オンライン テーブルを使用してリアルタイムで特徴量を提供する
重要
オンライン テーブルは、 westus、 eastus、 eastus2、 northeurope、 westeuropeの各リージョンでパブリック プレビュー段階にあります。 価格については、「 オンライン テーブルの価格」を参照してください。
オンライン テーブルは、オンライン アクセス用に最適化された行指向形式で保存される Delta テーブルの読み取り専用コピーです。 オンライン テーブルは、要求の負荷でスループット容量を自動スケーリングし、任意のスケールのデータへの低遅延と高スループット アクセスを提供する完全なサーバーレス テーブルです。 オンライン テーブルは、Mosaic AI Model Serving、Feature Serving、取得拡張生成 (RAG) アプリケーションを使用するように設計されており、高速なデータ参照に使用されます。
Lakehouse フェデレーションを使用して、クエリでオンライン テーブルを使用することもできます。 Lakehouse フェデレーションを使用する場合は、サーバーレス SQL ウェアハウスを使用してオンライン テーブルにアクセスする必要があります。 読み取り操作 (SELECT) のみがサポートされています。 この機能は、対話型またはデバッグのみを目的としており、運用環境またはミッション クリティカルなワークロードには使用しないでください。
Databricks UI を使ったオンライン テーブルの作成は、1 ステップのプロセスです。 カタログ エクスプローラーで Delta テーブルを選び、[オンライン テーブルの作成] を選ぶだけです。 REST API または Databricks SDK を使ってオンライン テーブルを作成および管理することもできます。 「API を使ってオンライン テーブルを操作する」を参照してください。
要件
- ワークスペースは、Unity Catalog に対して有効にする必要があります。 ドキュメントに従って Unity Catalog メタストアを作成し、ワークスペースで有効にして、カタログを作成します。
- オンライン テーブルにアクセスするには、モデルを Unity カタログに登録する必要があります。
UI を使ってオンライン テーブルを操作する
このセクションでは、オンライン テーブルを作成および削除する方法と、オンライン テーブルの状態を確認して更新をトリガーする方法について説明します。
UI を使ってオンライン テーブルを作成する
オンライン テーブルをカタログ エクスプローラーから作成します。 必要なアクセス許可の詳細については、「ユーザーのアクセス許可」を参照してください。
オンライン テーブルを作成するには、ソース Delta テーブルに主キーが必要です。 使用する Delta テーブルに主キーがない場合は、「Unity Catalog の既存の Delta テーブルを特徴テーブルとして使用する」の手順に従って作成します。
カタログ エクスプローラーで、オンライン テーブルと同期させるソース テーブルに移動します。 [作成] メニューの [オンライン テーブル] を選択します。
![[オンライン テーブルの作成] を選択する](../../_static/images/machine-learning/feature-store/create-online-table.png)
ダイアログのセレクターを使って、オンライン テーブルを構成します。
![[configure online table] (オンライン テーブルの構成) ダイアログ](../../_static/images/machine-learning/feature-store/create-online-table-dlg.png)
[名前]: Unity Catalog でオンライン テーブルに使う名前。
[主キー]: オンライン テーブルの主キーとして使うソース テーブルの列。
[Timeseries Key] (時系列キー): (省略可能)。 時系列キーとして使うソース テーブルの列。 指定すると、オンライン テーブルには、各主キーの最新の時系列キー値を持つ行のみが含まれます。
[Sync mode] (同期モード): 同期パイプラインがオンライン テーブルを更新する方法を指定します。 [スナップショット]、[トリガー]、または [連続] のいずれかを選びます。
ポリシー 説明 スナップショット パイプラインが 1 回実行され、ソース テーブルのスナップショットが取得され、オンライン テーブルにコピーされます。 ソース テーブルに対する後続の変更は、ソースの新しいスナップショットを取得して新しいコピーを作成することで、オンライン テーブルに自動的に反映されます。 オンライン テーブルの内容はアトミックに更新されます。 Triggered パイプラインが 1 回実行され、オンライン テーブルにソース テーブルの初期スナップショットのコピーが作成されます。 スナップショット同期モードとは異なり、オンライン テーブルが更新されると、最後のパイプライン実行以降の変更のみが取得され、オンライン テーブルに適用されます。 増分更新は、スケジュールに従って手動でトリガーすることも、自動的にトリガーすることもできます。 継続的 パイプラインは継続的に実行されます。 ソース テーブルに対する後続の変更は、リアルタイム ストリーミング モードでオンライン テーブルに増分的に適用されます。 手動更新は必要ありません。
Note
[トリガー] または [連続] 同期モードをサポートするには、ソース テーブルで変更データ フィードが有効になっている必要があります。
- 終わったら、[確認] をクリックします。 オンライン テーブル ページが表示されます。
- 新しいオンライン テーブルが、作成ダイアログで指定したカタログ、スキーマ、名前の下に作成されます。 カタログ エクスプローラーでは、オンライン テーブルは
 で表されます。
で表されます。
UI を使って状態を取得し、更新をトリガーする
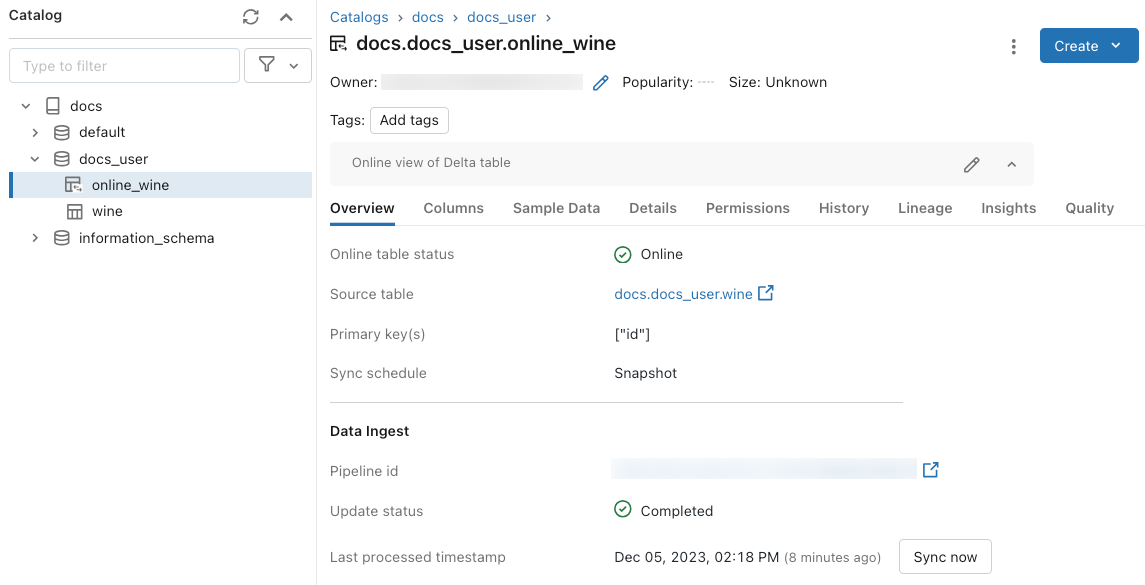
オンライン テーブルの状態を調べるには、カタログでテーブルの名前をクリックして開きます。 オンライン テーブルのページが表示され、[概要] タブが開きます。 [Data Ingest] (データの取り込み) セクションには、最新の更新の状態が示されます。 更新をトリガーするには、[今すぐ同期] をクリックします。 [Data Ingest] (データの取り込み) セクションには、テーブルを更新する Delta Live Tables パイプラインへのリンクも含まれています。
定期的な更新をスケジュールする
Snapshot または Triggered 同期モードのオンライン テーブルでは、自動更新をスケジュールできます。 更新スケジュールは、テーブルを更新する Delta Live Tables パイプラインによって管理されます。
- カタログ エクスプローラーで、オンライン テーブルに移動します。
- Data Ingest セクションで、パイプラインへのリンクをクリックします。
- 右上隅の Schedule をクリックし、新しいスケジュールを追加するか、既存のスケジュールを更新します。
UI を使ってオンライン テーブルを削除する
オンライン テーブルのページで、 ケバブ メニューから ![]() [削除] を選びます。
[削除] を選びます。
API を使ってオンライン テーブルを操作する
Databricks SDK または REST API を使って、オンライン テーブルを作成および管理することもできます。
リファレンス情報については、Databricks SDK for Python または REST API のリファレンス ドキュメントを参照してください。
要件
Databricks SDK バージョン 0.20 以降。
API を使ってオンライン テーブルを作成する
Databricks SDK - Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
online_table = OnlineTable(
name="main.default.my_online_table", # Fully qualified table name
spec=spec # Online table specification
)
w.online_tables.create_and_wait(table=online_table)
REST API
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
オンライン テーブルは、作成後に自動的に同期を開始します。
API を使って状態を取得し、更新をトリガーする
以下の例に従って、オンライン テーブルの状態と仕様を表示できます。 オンライン テーブルが継続的ではなく、そのデータの手動更新をトリガーした場合は、パイプライン API を使用してこれを行うことができます。
オンライン テーブル仕様でオンライン テーブルに関連付けられているパイプライン ID を使用し、パイプラインで新しい更新を開始して更新をトリガーします。 これは、カタログ エクスプローラーのオンライン テーブル UI で [今すぐ同期] をクリックするのと同じです。
Databricks SDK - Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'Delta Live Tables: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
REST API
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in Delta Live Tables: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
API を使ってオンライン テーブルを削除する
Databricks SDK - Python
w.online_tables.delete('main.default.my_online_table')
REST API
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
オンライン テーブルを削除すると、進行中のデータ同期が停止し、そのすべてのリソースが解放されます。
特徴量提供エンドポイントを使用してオンライン テーブルのデータを提供する
Databricks の外部でホストされているモデルとアプリケーションの場合は、オンライン テーブルから特徴量を提供する特徴量提供エンドポイントを作成できます。 エンドポイントがあると、REST API を使って低遅延で特徴量を利用できます。
特徴量指定を作成します。
特徴量指定を作成するときは、ソース Delta テーブルを指定します。 これにより、特徴量指定をオフラインとオンラインの両方のシナリオで使用できます。 オンライン検索では、提供エンドポイントにより、オンライン テーブルが自動的に使われて、低遅延の特徴量検索が実行されます。
ソース Delta テーブルとオンライン テーブルでは同じ主キーを使用する必要があります。
特徴量指定は、カタログ エクスプローラーの [関数] タブで確認できます。
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )特徴量提供エンドポイントを作成します。
このステップでは、Delta テーブル
user_preferences_online_tableからデータを同期するuser_preferencesという名前のオンライン テーブルを作成してあるとします。 特徴量指定を使って、特徴量提供エンドポイントを作成します。 このエンドポイントにより、関連付けられているオンライン テーブルを使って REST API でデータを利用できるようになります。Note
この操作を実行するユーザーは、オフライン テーブルとオンライン テーブル両方の所有者である必要があります。
Databricks SDK - Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )Python API
from databricks.feature_engineering.entities.feature_serving_endpoint import ( ServedEntity, EndpointCoreConfig, ) fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )特徴量提供エンドポイントからデータを取得します。
API エンドポイントにアクセスするには、HTTP GET 要求をエンドポイント URL に送信します。 この例では、Python API を使ってこれを行う方法を示します。 他の言語とツールについては、「Feature Serving」を参照してください。
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
RAG アプリケーションでオンライン テーブルを使用する
RAG アプリケーションは、オンライン テーブルの一般的なユース ケースです。 RAG アプリケーションに必要な構造化データのオンライン テーブルを作成し、特徴量提供エンドポイントでホストします。 RAG アプリケーションは、特徴量提供エンドポイントを使って、オンライン テーブルで関連データを検索します。
一般的な手順は次のとおりです。
- 特徴量提供エンドポイントを作成します。
- LangChain、またはエンドポイントを使用して関連するデータを検索する同様のパッケージを使用して、ツールを作成します。
- LangChain エージェントまたは同様のエージェントでツールを使用して、関連するデータを取得します。
- アプリケーションをホストするモデル提供エンドポイントを作成します。
詳細な手順とノートブックの例については、「特徴エンジニアリングの例: 構造化 RAG アプリケーション」を参照してください。
ノートブックの例
次のノートブックは、オンライン テーブルに特徴量を公開して、リアルタイムのサービス提供と特徴量の自動検索を行う方法を示しています。
オンライン テーブル デモ ノートブック
Mosaic AI Model Serving でオンライン テーブルを使用する
オンライン テーブルを使って、Mosaic AI Model Serving 用の特徴量を検索できます。 特徴量テーブルをオンライン テーブルに同期すると、その特徴量テーブルの特徴量を使ってトレーニングされたモデルにより、推論の間にオンライン テーブルから特徴量の値が自動的に検索されます。 追加の構成は不要です。
FeatureLookupを使ってモデルをトレーニングします。モデルのトレーニングでは、次の例に示すように、モデル トレーニング セットのオフライン特徴量テーブルの特徴量を使います。
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )Mosaic AI Model Serving を使用してモデルを提供します。 モデルにより、オンライン テーブルから特徴量が自動的に検索されます。 詳細については、「Databricks モデル提供を使用した自動特徴検索」を参照してください。
ユーザーのアクセス許可
オンライン テーブルを作成するには、次のアクセス許可が必要です。
- ソース テーブルに対する
SELECT特権。 - 同期先のカタログに対する
USE_CATALOG特権。 - 同期先のスキーマに対する
USE_SCHEMAおよびCREATE_TABLE特権。
オンライン テーブルのデータ同期パイプラインを管理するには、オンライン テーブルの所有者であるか、オンライン テーブルに対する REFRESH 権限が付与されている必要があります。 カタログに対する USE_CATALOG および USE_SCHEMA 権限を持たないユーザーには、カタログ エクスプローラーでオンライン テーブルが表示されません。
Unity Catalog メタストアには、Privilege Model バージョン 1.0 が必要です。
エンドポイント アクセス許可モデル
特徴量提供またはモデル提供エンドポイント用に、オンライン テーブルからデータのクエリに必要なアクセス許可が制限された一意のサービス プリンシパルが、自動的に作成されます。 このサービス プリンシパルを使うと、エンドポイントは、リソースを作成したユーザーに依存せずにデータにアクセスでき、作成者がワークスペースを離れた場合でも、エンドポイントが引き続き機能することが保証されます。
このサービス プリンシパルの有効期間は、エンドポイントの有効期間です。 監査ログでは、このサービス プリンシパルに必要な権限を付与する Unity Catalog カタログの所有者に対する、システムによって生成されたレコードが示されている場合があります。
制限事項
- ソース テーブルごとにサポートされているオンライン テーブルは 1 つだけです。
- オンライン テーブルとそのソース テーブルには、最大 1,000 個の列を含めることができます。
- データ型 ARRAY、MAP、または STRUCT の列は、オンライン テーブルの主キーとして使用できません。
- ソース テーブルで、オンライン テーブルの主キーとして使われている列に null 値が含まれる行は、すべて無視されます。
- 外部、システム、内部の各テーブルは、ソース テーブルとしてはサポートされていません。
- Delta の変更データ フィードが有効になっていないソース テーブルでは、スナップショット同期モードのみがサポートされます。
- Delta Sharing テーブルは、スナップショット同期モードでのみサポートされます。
- オンライン テーブルのカタログ、スキーマ、テーブル名には、英数字とアンダースコアのみを使用でき、先頭を数字にすることはできません。 ダッシュ (
-) は使用できません。 - String 型の列の長さは 64 KB に制限されています。
- 列名の長さは 64 文字に制限されています。
- 行の最大サイズは 2 MB です。
- パブリック プレビュー中の Unity Catalog メタストア内のすべてのオンライン テーブルの合計サイズは、非圧縮ユーザー データ 2 TB です。
- 1 秒あたりのクエリ数 (QPS) は、最大 12,000 です。 この制限を引き上げるには、Databricks アカウント チームにお問い合わせください。
トラブルシューティング
[オンライン テーブルの作成] オプションが表示されない
通常、同期元のテーブル (ソース テーブル) がサポートされていない種類であることが原因です。 ソース テーブルの [Securable Kind] (セキュリティ保護可能な種類) (カタログ エクスプローラーの [詳細] タブに表示されます) が、以下のサポートされているオプションのいずれかであることを確認してください。
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
オンライン テーブルを作成するときに、[トリガー] または [連続] の同期モードを選択できない
これは、ソース テーブルで差分変更データ フィードが有効になっていない場合、またはビューまたは具体化されたビューである場合に発生します。 増分同期モードを使用するには、ソース テーブルで変更データ フィードを有効にするか、ビュー以外のテーブルを使用します。
オンライン テーブルの更新が失敗するか、状態がオフラインと表示される
このエラーのトラブルシューティングを開始するには、カタログ エクスプローラーでオンライン テーブルの [概要] タブに表示されるパイプライン ID をクリックします。
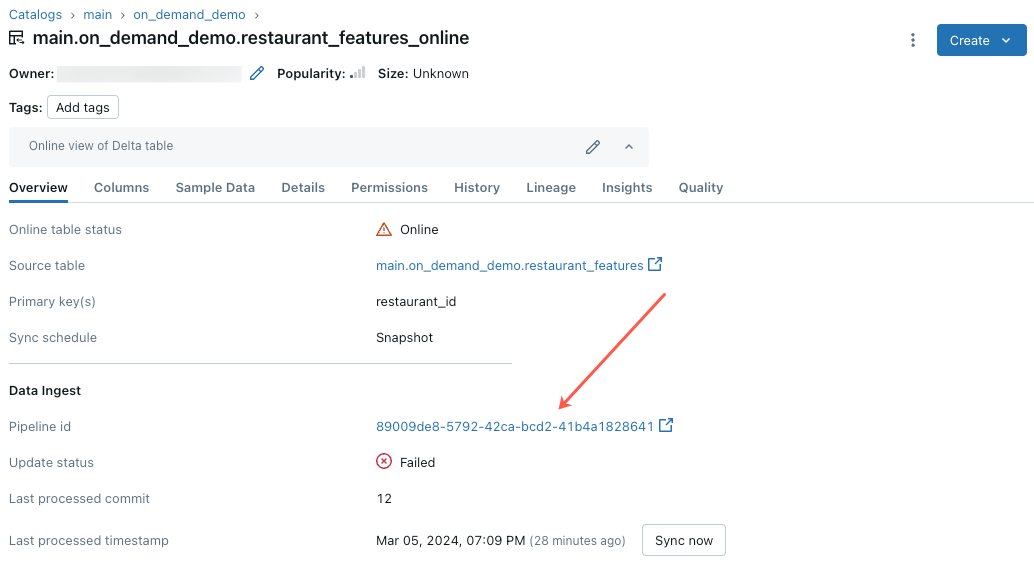
表示されたパイプライン UI ページで、"フロー '__online_table を解決できませんでした" というエントリをクリックします。
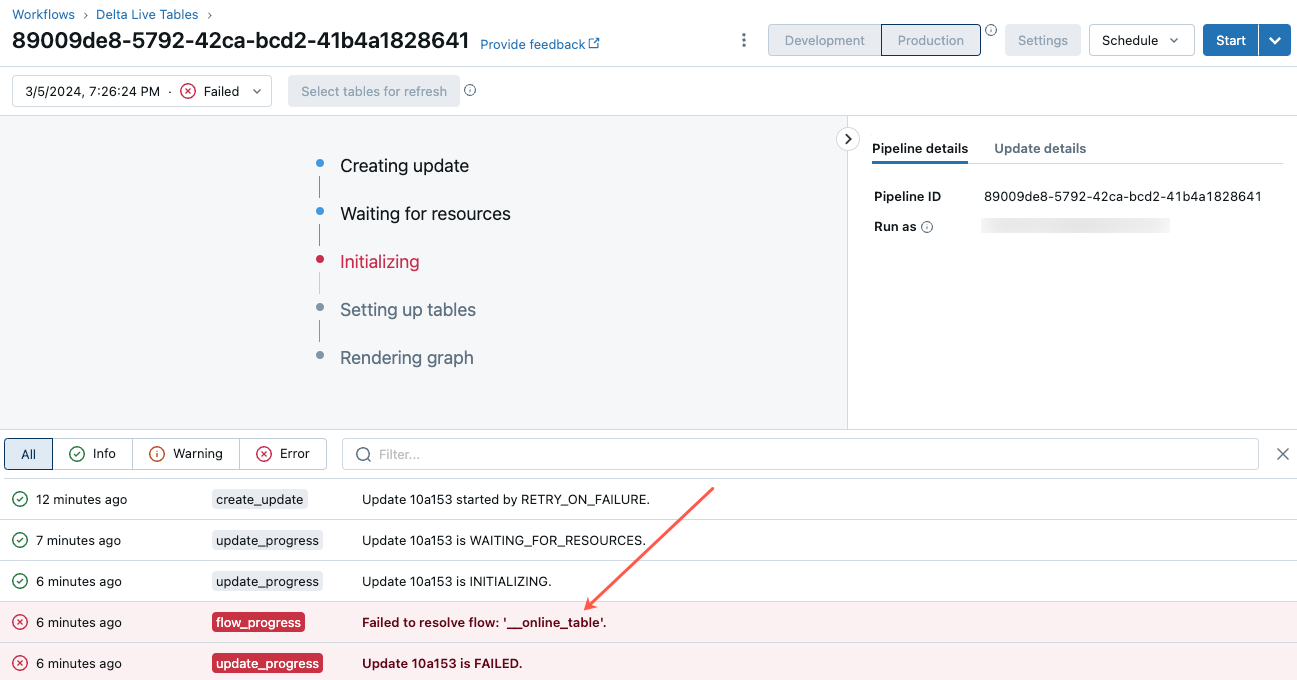
ポップアップが表示され、[エラーの詳細] セクションに詳細が表示されます。
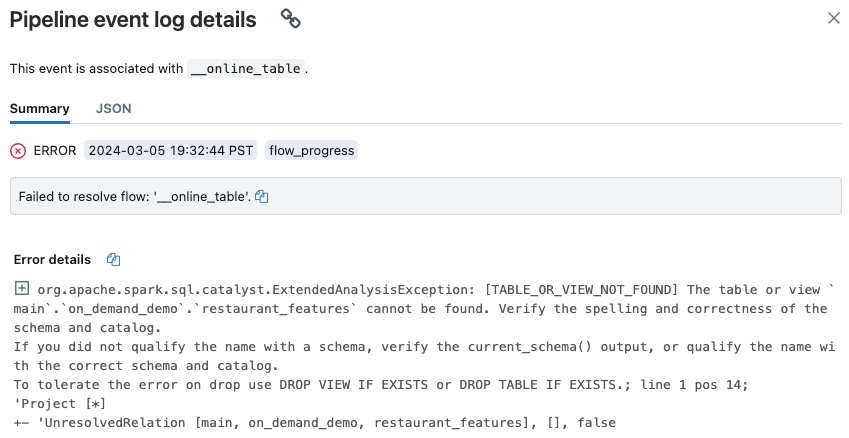
一般的なエラーの原因には、次のものがあります。
オンライン テーブルの同期中に、ソース テーブルが削除されたか、削除されて同じ名前で再作成されました。 これは、継続的なオンライン テーブルでは常に同期が行われるため、特に一般的です。
ファイアウォールの設定により、サーバーレス コンピューティング経由でソース テーブルにアクセスできません。 この状況では、[エラーの詳細] セクションに、"クラスター xxx で DLT サービスを開始できませんでした…" というエラー メッセージが表示される場合があります。
オンライン テーブルの集計サイズが、メタストア全体の上限である 2 TB (非圧縮サイズ) を超えています。 2 TB の制限は、行指向形式で Delta テーブルを展開した後の圧縮されていないサイズを指します。 行形式のテーブルのサイズは、カタログ エクスプローラーに表示される Delta テーブルのサイズより大幅に大きくなる場合があります。これは、列指向形式のテーブルの圧縮サイズを参照します。 テーブルの内容によっては、その差が 100 倍にもなる場合があります。
Delta テーブルの非圧縮の行展開サイズを見積もるには、サーバーレス SQL ウェアハウスから次のクエリを使用します。 このクエリは、拡張テーブルの推定サイズをバイト単位で返します。 このクエリが正常に実行されると、サーバーレス コンピューティングがソース テーブルにアクセスできることも確認されます。
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;