ワークスペース モデル レジストリの例
Note
このドキュメントでは、ワークスペース モデル レジストリについて説明します。 Azure Databricks では、Unity Catalog のモデルの使用をお勧めしています。 Unity Catalog のモデルには、一元化されたモデル ガバナンス、クロスワークスペース アクセス、系列、デプロイが備わっています。 ワークスペース モデル レジストリは、今後非推奨となる予定です。
この例では、ワークスペース モデル レジストリを使用して、風力発電所の毎日の電力出力を予測する機械学習アプリケーションをビルドする方法を示します。 この例では、次のことを行っています。
- MLflow によるモデルの追跡とログ記録
- モデル レジストリへのモデルの登録
- モデルの記述と、モデル バージョンのステージ移行
- 登録済みモデルと運用アプリケーションの統合
- モデル レジストリでのモデルの検索と検出
- モデルのアーカイブと削除
この記事では、MLflow Tracking および MLflow モデル レジストリの UI と API を使用して、これらの手順を実行する方法について説明します。
MLflow Tracking およびレジストの API を使用してこれらすべての手順を実行するノートブックについては、「モデル レジストリの例のノートブック」を参照してください。
MLflow Tracking によるデータセットの読み込み、モデルのトレーニング、追跡
モデルをモデル レジストリに登録する前に、まず、実験の実行時にモデルのトレーニングとログ記録を行う必要があります。 このセクションでは、風力発電所のデータセットを読み込み、モデルをトレーニングして、トレーニングの実行のログを MLflow に記録する方法を示します。
データセットを読み込む
次のコードは、気象データと米国内の風力発電所の電力出力情報を含むデータセットをロードします。 このデータセットには、6 時間ごと (wind direction に 1 回、wind speed に 1 回、air temperature に 1 回) にサンプリングされる 00:00、08:00、16:00 の各特徴と、数年間にわたる 1 日の合計電力出力 (power) が含まれます。
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
モデルをトレーニングする
次のコードは、データセット内の気象の特徴に基づいて電力出力を予測できるように、TensorFlow Keras を使用してニューラル ネットワークをトレーニングします。 MLflow は、モデルのハイパーパラメーター、パフォーマンス メトリック、ソース コード、成果物を追跡するために使用されます。
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
MLflow UI を使用してモデルを登録し管理する
このセクションの内容は次のとおりです。
新しい登録済みモデルを作成する
Azure Databricks ノートブックの右側のサイドバーで [実験] アイコン
![[実験] アイコン](../_static/images/icons/experiment.png) をクリックして、MLflow 実験実行サイドバーに移動します。
をクリックして、MLflow 実験実行サイドバーに移動します。
TensorFlow Keras モデル トレーニング セッションに対応する MLflow 実行を見つけ、[実行の詳細を表示] アイコンをクリックして MLflow 実行 UI で開きます。
MLflow UI で、[成果物] セクションまで下にスクロールし、model という名前のディレクトリをクリックします。 表示された [モデルの登録] ボタンをクリックします。

ドロップダウン メニューから [新しいモデルの作成] を選択し、モデル名として
power-forecasting-modelを入力します。[登録] をクリックします。 これにより、
power-forecasting-modelという名前の新しいモデルが登録され、新しいモデル バージョンVersion 1が作成されます。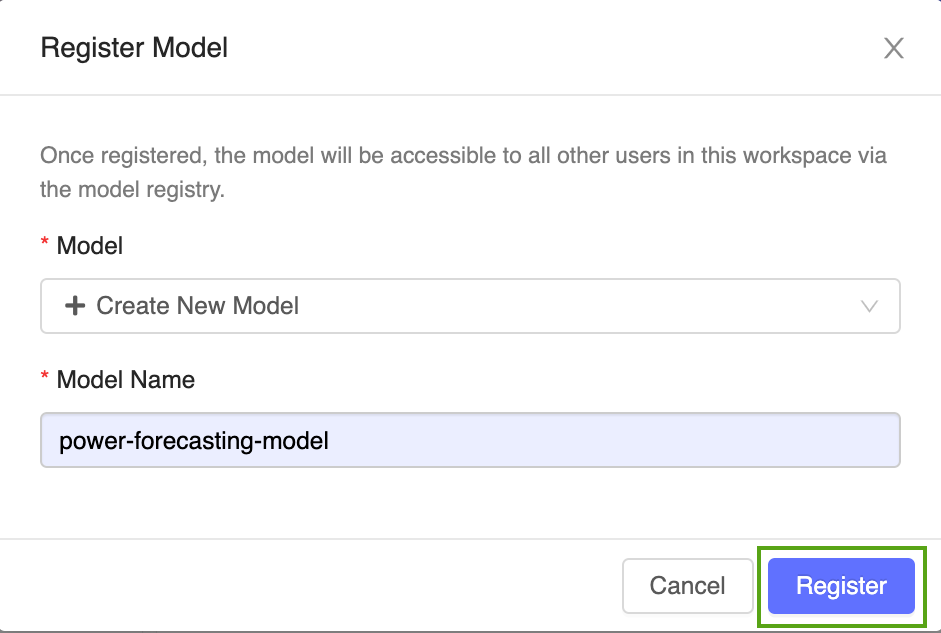
しばらくすると、MLflow UI に、新しい登録済みモデルへのリンクが表示されます。 このリンクに従って、MLflow モデル レジストリ UI で新しいモデル バージョンを開きます。
モデル レジストリ UI を調べる
MLflow モデル レジストリ UI のモデル バージョンのページには、作成者、作成日時、現在のステージなど、登録済みの予測モデルの Version 1 に関する情報が表示されます。
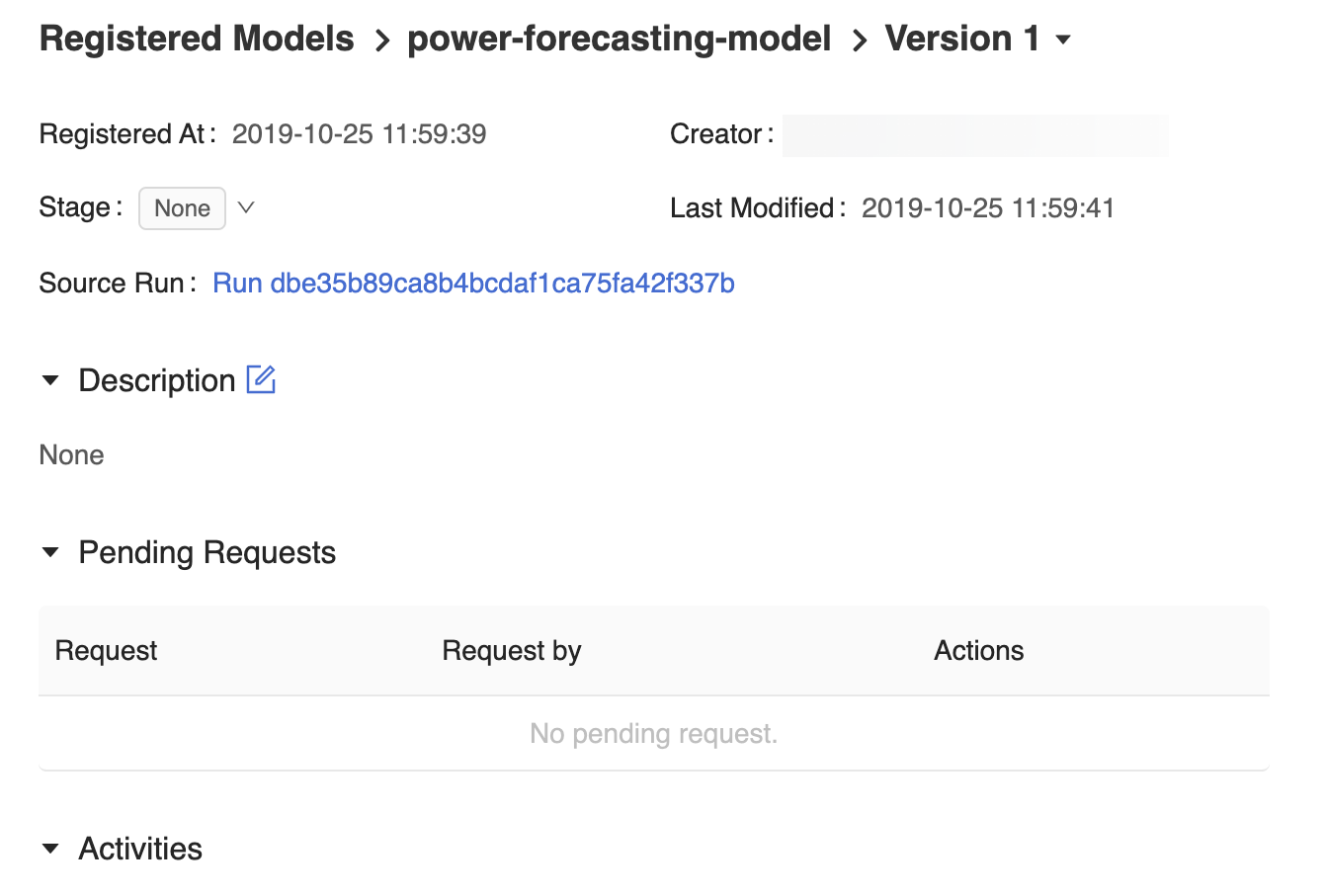
また、モデル バージョンのページでは、[ソースの実行] リンクも提供されます。これにより、MLflow 実行 UI でモデルを作成するために使用した MLflow 実行が開きます。 MLflow 実行 UI から、[ソース] ノートブック リンクにアクセスして、モデルのトレーニングに使用された Azure Databricks ノートブックのスナップショットを表示できます。


MLflow モデル レジストリに戻るには、サイド バーの ![]() [モデル] をクリックします。
[モデル] をクリックします。
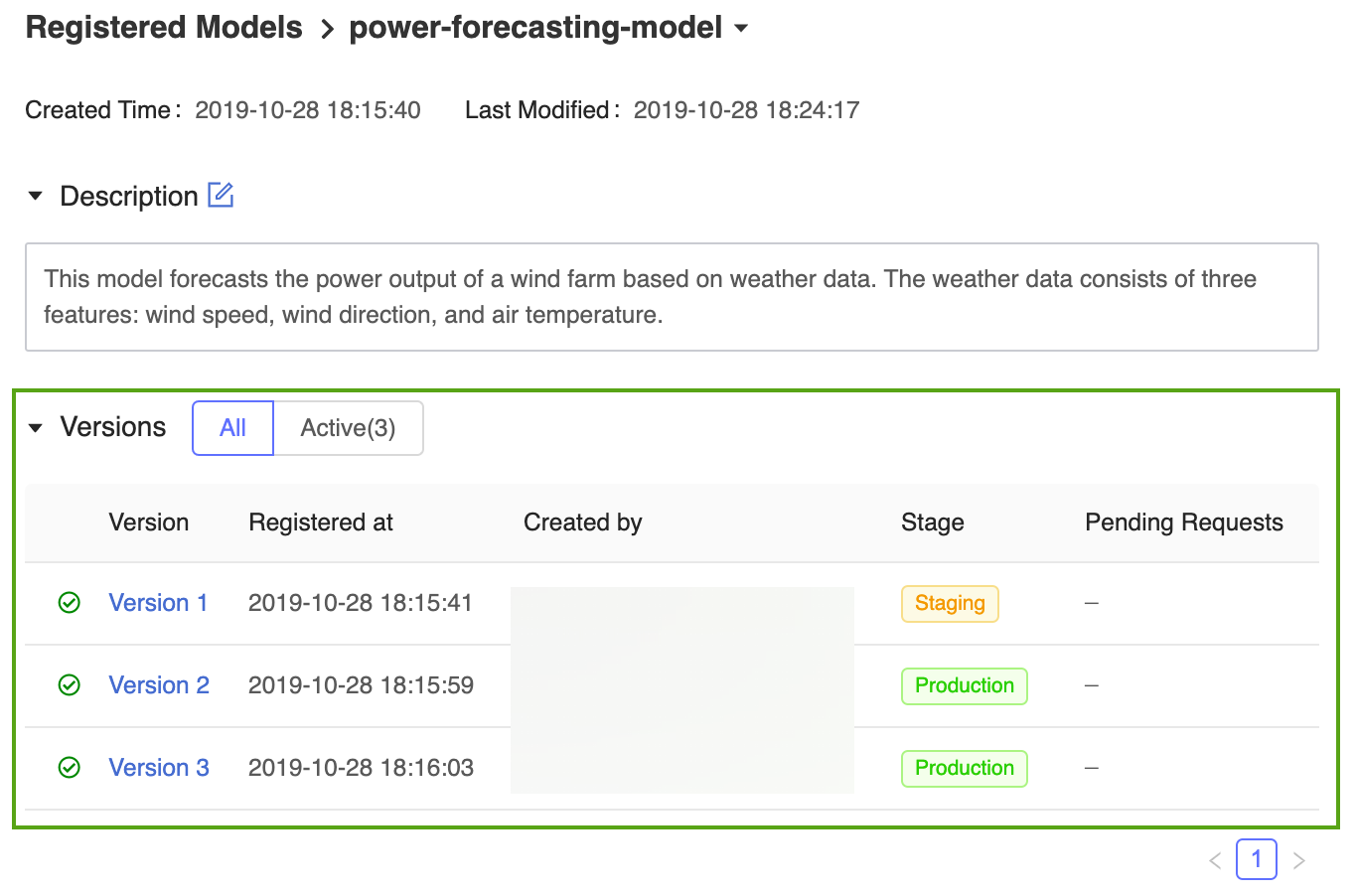
結果として表示される MLflow モデル レジストリのホーム ページには、Azure Databricks ワークスペースに登録されているすべてのモデルの一覧が表示されます。その中には、それらのバージョンとステージも含まれます。
[電力予測モデル] リンクをクリックして、登録済みモデルのページを開くと、その予測モデルのすべてのバージョンが表示されます。
モデルの説明を追加する
登録済みモデルおよびモデル バージョンに説明を追加できます。 登録済みモデルの説明は、複数のモデル バージョンに適用される情報 (たとえば、モデリングの問題やデータセットの一般的な概要など) を記録するのに役立ちます。 モデル バージョンの説明は、特定のモデル バージョンに固有の属性 (たとえば、モデルの開発に使用された手法やアルゴリズムなど) を詳細に説明するために役立ちます。
登録済み電力予測モデルの概要を追加します。
![[編集] アイコン](../_static/images/icons/edit-icon.png) アイコンをクリックして、次の説明を入力します。
アイコンをクリックして、次の説明を入力します。This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.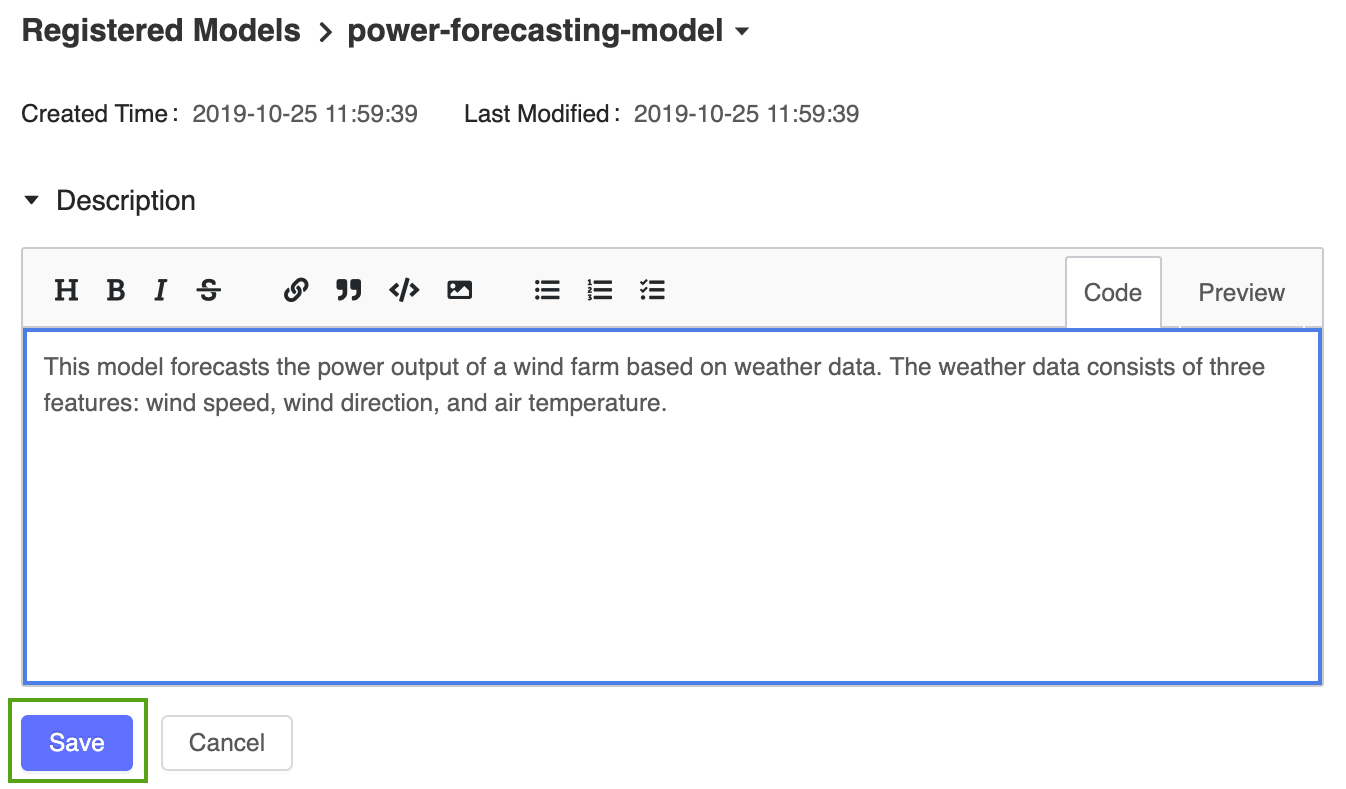
[保存] をクリックします。
登録済みモデルのページで [Version 1] リンクをクリックして、モデル バージョン ページに戻ります。
- アイコンをクリックして、次の説明を入力します。
This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.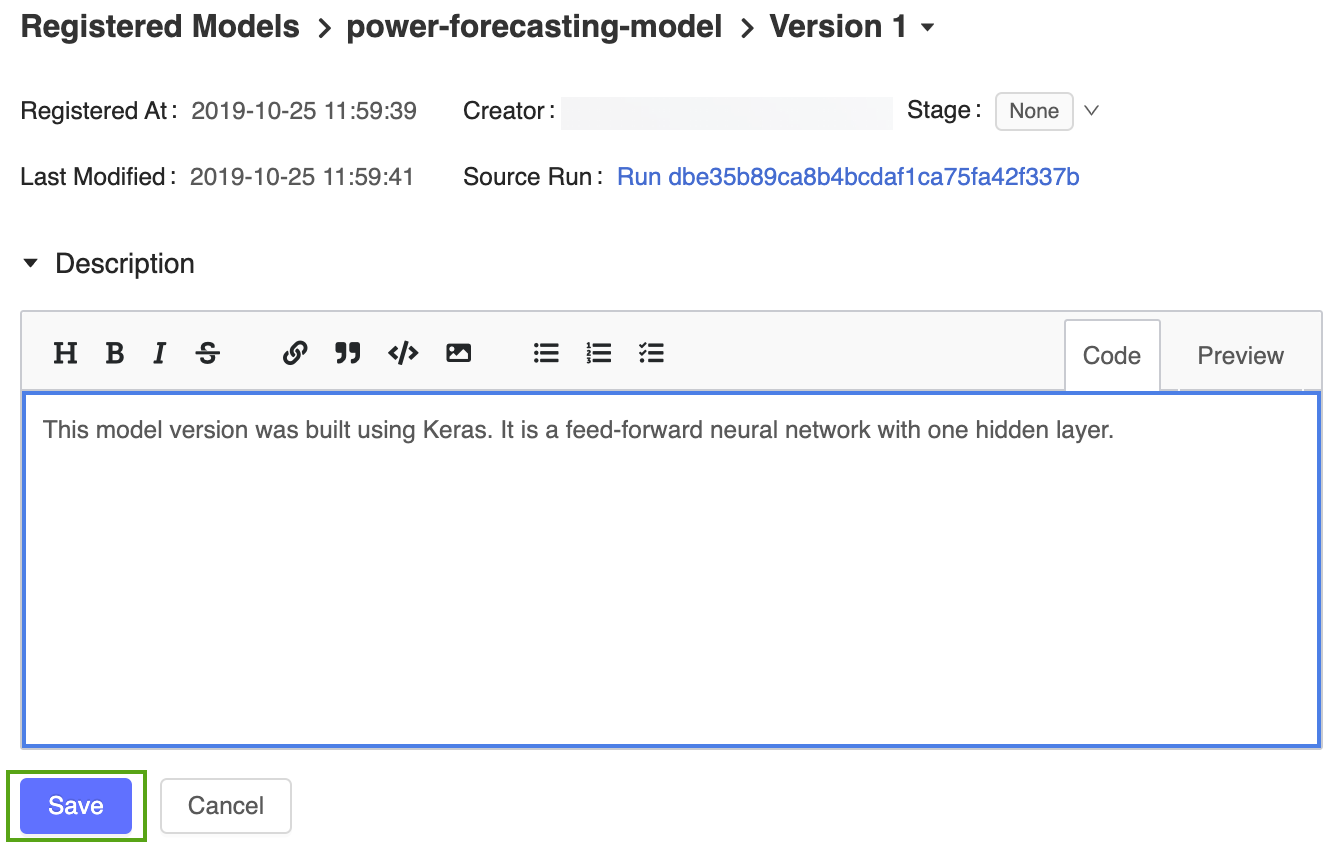
[保存] をクリックします。
モデル バージョンを移行する
MLflow モデル レジストリでは、なし、ステージング、運用、Archived という複数のモデル ステージが定義されています。 各ステージには、固有の意味があります。 たとえば、ステージングはモデルのテストを目的としており、運用は、テストまたはレビューのプロセスを完了し、アプリケーションにデプロイされたモデルを意味します。
[ステージ] ボタンをクリックすると、使用可能なモデル ステージと使用可能なステージ移行オプションの一覧が表示されます。
[移行先] -> [運用]の順に選択し、[ステージ移行の確認] ウィンドウで [OK] をクリックして、モデルを [運用] に移行します。

モデル バージョンを 運用に移行すると、現在のステージが UI に表示され、移行を反映するためにアクティビティ ログにエントリが追加されます。


MLflow モデル レジストリでは、複数のモデル バージョンで同じステージを共有できます。 モデルをステージ別に参照する場合、モデル レジストリでは、最新のモデル バージョン (バージョン ID が最大のモデル バージョン) が使用されます。 登録済みモデルのページには、特定のモデルのすべてのバージョンが表示されます。
MLflow API を使用してモデルを登録し管理する
このセクションの内容は次のとおりです。
プログラムでモデルの名前を定義する
モデルを登録し、運用に移行したので、MLflow API を使用してプログラムでモデルを参照することができます。 登録済みモデルの名前を次のように定義します。
model_name = "power-forecasting-model"
モデルを登録する
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
API を使用してモデルとモデル バージョンの説明を追加する
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
API を使用してモデル バージョンを移行し、詳細を取得する
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
API を使用して登録済みモデルのバージョンを読み込む
MLflow モデル コンポーネントでは、複数の機械学習フレームワークからモデルを読み込むための関数が定義されています。 たとえば、MLflow 形式で保存された TensorFlow モデルを読み込むには、mlflow.tensorflow.load_model() を使用します。また、MLflow 形式で保存された scikit-learn モデルを読み込むには、mlflow.sklearn.load_model() を使用します。
これらの関数は、モデルを MLflow モデル レジストリから読み込むことができます。
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
運用モデルを使用して電力出力を予測する
このセクションでは、運用モデルを使用して、風力発電所の天気予報データを評価します。 forecast_power() アプリケーションでは、指定されたステージから予測モデルの最新バージョンを読み込み、それを使用して、今後 5 日間の電力生産を予測します。
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
新しいモデル バージョンを作成する
従来の機械学習手法は、電力予測にも有効です。 次のコードでは、scikit-learn を使用してランダム フォレスト モデルをトレーニングし、mlflow.sklearn.log_model() 関数を使用して MLflow モデル レジストリに登録します。
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
MLflow モデル レジストリの検索を使用して新しいモデル バージョン ID をフェッチする
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
新しいモデル バージョンに説明を追加する
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
新しいモデル バージョンをステージングに移行してモデルをテストする
多くの場合、モデルを運用アプリケーションにデプロイする前に、ベスト プラクティスとしてステージング環境でテストすることをお勧めします。 次のコードでは、新しいモデル バージョンをステージングに移行し、そのパフォーマンスを評価します。
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
新しいモデル バージョンを運用環境にデプロイする
ステージングで新しいモデル バージョンが十分なパフォーマンスであることを確認した後、次のコードで、モデルを運用に移行し、「運用モデルを使用して電力出力を予測する」セクションとまったく同じアプリケーション コードを使用して、電力予測を生成します。
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
以上で、予測モデルの 2 つのバージョン (Keras モデルでトレーニングされたモデル バージョンと scikit-learn でトレーニングされたバージョン) が運用 ステージにあります。

Note
モデルをステージ別に参照する場合、MLflow モデル レジストリでは、最新の運用バージョンが自動的に使用されます。 これにより、アプリケーション コードを変更せずに運用モデルを更新できます。
モデルのアーカイブと削除
モデル バージョンを使用する必要がなくなったら、アーカイブまたは削除することができます。 また、登録済みモデル全体を削除することもできます。その場合、関連付けられているすべてのモデル バージョンが削除されます。
電力予測モデルの Version 1 をアーカイブする
電力予測モデルの Version 1 を使用する必要がなくなったため、それをアーカイブします。 モデルは、MLflow モデル レジストリ UI 内で、または MLflow API を使用してアーカイブすることができます。
MLflow UI で Version 1 をアーカイブする
電力予測モデルの Version 1 をアーカイブするには、次の操作を行います。
MLflow モデル レジストリ UI で対応するモデル バージョンのページを開きます。

[ステージ] ボタンをクリックして、[移行先] -> [アーカイブ済み] の順に選択します。
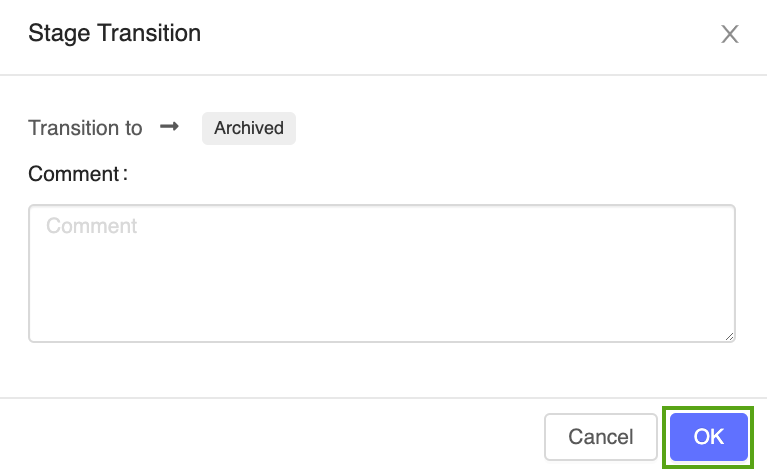
ステージ移行確認ウィンドウで [OK] をクリックします。

MLflow API を使用して Version 1 をアーカイブする
次のコードでは、MlflowClient.update_model_version() 関数を使用して、電力予測モデルの Version 1 をアーカイブします。
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
電力予測モデルの Version 1 を削除する
MLflow UI または MLflow API を使用してモデル バージョンを削除することもできます。
警告
モデル バージョンは完全に削除され、元に戻すことはできません。
MLflow UI で Version 1 を削除する
電力予測モデルの Version 1 を削除するには、次の操作を行います。
MLflow モデル レジストリ UI で対応するモデル バージョンのページを開きます。
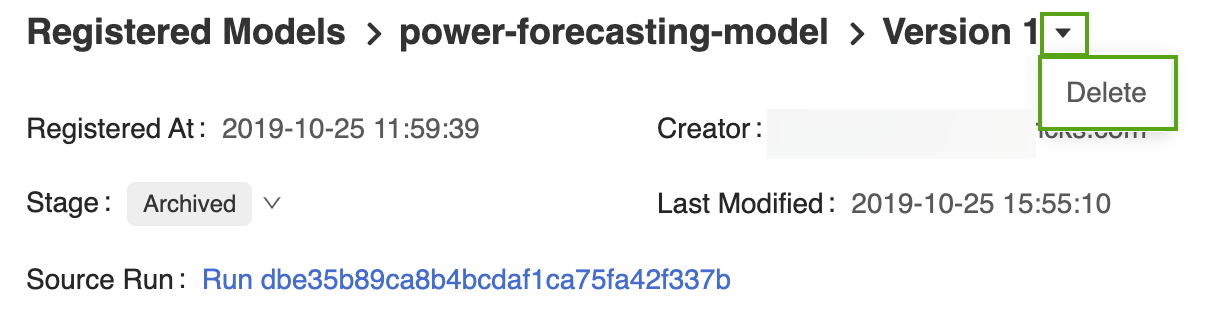
バージョン識別子の横にあるドロップダウン矢印を選択して、[削除] をクリックします。
MLflow API を使用して Version 1 を削除する
client.delete_model_version(
name=model_name,
version=1,
)
MLflow API を使用してモデルを削除する
最初に、残っているすべてのモデル バージョンのステージをなしまたはアーカイブ済みに移行します。
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)