Apache Airflow を使用して Azure Databricks ジョブを調整する
この記事では、Azure Databricks でデータ パイプラインを調整するための Apache Airflow のサポートについて説明し、Airflow をローカル環境にインストールして構成する手順と、Airflow を使って Azure Databricks ワークフローのデプロイと実行を行う例を示します。
データ パイプラインでのジョブ オーケストレーション
多くの場合、データ処理パイプラインを開発して配置するには、タスク間の複雑な依存関係を管理する必要があります。 たとえば、パイプラインは、ソースからデータを読み取り、データを消去し、クリーニングされたデータを変換し、変換されたデータをターゲットに書き込みます。 また、パイプラインを運用化するときは、テスト、スケジュール設定、エラーのトラブルシューティングに関するサポートも必要です。
ワークフロー システムは、タスク間の依存関係の定義、パイプラインの実行時期のスケジュール設定、およびワークフローの監視を可能にすることで、これらの課題に対処します。 Apache Airflow は、データ パイプラインを管理およびスケジュールするためのオープン ソース ソリューションです。 Airflow は、データ パイプラインを操作の有向非循環グラフ (Dag) として表します。 ユーザーが Python ファイルでワークフローを定義すると、Airflow によってスケジュールと実行が管理されます。 Airflow Azure Databricks 接続を使用すると、Azure Databricks によって提供される最適化された Spark エンジンを使用して、Airflow のスケジュール機能を利用できます。
必要条件
- Airflow と Azure Databricks を統合するには、Airflow バージョン 2.5.0 以降が必要です。 この記事の例は、Airflow バージョン 2.6.1 でテストされています。
- Airflow には、Python 3.8、3.9、3.10、または 3.11 が必要です。 この記事の例は、Python 3.8 でテストされています。
- この記事の手順で Airflow をインストールして実行するには、Python 仮想環境を作成するために pipenv が必要です。
Databricks の Airflow 演算子
Airflow DAG を構成する各タスクでは、Airflow オペレーターが実行されます。 Databricks への統合をサポートする Airflow オペレーターは、Databricks プロバイダーに実装されています。
Databricks プロバイダーには、テーブルへのデータのインポート、SQL クエリの実行、Databricks Git フォルダーの操作など、Azure Databricks ワークスペースを対象とする多数のタスクを実行するオペレーターが含まれています。
Databricks プロバイダーには、ジョブをトリガーするための 2 つのオペレーターが実装されています。
- DatabricksRunNowOperator は、既存の Azure Databricks ジョブを必要とし、POST /api/2.1/jobs/run-now API 要求を使って実行をトリガーします。 Databricks では、ジョブの定義の重複を減らし、このオペレーターによってトリガーされたジョブの実行を
DatabricksRunNowOperatorで見つけることができるので、 を使うことをお勧めします。 - DatabricksSubmitRunOperator では、Azure Databricks にジョブが存在している必要はなく、POST /api/2.1/jobs/runs/submit API 要求を使ってジョブの仕様が送信されて、実行がトリガーされます。
Databricks プロバイダーには、新しい Azure Databricks ジョブの作成または既存のジョブのリセットのために、DatabricksCreateJobsOperator が実装されています。 DatabricksCreateJobsOperator では、POST /api/2.1/jobs/create と POST /api/2.1/jobs/reset の API 要求が使われます。 DatabricksCreateJobsOperator と DatabricksRunNowOperator を使って、ジョブの作成と実行を行うことがことできます。
Note
Databricks オペレーターを使ってジョブをトリガーするには、Databricks の接続構成で資格情報を指定する必要があります。 「Airflow 用の Azure Databricks 個人用アクセス トークンを作成する」をご覧ください。
Databricks Airflow オペレーターは、ジョブ実行ページの URL を、polling_period_seconds ごとに Airflow ログに書き込みます (既定値は 30 秒)。 詳細については、Airflow Web サイトの apache-airflow-providers-databricks パッケージに関するページを参照してください。
Airflow Azure Databricks 統合をローカル環境にインストールする
テストと開発のために Airflow と Databricks プロバイダーをローカル環境にインストールするには、次の手順を使用します。 運用インストールの作成など、他の Airflow インストール オプションについては、Airflow のドキュメントのインストールに関するページをご覧ください。
ターミナルを開き、次のコマンドを実行します。
mkdir airflow
cd airflow
pipenv --python 3.8
pipenv shell
export AIRFLOW_HOME=$(pwd)
pipenv install apache-airflow
pipenv install apache-airflow-providers-databricks
mkdir dags
airflow db init
airflow users create --username admin --firstname <firstname> --lastname <lastname> --role Admin --email <email>
<firstname>、<lastname>、<email> を自分のユーザー名とメール アドレスに置き換えます。 管理者ユーザーのパスワードの入力を求められます。 このパスワードは、Airflow UI にログインするときに必要になるため、必ず保存しておいてください。
このスクリプトでは、次の手順が実行されます。
airflowという名前のディレクトリを作成し、そのディレクトリに移動します。pipenvを使って、Python 仮想環境を作成して生成します。 Databricks では、Python 仮想環境を使用して、パッケージのバージョンとコードの依存関係をその環境に分離することをお勧めします。 この分離により、予期しないパッケージ バージョンの不一致とコード依存関係の競合が軽減されます。AIRFLOW_HOMEという名前の環境変数をairflowディレクトリのパスに設定して初期化します。- Airflow と Airflow Databricks プロバイダーのパッケージをインストールします。
airflow/dagsディレクトリを作成します。 Airflow では、dagsディレクトリを使用してDAG 定義を格納します。- Airflow がメタデータの追跡に使う SQLite データベースを初期化します。 運用環境への Airflow のデプロイでは、標準データベースを使用して Airflow を構成します。 Airflow デプロイの SQLite データベースと既定の構成は、
airflowディレクトリで初期化されます。 - Airflow の管理者ユーザーを作成します。
ヒント
Databricks プロバイダーのインストールを確認するには、Airflow のインストール ディレクトリで次のコマンドを実行します。
airflow providers list
Airflow Web サーバーとスケジューラを開始する
Airflow UI を表示するには、Airflow Web サーバーが必要です。 Web サーバーを起動するには、Airflow のインストール ディレクトリでターミナルを開き、次のコマンドを実行します。
Note
ポートの競合が原因で Airflow Web サーバーの起動が失敗する場合は、Airflow の構成で既定のポートを変更できます。
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow webserver
スケジューラは、DAG をスケジュールする Airflow コンポーネントです。 スケジューラを起動するには、Airflow のインストール ディレクトリで新しいターミナルを開き、次のコマンドを実行します。
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow scheduler
Airflow のインストールをテストする
Airflow のインストールを確認するには、Airflow に含まれる例の DAG のいずれかを実行します。
- ブラウザー ウィンドウで、
http://localhost:8080/homeを開きます。 Airflow のインストール時に作成したユーザー名とパスワードを使って、Airflow UI にログインします。 Airflow の [DAGs] ページが表示されます。 - [DAG の一時停止/一時停止解除] トグルをクリックして、
example_python_operatorなど、DAG の例 の 1 つを一時停止解除します。 - [Trigger DAG] (DAG のトリガー) ボタンをクリックして、DAG の例をトリガーします。
- DAG 名をクリックすると、DAG の実行状態を含む詳細が表示されます。
Airflow 用の Azure Databricks 個人用アクセス トークンを作成する
Airflow は Azure Databricks 個人用アクセス トークン (PAT) を使用して、Databricks に接続します。 PAT を作成するには、 ワークスペース ユーザーの Azure Databricks 個人用アクセス トークンの手順に従います。
Note
セキュリティのベスト プラクティスとして、自動化ツール、システム、スクリプト、アプリを使用して認証する場合、Databricks では、ワークスペース ユーザーではなくサービス プリンシパルに属する個人用アクセス トークンを使用することを推奨しています。 サービス プリンシパルのトークンを作成するには、「サービス プリンシパルのトークンを管理する」をご覧ください。
Microsoft Entra ID のトークンを使って、Azure Databricks に対する認証を行うこともできます。 Airflow のドキュメントの「Databricks の接続」をご覧ください。
Azure Databricks 接続の構成
Airflow インストールには、Azure Databricks の既定の接続が含まれています。 接続を更新して、上で作成した個人用アクセス トークンを使用してワークスペースに接続するには、次の手順を実行します。
- ブラウザー ウィンドウで、
http://localhost:8080/connection/list/を開きます。 サインインを求められたら、管理者のユーザー名とパスワードを入力します。 - [CONN ID] で databricks_default を見つけて、[レコードの編集] ボタンをクリックします。
- [Host] (ホスト) フィールドの値を、Azure Databricks の展開のワークスペース インスタンス名に置き換えます (例:
https://adb-123456789.cloud.databricks.com)。 - [Password] (パスワード) フィールドに、Azure Databricks の個人用アクセス トークンを入力します。
- [保存] をクリックします。
Microsoft Entra ID のトークンを使っている場合の認証の構成方法については、Airflow のドキュメントの「Databricks の接続」をご覧ください。
例: Azure Databricks ジョブを実行するための Airflow DAG を作成する
次の例では、ローカル コンピューターで実行される簡単な Airflow のデプロイを作成し、Azure Databricks のトリガーの実行に DAG の例をデプロイする方法を示します。 この例では、次の操作を行います。
- 新しいノートブックを作成し、構成されたパラメーターに基づいてあいさつを印刷するコードを追加します。
- Notebook を実行する 1 つのタスクで Azure Databricks ジョブを作成します。
- Azure Databricks ワークスペースへの Airflow 接続を構成します。
- ノートブック ジョブをトリガーするための Airflow DAG を作成します。
DatabricksRunNowOperatorを使用して、Python スクリプトの DAG を定義します。 - Airflow UI を使用して、DAG をトリガーし、実行状態を表示します。
ノートブックを作成する
この例では、次の 2 つのセルを含むノートブックを使用します。
ノートブックを作成するには:
Azure Databricks ワークスペースに移動し、サイドバーの
 [新規] をクリックして、[ノートブック] を選びます。
[新規] をクリックして、[ノートブック] を選びます。ノートブックに "Hello Airflow" のような名前を付け、既定の言語が Python に設定されていることを確認します。
次の Python コードをコピーし、ノートブックの最初のセルに貼り付けます。
dbutils.widgets.text("greeting", "world", "Greeting") greeting = dbutils.widgets.get("greeting")最初のセルの下に新しいセルを追加し、次の Python コードをコピーして新しいセルに貼り付けます。
print("hello {}".format(greeting))
ジョブの作成
サイドバーの
![[ワークフロー] アイコン](../../_static/images/icons/workflows-icon.png) [ワークフロー] をクリックします。
[ワークフロー] をクリックします。![[ジョブの作成] ボタン](../../_static/images/jobs/create-job.png) をクリックします。
をクリックします。[タスク] タブが表示され、[タスクの作成] ダイアログが表示されます。
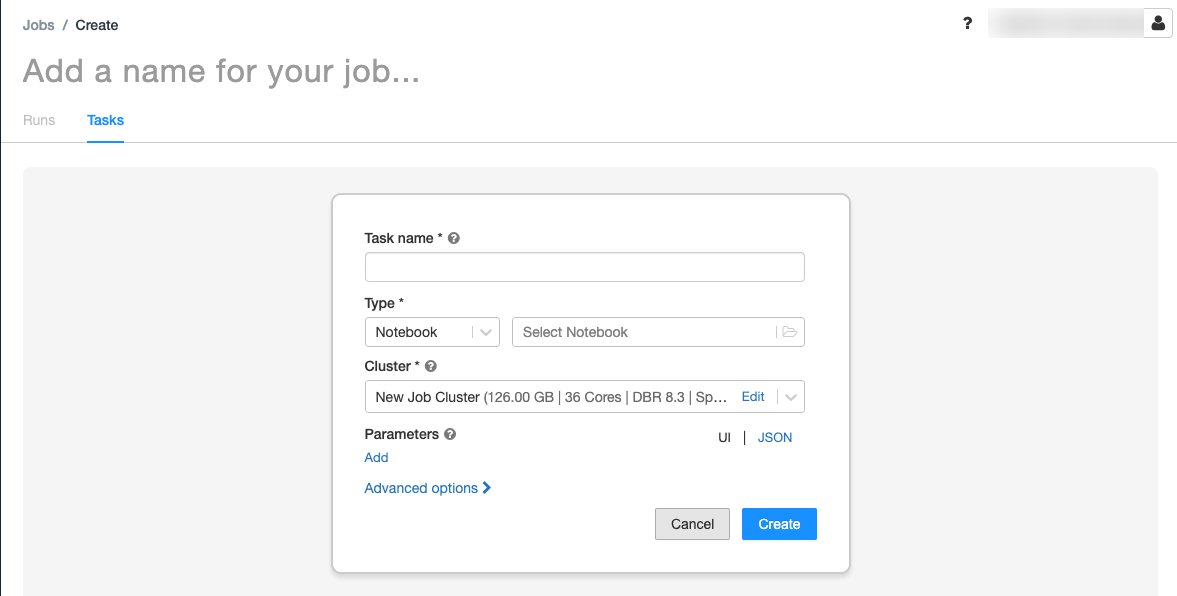
[ジョブ名を追加] を自分のジョブ名に置き換えます。
[タスク名] フィールドに、タスクの名前を入力します。たとえば、「greeting-task」と入力します。
[種類] ドロップダウン メニューで、[ノートブック] を選択します。
[ソース] ドロップダウン メニューで、[ワークスペース] を選びます。
[パス] テキスト ボックスをクリックし、ファイル ブラウザーを使って作成したノートブックを検索し、ノートブック名をクリックして [確認] をクリックします。
[パラメーター] の下の [追加] をクリックします。 [キー] フィールドに「
greeting」と入力します。 “値” フィールドに「Airflow user」と入力します。[タスクの作成] をクリックします。
[ジョブの詳細] パネルで、[ジョブ ID] の値をコピーします。 この値は、ジョブを Airflow からトリガーするために必要です。
ジョブの実行
Azure Databricks ジョブの UI で新しいジョブをテストするには、右上隅にある ![[今すぐ実行] ボタン](../../_static/images/jobs/run-now-button.png) をクリックします。 実行が完了したら、ジョブの実行の詳細を表示して出力を確認できます。
をクリックします。 実行が完了したら、ジョブの実行の詳細を表示して出力を確認できます。
新しい Airflow DAG を作成する
Python ファイルに、Airflow DAG を定義します。 サンプル ノートブック ジョブをトリガーする DAG を作成するには、次のようにします。
テキスト エディターまたは IDE で、次の内容を含む
databricks_dag.pyという名前の新しいファイルを作成します。from airflow import DAG from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator from airflow.utils.dates import days_ago default_args = { 'owner': 'airflow' } with DAG('databricks_dag', start_date = days_ago(2), schedule_interval = None, default_args = default_args ) as dag: opr_run_now = DatabricksRunNowOperator( task_id = 'run_now', databricks_conn_id = 'databricks_default', job_id = JOB_ID )JOB_IDを、前に保存したジョブ ID の値に置き換えます。airflow/dagsディレクトリ内のファイルを保存します。airflow/dags/に格納されている DAG ファイルは、Airflow によって自動的に読み取りおよびインストールされます。
Airflow の DAG をインストールして、検証する
Airflow UI で DAG をトリガーして確認するには、次のようにします。
- ブラウザー ウィンドウで、
http://localhost:8080/homeを開きます。 Airflow DAGs 画面が表示されます。 databricks_dagを見つけて [一時停止/DAG の一時停止解除] トグルをクリックし、DAG を一時停止解除します。- [Trigger DAG] (DAG のトリガー) ボタンをクリックして、DAG をトリガーします。
- 実行の状態と詳細を表示するには、[実行] 列で実行をクリックします。