自動ローダー ファイル通知モードとは
ファイル通知モードでは、自動ローダーは、入力ディレクトリからファイル イベントをサブスクライブする通知サービスとキュー サービスを自動的に設定します。 ファイル通知を使用して、自動ローダーをスケーリングし、1 時間に数百万のファイルを取り込むことができます。 ディレクトリ一覧モードと比較すると、ファイル通知モードは、大規模な入力ディレクトリや大量のファイルに対して高いパフォーマンスと拡張性をもたらしますが、追加のクラウド アクセス許可が必要になります。
ファイル通知とディレクトリ一覧をいつでも切り替えて、データが厳密に 1 回だけ処理されるという保証を引き続き維持できます。
Note
Azure Premium Storage アカウントではファイル通知モードはサポートされていません。Premium アカウントではキュー ストレージがサポートされていないためです。
警告
自動ローダーのソース パスの変更は、ファイル通知モードではサポートされていません。 ファイル通知モードが使用されていて、パスが変更済みの場合にディレクトリを更新する際、新しいディレクトリに既に存在するファイルは、その取り込みに失敗する可能性があります。
自動ローダー ファイル通知モードで使用されるクラウド リソース
重要
ファイル通知モード用にクラウド インフラストラクチャを自動的に構成するには、高い権限のアクセス許可が必要です。 クラウド管理者またはワークスペース管理者に問い合わせてください。以下を参照してください。
自動ローダーは、オプション cloudFiles.useNotifications を true に設定し、クラウド リソースを作成するために必要なアクセス許可を提供すると、自動的にファイル通知を設定できます。 さらに、これらのリソースを作成するための自動ローダー承認を付与するために 追加のオプションを指定する必要がある場合があります。
次の表は、自動ローダーによって作成されるリソースをまとめたものです。
| クラウド ストレージ | サブスクリプション サービス | Queue サービス | プレフィックス * | 極限** |
|---|---|---|---|---|
| Amazon S3 | AWS SNS | AWS SQS | databricks-auto-ingest | S3 バケットあたり 100 |
| ADLS Gen2 | Azure Event Grid | Azure Queue Storage | databricks | ストレージ アカウントあたり 500 |
| GCS | Google Pub/Sub | Google Pub/Sub | databricks-auto-ingest | GCS バケットあたり 100 |
| Azure Blob Storage | Azure Event Grid | Azure Queue Storage | databricks | ストレージ アカウントあたり 500 |
- 自動ローダーにより、このプレフィックスを使用してリソースに名前を付けます。
** 起動できる同時実行ファイル通知パイプラインの数
特定のストレージ アカウントに対して、限られた数を超えるファイル通知パイプラインを実行する必要がある場合は、次のように行えます。
- AWS Lambda、Azure Functions、Google Cloud Functions などのサービスを利用して、コンテナーまたはバケット全体をリッスンする単一のキューからの通知を、ディレクトリ固有のキューにファンアウトします。
ファイル通知イベント
Amazon S3 では、put アップロードによってアップロードされたか、マルチパート アップロードによってアップロードされたかにかかわらず、S3 バケットにファイルがアップロードされたときに ObjectCreated イベントが提供されます。
ADLS Gen2 では、Gen2 コンテナーに表示されるファイルに対して異なるイベント通知が提供されます。
- 自動ローダーは、ファイルを処理するために
FlushWithCloseイベントをリッスンします。 - 自動ローダー ストリームでは、ファイルを検出するための
RenameFileアクションがサポートされています。RenameFileアクションでは、名前が変更されたファイルのサイズを取得するために、ストレージ システムへの API 要求が必要です。 - Databricks Runtime 9.0 以降で作成された自動ローダー ストリームは、ファイルを検出するための
RenameDirectoryアクションをサポートします。RenameDirectoryアクションでは、名前が変更されたディレクトリの内容を一覧表示するために、ストレージ システムへの API 要求が必要です。
Google Cloud Storage では、ファイルのアップロード時に、上書きやファイル コピーなどの OBJECT_FINALIZE イベントが提供されます。 失敗したアップロードでは、このイベントは生成されません。
Note
クラウド プロバイダーは、非常にまれな条件下ですべてのファイル イベントの 100% 配信を保証するわけではありません。また、ファイル イベントの待機時間に関する厳密な SLA も提供しません。 Databricks では、データの完全性が要件になる場合、cloudFiles.backfillInterval オプションを使用することで自動ローダーによる定期的なバックフィルをトリガーし、所定の SLA の範囲内ですべてのファイルが検出されるように保証することを推奨しています。 定期的なバックフィルをトリガーしても、重複は発生しません。
ADLS Gen2 および Azure Blob Storage のファイル通知を構成するために必要なアクセス許可
入力ディレクトリに対する読み取りアクセス許可が必要です。 「Azure Blob ストレージ」を参照してください。
ファイル通知モードを使用するには、イベント通知サービスを設定してアクセスするための認証資格情報を指定する必要があります。
認証には、次のいずれかの方法を使用できます。
- Databricks サービス資格情報 (推奨): マネージド ID と Databricks アクセス コネクタを使用して、サービス資格情報 を作成します。
- サービス プリンシパル: Microsoft Entra ID (旧称 Azure Active Directory) アプリとサービス プリンシパル をクライアント ID とクライアント シークレットの形式で作成します。
認証資格情報を取得したら、Databricks アクセス コネクタ (サービス資格情報の場合) または Microsoft Entra ID アプリ (サービス プリンシパルの場合) に必要なアクセス許可を割り当てます。
Azure 組み込みロールの使用
入力パスが存在するストレージ アカウントに、アクセス コネクタに次のロールを割り当てます。
- 共同作成者: これは、キューやイベント サブスクリプションなど、ストレージ アカウント内のリソースを設定するためのロールです。
- ストレージ キュー データ共同作成者: これは、キューからのメッセージの取得や削除などのキュー操作を実行するためのロールです。 このロールは、接続文字列を指定せずにサービス プリンシパルを指定する場合にのみ必要です。
このアクセス コネクタに、関連するリソース グループに次のロールを割り当てます。
- EventGrid EventSubscription 共同作成者: このロールは、イベント サブスクリプションの作成や一覧表示など、Azure Event Grid (Event Grid) サブスクリプション操作を実行するためのロールです。
詳細については、Azure portal を使用して Azure ロールを割り当てる方法に関するページを参照してください。
カスタム ロールの使用
上記のロールに必要なアクセス許可の過剰な付与が懸念される場合は、Azure ロールの JSON 形式で、以下に一覧表示されている、少なくとも次のアクセス許可を持つカスタム役割を作成できます。
"permissions": [ { "actions": [ "Microsoft.EventGrid/eventSubscriptions/write", "Microsoft.EventGrid/eventSubscriptions/read", "Microsoft.EventGrid/eventSubscriptions/delete", "Microsoft.EventGrid/locations/eventSubscriptions/read", "Microsoft.Storage/storageAccounts/read", "Microsoft.Storage/storageAccounts/write", "Microsoft.Storage/storageAccounts/queueServices/read", "Microsoft.Storage/storageAccounts/queueServices/write", "Microsoft.Storage/storageAccounts/queueServices/queues/write", "Microsoft.Storage/storageAccounts/queueServices/queues/read", "Microsoft.Storage/storageAccounts/queueServices/queues/delete" ], "notActions": [], "dataActions": [ "Microsoft.Storage/storageAccounts/queueServices/queues/messages/delete", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/read", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/write", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/process/action" ], "notDataActions": [] } ]その後、このカスタム ロールをアクセス コネクタに割り当てることができます。
詳細については、Azure portal を使用して Azure ロールを割り当てる方法に関するページを参照してください。
Amazon S3 のファイル通知を構成するために必要なアクセス許可
入力ディレクトリに対する読み取りアクセス許可が必要です。 詳細については、S3 接続の詳細を参照してください。
ファイル通知モードを使用するには、次の JSON ポリシー ドキュメントを IAM ユーザーまたはロールにアタッチします。 この IAM ロールは、自動ローダーの認証に使用するサービス資格情報を作成するために必要です。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DatabricksAutoLoaderSetup",
"Effect": "Allow",
"Action": [
"s3:GetBucketNotification",
"s3:PutBucketNotification",
"sns:ListSubscriptionsByTopic",
"sns:GetTopicAttributes",
"sns:SetTopicAttributes",
"sns:CreateTopic",
"sns:TagResource",
"sns:Publish",
"sns:Subscribe",
"sqs:CreateQueue",
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:SendMessage",
"sqs:GetQueueUrl",
"sqs:GetQueueAttributes",
"sqs:SetQueueAttributes",
"sqs:TagQueue",
"sqs:ChangeMessageVisibility",
"sqs:PurgeQueue"
],
"Resource": [
"arn:aws:s3:::<bucket-name>",
"arn:aws:sqs:<region>:<account-number>:databricks-auto-ingest-*",
"arn:aws:sns:<region>:<account-number>:databricks-auto-ingest-*"
]
},
{
"Sid": "DatabricksAutoLoaderList",
"Effect": "Allow",
"Action": [
"sqs:ListQueues",
"sqs:ListQueueTags",
"sns:ListTopics"
],
"Resource": "*"
},
{
"Sid": "DatabricksAutoLoaderTeardown",
"Effect": "Allow",
"Action": [
"sns:Unsubscribe",
"sns:DeleteTopic",
"sqs:DeleteQueue"
],
"Resource": [
"arn:aws:sqs:<region>:<account-number>:databricks-auto-ingest-*",
"arn:aws:sns:<region>:<account-number>:databricks-auto-ingest-*"
]
}
]
}
各値の説明:
<bucket-name>: ストリームがファイルを読み取る S3 バケット名 (例:auto-logs)。 ワイルドカードとして*を使用できます (例:databricks-*-logs)。 DBFS パスの基になる S3 バケットを調べるには、%fs mountsを実行して、ノートブック内のすべての DBFS マウント ポイントを一覧表示できます。<region>: S3 バケットが存在する AWS リージョン (例:us-west-2)。 リージョンを指定しない場合は、*を使用します。<account-number>: S3 バケットを所有する AWS アカウント番号 (例:123456789012)。 アカウント番号を指定しない場合は、*を使用します。
SQS および SNS ARN 指定の文字列 databricks-auto-ingest-* は、SQS および SNS サービスを作成するときに cloudFiles ソースで使用される名前プレフィックスです。 Azure Databricks は、ストリームの初回実行時に通知サービスを設定するため、最初の実行後にアクセス許可が削減されたポリシーを使用できます (たとえば、ストリームを停止してから再起動するなど)。
Note
前のポリシーは、ファイル通知サービス (つまり、S3 バケット通知、SNS、および SQS の各サービス) を設定するために必要なアクセス許可にのみ関係し、S3 バケットへの読み取りアクセス権が既にあることを想定しています。 S3 読み取り専用のアクセス許可を追加する必要がある場合は、JSON ドキュメントの DatabricksAutoLoaderSetup ステートメントの Action リストに次を追加します。
s3:ListBuckets3:GetObject
初期セットアップ後のアクセス許可の削減
上記のリソース設定のアクセス許可は、ストリームの最初の実行時にのみ必要になります。 最初の実行後は、アクセス許可が削減された次の IAM ポリシーに切り替えることができます。
重要
アクセス許可を減らすと、障害が発生した場合に新しいストリーミング クエリを開始したり、リソースを再作成したりすることはできません (たとえば、SQS キューが誤って削除されました)。また、クラウド リソース管理 API を使用してリソースを一覧表示または破棄することもできません。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DatabricksAutoLoaderUse",
"Effect": "Allow",
"Action": [
"s3:GetBucketNotification",
"sns:ListSubscriptionsByTopic",
"sns:GetTopicAttributes",
"sns:TagResource",
"sns:Publish",
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:SendMessage",
"sqs:GetQueueUrl",
"sqs:GetQueueAttributes",
"sqs:TagQueue",
"sqs:ChangeMessageVisibility",
"sqs:PurgeQueue"
],
"Resource": [
"arn:aws:sqs:<region>:<account-number>:<queue-name>",
"arn:aws:sns:<region>:<account-number>:<topic-name>",
"arn:aws:s3:::<bucket-name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<bucket-name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<bucket-name>/*"
]
},
{
"Sid": "DatabricksAutoLoaderListTopics",
"Effect": "Allow",
"Action": [
"sqs:ListQueues",
"sqs:ListQueueTags",
"sns:ListTopics"
],
"Resource": "arn:aws:sns:<region>:<account-number>:*"
}
]
}
GCS のファイル通知を構成するために必要なアクセス許可
GCS バケットとすべてのオブジェクトに対する list および get の権限が必要です。 詳細については、IAM 権限に関する Google ドキュメントを参照してください。
ファイル通知モードを使用するには、GCS サービス アカウントの と、Google Cloud Pub/Sub リソースへのアクセスに使用するサービス アカウントのアクセス許可を追加する必要があります。
GCS サービス アカウントに Pub/Sub Publisher ロールを追加します。 これにより、このアカウントで GCS バケットから Google Cloud Pub/Sub にイベント通知メッセージを発行できます。
Google Cloud Pub/Sub リソースに使用されるサービス アカウントについては、次のアクセス許可を追加する必要があります。 このサービス アカウントは、Databricks サービス資格情報を作成すると自動的に作成されます。
pubsub.subscriptions.consume
pubsub.subscriptions.create
pubsub.subscriptions.delete
pubsub.subscriptions.get
pubsub.subscriptions.list
pubsub.subscriptions.update
pubsub.topics.attachSubscription
pubsub.topics.create
pubsub.topics.delete
pubsub.topics.get
pubsub.topics.list
pubsub.topics.update
これを行うには、これらの権限を持つ IAM カスタム ロールを作成するか、これらの権限をカバーする既存の GCP ロールを割り当てます。
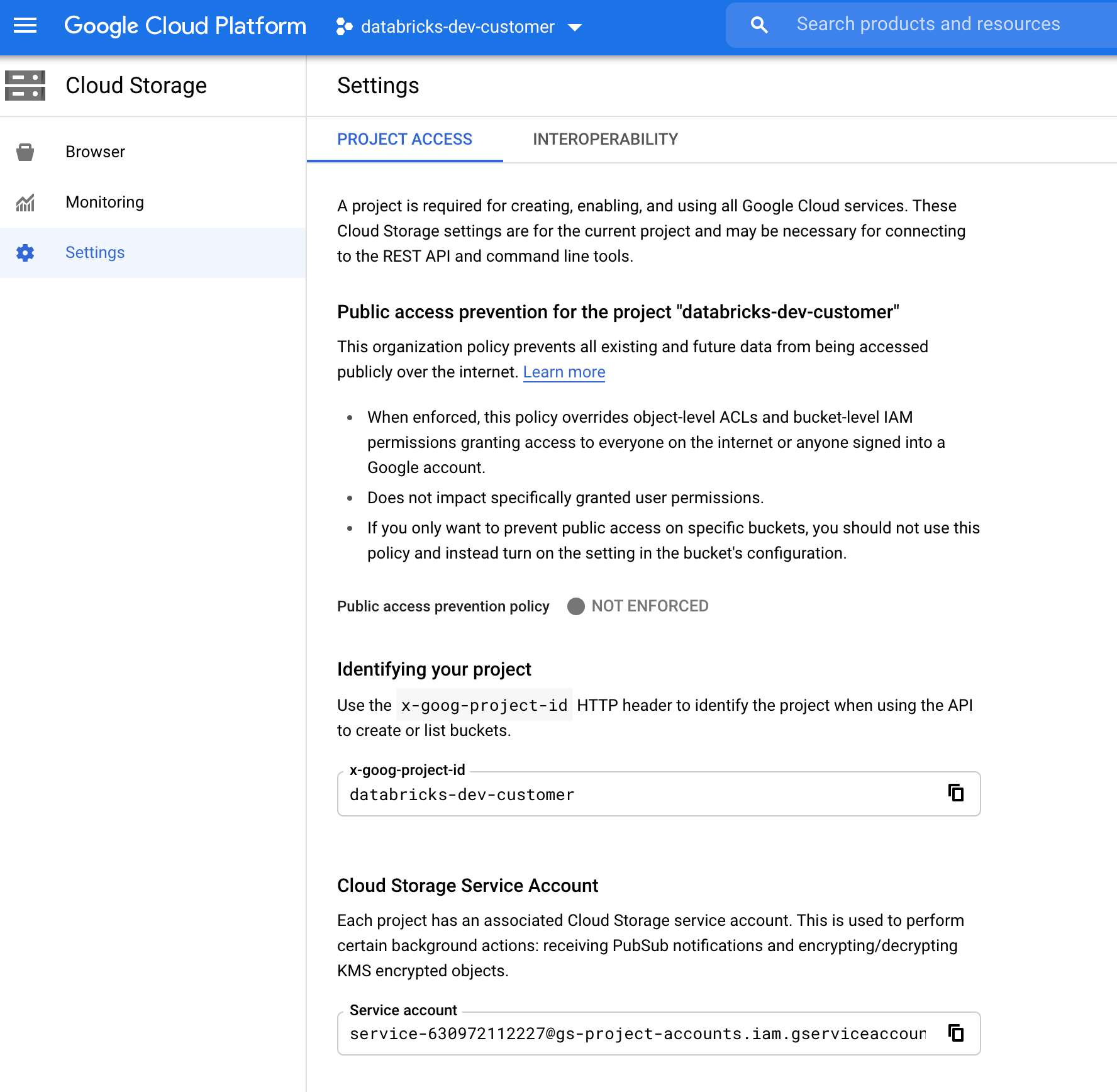
GCS サービス アカウントを見つける
対応するプロジェクトの Google Cloud Console で、Cloud Storage > Settings に移動します。
[Cloud Storage サービス アカウント] セクションには、GCS サービス アカウントのメールアドレスが含まれます。
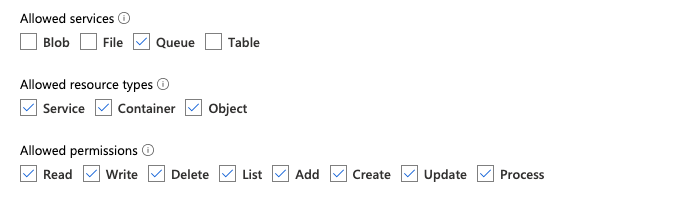
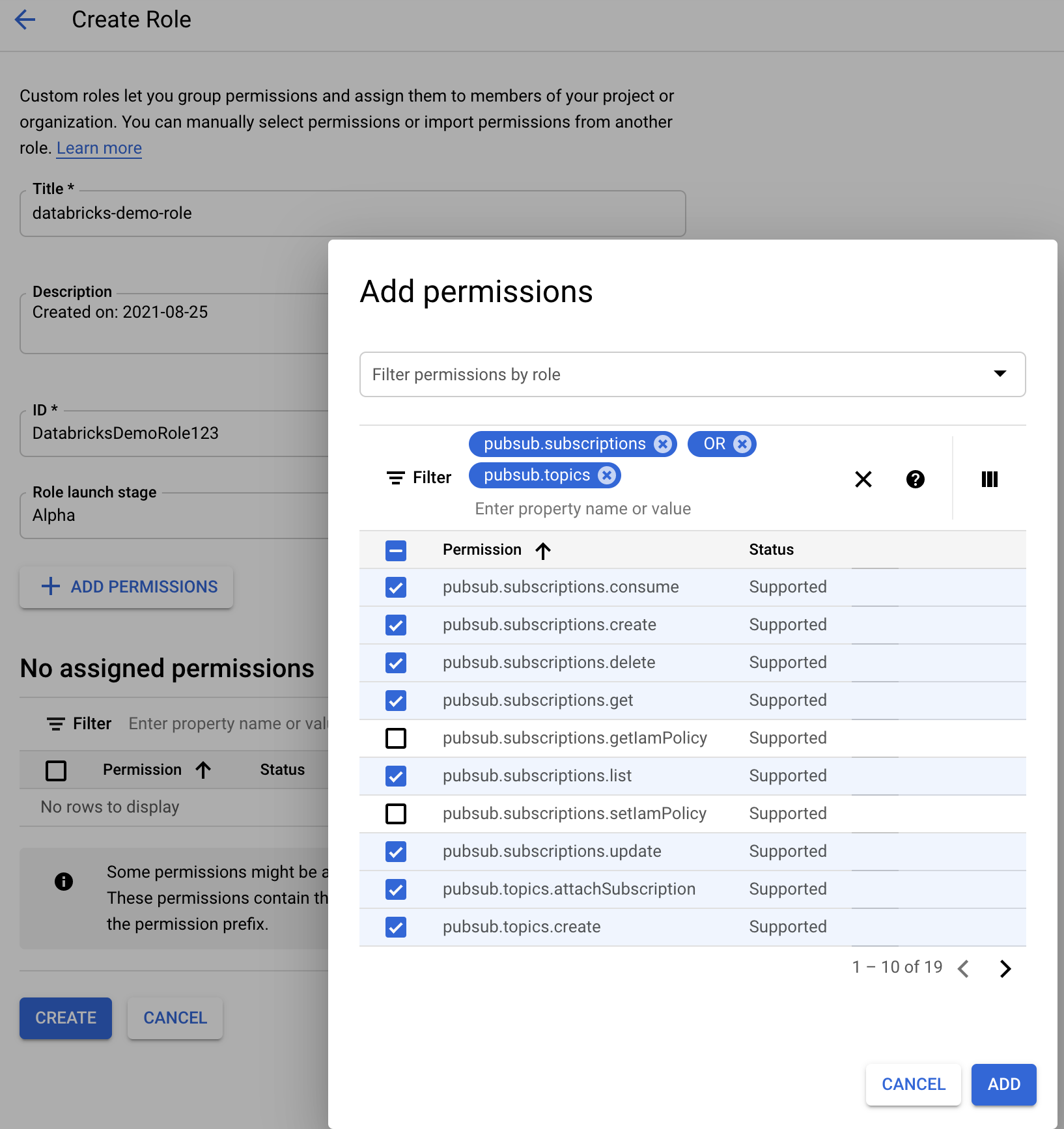
ファイル通知モード用のカスタム Google Cloud IAM ロールを作成する
対応するプロジェクトの Google Cloud Console で、IAM & Admin > Roles に移動します。 次に、上部にロールを作成するか、既存のロールを更新します。 ロールの作成または編集の画面で、Add Permissions をクリックします。 メニューが表示され、ここで必要な権限をロールに追加できます。
ファイル通知リソースを手動で構成または管理する
権限のあるユーザーは、ファイル通知リソースを手動で構成または管理することができます。
- クラウド プロバイダーを使用してファイル通知サービスを手動で設定し、キュー識別子を手動で指定します。 詳細については「ファイル通知オプション」を参照してください。
- 次の例に示すように、Scala API を使用して、通知サービスとキュー サービスを作成または管理します。
Python
# Databricks notebook source
# MAGIC %md ## Python bindings for CloudFiles Resource Managers for all 3 clouds
# COMMAND ----------
#####################################
## Creating a ResourceManager in AWS
#####################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesAWSResourceManager \
.newManager() \
.option("cloudFiles.region", <region>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.create()
# Using AWS access key and secret key
manager = spark._jvm.com.databricks.sql.CloudFilesAWSResourceManager \
.newManager() \
.option("cloudFiles.region", <region>) \
.option("cloudFiles.awsAccessKey", <aws-access-key>) \
.option("cloudFiles.awsSecretKey", <aws-secret-key>) \
.option("cloudFiles.roleArn", <role-arn>) \
.option("cloudFiles.roleExternalId", <role-external-id>) \
.option("cloudFiles.roleSessionName", <role-session-name>) \
.option("cloudFiles.stsEndpoint", <sts-endpoint>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
#######################################
## Creating a ResourceManager in Azure
#######################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesAzureResourceManager \
.newManager() \
.option("cloudFiles.resourceGroup", <resource-group>) \
.option("cloudFiles.subscriptionId", <subscription-id>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.option("path", <path-to-specific-container-and-folder>) \
.create()
# Using an Azure service principal
manager = spark._jvm.com.databricks.sql.CloudFilesAzureResourceManager \
.newManager() \
.option("cloudFiles.connectionString", <connection-string>) \
.option("cloudFiles.resourceGroup", <resource-group>) \
.option("cloudFiles.subscriptionId", <subscription-id>) \
.option("cloudFiles.tenantId", <tenant-id>) \
.option("cloudFiles.clientId", <service-principal-client-id>) \
.option("cloudFiles.clientSecret", <service-principal-client-secret>) \
.option("path", <path-to-specific-container-and-folder>) \
.create()
#######################################
## Creating a ResourceManager in GCP
#######################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesGCPResourceManager \
.newManager() \
.option("cloudFiles.projectId", <project-id>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
# Using a Google service account
manager = spark._jvm.com.databricks.sql.CloudFilesGCPResourceManager \
.newManager() \
.option("cloudFiles.projectId", <project-id>) \
.option("cloudFiles.client", <client-id>) \
.option("cloudFiles.clientEmail", <client-email>) \
.option("cloudFiles.privateKey", <private-key>) \
.option("cloudFiles.privateKeyId", <private-key-id>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
# Set up a queue and a topic subscribed to the path provided in the manager.
manager.setUpNotificationServices(<resource-suffix>)
# List notification services created by <AL>
from pyspark.sql import DataFrame
df = DataFrame(manager.listNotificationServices(), spark)
# Tear down the notification services created for a specific stream ID.
# Stream ID is a GUID string that you can find in the list result above.
manager.tearDownNotificationServices(<stream-id>)
Scala
/////////////////////////////////////
// Creating a ResourceManager in AWS
/////////////////////////////////////
import com.databricks.sql.CloudFilesAWSResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesAWSResourceManager
.newManager
.option("cloudFiles.region", <region>) // optional, will use the region of the EC2 instances by default
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-bucket-and-folder>) // required only for setUpNotificationServices
.create()
/**
* Using AWS access key and secret key
*/
val manager = CloudFilesAWSResourceManager
.newManager
.option("cloudFiles.region", <region>)
.option("cloudFiles.awsAccessKey", <aws-access-key>)
.option("cloudFiles.awsSecretKey", <aws-secret-key>)
.option("cloudFiles.roleArn", <role-arn>)
.option("cloudFiles.roleExternalId", <role-external-id>)
.option("cloudFiles.roleSessionName", <role-session-name>)
.option("cloudFiles.stsEndpoint", <sts-endpoint>)
.option("path", <path-to-specific-bucket-and-folder>) // required only for setUpNotificationServices
.create()
///////////////////////////////////////
// Creating a ResourceManager in Azure
///////////////////////////////////////
import com.databricks.sql.CloudFilesAzureResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesAzureResourceManager
.newManager
.option("cloudFiles.resourceGroup", <resource-group>)
.option("cloudFiles.subscriptionId", <subscription-id>)
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-container-and-folder>) // required only for setUpNotificationServices
.create()
/**
* Using an Azure service principal
*/
val manager = CloudFilesAzureResourceManager
.newManager
.option("cloudFiles.connectionString", <connection-string>)
.option("cloudFiles.resourceGroup", <resource-group>)
.option("cloudFiles.subscriptionId", <subscription-id>)
.option("cloudFiles.tenantId", <tenant-id>)
.option("cloudFiles.clientId", <service-principal-client-id>)
.option("cloudFiles.clientSecret", <service-principal-client-secret>)
.option("path", <path-to-specific-container-and-folder>) // required only for setUpNotificationServices
.create()
///////////////////////////////////////
// Creating a ResourceManager in GCP
///////////////////////////////////////
import com.databricks.sql.CloudFilesGCPResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesGCPResourceManager
.newManager
.option("cloudFiles.projectId", <project-id>)
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-bucket-and-folder>) // Required only for setUpNotificationServices.
.create()
/**
* Using a Google service account
*/
val manager = CloudFilesGCPResourceManager
.newManager
.option("cloudFiles.projectId", <project-id>)
.option("cloudFiles.client", <client-id>)
.option("cloudFiles.clientEmail", <client-email>)
.option("cloudFiles.privateKey", <private-key>)
.option("cloudFiles.privateKeyId", <private-key-id>)
.option("path", <path-to-specific-bucket-and-folder>) // Required only for setUpNotificationServices.
.create()
// Set up a queue and a topic subscribed to the path provided in the manager.
manager.setUpNotificationServices(<resource-suffix>)
// List notification services created by <AL>
val df = manager.listNotificationServices()
// Tear down the notification services created for a specific stream ID.
// Stream ID is a GUID string that you can find in the list result above.
manager.tearDownNotificationServices(<stream-id>)
setUpNotificationServices(<resource-suffix>) を使用して、名前 <prefix>-<resource-suffix> を持つキューとサブスクリプションを作成します (プレフィックスは「自動ローダー ファイル通知モードで使用されるクラウド リソース」で要約されているストレージ システムにより異なります)。 同じ名前の既存のリソースがある場合、Azure Databricks は、新たに作成する代わりに、既存のリソースを再利用します。 この関数は、ファイル通知オプションの識別子を使用して、cloudFiles ソースに渡すことができるキュー識別子を返します。 これにより、cloudFiles ソース ユーザーに、リソースを作成するユーザーよりも少ないアクセス許可を付与できます。
"path" オプションは、newManager を呼び出す場合にのみ setUpNotificationServices に指定します。listNotificationServices または tearDownNotificationServices では必要ありません。 これは、ストリーミング クエリを実行するときに使用するのと同じ path です。
次の表は、ストレージの種類ごとに Databricks Runtime でサポートされている API メソッドを示しています。
| クラウド ストレージ | API のセットアップ | API の一覧表示 | API の破棄 |
|---|---|---|---|
| Amazon S3 | すべてのバージョン | すべてのバージョン | すべてのバージョン |
| ADLS Gen2 | すべてのバージョン | すべてのバージョン | すべてのバージョン |
| GCS | Databricks Runtime 9.1 以降 | Databricks Runtime 9.1 以降 | Databricks Runtime 9.1 以降 |
| Azure Blob Storage | すべてのバージョン | すべてのバージョン | すべてのバージョン |
| ADLS Gen1 | サポートされていません | サポートされていません | サポートされていません |
一般的なエラーのトラブルシューティング
このセクションでは、ファイル通知モードで自動ローダーを使用する場合の一般的なエラーとその解決方法について説明します。
Event Grid サブスクリプションを作成できませんでした
自動ローダーを初めて実行したときに次のエラー メッセージが表示される場合、Event Grid は Azure サブスクリプションのリソース プロバイダーとして登録されていません。
java.lang.RuntimeException: Failed to create event grid subscription.
Event Grid をリソース プロバイダーとして登録するには、次の操作を行います。
- Azure portal で、ご自分のサブスクリプションに移動します。
- [設定] セクション リソース プロバイダーの をクリックします。
- プロバイダー
Microsoft.EventGridを登録します。
Event Grid サブスクリプション操作を実行するために必要な認可
自動ローダーを初めて実行したときに次のエラー メッセージが表示される場合は、共同作成者ロールが Event Grid とストレージ アカウントのサービス プリンシパルに割り当てられていることを確認してください。
403 Forbidden ... does not have authorization to perform action 'Microsoft.EventGrid/eventSubscriptions/[read|write]' over scope ...
Event Grid クライアントがプロキシをバイパスする
Databricks Runtime 15.2 以降では、自動ローダーの Event Grid 接続では、既定でシステム プロパティからのプロキシ設定が使用されます。 Databricks Runtime 13.3 LTS、14.3 LTS、および 15.0 から 15.2 では、Spark Config プロパティ spark.databricks.cloudFiles.eventGridClient.useSystemProperties true設定することで、プロキシを使用するように Event Grid 接続を手動で構成できます。 Azure Databricks で Spark 構成プロパティを設定するを参照してください。