンにします。
[購入] を選択します。
注意
クラスターの作成には最大で 20 分かかります。
Spark 構造化ストリーミングを使用する
この例では、HDInsight 上の Kafka で Spark 構造化ストリーミングを使用する方法を示します。 ここでは、ニューヨーク市が提供しているタクシー乗車データを使用します。 このノートブックで使用されるデータ セットは「2016 Green Taxi Trip Data (2016 年のグリーン タクシー乗車データ)」です。
ホスト情報を収集します。 以下の curl コマンドと jq コマンドを使用して、Kafka ZooKeeper とブローカー ホストの情報を取得します。 これらのコマンドは Windows コマンド プロンプト用に設計されているので、他の環境では若干の調整が必要となります。
KafkaClusterを Kafka クラスターの名前に、KafkaPasswordをクラスターのログイン パスワードに置き換えます。 また、C:\HDI\jq-win64.exeを実際の jq インストールへのパスに置き換えます。 Windows コマンド プロンプトでこれらのコマンドを入力し、後の手順で使用するために出力を保存します。REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"Web ブラウザーから、
https://CLUSTERNAME.azurehdinsight.net/jupyterに移動します。ここで、CLUSTERNAMEはクラスターの名前です。 プロンプトが表示されたら、クラスターの作成時に使用したログイン (管理者) パスワードを入力します。[新規] > [Spark] の順に選択して、ノートブックを作成します。
Spark ストリーミングには、マイクロバッチ処理があります。つまり、データをバッチとして受信し、データのバッチに対して Executor が実行されます。 Executor のアイドル タイムアウトがバッチの処理にかかる時間よりも少ない場合、Executor は常に追加され、削除されます。 Executor のアイドル タイムアウトがバッチ期間より長い場合、Executor は削除されません。 そのため、ストリーミング アプリケーションを実行する場合は、spark.dynamicAllocation.enabled を false に設定して、動的割り当てを無効にすることをお勧めします。
次の情報を Notebook セルに入力して、Notebook で使用されるパッケージを読み込みます。 Ctrl + Enter キーを使用してコマンドを実行します。
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Kafka トピックを作成します。 以下のコマンドに対して、
YOUR_ZOOKEEPER_HOSTSを最初の手順で抽出した Zookeeper ホスト情報で置き換えるという編集を実施します。 編集したコマンドを Jupyter Notebook に入力して、tripdataトピックを作成します。%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersタクシー乗車データを取得します。 次のセルにコマンドを入力して、ニューヨーク市のタクシー乗車データを読み込みます。 データフレームにデータが読み込まれると、そのデータフレームはセルの出力として表示されます。
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Kafka ブローカー ホストの情報を設定します。
YOUR_KAFKA_BROKER_HOSTSを手順 1 で抽出したブローカー ホスト情報に置き換えます。 次の Jupyter Notebook セルに編集したコマンドを入力します。// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Kafka にデータを送信します。 次のコマンドでは、
vendoridフィールドが Kafka メッセージのキー値として使用されています。 このキーは、Kafka でデータをパーティション分割するときに使用されます。 フィールドはすべて JSON 文字列値として Kafka メッセージに格納されます。 Jupyter で次のコマンドを入力し、バッチ クエリを使用して Kafka にデータを保存します。// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")スキーマを宣言します。 次のコマンドは、Kafka から JSON データを読み取るときにスキーマを使用する方法を示しています。 次の Jupyter セルにコマンドを入力します。
// Import bits used for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")データを選択してストリーミングを開始します。 次のコマンドは、バッチ クエリを使用して Kafka からデータを取得する方法を示しています。 次に、Spark クラスター上の HDFS に結果を書き込みます。 この例では、
selectが Kafka からメッセージ (値フィールド) を取得し、そのメッセージにスキーマを適用します。 その後、データは parquet 形式で HDFS (WASB または ADL) に書き込まれます。 次の Jupyter セルにコマンドを入力します。// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")次の Jupyter セルにコマンドを入力することで、ファイルが作成されたことを確認できます。
/example/batchtripdataディレクトリ内のファイルが一覧表示されます。%%bash hdfs dfs -ls /example/batchtripdata前の例ではバッチ クエリが使用されていましたが、以下のコマンドでは、ストリーミング クエリを使用して同じ処理を行う方法を示します。 次の Jupyter セルにコマンドを入力します。
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")次のセルを実行して、ファイルがストリーミング クエリによって書き込まれたことを確認します。
%%bash hdfs dfs -ls /example/streamingtripdata
リソースをクリーンアップする
このチュートリアルで作成したリソースをクリーンアップするために、リソース グループを削除することができます。 リソース グループを削除すると、関連付けられている HDInsight クラスターも削除されます。 さらに、リソース グループに関連付けられている他のリソースも削除されます。
Azure Portal を使用してリソース グループを削除するには:
- Azure portal で左側のメニューを展開してサービスのメニューを開き、 [リソース グループ] を選択して、お使いのリソース グループの一覧を表示します。
- 削除するリソース グループを見つけて、一覧の右側にある [詳細] ボタン ([...]) を右クリックします。
- [リソース グループの削除] を選択し、確認します。
警告
HDInsight クラスターの課金は、クラスターが作成されると開始し、クラスターが削除されると停止します。 課金は分単位なので、クラスターを使わなくなったら必ず削除してください。
HDInsight クラスター上の Kafka を削除すると、Kafka に格納されているすべてのデータが削除されます。