Apache Flink® DataStream API を使用して Azure Data Lake Storage Gen2 にイベント メッセージを書き込む
Note
Azure HDInsight on AKS は 2025 年 1 月 31 日に廃止されます。 2025 年 1 月 31 日より前に、ワークロードを Microsoft Fabric または同等の Azure 製品に移行することで、ワークロードの突然の終了を回避する必要があります。 サブスクリプション上に残っているクラスターは停止され、ホストから削除されることになります。
提供終了日までは基本サポートのみが利用できます。
重要
現在、この機能はプレビュー段階にあります。 ベータ版、プレビュー版、または一般提供としてまだリリースされていない Azure の機能に適用されるその他の法律条項については、「Microsoft Azure プレビューの追加の使用条件」に記載されています。 この特定のプレビューについては、「Microsoft HDInsight on AKS のプレビュー情報」を参照してください。 質問や機能の提案については、詳細を記載した要求を AskHDInsight で送信してください。また、その他の更新については、Azure HDInsight コミュニティのフォローをお願いいたします。
Apache Flink ではファイル システムを使用して、アプリケーションの結果と、フォールト トレランスおよび復旧の両方の目的で、データを使用して永続的に格納します。 この記事では、DataStream API を使用して Azure Data Lake Storage Gen2 にイベント メッセージを書き込む方法について説明します。
前提条件
- HDInsight on AKS の Apache Flink クラスター
- HDInsight の Apache Kafka クラスター
- HDInsight での Apache Kafka の使用に関するページの説明に従って、ネットワーク設定を確実に行う必要があります。 HDInsight on AKS と HDInsight クラスターが同じ仮想ネットワーク内にあることを確認します。
- MSI を使用して ADLS Gen2 にアクセスする
- HDInsight on AKS 仮想ネットワーク上の Azure VM での開発のための IntelliJ
Apache Flink FileSystem コネクタ
このファイルシステム コネクタでは、BATCH と STREAMING の両方で同じ保証が提供され、STREAMING の実行に対して 1 回だけのセマンティクスを提供するように設計されています。 詳細については、Flink DataStream ファイルシステムに関する記事を参照してください。
Apache Kafka コネクタ
Flink には、Kafka トピックとの間でデータを読み書きするための Apache Kafka コネクタが 1 回限りの保証で用意されています。 詳細については、Apache Kafka コネクタに関する記事を参照してください。
Apache Flink 用のプロジェクトをビルドする
IntelliJ IDEA での pom.xml
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
ADLS Gen2 シンク用のプログラム
abfsGen2.java
Note
HDInsight 上の Apache Kafka クラスター bootStrapServers を、Kafka 3.2 用の独自のブローカーに置き換えます
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
jar をパッケージ化して Apache Flink に送信します。
jar を ABFS にアップロードします。
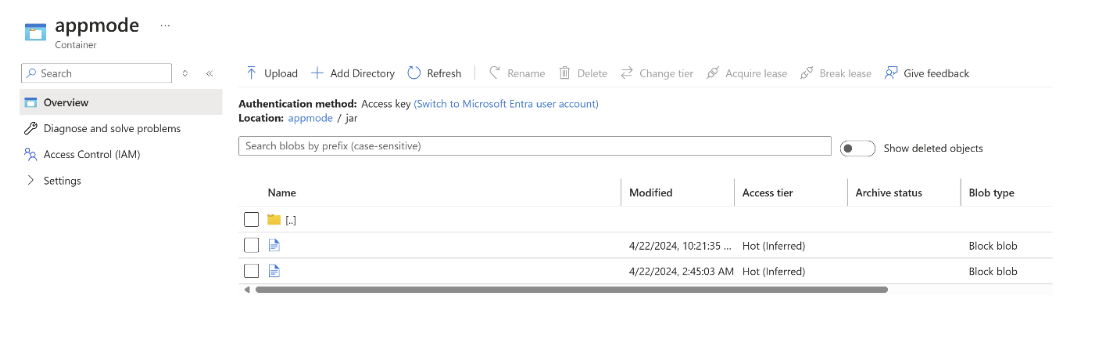
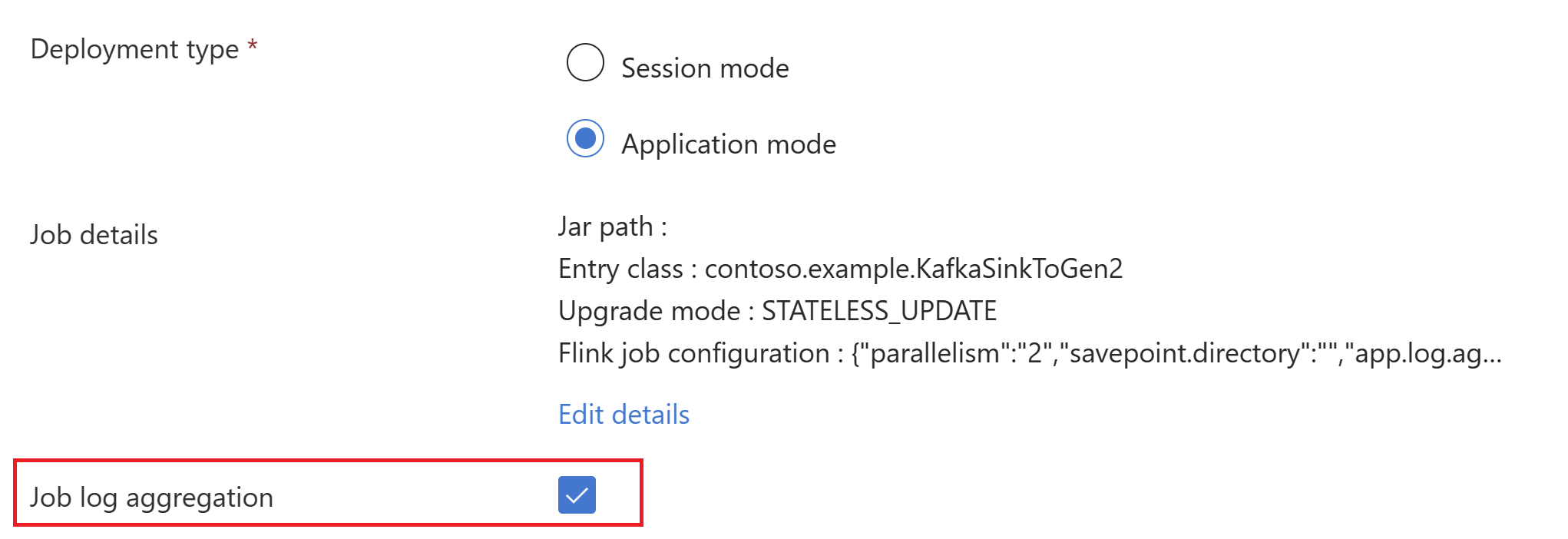
AppModeクラスターの作成でジョブ jar 情報を渡します。
Note
classloader.resolve-order を 'parent-first' として、hadoop.classpath.enable を
trueとして追加してくださいジョブ ログの集計を選択して、ジョブ ログをストレージ アカウントにプッシュします。
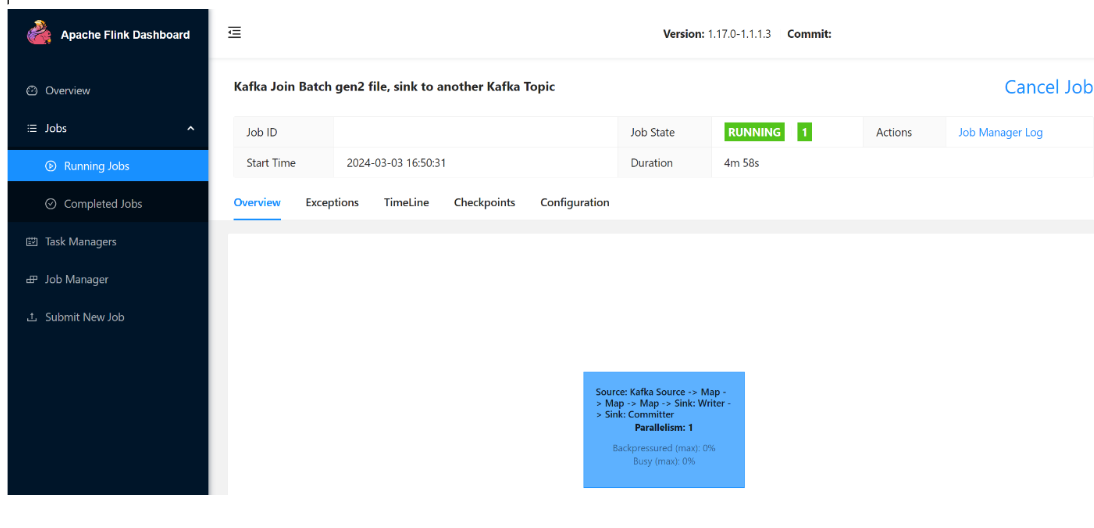
実行中のジョブを確認できます。




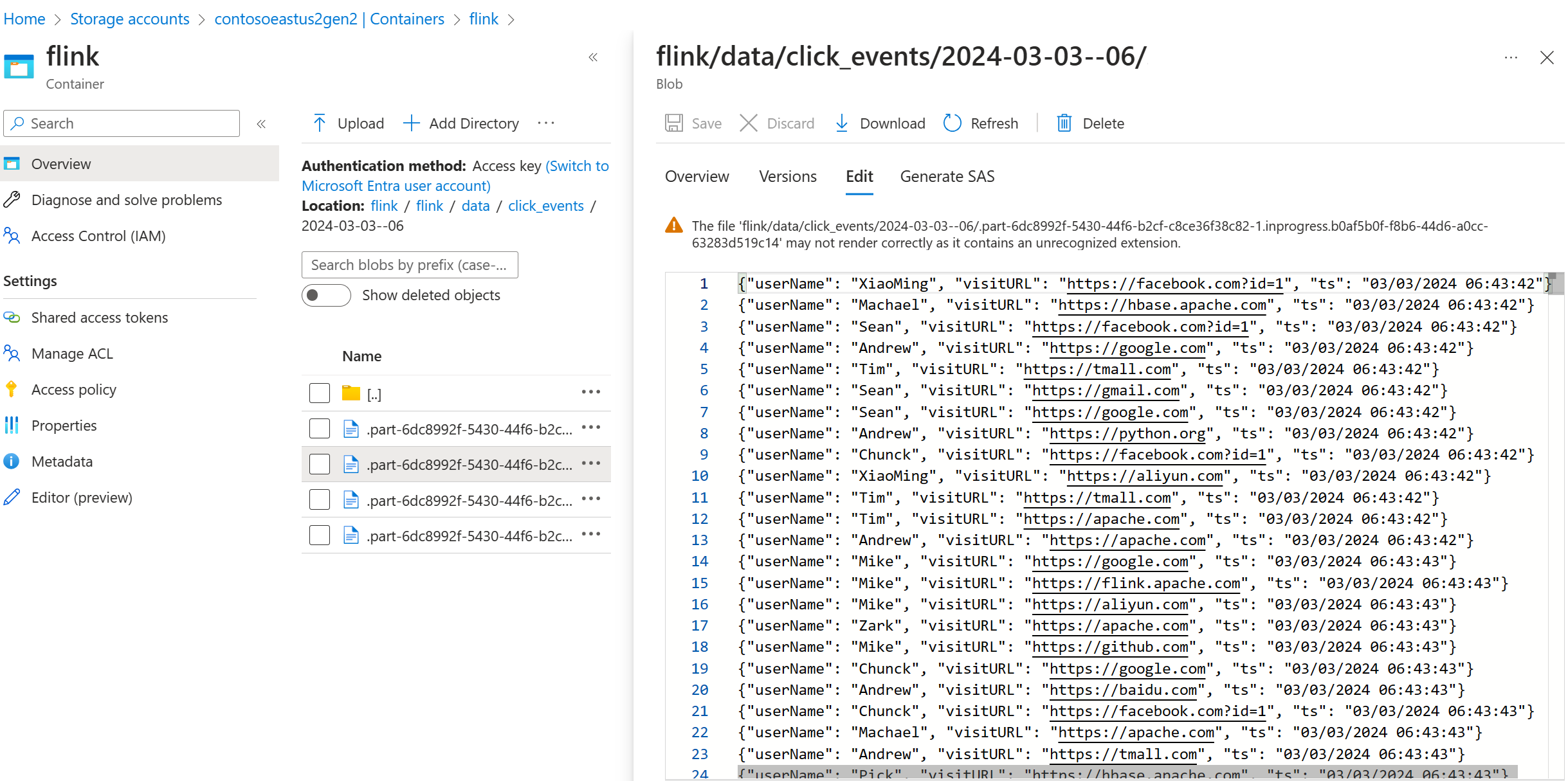
ADLS Gen2 のストリーミング データを検証する
ADLS Gen2 への click_events ストリーミングが表示されています。

進行中のパーツ ファイルを次の 3 つの条件のいずれかでロールするローリング ポリシーを指定できます。
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
リファレンス
- Apache Kafka コネクタ
- Flink DataStream ファイルシステム
- Apache Flink Web サイト
- Apache、Apache Kafka、Kafka、Apache Flink、Flink、関連するオープン ソース プロジェクト名は、Apache Software Foundation (ASF) の商標です。