AutoML を使用した予測 (サーバーレス)
重要
この機能は、パブリック プレビューにあります。
この記事では、モザイク AI モデル トレーニング UI を使用してサーバーレス予測実験を実行する方法について説明します。
モザイク AI モデル トレーニング - 予測では、フル マネージドのコンピューティング リソースで実行しながら、最適なアルゴリズムとハイパーパラメーターを自動的に選択することで、時系列データの予測が簡略化されます。
サーバーレス予測と従来のコンピューティング予測の違いについては、サーバーレス予測と従来のコンピューティング予測のを参照してください。
必要条件
Unity カタログ テーブルとして保存された時系列列を含むトレーニング データ。
ワークスペースで Secure Egress Gateway (SEG) が有効になっている場合は、
pypi.orgを 許可ドメインリスト に追加する必要があります。 サーバーレス エグレス制御については、「ネットワーク ポリシーの管理」を参照してください。
UI を使用して予測実験を作成する
Azure Databricks のランディング ページに移動し、サイドバー [実験] をクリックします。
[予測] タイルで、[トレーニングの開始] を選びます。
アクセスできる Unity カタログ テーブルの一覧から トレーニング データ を選択します。
- 時間列: 時系列の期間を含む列を選択します。 列の型は、
timestampまたはdateである必要があります。 - 予測頻度: 入力データの頻度を表す時間単位を選択します。 たとえば、分、時間、日、月などです。 これにより、時系列の細分性が決まります。
- 予測期間: 将来に予測する選択した頻度の単位数を指定します。 予測頻度と共に、時間単位と予測する時間単位の数の両方が定義されます。
手記
Auto-ARIMA アルゴリズムを使用するには、時系列の 2 つのポイント間の間隔が時系列全体で同じである必要がある定期的な頻度が必要です。 AutoML は、これらの値に前の値を入力することで、不足している時間ステップを処理します。
- 時間列: 時系列の期間を含む列を選択します。 列の型は、
モデルで予測する 予測ターゲット列 を選択します。
必要に応じて、出力予測を格納 予測データ パス
Unity カタログ テーブルを指定します。 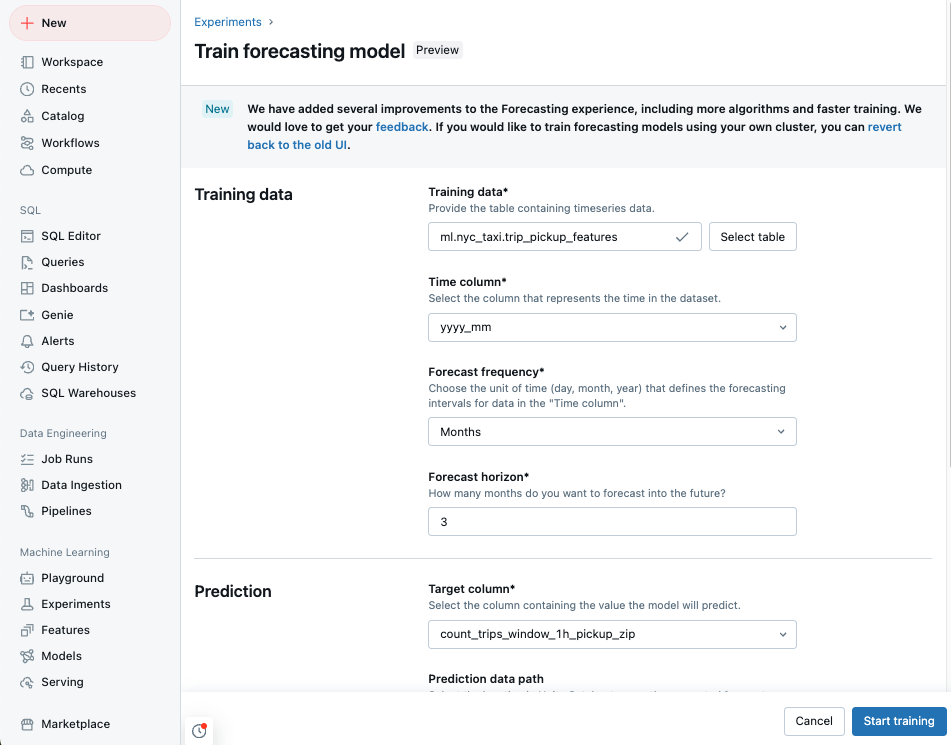
モデル登録の Unity Catalog の場所と名前を選びます。
必要に応じて、[詳細設定] オプション 設定します。
- 実験名: MLflow 実験名を指定します。
- 時系列識別子の列 - 複数系列の予測の場合は、個々の時系列を識別する列を選択します。 Databricks は、これらの列ごとにデータを異なる時系列としてグループ化し、各系列のモデルを個別にトレーニングします。
- プライマリ メトリック: 評価に使用するプライマリ メトリックを選択し、最適なモデルを選択します。
- トレーニングフレームワーク: 自動機械学習のために探索するフレームワークを選択します。
- 分割列: カスタム データ分割を含む列を選択します。 値は"train"、"validate"、"test" である必要があります
- 重み列: 時系列の重み付けに使用する列を指定します。 特定の時系列のすべてのサンプルの重みは同じである必要があります。 重みは 、[0, 10000] の範囲内である必要があります。
- 休日リージョン: モデル トレーニングで共変量として使用する休日リージョンを選択します。
- タイムアウト: AutoML 実験の最大期間を設定します。
実験を実行して結果を監視する
AutoML 実験を開始するには、[トレーニング
- 実験はいつでも停止します。
- 実行を監視します。
- 任意の実行ページに移動します。
結果を表示するか、最適なモデルを使用する
トレーニングが完了すると、予測結果が指定された Delta テーブルに格納され、最適なモデルが Unity カタログに登録されます。
実験ページから、次の手順から選択します。
- 予測の表示 を選択して、予測結果テーブルを表示します。
- 最適なモデル 使用してバッチ推論用に自動生成されたノートブックを開くには、バッチ推論ノートブック を選択します。
- [サービス エンドポイント
作成] を選択して、最適なモデルをモデル サービス エンドポイントにデプロイします。
サーバーレス予測と従来のコンピューティング予測
次の表は、従来のコンピューティング を使用したサーバーレス予測と
| 特徴 | サーバーレス予測 | 従来のコンピューティング予測 |
|---|---|---|
| コンピューティング インフラストラクチャ | Azure Databricks はコンピューティング構成を管理し、コストとパフォーマンスに合わせて自動的に最適化します。 | ユーザーが構成したコンピューティング |
| 統治 | Unity カタログに登録されているモデルと成果物 | ユーザーが構成したワークスペース ファイル ストア |
| アルゴリズムの選択 | 統計モデル とディープ ラーニング ニューラル ネット アルゴリズム DeepAR | 統計モデル |
| 特徴量ストアの統合 | サポートされていません | サポートされています |
| 自動生成されたノートブック | バッチ推論ノートブック | すべての試用版のソース コード |
| ワンクリック モデル サービングのデプロイ | 対応済み | サポートされていない |
| カスタム トレーニング/検証/テストの分割 | サポート済み | サポートされていません |
| 個々の時系列のカスタム重み付け | サポートされている | サポートされていません |