AI 開発における RAG の概要
この記事では、検索拡張生成 (RAG) の概要、しくみ、および主要な概念について説明します。
検索拡張生成とは
RAG は、大規模な言語モデル (LLM) が外部の情報ソースから検索したサポート データを使用してユーザーのプロンプトを拡張して、豊富な応答を生成できるようにする手法です。 この検索した情報を組み込むことで、RAG を使用すると、プロンプトを追加のコンテキストで拡張しない場合に比べて、LLM はより正確で高品質な応答を生成できます。
たとえば、あなたは、会社の独自のドキュメントに関する質問に回答できる質問応答のチャットボットを構築しているとします。 スタンドアロンの LLM では、これらのドキュメントに対して特別にトレーニングされていなければ、これらのドキュメントの内容に関する質問に正確に答えることはできません。 LLM は、情報が不足しているために回答を拒否したり、さらに悪い場合は間違った応答を生成したりすることがあります。
RAG では、まずユーザーのクエリに基づいて会社のドキュメントから関連情報を検索し、次に検索した情報を追加のコンテキストとして LLM に提供して、この問題に対処します。 これにより、LLM は関連文書に記載されている具体的な詳細を利用して、より正確な応答を生成できるようになります。 本質的には、RAG により、LLM は検索した情報を "参照" して回答を作成できるようになります。
RAG アプリケーションのコア コンポーネント
RAG アプリケーションは、複合 AI システムの一例です。これにより、モデル単体の言語機能が他のツールや手順と組み合わされて拡張されます。
スタンドアロン LLM を使用する場合、ユーザーは質問などの要求を LLM に送信し、LLM はトレーニング データのみに基づいて回答を返します。
この最も基本的な形式では、RAG アプリケーションで次の手順が行われます。
- 検索: ユーザーの要求 は、外部の情報ソースに対してクエリを実行するために使用されます。 これは、ベクター ストアのクエリ、テキストに対するキーワード検索、または SQL データベースのクエリの実行を意味する場合があります。 検索手順の目的は、LLM が有用な応答を提供するのに役立つ サポート データ を取得することです。
- 拡張: 検索手順のサポート データは、ユーザーの要求と組み合わされ、多くの場合、追加の書式設定と LLM への指示を含むテンプレートを使用して、プロンプトを作成します。
- 生成: 結果のプロンプトが LLM に渡され、LLM によってユーザーの要求に対する応答が生成されます。
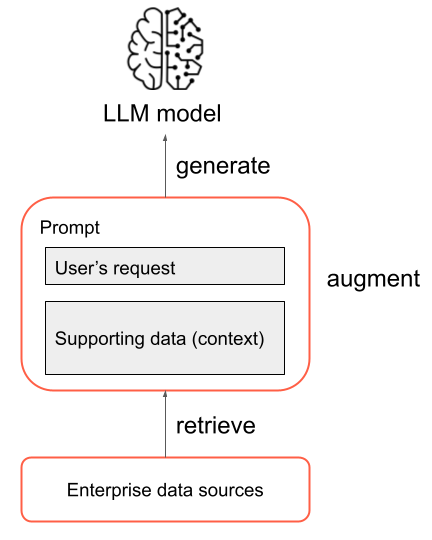
これは RAG プロセスの簡略化した概要ですが、RAG アプリケーションの実装には多くの複雑なタスクが含まれることに注意することが重要です。 RAG での使用に適応するようにソース データを前処理し、効率的にデータを検索し、拡張プロンプトを書式設定し、生成された応答を評価するには、すべてに慎重な検討と労力が必要です。 これらのトピックについては、このガイドの後続のセクションで詳しく説明します。
RAG を使用する理由
次の表に、RAG とスタンドアロン LLM を使用する利点の概要を示します。
| LLM のみ | RAG と LLM を併用 |
|---|---|
| 独自の知識がない: LLM は、一般に公開されているデータに対してトレーニングされるため、会社の内部データや独自のデータに関する質問に正確に答えることはできません。 | RAG アプリケーションは、独自のデータを組み込むことができる RAG アプリケーションは、メモ、メール、デザイン ドキュメントなどの独自のドキュメントを LLM に提供して、LLM がそれらのドキュメントに関する質問に答えられるようにします。 |
| 知識がリアルタイムで更新されない: LLM は、トレーニング後に発生したイベントに関する情報にアクセスできません。 たとえば、スタンドアロン LLM は、今日の在庫移動について何も伝えることができません。 | RAG アプリケーションはリアルタイム データにアクセスできる: RAG アプリケーションは、更新されたデータ ソースからタイムリーな情報を LLM に提供できるため、トレーニングの終了日を過ぎたイベントに関する有用な回答を提供できます。 |
| 引用の欠如: LLM は応答時に特定の情報ソースを引用できず、ユーザーは応答が事実に基づいていて正しいか、またはハルシネーションであるかを確認できません。 | RAG はソースを引用できる: RAG アプリケーションの一部として使用される場合、LLM はその出典を引用するよう求められることがあります。 |
| データ アクセス制御 (ACL) の欠如: LLM だけでは、特定のユーザーのアクセス許可に基づいて別々のユーザーに個別の回答を確実に提供することはできません。 | RAG では、データ セキュリティ/ACL を使用できる: 検索手順は、ユーザーがアクセスする資格情報を持っている情報のみを検索するように設計でき、RAG アプリケーションにより、個人または独自の情報を選択的に検索することができます。 |
RAG の種類
RAG アーキテクチャは、次の 2 種類のサポート データで動作します。
| 構造化データ | 非構造化データ | |
|---|---|---|
| Definition | データベース内のテーブルなどの、特定のスキーマを持つ行と列に配置された表形式データ。 | テキストや画像を含む可能性のあるドキュメントや、オーディオや動画などのマルチメディア コンテンツなど、特定の構造や構成を持たないデータ。 |
| データ ソースの例 | - BI または Data Warehouse システム内の顧客レコード - SQL Database のトランザクション データ - アプリケーション API からのデータ (SAP、Salesforce など) |
- BI または Data Warehouse システム内の顧客レコード - SQL Database のトランザクション データ - アプリケーション API からのデータ (SAP、Salesforce など) - Google または Microsoft Office ドキュメント - Wiki - 画像 - ビデオ |
RAG のデータの選択は、ユース ケースによって異なります。 このチュートリアルの残りの部分では、非構造化データの RAG に焦点を当てます。