アダプティブ クエリの実行
アダプティブ クエリ実行 (AQE) は、クエリの実行中に行われるクエリの再最適化です。
実行時に再最適化を行う理由は、Azure Databricks では、シャッフルおよびブロードキャスト交換 (AQE ではクエリ ステージと呼ばれます) の最後に最新の正確な統計情報が得られることにあります。 その結果、Azure Databricks では、より優れた物理戦略を選択する、最適なシャッフル後のパーティションのサイズと数を選択する、ヒントを必要としていた (スキュー結合処理など) 最適化を実行する、などの操作を行うことができます。
これは、統計情報の収集がオンになっていない場合や統計情報が古くなっている場合に非常に役立ちます。 また、複雑なクエリの途中やデータ スキューの発生後など、静的に導出された統計情報が不正確な状況でも役立ちます。
機能
AQE は既定で有効になっています。 4 つの主要な機能があります。
- 並べ替えマージ結合をブロードキャスト ハッシュ結合に動的に変更します。
- シャッフル交換後、パーティションを動的に結合します (小さなパーティションを妥当なサイズのパーティションに結合します)。 非常に小さなタスクは I/O スループットが低く、スケジューリングのオーバーヘッドとタスク設定のオーバーヘッドにより影響を受けやすい傾向があります。 小さなタスクを結合することで、リソースを節約し、クラスターのスループットを向上させることができます。
- 偏りのあるタスクをほぼ均等なサイズのタスクに分割 (および必要に応じて複製) することにより、並べ替えマージ結合およびシャッフル ハッシュ結合でスキューを動的に処理します。
- 空の関係を動的に検出して伝達します。
Application
AQE は、次のすべてのクエリに適用されます。
- 非ストリーミング
- 少なくとも 1 つの交換 (通常、結合、集計、またはウィンドウがある場合)、1 つのサブクエリ、またはその両方を含む。
AQE が適用されたすべてのクエリが必ずしも再最適化されるとは限りません。 再最適化の結果、静的にコンパイルされたクエリ プランとは異なるクエリ プランが作成される場合と作成されない場合があります。 クエリのプランが AQE によって変更されたかどうかを判断するには、次の「クエリ プラン」を参照してください。
クエリ プラン
このセクションでは、さまざまな方法でクエリ プランを調べる方法について説明します。
このセクションの内容は次のとおりです。
Spark UI
AdaptiveSparkPlan ノード
AQE が適用されたクエリには、通常、各メイン クエリまたはサブクエリのルート ノードとして、1 つ以上の AdaptiveSparkPlan ノードが含まれます。
クエリが実行される前または実行されているとき、対応する AdaptiveSparkPlan ノードの isFinalPlan フラグは false として表示されます。クエリの実行が完了すると、isFinalPlan フラグは true. に変わります
進展するプラン
クエリ プラン ダイアグラムは、実行の進行と共に進展して、実行されている最新のプランを反映します。 (メトリックが使用可能な) 既に実行されているノードは変化しませんが、実行されていないノードについては、再最適化の結果として時間の経過と共に変化する可能性があります。
クエリ プラン ダイアグラムの例を次に示します。
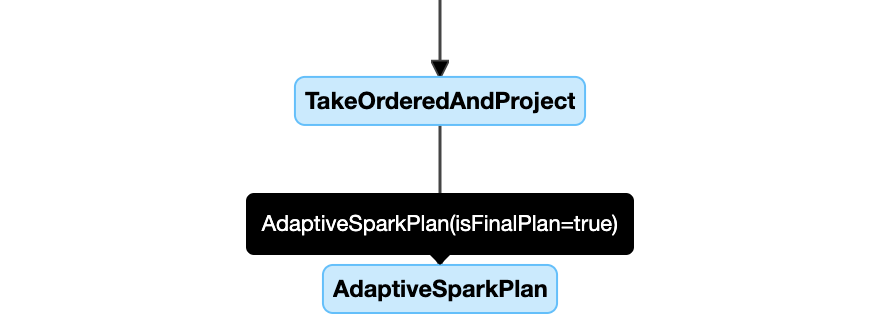
DataFrame.explain()
AdaptiveSparkPlan ノード
AQE が適用されたクエリには、通常、各メイン クエリまたはサブクエリのルート ノードとして、1 つ以上の AdaptiveSparkPlan ノードが含まれます。 クエリが実行される前または実行されているとき、対応する AdaptiveSparkPlan ノードの isFinalPlan フラグは false として表示されます。クエリの実行が完了すると、isFinalPlan フラグは true に変わります。
現在のプランと初期プラン
各ノード AdaptiveSparkPlan の下には、実行が完了したかどうかに応じて、初期プラン (AQE 最適化を適用する前のプラン) と、現在のプランまたは最終プランの両方があります。 現在のプランは、実行の進行と共に進展します。
実行時統計情報
各シャッフル ステージとブロードキャスト ステージには、データ統計情報が含まれます。
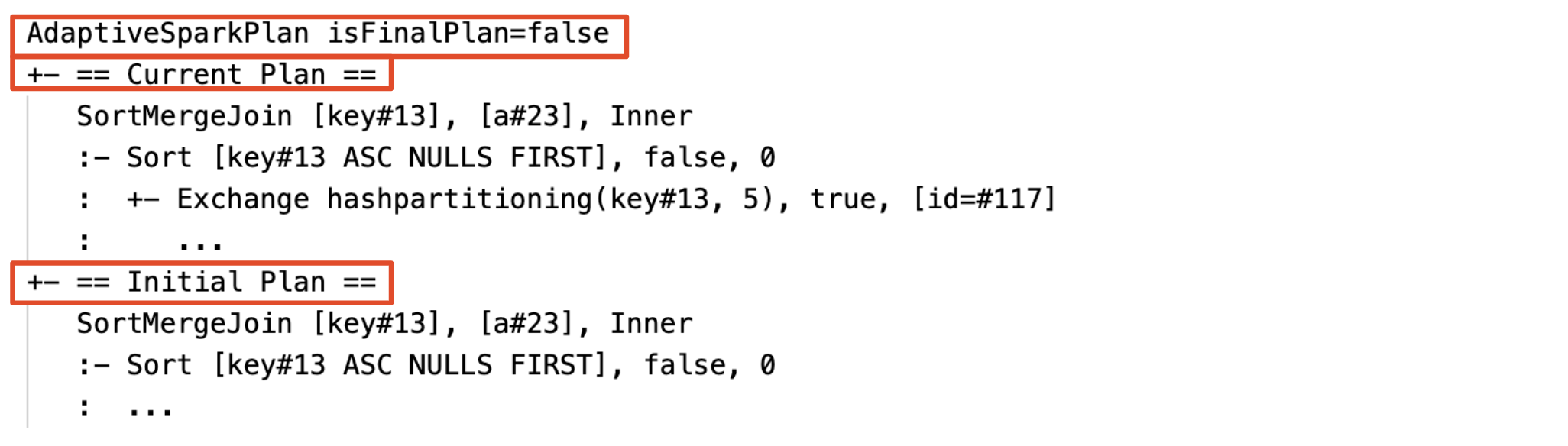
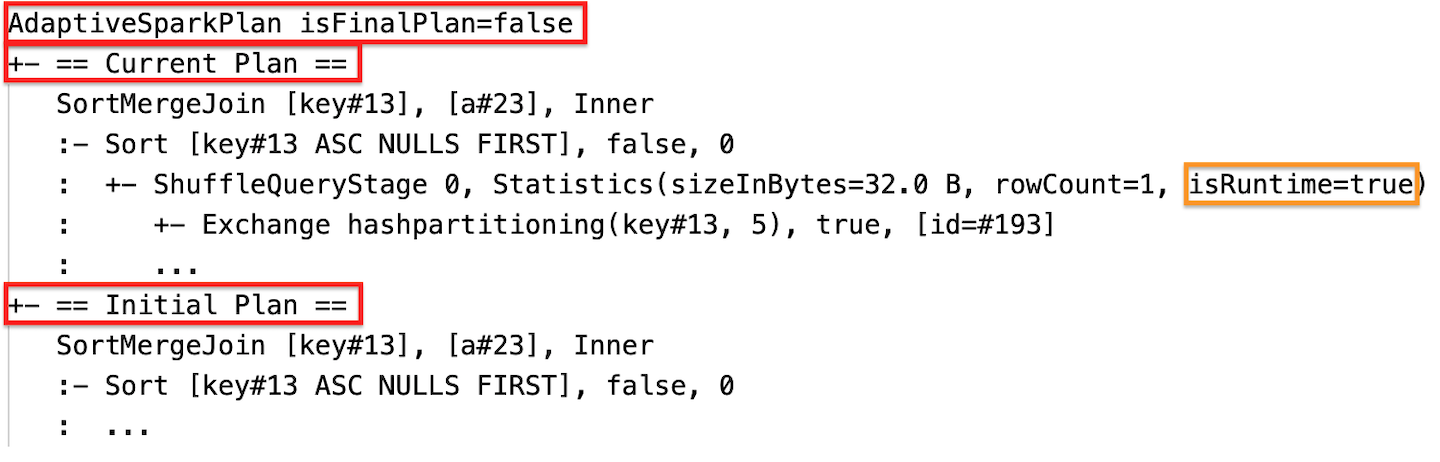
ステージが実行される前または実行されているとき、統計情報はコンパイル時の推定値を表し、フラグ isRuntime は false になります (例: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);)
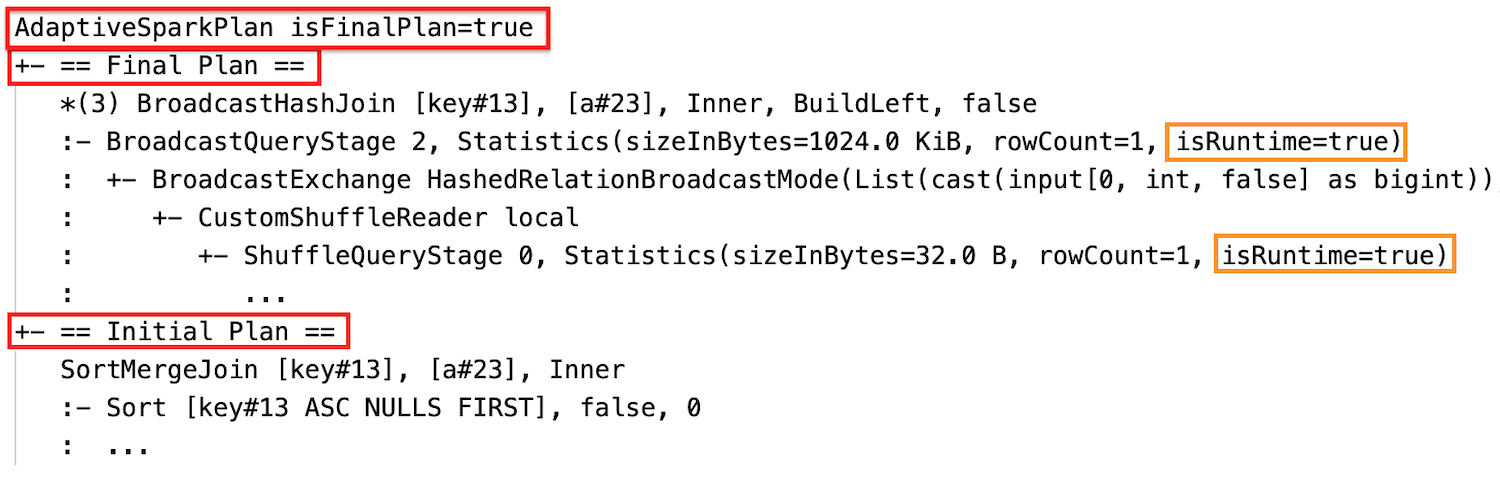
ステージの実行が完了した後、統計情報は実行時に収集されたものを表し、フラグ isRuntime は true になります (例: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true))
DataFrame.explain の例を次に示します。
実行前
実行中
実行後
SQL EXPLAIN
AdaptiveSparkPlan ノード
AQE が適用されたクエリには、通常、各メイン クエリまたはサブクエリのルート ノードとして、1 つ以上の AdaptiveSparkPlan ノードが含まれます。
現在のプランなし
SQL EXPLAIN ではクエリが実行されないため、現在のプランは常に初期プランと同じになり、AQE によって最終的に実行される内容を反映しません。
SQL explain の例を次に示します。

有効性
クエリ プランは、1 つ以上の AQE 最適化が有効になると変更されます。 これらの AQE 最適化による効果は、現在のプランと最終プラン、および現在のプランと最終プランの初期プラン ノードと特定のプラン ノードの相違によって示されます。
並べ替えマージ結合をブロードキャスト ハッシュ結合に動的に変更する: 現在のプランまたは最終プランと初期プランとの間で物理結合ノードが異なります
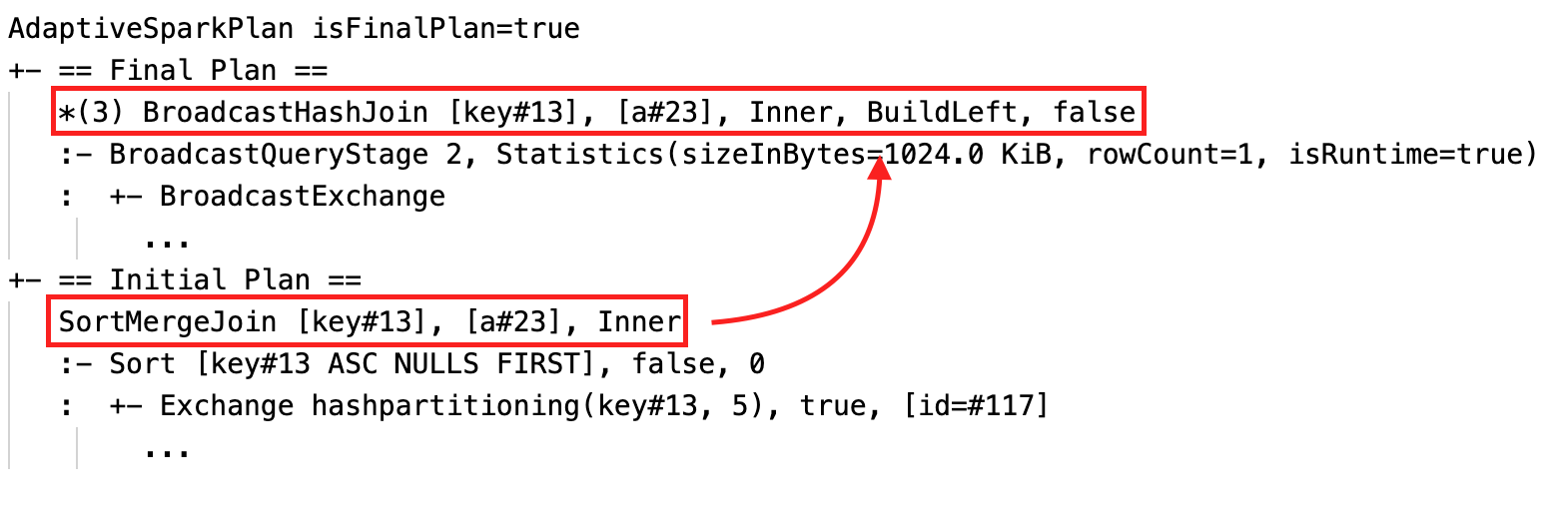
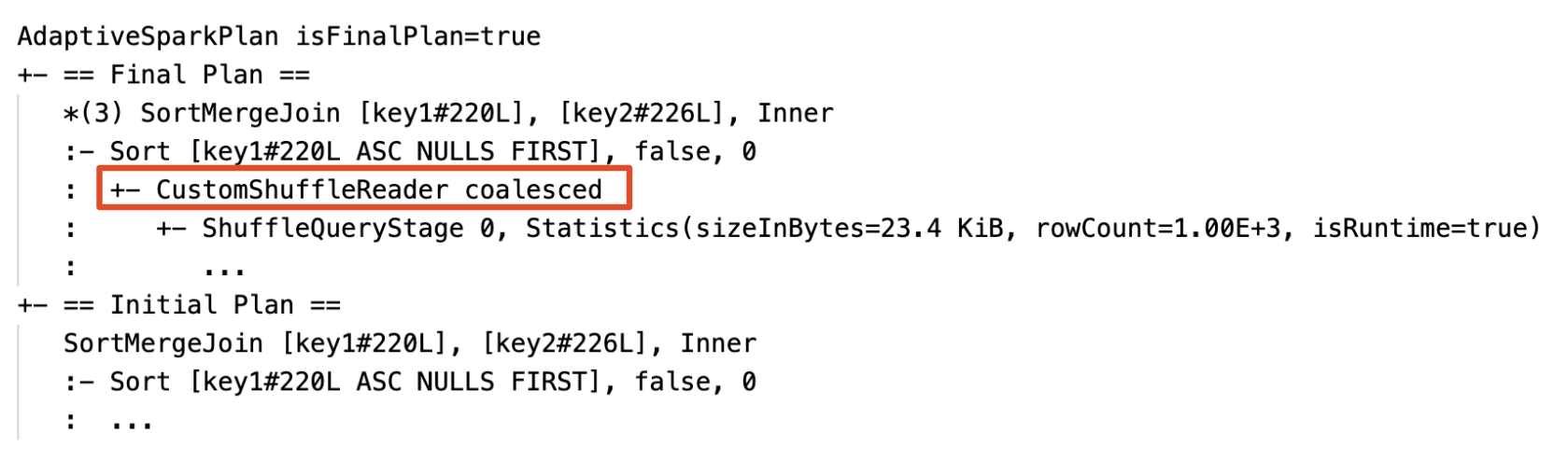
パーティションを動的に結合する: ノード
CustomShuffleReaderのプロパティがCoalescedとして示されます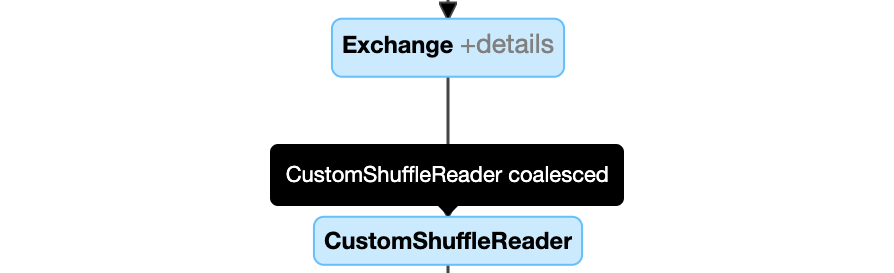
スキュー結合を動的に処理する: ノード
SortMergeJoinのフィールドisSkewが true として示されます。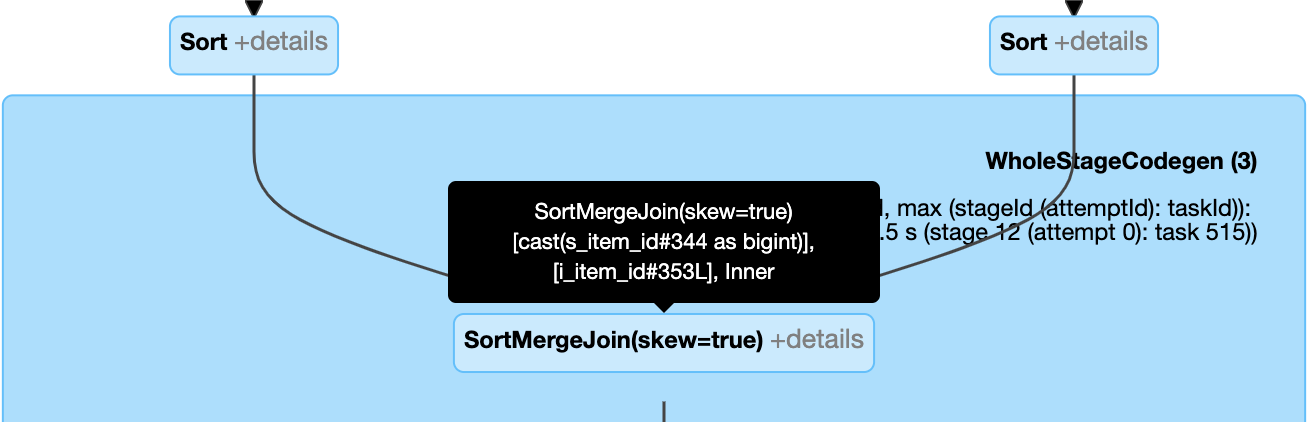
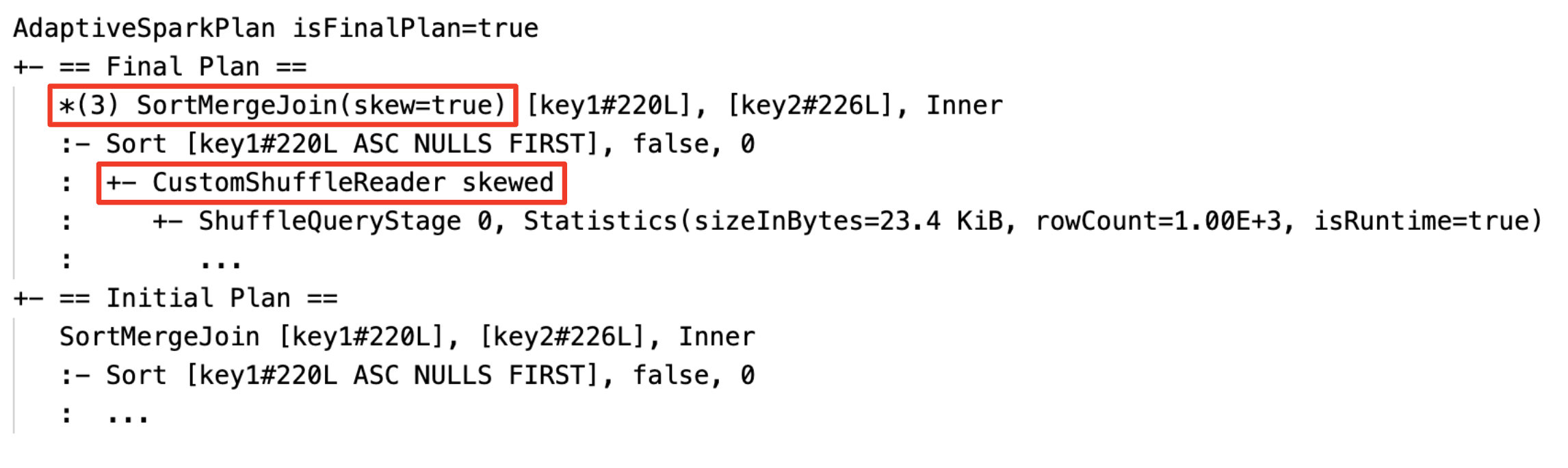
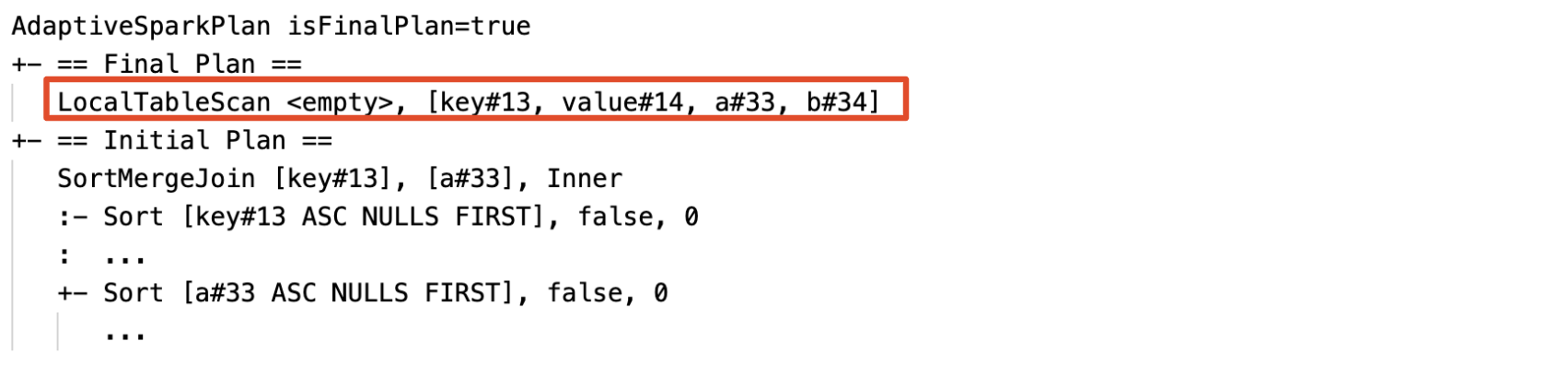
空の関係を動的に検出して伝達する: プランの一部 (または全体) が、関係フィールドが空のノード LocalTableScan に置き換えられます。
構成
このセクションの内容は次のとおりです。
- アダプティブ クエリ実行を有効または無効にする
- 自動最適化シャッフルを有効にする
- 並べ替えマージ結合をブロードキャスト ハッシュ結合に動的に変更する
- パーティションを動的に結合する
- スキュー結合を動的に処理する
- 空の関係を動的に検出して伝達する
アダプティブ クエリ実行を有効または無効にする
| プロパティ |
|---|
| spark.databricks.optimizer.adaptive.enabled 次のコマンドを入力します: Booleanアダプティブ クエリ実行を有効にするか、無効にするか。 既定値: true |
自動最適化シャッフルを有効にする
| プロパティ |
|---|
| spark.sql.shuffle.partitions 次のコマンドを入力します: Integer結合または集計のためにデータをシャッフルする際に使用する既定のパーティション数。 値 auto を設定すると、自動最適化シャッフルが有効になり、クエリ プランとクエリ入力データ サイズに基づいて、この数値が自動的に決定されます。注: 構造化ストリーミングの場合は、同じチェックポイントの場所からクエリを再起動する間に、この構成を変更できません。 既定値:200 |
並べ替えマージ結合をブロードキャスト ハッシュ結合に動的に変更する
| プロパティ |
|---|
| spark.databricks.adaptive.autoBroadcastJoinThreshold 次のコマンドを入力します: Byte String実行時にブロードキャスト結合への切り替えをトリガーするしきい値。 既定値: 30MB |
パーティションを動的に結合する
| プロパティ |
|---|
| spark.sql.adaptive.coalescePartitions.enabled 次のコマンドを入力します: Booleanパーティションの結合を有効にするか、無効にするか。 既定値: true |
| spark.sql.adaptive.advisoryPartitionSizeInBytes 次のコマンドを入力します: Byte String結合後のターゲット サイズ。 結合されたパーティションのサイズは、このターゲット サイズに近くなりますが、これより大きくなることはありません。 既定値: 64MB |
| spark.sql.adaptive.coalescePartitions.minPartitionSize 次のコマンドを入力します: Byte String結合後のパーティションの最小サイズ。 結合したパーティションのサイズは、このサイズ以上になります。 既定値: 1MB |
| spark.sql.adaptive.coalescePartitions.minPartitionNum 次のコマンドを入力します: Integer結合後のパーティションの最小数。 この設定は次のものを明示的にオーバーライドするため、推奨されません: spark.sql.adaptive.coalescePartitions.minPartitionSize既定値: 2 x クラスター コアの数 |
スキュー結合を動的に処理する
| プロパティ |
|---|
| spark.sql.adaptive.skewJoin.enabled 次のコマンドを入力します: Booleanスキュー結合処理を有効にするか、無効にするか。 既定値: true |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor 次のコマンドを入力します: Integerパーティションが偏っているかどうかを判断するために使用される、パーティション サイズの中央値にかける係数。 既定値: 5 |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 次のコマンドを入力します: Byte Stringパーティションが偏っているかどうかを判断するために使用されるしきい値。 既定値: 256MB |
(partition size > skewedPartitionFactor * median partition size) と (partition size > skewedPartitionThresholdInBytes) の両方が true の場合、パーティションは偏っていると見なされます。
空の関係を動的に検出して伝達する
| プロパティ |
|---|
| spark.databricks.adaptive.emptyRelationPropagation.enabled 次のコマンドを入力します: Boolean動的な空の関係の伝達を有効にするか、無効にするか。 既定値: true |
よく寄せられる質問 (FAQ)
このセクションの内容は次のとおりです。
- AQE によって小さな結合テーブルがブロードキャストされなかったのはなぜですか?
- AQE が有効な場合でもブロードキャスト結合戦略のヒントを使用する必要がありますか?
- スキュー結合のヒントと AQE スキュー結合最適化の違いは何ですか? 使用する方法の選択
- AQE によって結合順序が自動的に調整されなかったのはなぜですか?
- AQE によってデータ スキューが検出されなかったのはなぜですか?
AQE によって小さな結合テーブルがブロードキャストされなかったのはなぜですか?
ブロードキャストされると予想される関係のサイズがこのしきい値を下回っているにもかかわらずブロードキャストされない場合:
- 結合の種類を確認します。 ブロードキャストは、特定の種類の結合でサポートされていません。たとえば、
LEFT OUTER JOINの左側の関係はブロードキャストできません。 - また、関係に多数の空のパーティションが含まれている場合もあります。その場合、ほとんどのタスクは、並べ替えマージ結合で即座に終了するか、スキュー結合処理によって最適化される可能性があります。 空でないパーティションの割合が
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoinより小さい場合、このような並べ替えマージ結合は AQE によってブロードキャスト ハッシュ結合に変更されません。
AQE が有効な場合でもブロードキャスト結合戦略のヒントを使用する必要がありますか?
はい。 静的に計画されたブロードキャスト結合は、通常、AQE によって動的に計画された結合よりもパフォーマンスが高くなります。これは、結合の両側でシャッフルを実行するまで (実際の関係のサイズが取得されるまで) AQE によるブロードキャスト結合への切り替えが行われない場合があるためです。 したがって、クエリについてよく理解している場合は、ブロードキャスト ヒントの使用は依然として良い選択肢となります。 AQE では、静的な最適化の場合と同様にクエリ ヒントが考慮されますが、依然としてヒントの影響を受けない動的最適化を適用することができます。
スキュー結合のヒントと AQE スキュー結合最適化の違いは何ですか? 使用する方法の選択
AQE のスキュー結合は完全に自動化されており、一般論として、ヒントの対応するものよりもパフォーマンスが優れているため、スキュー結合ヒントを使用するよりも、AQE スキュー結合処理を使用することをお勧めします。
AQE によって結合順序が自動的に調整されなかったのはなぜですか?
動的結合の順序変更は AQE の一部ではありません。
AQE によってデータ スキューが検出されなかったのはなぜですか?
AQE がパーティションをスキュー パーティションとして検出するには、次の 2 つのサイズ条件が満たされる必要があります。
- パーティション サイズが
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(既定値は 256 MB) より大きい - パーティション サイズが、すべてのパーティションの中央値にスキュー パーティション係数
spark.sql.adaptive.skewJoin.skewedPartitionFactor(既定値は 5) をかけた値よりも大きい
さらに、スキュー処理のサポートは特定の結合の種類に対して制限されています。たとえば、LEFT OUTER JOIN では、左側のスキューのみを最適化できます。
従来
"アダプティブ実行" という用語は Spark 1.6 から存在しますが、Spark 3.0 の新しい AQE は根本的に異なります。 機能面では、Spark 1.6 では、"パーティションを動的に結合する" 部分のみが実行されます。 技術アーキテクチャの面では、新しい AQE は、実行時統計に基づくクエリの動的な計画および再計画のフレームワークであり、この記事で説明したようなさまざまな最適化をサポートし、より多くの潜在的な最適化を可能にするために拡張できます。