MLflow の実行を使用してトレーニング コードを管理する
この記事では、機械学習トレーニングを管理するための MLflow の実行について説明します。 また、実験全体の実行を管理および比較する方法に関するガイダンスも含まれています。
MLflow の実行はモデル コードの 1 回の実行に対応します。 各実行レコードには、次の情報が記録されます。
- ソース: 実行を起動したノートブックの名前、または実行のプロジェクト名とエントリ ポイント。
- バージョン: ノートブックが Databricks Git フォルダーに格納されている場合、またはMLflow Project からの実行の場合は Git コミット ハッシュ。 それ以外の場合は、ノートブック リビジョン。
- 開始時刻と終了時刻: 実行の開始と終了の時刻。
- パラメーター: キーと値のペアとして保存されるモデル パラメーター。 キーと値はどちらも文字列です。
- メトリック: キーと値のペアとして保存されるモデル評価メトリック。 値は数値です。 各メトリックは、実行の全期間にわたって更新できます (たとえば、モデルの損失関数が収束している状況を追跡するために)。MLflow ではメトリックの履歴を記録し、視覚化できます。
- タグ: キーと値のペアとして保存される実行のメタデータ。 実行の実行中完了後にタグを更新できます。 キーと値はどちらも文字列です。
- 成果物: 任意の形式の出力ファイル。 たとえば、画像、モデル (例: pickle から出力された scikit-learn モデル)、およびデータ ファイル (例: Parquet ファイル) を成果物として記録できます。
すべての MLflow 実行は、アクティブな実験にログが記録されます。 実験をアクティブな実験として明示的に設定していない場合、実行はノートブックの実験にログ記録されます。
実行を表示する
実行には、その親の実験ページから、または実行を作成したノートブックから直接アクセスできます。
実験ページの [実行] テーブルで、実行の開始時刻をクリックします。
ノートブックから、[実験実行] サイドバーの実行の日付と時刻の横にある ![]() をクリックします。
をクリックします。
実行画面には、実行に使用されるパラメーター、実行に起因するメトリック、タグやメモが表示されます。 実行の [メモ]、[パラメーター]、[メトリック]、または [タグ] を表示するには、ラベルの左側にある ![]() をクリックします。
をクリックします。
また、この画面の実行から保存された成果物にもアクセスできます。
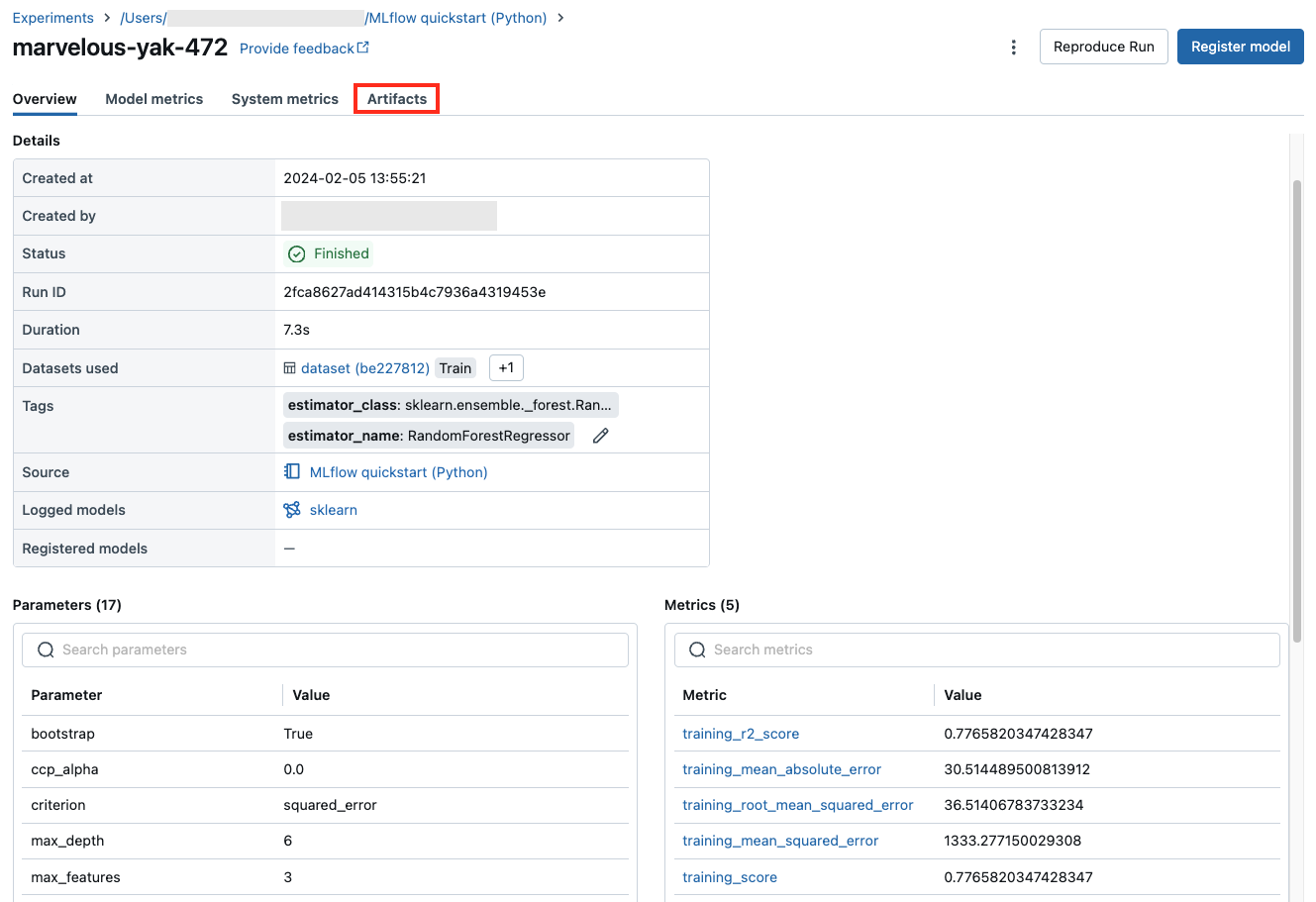
予測のためのコード スニペット
実行からモデルをログに記録すると、このページの [成果物] セクションにモデルが表示されます。 モデルを読み込んで使用し、Spark と pandas DataFrames で予測を行う方法を示すコード スニペットを表示するには、モデル名をクリックします。
実行に使用されるノートブックまたは Git プロジェクトを表示する
実行を作成したノートブックのバージョンを表示するには、次のようにします。
- 実験ページで、[ソース] 列のリンクをクリックします。
- 実行ページで、[ソース] の横にあるリンクをクリックします。
- ノートブックから、[実験実行] サイドバーで、その実験実行のボックスの [ノートブック] アイコン
 をクリックします。
をクリックします。
その実行に関連付けられているノートブックのバージョンがメイン ウィンドウに表示され、実行の日付と時刻が強調表示バーに表示されます。
実行が Git プロジェクトからリモートで起動された場合は、[Git コミット] フィールドのリンクをクリックして、実行で使用されているプロジェクトの特定のバージョンを開きます。 [ソース] フィールドのリンクによって、実行で使用される Git プロジェクトのメイン ブランチが開きます。
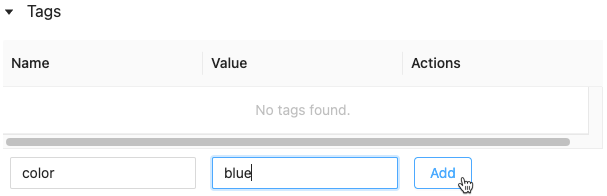
実行にタグを追加する
タグはキーと値のペアであり、作成して後で実行を検索するために使用できます。
実行ページから
 をクリックします (まだ開いていない場合)。 タグ テーブルが表示されます。
をクリックします (まだ開いていない場合)。 タグ テーブルが表示されます。
[名前] フィールドと [値] フィールド内をクリックし、タグのキーと値を入力します。
追加をクリックします。
実行のタグを編集または削除する
既存のタグを編集または削除するには、[アクション] 列のアイコンを使用します。

実行のソフトウェア環境を再現する
[実行の再現] をクリックすると、実行のソフトウェア環境を正確に再現できます。 次のダイアログが表示されます。
![[Reproduce run] (実行の再現) ダイアログ](../_static/images/mlflow/reproduce-run.png)
既定の設定で、[確認] をクリックします。
- ノートブックは、ダイアログに表示される場所に複製されます。
- 元のクラスターがまだ存在する場合は、複製されたノートブックが元のクラスターにアタッチされ、クラスターが起動されます。
- 元のクラスターが既に存在していない場合は、インストールされているライブラリを含め、同じ構成の新しいクラスターが作成され、起動されます。 ノートブックは新しいクラスターにアタッチされます。
複製されたノートブックに対して別の場所を選択し、クラスター構成とインストールされているライブラリを検査できます。
- 複製したノートブックを保存するのに別のフォルダーを選択するには、[フォルダーの編集] をクリックします。
- クラスターの仕様を表示するには、[仕様の表示] をクリックします。クラスターではなくノートブックのみを複製するには、このオプションをオフにします。
- 元のクラスターにインストールされているライブラリを表示するには、[ライブラリの表示] をクリックします。 元のクラスターと同じライブラリのインストールを必要としない場合は、このオプションをオフにします。
実行を管理する
実行の名前を変更する
実行の名前を変更するには、実行ページの右上隅にある ![]() をクリックし、[名前の変更] を選びます。
をクリックし、[名前の変更] を選びます。
実行をフィルター処理する
パラメーター値またはメトリック値に基づいて実行を検索できます。 タグでも実行を検索できます。
パラメーター値とメトリック値を含む式に一致する実行を検索するには、検索フィールドにクエリを入力し、[検索] をクリックします。 クエリ構文の例を次に示します。
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1既定ではでは、メトリック値は最後にログに記録された値に基づいてフィルタリングされます。
MINまたはMAXを使用すると、それぞれ最小または最大メトリック値に基づいて実行を検索することができます。 2024年8月以降に記録された実行にのみ、最小値と最大値が設定されています。タグで実行を検索するには、
tags.<key>="<value>"の形式でタグを入力します。 文字列値は、次のように引用符で囲む必要があります。tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5キーと値の両方にスペースを含めることができます。 キーにスペースが含まれている場合は、次のようにバッククォートで囲む必要があります。
tags.`my custom tag` = "my value"
また、その状態 (アクティブまたは削除済み) と、モデル バージョンが実行に関連付けられているかどうかに基づいて、実行をフィルター処理できます。 これを行うには、[状態] および [作成時刻] ドロップダウン メニューからそれぞれ選びます。
実行をダウンロードする
1 つ以上の実行を選択します。
[CSV のダウンロード] をクリックします。 次のフィールドを含む CSV ファイルがダウンロードされます。
Run ID,Name,Source Type,Source Name,User,Status,<parameter1>,<parameter2>,...,<metric1>,<metric2>,...
実行を削除する
以下の手順で、Databricks Machine Mosaic AI UI を使って実行を削除できます。
- 実験で、実行の左側にあるチェックボックスをオンにして、1 つ以上の実行を選択します。
- [削除] をクリックします。
- 実行が親実行の場合は、子孫の実行も削除するかどうかを決定します。 既定では、このオプションが選択されます。
- [削除] をクリックして確定します。 削除された実行は 30 日間保存されます。 削除された実行を表示するには、[状態] フィールドで [削除済み] を選択します。
作成時刻に基づいて実行を一括削除する
Python を使って、UNIX タイムスタンプ以前に作成された実験の実行を一括削除することができます。
Databricks Runtime 14.1 以降を使用すると、mlflow.delete_runs API を呼び出して実行を削除し、削除された実行の数を返すことができます。
mlflow.delete_runs パラメーターを以下に示します。
experiment_id: 削除する実行を含む実験の ID。max_timestamp_millis: 実行を削除するための UNIX エポック以降の最大作成タイムスタンプ (ミリ秒単位)。 このタイムスタンプ以前に作成された実行のみが削除されます。max_runs: オプション。 削除する実行の最大数を示す正の整数。 max_runs の最大許容値は 10000 です。 指定しない場合、max_runsの既定値は 10000 です。
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
Databricks Runtime 13.3 LTS 以前を使用すると、Azure Databricks Notebook で次のクライアント コードを実行できます。
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
Azure Databricks Experiments API ドキュメントで、作成時刻に基づいた実行の削除のパラメーターと戻り値の仕様を参照してください。
実行を復元する
Databricks Mosaic AI UI を使って、以前に削除した実行を復元できます。
- [実験] ページの [状態] フィールドで [削除済み] を選び、削除された実行を表示します。
- 実行の左側にあるチェックボックスをオンにして、1 つ以上の実行を選びます。
- [復元] をクリックします。
- [復元] をクリックして確定します。 復元された実行を表示するには、[状態] フィールドで [アクティブ] を選びます。
削除時刻に基づいて実行を一括復元する
Python を使って、UNIX タイムスタンプ以降に削除された実験の実行を一括復元することもできます。
Databricks Runtime 14.1 以降を使用すると、mlflow.restore_runs API を呼び出して実行を復元し、復元された実行の数を返すことができます。
mlflow.restore_runs パラメーターを以下に示します。
experiment_id: 復元する実行を含む実験の ID。min_timestamp_millis: 実行を復元するための UNIX エポック以降の最小削除タイムスタンプ (ミリ秒単位)。 このタイムスタンプ以降に削除された実行のみが復元されます。max_runs: オプション。 復元する実行の最大数を示す正の整数。 max_runs の最大許容値は 10000 です。 指定しない場合、max_runs の既定値は 10000 です。
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
Databricks Runtime 13.3 LTS 以前を使用すると、Azure Databricks Notebook で次のクライアント コードを実行できます。
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
Azure Databricks Experiments API ドキュメントで、削除時刻に基づいた実行の復元のパラメーターと戻り値の仕様を参照してください。
実行を比較する
1 つの実験または複数の実験の実行を比較できます。 [実行の比較] ページには、選択した実行に関する情報がグラフィックと表の形式で表示されます。 実行結果の視覚化と、実行情報、実行パラメーター、メトリックのテーブルを作成することもできます。
視覚化カードを作成するには、
- プロットの種類 (平行座標プロット、散布図、または等高線プロット) を選択します。
平行座標プロットの場合は、プロットするパラメータとメトリックを選択します。 ここから、選んだパラメーターとメトリックの間の関係を特定できます。これにより、モデルのハイパーパラメーター調整領域をより適切に定義できます。
![[compare runs] (実行を比較する) ページの視覚化](../_static/images/mlflow/mlflow-run-comparison-viz.png)
散布図または等高線プロットの場合は、各軸に表示するパラメーターまたはメトリックを選択します。
[パラメーター] と [メトリック] のテーブルには、選択したすべての実行の実行パラメーターとメトリックが表示されます。 これらのテーブルの列は、すぐ上の実行の詳細テーブルで識別されます。 わかりやすくするために、![[差分のみ表示] ボタン](../_static/images/mlflow/show-diff-only.png) を切り替えて、選んだすべての実行で同一のパラメーターとメトリックを非表示にすることができます。
を切り替えて、選んだすべての実行で同一のパラメーターとメトリックを非表示にすることができます。
![[compare runs] (実行を比較する) ページのテーブル](../_static/images/mlflow/mlflow-run-comparison-table.png)
1 つの実験の実行を比較する
- 実験ページで、実行の左側にあるチェック ボックスをクリックして 2 つ以上の実行を選択するか、列の上部にあるチェック ボックスをオンにしてすべての実行を選択します。
- [比較] をクリックします。 [
<N>個の実行の比較] 画面が表示されます。
複数の実験の実行を比較する
- 実験ページで、実験名の左側にあるボックスをクリックして、比較する実験を選択します。
- [比較 (n)] をクリックします (n は選択した実験の数です)。 選択した実験のすべての実行を示す画面が表示されます。
- 実行の左側にあるチェック ボックスをクリックして 2 つ以上の実行を選択するか、列の上部にあるチェック ボックスをオンにしてすべての実行を選択します。
- [比較] をクリックします。 [
<N>個の実行の比較] 画面が表示されます。
ワークスペース間で実行をコピーする
Databricks ワークスペースに対して MLflow 実行をインポートまたはエクスポートするために、コミュニティ主導のオープンソース プロジェクト MLflow Export-Import を使用できます。