MLOps Stacks: コードとしてのモデル開発プロセス
この記事では、MLOps Stacks を使用して、開発とデプロイのプロセスをソース管理されるリポジトリ内のコードとして実装する方法について説明します。 また、Databricks Data Intelligence プラットフォームでのモデル開発の利点についても説明します。これは、モデル開発とデプロイ プロセスのすべてのステップを統合する単一プラットフォームです。
MLOps スタックとは
MLOps Stacks では、モデル開発プロセス全体が、ソースで管理されるリポジトリ内のコードとして実装、保存、追跡されます。 この方法でプロセスを自動化すると、反復可能、予測可能で体系的なデプロイが容易になり、CI/CD プロセスと統合できるようになります。 モデル開発プロセスをコードとして表すことで、モデルをデプロイする代わりにコードをデプロイできます。 コードをデプロイすると、モデルをビルドする機能が自動化され、必要な場合にモデルの再トレーニングがはるかに簡単になります。
MLOps Stacks を使用してプロジェクトを作成する場合は、機能エンジニアリング、トレーニング、テスト、デプロイに使用するノートブック、トレーニングとテスト用のパイプライン、各ステージに使用するワークスペース、コードの自動テストとデプロイに GitHub Actions または Azure DevOps を使用する CI/CD ワークフローなど、ML 開発とデプロイ プロセスのコンポーネントを定義します。
MLOps スタックによって作成された環境では、Databricks によって推奨される MLOps ワークフローが実装されます。 コードをカスタマイズして、組織のプロセスまたは要件に合わせてスタックを作成できます。
MLOps スタックのしくみ
Databricks CLI を使用して MLOps スタックを作成します。 詳細な手順については、「MLOps スタック用の Databricks アセット バンドル」を参照してください。
MLOps スタック プロジェクトを開始するときは、ソフトウェアに示される手順に従って構成の詳細を入力してから、プロジェクトを構成するファイルを含むディレクトリを作成します。 このディレクトリ (スタック) は、Databricks によって推奨される運用 MLOps ワークフローを実装します。 図に示されているコンポーネントは自動的に作成されるので、カスタム コードを追加するためのファイルを編集するだけで済みます。
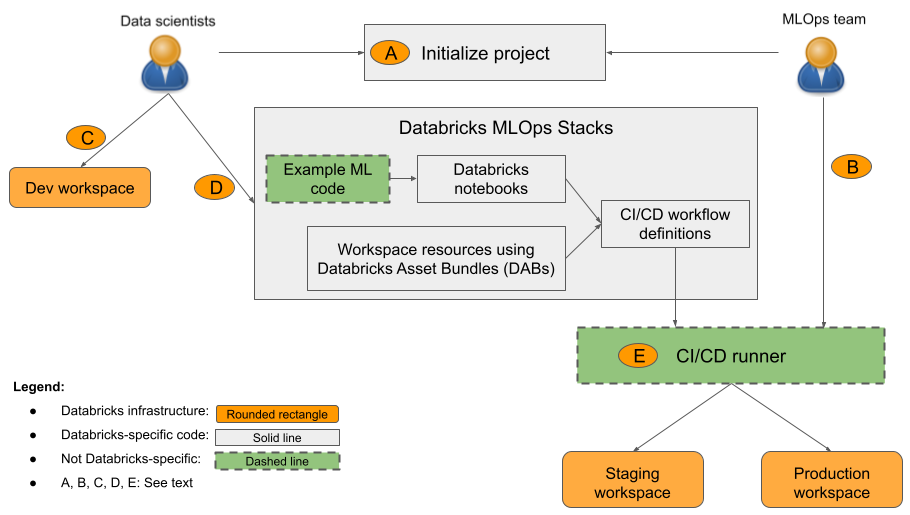
図の説明:
- A: データ科学者または ML エンジニアが、
databricks bundle init mlops-stacksを使用してプロジェクトを初期化します。 プロジェクトを初期化するときに、ML コード コンポーネント (通常はデータ科学者が使用)、CI/CD コンポーネント (通常は ML エンジニアが使用)、またはその両方を設定できます。 - B: ML エンジニアは、CI/CD 用に Databricks サービス プリンシパル シークレットを設定します。
- C: データ科学者は、Databricks またはローカル システムでモデルを開発します。
- D: データ科学者は、ML コードを更新するためのプル要求を作成します。
- E: CI/CD ランナーは、ノートブックを実行し、ジョブを作成し、ステージング ワークスペースと運用ワークスペースで他のタスクを実行します。
組織では、既定のスタックを使用することも、必要に応じてカスタマイズして、組織のプラクティスに合わせてコンポーネントを追加、削除、または修正することもできます。 詳細については、GitHub リポジトリにある readme を参照してください。
MLOps スタックはモジュール構造で設計されているため、さまざまな ML チームがソフトウェア エンジニアリングのベスト プラクティスに従い、運用グレードの CI/CD を維持しながら、プロジェクトで独立して作業できます。 運用エンジニアは、データ サイエンティストによる ML パイプラインとモデルの開発、テスト、運用環境へのデプロイを可能にする ML インフラストラクチャを構成します。
図に示すように、既定の MLOps Stack には次の 3 つのコンポーネントが含まれています。
- ML コード。 MLOps Stacks は、トレーニング用のノートブック、バッチ推論などの、ML プロジェクト用の一連のテンプレートを作成します。 標準化されたテンプレートによって、データ サイエンティストは迅速に作業を開始し、チーム間でプロジェクト構造を統合し、テストの準備ができているモジュール化されたコードを適用することができます。
- コードとしての ML リソース。 MLOps Stacks では、トレーニングやバッチ推論などのタスクのためのワークスペースやパイプラインなどのリソースを定義します。 リソースは、Databricks アセット バンドルで定義され、ML 環境のテスト、最適化、およびバージョン管理を容易にします。 たとえば、モデルの再トレーニングを自動化するために、より大きなインスタンスの種類を試すことができます。変更は将来の参照のために自動的に追跡されます。
- CI/CD。 GitHub Actions または Azure DevOps を使用して ML コードとリソースをテストしてデプロイすることができます。これによって、すべての運用環境の変更が自動化によって実行され、テストされたコードのみが運用環境にデプロイされるようになります。
MLOps プロジェクト フロー
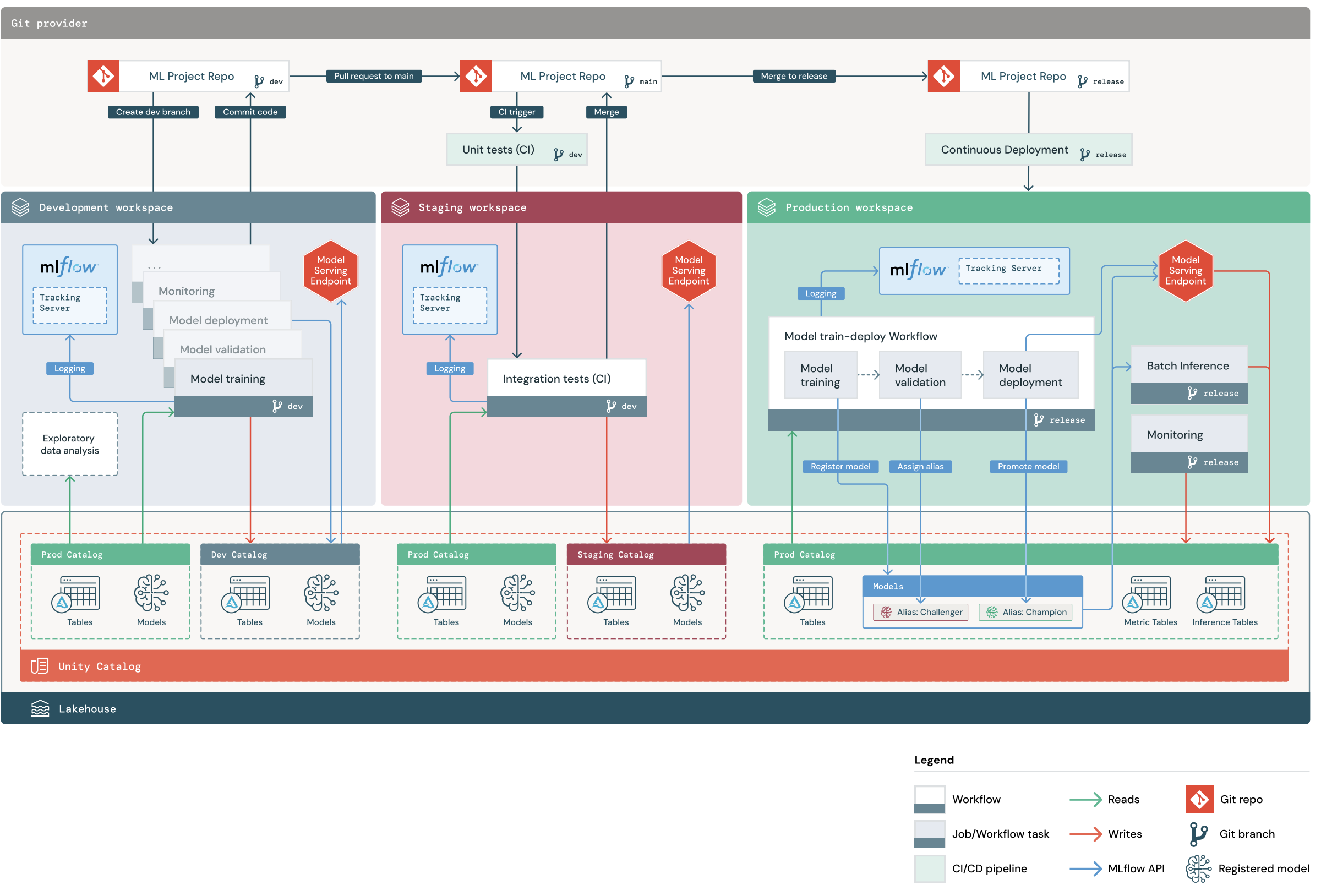
既定の MLOps Stacks プロジェクトには、開発、ステージング、運用の Databricks ワークスペース間で自動モデル トレーニング ジョブとバッチ推論ジョブをテストしてデプロイするための CI/CD ワークフローを含む ML パイプラインが含まれています。 MLOps Stacks は構成可能であり、組織のプロセスに合わせてプロジェクト構造を変更できます。
この図は、既定の MLOps Stack によって実装されるプロセスを示しています。 開発ワークスペースで、データ サイエンティストは ML コードとファイル プル要求 (PR) を反復処理します。 PR は、分離されたステージング Databricks ワークスペースで単体テストと統合テストをトリガーします。 PR がメインにマージされると、ステージングで実行されるモデル トレーニング ジョブとバッチ推論ジョブが直ちに更新され、最新のコードが実行されます。 PR をメインにマージした後は、スケジュールされたリリース プロセスの一環として新しいリリース ブランチを切り取り、コードの変更を運用環境にデプロイできます。
MLOps スタックのプロジェクトの構造
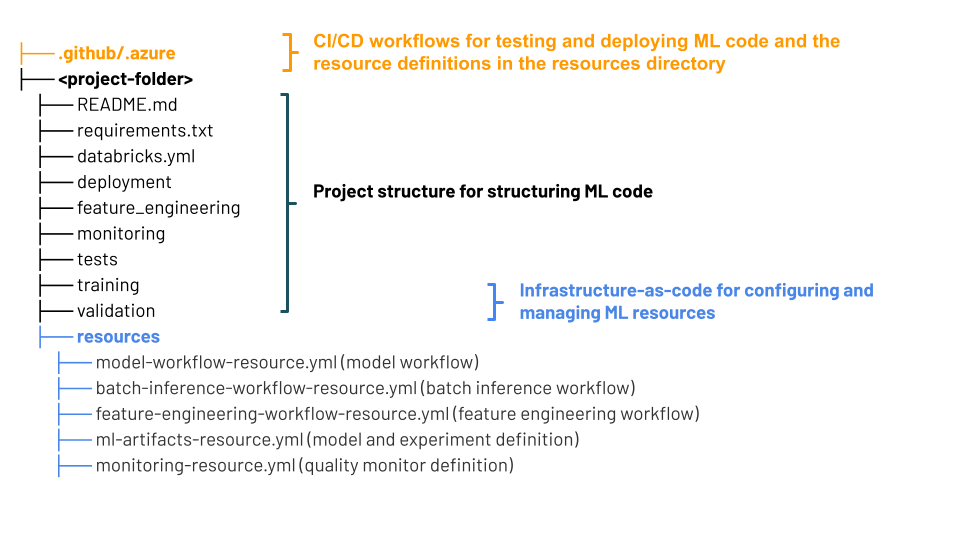
MLOps スタックでは、Databricks アセット バンドル (プロジェクトのエンドツーエンドの定義として機能するソース ファイルのコレクション) が使用されます。 これらのソース ファイルには、テストとデプロイの方法に関する情報が含まれています。 ファイルをバンドルとして収集すると、変更の共同バージョン管理が簡単にになり、ソース管理、コード レビュー、テスト、CI/CD などのソフトウェア エンジニアリングのベスト プラクティスを使用できるようになります。
この図は、既定の MLOps スタック用に作成されたファイルを示しています。 スタックに含まれるファイルの詳細については、GitHub リポジトリにあるドキュメントまたは「MLOps スタック用の Databricks アセット バンドル」を参照してください。
MLOps スタックのコンポーネント
"スタック" とは、開発プロセスで使用される一連のツールを指します。 既定の MLOps スタックは、統合された Databricks プラットフォームを利用し、次のツールを使用します。
| コンポーネント | Databricks のツール |
|---|---|
| ML モデル開発コード | Databricks Notebooks、MLflow |
| 特徴開発と管理 | 特徴エンジニアリング |
| ML モデル リポジトリ | Unity Catalog のモデル |
| ML モデルの提供 | Mosaic AI Model Serving |
| コードとしてのインフラストラクチャ | Databricks アセット バンドル |
| Orchestrator | Databricks ジョブ |
| CI/CD | GitHub Actions、Azure DevOps |
| データとモデルのパフォーマンスの監視 | レイクハウス監視 |
次のステップ
開始するには、「MLOps Stacks 用のDatabricks アセット バンドル」または「GitHub の Databricks MLOps Stacks リポジトリ」を参照してください。