AutoML を使用した回帰
AutoML を使用して、最適な回帰アルゴリズムとハイパーパラメーター構成を自動的に検索し、連続する数値 valuesを予測します。
UI を使用して回帰実験をSetする
回帰の問題は、AutoML UI を使って次の手順でsetできます。
サイド バーで、[実験] をselectします。
[回帰] カードで、[トレーニングの開始] をselectします。
[AutoML 実験の構成] ページが表示されます。 このページでは、AutoML プロセスを構成し、予測するデータセット、問題の種類、ターゲットまたはラベルの column、実験の実行の評価とスコア付けに使用するメトリック、および停止条件を指定します。
[コンピューティング] フィールドで、Databricks Runtime ML が実行されているクラスターをselectします。
[データセット] の下の [参照] をselectします。
使用する table に移動し、[Select] をクリックします。 tableschema が表示されます。
- Databricks Runtime 10.3 ML 以降では、AutoML でトレーニングに使う必要があるcolumnsを指定できます。 予測ターゲットとして選択した column や、データを分割 column 時間を remove することはできません。
- Databricks Runtime 10.4 LTS ML 以降では、[次で補完] ドロップダウンから選択して、null valuesを補完する方法を指定できます。 既定では、AutoML では、column の種類とコンテンツに基づいて補完方法が選択されます。
注意
既定以外の補完方法を指定した場合、AutoML ではセマンティック型の検出は実行されません。
[予測ターゲット] フィールドをクリックします。 schemaに表示される columns が一覧表示されたドロップダウンが表示されます。 モデルで予測するcolumnをSelectします。
[実験名フィールド] には、既定の名前が表示されます。 変更するには、フィールドに新しい名前を入力します。
さらに、以下を実行できます。
- その他の構成オプションを指定します。
- フィーチャ ストア 既存のフィーチャ tables を使用して、元の入力データセットを拡張します。
詳細な構成
これらのparametersにアクセスするには、[詳細な構成 (省略可能)] セクションを開きます。
- 評価メトリックは、実行のスコア付けに使用されるプライマリ メトリックです。
- Databricks Runtime 10.4 LTS ML 以降では、トレーニング フレームワークを考慮事項から除外できます。 既定では、AutoML では [AutoML アルゴリズム] の下に一覧表示されているフレームワークを使用してモデルがトレーニングされます。
- 停止条件は編集できます。 既定の停止条件は次のとおりです。
- 予測実験の場合は、120 分後に停止します。
- Databricks Runtime 10.4 LTS ML 以下での分類と回帰の実験の場合は、60 分経過後または 200 個の試用版完了後のうち、どちらか早い方で停止します。 Databricks Runtime 11.0 ML 以上の場合は、試行回数は停止条件として使用されません。
- Databricks Runtime 10.4 LTS ML 以降では、分類と回帰の実験のために、AutoML には早期停止が組み込まれており、検証メトリックにそれ以上の改善が見込まれなくなった場合に、モデルのトレーニングとチューニングが停止されます。
- Databricks Runtime 10.4 LTS ML 以降では、select を
time columnすることで、トレーニング、検証、テストのデータを時系列順に分割できます(の分類 と の回帰にのみ適用されます)。 - Databricks では、[データ ディレクトリ] フィールドには値を設定しないことをお勧めします。 それを行うと、MLflow 成果物としてデータセットを安全に格納する既定の動作がトリガーされます。 DBFS パスを指定できますが、この場合、データセットは AutoML 実験のアクセス許可を継承しません。
実験を実行して結果を確認する
AutoML 実験を開始するには、[AutoML の起動] をクリックします。 実験の実行が始まり、AutoML トレーニング ページが表示されます。 実行tableをrefreshするには、![[Refresh] ボタン](../../_static/images/machine-learning/automl-refresh-button.png) をクリックします。
をクリックします。
実験の進行状況を表示する
このページからは、次のことを行うことができます。
- 任意のタイミングで、実験を停止します。
- データ探索ノートブックを開きます。
- 実行を監視します。
- 任意の実行の実行ページに移動します。
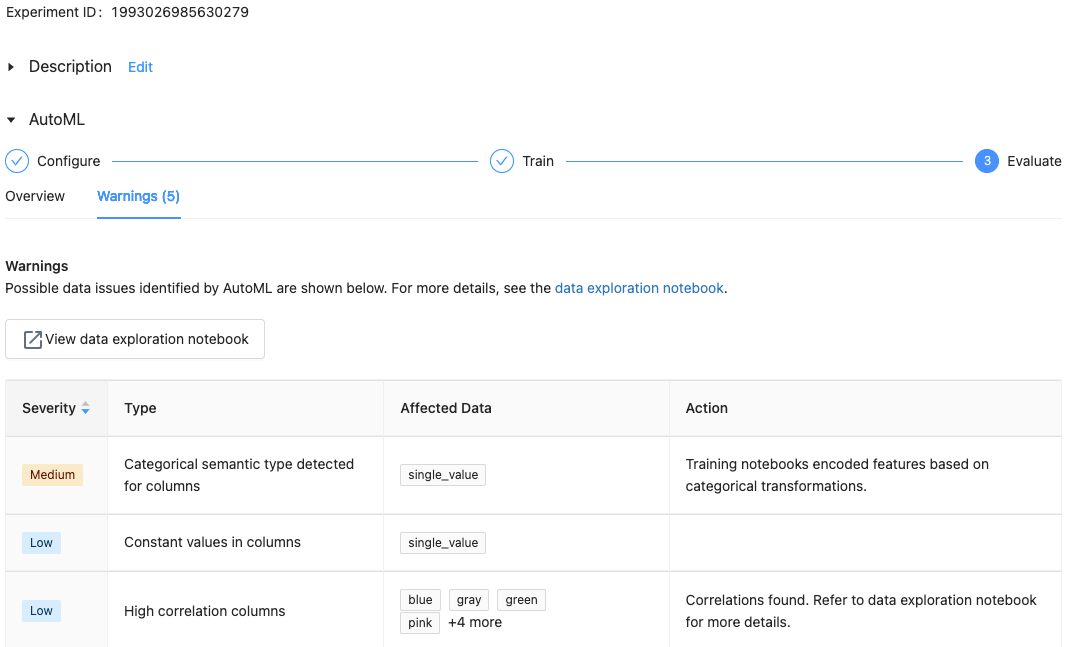
Databricks Runtime 10.1 ML 以降では、AutoML には、サポートされていない column の種類やカーディナリティの高い columnsなど、データセットに関する潜在的な問題に関する警告が表示されます。
注意
Databricks では、潜在的なエラーや問題を示すための最大限の取り組みが行われます。 ただし、これは包括的ではなく、検索対象の問題やエラーをキャプチャしない可能性があります。
データセットについての警告を表示するには、トレーニング ページまたは実験が完了した後の実験ページの [警告] タブをクリックします。
結果の表示
実験が完了すると、次の操作を実行できます。
- MLflow で、モデルのいずれかの 登録およびデプロイ を行います。
- [最適なモデルのノートブックを表示] をSelectして、最適なモデルの作成に使われたノートブックを確認および編集します。
- Selectデータ探索ノートブック を表示して、データ探索ノートブックを開きます。
- 実行table内の実行の検索、フィルター処理、並べ替えを行います。
- 次の操作により、任意の実行の詳細を参照します。
- 生成されたノートブック (試験実行のソース コードを含む) を見つけるには、MLflow 実行をクリックします。 ノートブックは、実行ページの Artifacts セクションに保存されます。 ワークスペース管理者が成果物のダウンロードを有効にしている場合、このノートブックをダウンロードしてワークスペースにインポートできます。
- 実行結果を表示するには、[モデル]column または [開始時刻]columnをクリックします。 実行ページが表示され、試用の実行 (parameters、メトリック、タグなど) と、実行によって作成された成果物 (モデルを含む) に関する情報が表示されます。 このページには、モデルで予測を行うために使用できるコード スニペットも含まれています。
このAutoML実験に後で戻るためには、実験ページのtableでを見つけてください。 データ探索やトレーニング ノートブックを含む各 AutoML 実験の結果は、実験を実行したユーザーのdatabricks_automl内の フォルダーに格納されます。
モデルを登録してデプロイする
モデルの登録とデプロイは、AutoML UI で次のように行います。
- モデルcolumn のモデルを登録するためのリンクを Select にします。 実行が完了すると、一番上の行に (プライマリ メトリックに基づく) 最適なモデルが表示されます。
- Select
 を登録します。
を登録します。 - サイド バーの
![[モデル] アイコン](../../_static/images/icons/models-icon.png) [モデル] をSelectして、モデル レジストリに移動します。
[モデル] をSelectして、モデル レジストリに移動します。 - モデル table内のモデルの名前をSelectします。
- 登録済みのモデルのページから、Model Serving を使用してモデルを提供できます。
'pandas.core.indexes.numeric' という名前のモジュールはありません
AutoML と Model Serving を使用して構築されたモデルを提供すると、エラー No module named 'pandas.core.indexes.numeric が発生することがあります。
これは、AutoML とモデル サービングのエンドポイント環境との間の互換性のない pandas バージョンが原因です。 このエラーは、add-pandas-dependency.py スクリプトを実行することで解決できます。 このスクリプトは、ログに記録されたモデルの requirements.txt と conda.yaml を編集して、適切な pandas 依存関係バージョン pandas==1.5.3 を含めます
- モデルがログされた MLflow 実行の
run_idを含むように、スクリプトを変更します。 - モデルを MLflow モデル レジストリに再登録します。
- MLflow モデルの新しいバージョンをサービングしてみてください。