増分ストリーム処理の理由
今日のデータ主導型企業は継続的にデータを生成します。そのため、このデータを継続的に取り込んで変換するエンジニアリング データ パイプラインが必要になります。 これらのパイプラインは、1 回だけデータを処理して配信し、待機時間が 200 ミリ秒未満の結果を生成し、常にコストを最小限に抑えるようにする必要があります。
この記事では、エンジニアリング データ パイプラインのバッチおよび増分ストリーム処理のアプローチ、増分ストリーム処理の方が優れたオプションである理由、Databricks の増分ストリーム処理オファリング、 Azure Databricks でのストリーミング および Delta Live Tables の概要について説明。 これらの機能を使用すると、配信セマンティクス、待機時間、コストなどを保証するパイプラインをすばやく作成して実行できます。
繰り返されるバッチ ジョブの落とし穴
データ パイプラインを設定するときに、最初に繰り返しバッチ ジョブを書き込んでデータを取り込むことができます。 たとえば、ソースから読み取り、Delta Lake などのシンクにデータを書き込む Spark ジョブを 1 時間ごとに実行できます。 このアプローチの課題は、ソースを段階的に処理することです。これは、1 時間おきに実行される Spark ジョブが最後の 1 つを終了した場所から開始する必要があるためです。 処理したデータの最新のタイムスタンプを記録し、そのタイムスタンプより新しいタイムスタンプを持つすべての行を選択できますが、落とし穴があります。
継続的なデータ パイプラインを実行するには、ソースから増分読み取り、変換を実行し、Delta Lake などのシンクに結果を書き込む 1 時間ごとのバッチ ジョブをスケジュールしてみてください。 このアプローチには、次のような落とし穴が考えられます。
- タイムスタンプの後にすべての新しいデータを照会する Spark ジョブは、遅延データを見落とします。
- 失敗した Spark ジョブは、慎重に処理しないと、1 回だけ保証が解除される可能性があります。
- 新しいファイルを見つけるためのクラウド ストレージの場所の内容を一覧表示する Spark ジョブは、コストがかかります。
その後も、このデータを繰り返し変換する必要があります。 バッチ ジョブを繰り返し記述してデータを集計したり、他の操作を適用したりすると、パイプラインの効率がさらに複雑になり、効率が低下します。
バッチの例
パイプラインのバッチ インジェストと変換の落とし穴を完全に理解するには、次の例を検討してください。
見落とされたデータ
顧客に請求する金額を決定する使用状況データを含む Kafka トピックとパイプラインがバッチで取り込まれている場合、イベントのシーケンスは次のようになります。
- 最初のバッチには、午前 8 時と午前 8 時 30 分に 2 つのレコードがあります。
- 最新のタイムスタンプを午前 8 時 30 分に更新します。
- 午前 8 時 15 分に別のレコードを取得します。
- 午前 8 時 30 分以降のすべての 2 番目のバッチ クエリ 、午前 8 時 15 分にレコードが見落とされます。
さらに、ユーザーの過大請求や過大請求は行わないので、すべてのレコードを 1 回だけ取り込む必要があります。
冗長処理
次に、データにユーザー購入の行が含まれており、ストアで最も人気のある時間を把握できるように、1 時間あたりの売上を集計するとします。 同じ時間の購入が異なるバッチで到着した場合、同じ時間の出力を生成する複数のバッチがあります。
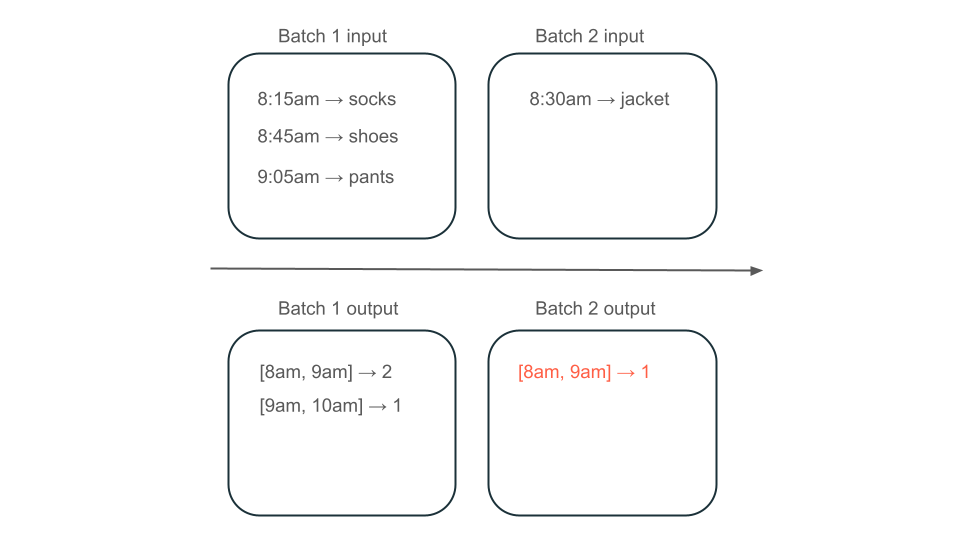
午前 8 時から午前 9 時のウィンドウには、2 つの要素 (バッチ 1 の出力)、1 つの要素 (バッチ 2 の出力)、または 3 つ (バッチなしの出力) がありますか? 特定の時間枠を生成するために必要なデータは、変換の複数のバッチにわたって表示されます。 これを解決するには、データを日単位でパーティション分割し、結果を計算する必要があるときにパーティション全体を再処理します。 次に、シンクの結果を上書きできます。
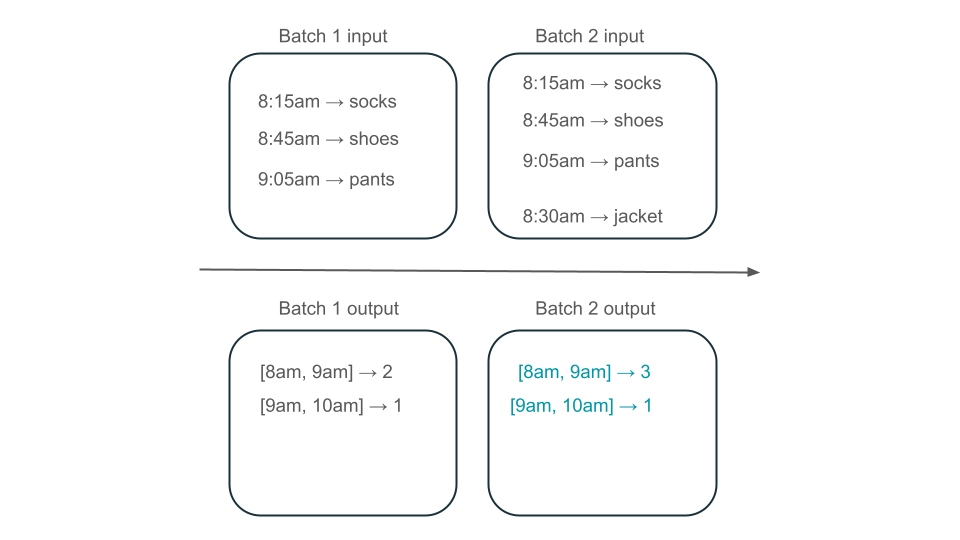
ただし、2 番目のバッチでは、既に処理されている可能性があるデータを処理する不要な処理を行う必要があるため、待機時間とコストが発生します。
増分ストリーム処理による落とし穴なし
増分ストリーム処理により、データを取り込んで変換するバッチ ジョブの繰り返しの落とし穴をすべて簡単に回避できます。 Databricks 構造化ストリーミング および Delta ライブ テーブル ストリーミングの実装の複雑さを管理して、ビジネス ロジックだけに集中できるようにします。 接続するソース、データに対して実行する変換、および結果を書き込む場所を指定するだけで済みます。
インジェストの増分
Databricks での増分インジェストは、Apache Spark Structured Streaming を利用します。これは、データソースを増分的に使用してシンクに書き込むことができます。 構造化ストリーミング エンジンはデータを 1 回だけ消費でき、エンジンは順序の正しいデータを処理できます。 エンジンは、ノートブックで実行することも、Delta Live Tables のストリーミング テーブルを使用して実行することもできます。
Databricks の Structured Streaming エンジンには、コスト効率の高い方法でクラウド ファイルを段階的に処理できる AutoLoader などの独自のストリーミング ソースが用意されています。 Databricks には、 Apache Kafka、 Google Kinesis、 Apache Pulsar、 Google Pub/Sub などの他の一般的なメッセージ バス用のコネクタも用意されています。
増分変換
構造化ストリーミングを使用した Databricks の増分変換を使用すると、バッチ クエリと同じ API を使用して DataFrames への変換を指定できますが、時間の経過と共にバッチと集計された値の間でデータが追跡されるため、必要ありません。 データを再処理する必要がないため、バッチ ジョブを繰り返すよりも高速でコスト効率が高くなります。 構造化ストリーミングでは、Delta Lake、Kafka、その他のサポートされているコネクタなど、シンクに追加できるデータのストリームが生成されます。
Delta Live Tables の具体化されたビュー は、酵素エンジンを搭載しています。 酵素はソースを段階的に処理しますが、ストリームを生成する代わりに、 具体化されたビューを作成します。これは、指定したクエリの結果を格納する事前計算済みのテーブルです。 酵素は、新しいデータがクエリの結果に与える影響を効率的に判断でき、事前に計算されたテーブルを最新の状態に保ちます。
具体化されたビューでは、集計に対するビューが作成され、常に効率的に更新されます。たとえば、上記のシナリオでは、午前 8 時から午前 9 時のウィンドウに 3 つの要素があることを確認できます。
構造化ストリーミング テーブルまたはデルタ ライブ テーブル
構造化ストリーミング テーブルと差分ライブ テーブルの大きな違いは、ストリーミング クエリを運用化する方法です。 Structured Streaming では、多数の構成を手動で指定し、クエリを手動で結合する必要があります。 クエリを明示的に開始し、クエリが終了するのを待ち、失敗した場合に取り消す、その他のアクションを実行する必要があります。 Delta Live Tables では、パイプラインを実行するように宣言によって Delta Live テーブルを指定し、実行を維持します。
デルタ ライブ テーブルには、データの変換を効率的かつ段階的に事前計算する Materialized Views などの機能もあります。
これらの機能の詳細については、「 Azure Databricks でのストリーミング と Delta Live Tables とはを参照してください。
次のステップ
Delta Live Tables を使用して最初のパイプラインを作成します。 「チュートリアル: 最初の Delta Live Tables パイプラインを実行する」を参照してください。
Databricks で最初の構造化ストリーミング クエリを実行します。 「 最初の構造化ストリーミング ワークロードを実行するを参照してください。
具体化されたビューを使用します。 「Databricks SQL の具体化されたビューを使用する」を参照してください。