Databricks での AI および機械学習の概要
この記事では、Mosaic AI (旧 Databricks Machine Learning) に用意されている AI および ML システムの構築に役立つツールについて説明します。 この図は、Databricks プラットフォームのさまざまな製品が、AI および ML システムを構築してデプロイするためのエンド ツー エンド ワークフローの実装にどのように役立つかを示しています
Databricks における生成 AI
Mosaic AI は、データ収集と準備から、モデル開発と LLMOps、サービス提供と監視に至るまで、AI のライフサイクルを統合します。 次の機能は、特に生成 AI アプリケーションの開発を促進するために最適化されています。
- データ、機能、モデル、関数を対象にした、ガバナンス、検出、バージョン管理、アクセス制御のための Unity Catalog。
- モデル開発追跡用の MLflow。
- LLM を展開するための Mosaic AI Model Serving。 特に生成 AI モデルにアクセスするためのモデル提供エンドポイントを構成できます。
- Foundation Model API を使用した最新のオープン LLM。
- Databricks の外部でホストされているサードパーティ モデル。 「Mosaic AI Model Serving の外部モデル」を参照してください。
- Mosaic AI ベクトル検索には、埋め込みベクトルを保存するクエリ可能なベクトル データベースが用意されており、ナレッジ ベースと自動的に同期するように構成できます。
- 推論テーブルによる自動ペイロード ログを使って、データの監視と、モデルの予測品質とドリフトを追跡するためのレイクハウス監視。
- Databricks ワークスペースから生成 AI モデルをテストするための AI プレイグラウンド。 システム プロンプトや推論パラメーターなどの設定をプロンプト表示、比較、調整することができます。
- 独自のデータを使用して基礎モデルをカスタマイズし 特定のアプリケーションのパフォーマンスを最適化するための Foundation Model Fine-tuning (現在はモザイク AI モデル トレーニングの一部)。
- 取得拡張生成 (RAG) アプリケーションなどの運用品質のエージェントを構築して配置する Mosaic AI エージェント フレームワーク。
- RAG アプリケーションやチェーンを含め、生成 AI アプリケーションの品質、コスト、待機時間を評価する Mosaic AI エージェント評価。
生成 AI とは
生成 AI は、画像、テキスト、コード、合成データなどのコンテンツを作成するためにモデルを使用するコンピューターの機能に焦点を当てた人工知能の一種です。
生成 AI アプリケーションは、生成 AI モデル (大規模言語モデル (LLM) や基盤モデル) 上に構築されます。
- LLM は、優れた言語処理タスクを行うために膨大なデータセットを消費してトレーニングを行うディープ ラーニング モデルです。 LLM は、そのトレーニング データに基づいて、自然言語を模倣した新しいテキストの組み合わせを作成します。
- 生成 AI モデルまたは基礎モデル は、より具体的な言語理解と生成タスクのために微調整されることを意図して事前トレーニングされた大規模な ML モデルです。 これらのモデルは、入力データのパターンを識別するために使用されます。
これらのモデルは、学習プロセスを完了した後、一緒にプロンプトが表示されたときに統計的に確率の高い出力を生成し、次のようなさまざまなタスクを達成するために採用できます。
- 既存の画像に基づく画像生成、またはある画像のスタイルを利用して新しい画像を修正または作成します。
- 文字起こし、翻訳、質問と回答の生成、テキストの意図や意味の解釈などの音声タスク。
重要
多くの LLM やその他の生成型 AI モデルにはセーフガードが用意されていますが、それでも有害、または不正確な情報が生成される可能性があります。
生成 AI には、次の設計パターンがあります。
- プロンプト エンジニアリング: LLM の動作のガイド専用のプロンプトの作成
- 検索拡張生成 (RAG): LLM と外部ナレッジの検索の組み合わせ
- 微調整: ドメインの特定のデータ セットへの事前トレーニング済み LLM の適応
- 事前トレーニング: LLM のゼロからのトレーニング
Databricks での機械学習
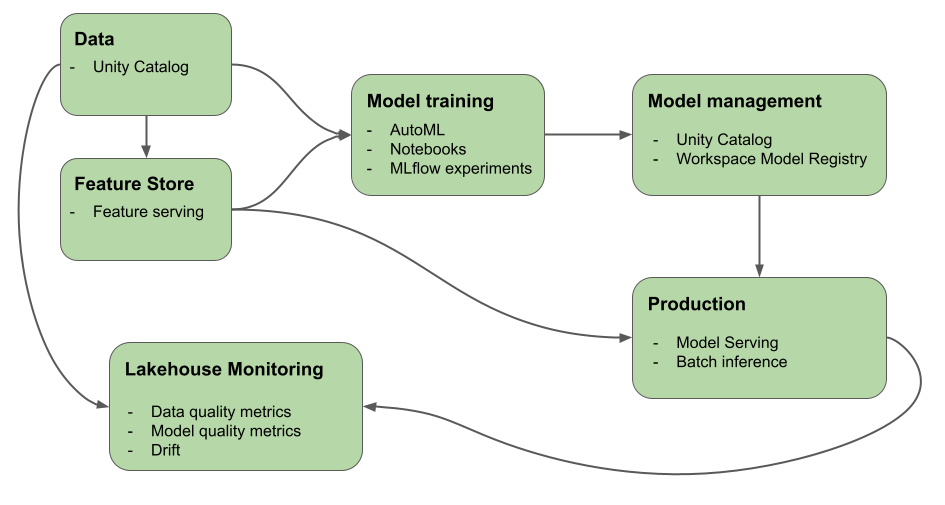
Databricks を使うと、生データから、提供されるモデルのすべての要求と応答が保存される推論テーブルまで、ML の開発とデプロイのすべてのステップが、1 つのプラットフォームで提供されます。 データ サイエンティスト、データ エンジニア、ML エンジニア、DevOps は、同じツール セットと、データの信頼できる唯一の情報源を使って、自分の仕事を行うことができます。
Mosaic AI は、データレイヤーと ML プラットフォームを統合します。 モデルや関数など、すべてのデータ資産と成果物は、1 つのカタログで検出でき、管理されます。 データとモデルに 1 つのプラットフォームを使うと、生データから運用モデルまでの系列を追跡できます。 組み込まれたデータとモデル モニタリングは、プラットフォームにも格納されるテーブルに品質メトリックを保存するため、モデルのパフォーマンスの問題の根本原因を簡単に特定できます。 Databricks が ML の完全なライフサイクルと MLOps をサポートする方法について詳しくは、「Azure Databricks での MLOps ワークフロー」と「MLOps スタック: コードとしてのモデル開発プロセス」をご覧ください。
データ インテリジェンス プラットフォームの主要なコンポーネントの一部を次に示します。
| タスク | コンポーネント |
|---|---|
| データ、機能、モデル、特徴量のガバナンスと管理。 検出、バージョン管理、系列も。 | Unity Catalog |
| データ、データ品質、モデル予測品質の変化を追跡する | レイクハウス監視、推論テーブル |
| 特徴の開発と管理 | 特徴エンジニアリングとサービス提供。 |
| モデルをトレーニングする | AutoML、 Databricks ノートブック |
| モデル開発の追跡 | MLflow 追跡 |
| カスタム モデルを提供する | Mosaic AI Model Serving |
| 自動化されたワークフローと運用対応の ETL パイプラインの構築 | Databricks ジョブ |
| Git 統合 | Databricks Git フォルダー |
Databricks でのディープ ラーニング
ディープ ラーニング アプリケーションのインフラストラクチャを構成することは容易でない場合があります。 Databricks Runtime for Machine Learning は、TensorFlow、PyTorch、Keras などの最も一般的なディープ ラーニング ライブラリの互換性のあるバージョンが組み込まれたクラスターを使用して、これを処理します。
Databricks Runtime ML クラスターには、ドライバーとサポート ライブラリを含む、事前に構成された GPU サポートも組み込まれています。 また、ML ワークフローや ML アプリケーションをスケーリングするための計算処理を並列化する Ray のようなライブラリもサポートしています。
Databricks Runtime ML クラスターには、ドライバーとサポート ライブラリを含む、事前に構成された GPU サポートも組み込まれています。 Mosaic AI Model Serving を使用すると、追加の構成なしでディープ ラーニング モデル用のスケーラブルな GPU エンドポイントを作成できます。
機械学習アプリケーションの場合、Databricks では、Databricks Runtime for Machine Learning を実行するクラスターを使用することをお勧めします。 「Databricks Runtime ML を使用してクラスターを作成する」を参照してください。
Databricks でディープ ラーニングを開始するには、以下を参照してください。
次の手順
作業を開始するには、次のトピックをご覧ください。
Databricks Mosaic AI の推奨 MLOps ワークフローについては、次を参照してください。
Databricks Mosaic AI の主な機能については、以下を参照してください。