ベクトル検索インデックスを作成してクエリを実行する方法
この記事では、Mosaic AI Vector Search を使用してベクトル検索インデックスを作成し、クエリを実行する方法について説明します。
ベクトル検索のコンポーネント (ベクトル検索エンドポイントやベクトル検索インデックスなど) は、UI、Python SDK、または REST API を使用して作成および管理することができます。
要件
- Unity Catalog 対応ワークスペース。
- サーバーレス コンピューティングが有効になっている。 手順については、「サーバーレス コンピューティングに接続する」を参照してください。
- 変更データ フィードが有効なソース テーブル。 手順については、「Azure Databricks で Delta Lake 変更データ フィードを使用する」を参照してください。
- インデックスを作成するには、インデックスを作成するカタログ スキーマに対して CREATE TABLE 特権が必要です。 別のユーザーが所有するインデックスにクエリを実行するには、追加の特権が必要です。 「ベクトル検索エンドポイントにクエリを実行する」を参照してください。
- 個人用アクセス トークンを使用する場合 (運用ワークロードにはお勧めできません)、個人用アクセス トークンが有効になっていることを確認してください。 代わりにサービス プリンシパル トークンを使用するには、SDK または API 呼び出しを使用して明示的に渡します。
SDK を使用するには、ノートブックにインストールする必要があります。 次のコードを使用します。
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
ベクトル検索エンドポイントを作成する
Databricks UI、Python SDK、または API を使用して、ベクトル検索エンドポイントを作成することができます。
UI を使用してベクトル検索エンドポイントを作成する
UI を使用してベクトル検索エンドポイントを作成するには、次の手順に従います。
左側サイドバー内で、[コンピューティング] をクリックします。
[ベクトル検索] タブをクリックして、[作成] をクリックします。

[エンドポイントの作成] フォームが開きます。 このエンドポイントの名前を入力します。
[Confirm](確認) をクリックします。
Python SDK を使用してベクトル検索エンドポイントを作成する
次の例では、create_endpoint() SDK 関数を使用してベクトル検索エンドポイントを作成します。
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
REST API を使用してベクトル検索エンドポイントを作成する
REST API リファレンス ドキュメント「 POST /api/2.0/vector-search/endpointsを参照してください。
(省略可能) 埋め込みモデルを提供するエンドポイントを作成および構成する
Databricks で埋め込みを計算することを選択した場合、事前に構成された Foundation Model API エンドポイントを使用するか、モデル提供エンドポイントを作成して、任意の埋め込みモデルを提供できます。 手順については、「トークン単位の支払いの Foundation Model API」または「生成 AI モデル提供エンドポイントを作成する」を参照してください。 ノートブックの例については、「埋め込みモデルを呼び出すためのノートブックの例」をご参照ください。
埋め込みエンドポイントを構成する場合、Databricks では、既定の [Scale to zero] の選択を外すことをお勧めします。 サービング エンドポイントではウォームアップに数分かかる場合があり、スケール ダウンされたエンドポイントを含むインデックスに対する最初のクエリがタイムアウトする可能性があります。
Note
埋め込みエンドポイントがデータセット用に適切に構成されていない場合、ベクトル検索インデックスの初期化がタイムアウトになる可能性があります。 CPU エンドポイントは、小規模なデータセットとテストにのみ使用します。 大規模なデータセットの場合、最適なパフォーマンスを得るために GPU エンドポイントを使用します。
ベクトル検索インデックスを作成する
ベクトル検索インデックスは、UI、Python SDK、または REST API を使用して作成することができます。 UI が最も簡単なアプローチです。
インデックスには 2 種類あります。
- Delta Sync Index: ソースの Delta テーブルと自動的に同期し、Delta テーブル内の基になるデータが変更されると、このインデックスは自動的に増分更新されます。
- Direct Vector Access Index: ベクトルとメタデータの直接読み取りおよび書き込みがサポートされます。 ユーザーは、REST API または Python SDK を使用して、このテーブルを更新する必要があります。 この種類のインデックスは、UI を使用して作成することはできません。 REST API または SDK を使用する必要があります。
UI を使用してインデックスを作成する
左側サイドバー内の [カタログ] をクリックして、カタログ エクスプローラーの UI を開きます。
使用する Delta テーブルに移動します。
右上にある [作成] ボタンをクリックし、ドロップダウン メニューから [ベクトル検索インデックス] を選択します。
ダイアログ内のセレクターを使用して、インデックスを構成します。
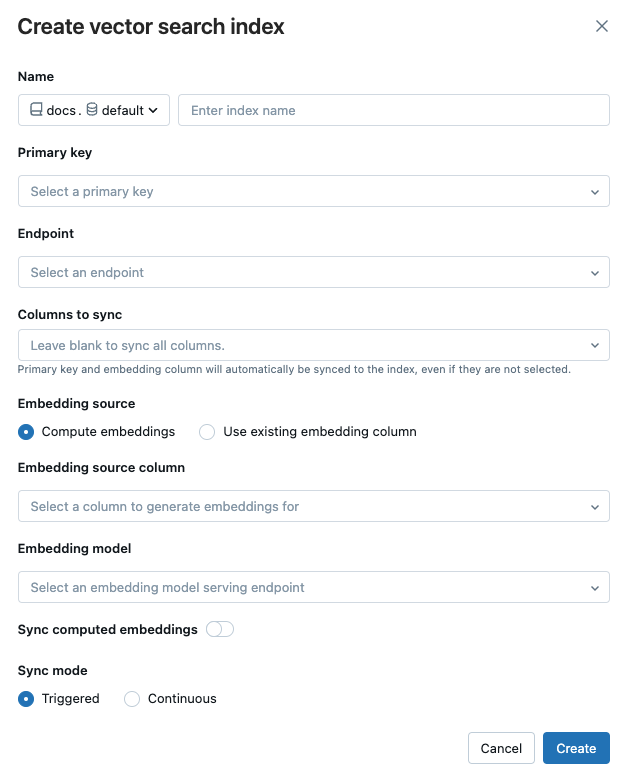
[名前]: Unity Catalog でオンライン テーブルに使う名前。 名前には 3 レベルの名前空間が必要です
<catalog>.<schema>.<name>。 英数字とアンダースコアのみを使用することができます。[Primary key]: 主キーとして使用する列。
[Endpoint]: 使用するベクトル検索エンドポイントを選択します。
同期する列: ベクトル INDEX と同期する列を選択します。 このフィールドを空白のままにすると、ソース テーブルのすべての列がインデックスと同期されます。 主キー列と埋め込みソース列、または埋め込みベクトル列は常に同期されます。
[Embedding source]: Databricks で Delta テーブル内のテキスト列の埋め込みを計算するか ([Compute embeddings])、または Delta テーブルに事前計算済みの埋め込みが含まれるか ([Use existing embedding column]) どうかを示します。
- [Compute embeddings] を選択した場合は、埋め込みを計算する列と、埋め込みモデルを提供するエンドポイントを選択します。 テキスト列のみがサポートされます。
- [Use existing embedding column] を選択した場合は、事前計算済みの埋め込みと埋め込みディメンションを含む列を選択します。 事前に計算された埋め込み列の形式は、
array[float]である必要があります。
計算された埋め込みを同期する: 生成された埋め込みを Unity Catalog テーブルに保存するには、この設定をオンにします。 詳細については、「生成された埋め込みテーブルを保存する」を参照してください。
[Sync mode]: [Continuous] は、数秒の待機時間でインデックスの同期を維持します。 ただし、継続的同期ストリーミング パイプラインを実行するためにコンピューティング クラスターがプロビジョニングされるため、それに関連するコストは高くなります。 [連続的な] と [トリガー] のどちらの場合も、更新は増分 (最後の同期が処理されてから変更されたデータのみ) で行われます。
Triggered 同期モードでは、Python SDK または REST API を使用して同期を開始します。「差分同期インデックスの更新を参照してください。
インデックスの構成が完了したら、[Create] をクリックします。
Python SDK を使用してインデックスを作成する
次の例では、Databricks によって計算された埋め込みを使用して、Delta Sync Index を作成します。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
次の例では、自己管理型埋め込みを使用して差分同期インデックスを作成します。 この例では、インデックスで使用する列の SUBSET のみを選択するオプション パラメーター columns_to_sync の使用も示しています。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
既定では、ソース テーブルのすべての列がインデックスと同期されます。 列の SUBSET のみを同期するには、columns_to_sync を使用します。 主キーと埋め込み列は常にインデックスに含まれます。
主キーと埋め込み列 のみ を同期するには、次のように columns_to_sync で指定する必要があります。
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
追加の列を同期するには、次のように指定します。 主キーと埋め込み列は常に同期されるため、含める必要はありません。
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
次の例では、Direct Vector Access Index を作成します。
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
REST API を使用してインデックスを作成する
REST API リファレンス ドキュメント「 POST /api/2.0/vector-search/indexesを参照してください。
生成された埋め込みテーブルを保存する
Databricks で埋め込みを生成すると、生成された埋め込みを Unity Catalog のテーブルに保存できます。 このテーブルは、ベクトル インデックスと同じスキーマで作成され、ベクトル インデックス ページからリンクされます。
テーブルの名前は、ベクトル検索インデックスの名前に _writeback_table が追加されます。 この名前を編集することはできません。
このテーブルには、Unity Catalog の他のテーブルと同様にアクセスしてクエリを実行できます。 ただし、このテーブルは手動で更新することを目的としていないため、テーブルを削除したり変更したりしないでください。 テーブルは、インデックスが削除されると自動的に削除されます。
ベクトル検索インデックスを更新する
差分同期インデックスを更新する
Continuous 同期モードで作成されたインデックスは、ソースの Delta テーブルが変更されると自動的に更新されます。 Triggered 同期モードを使用している場合は、Python SDK または REST API を使用して同期を開始します。
Python SDK
index.sync()
REST API
REST API リファレンス ドキュメントを参照してください。 POST /api/2.0/vector-search/indexes/{index_name}/sync。
Direct Vector Access Index を更新する
Python SDK または REST API を使用して、Direct Vector Access Index にデータを挿入、更新、または削除することができます。
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST API
REST API リファレンス ドキュメント「 POST /api/2.0/vector-search/indexesを参照してください。
次のコード例は、個人用アクセス トークン (PAT) を使用してインデックスを更新する方法を示しています。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
次のコード例は、サービス プリンシパルを使用してインデックスを更新する方法を示しています。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
ベクトル検索エンドポイントにクエリを実行する
ベクトル検索エンドポイントにクエリを実行できるのは、Python SDK、REST API、または SQL vector_search() AI 関数を使用してのみです。
Note
エンドポイントに対してクエリを実行するユーザーが、そのベクトル検索インデックスの所有者ではない場合、そのユーザーは次の UC 特権を持つ必要があります。
- ベクトル検索インデックスを含むカタログに対する USE CATALOG。
- ベクトル検索インデックスを含むスキーマに対する USE SCHEMA。
- ベクトル検索インデックスに対する SELECT。
ハイブリッド キーワード類似性検索を実行するには、query_type パラメーターを hybrid に設定します。 既定値は ann (近似最近傍) です。
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST API
REST API リファレンス ドキュメントを参照してください。 POST /api/2.0/vector-search/indexes/{index_name}/query。
次のコード例は、個人用アクセス トークン (PAT) を使用してインデックスにクエリを実行する方法を示しています。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
次のコード例は、サービス プリンシパルを使用してインデックスを照会する方法を示しています。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
重要
vector_search() AI 関数はパブリック プレビュー段階です。
この AI 関数を使用するには、「vector_search 関数」を参照してください。
クエリにフィルターを使う
クエリでは、Delta テーブル内の任意の列に基づくフィルターを定義することができます。 similarity_search は、指定されたフィルターに一致する行のみを返します。 次のフィルターがサポートされています。
| フィルター演算子 | Behavior | 例 |
|---|---|---|
NOT |
フィルターを否定します。 キーは "NOT" で終わる必要があります。 たとえば、値が "red" の "color NOT" は、色が赤ではないドキュメントと一致します。 | {"id NOT": 2} {“color NOT”: “red”} |
< |
フィールド値がフィルター値より小さいかどうかを確認します。 キーは "<" で終わる必要があります。 たとえば、値が 200 の "price <" は、価格が 200 未満のドキュメントと一致します。 | {"id <": 200} |
<= |
フィールド値がフィルター値以下かどうかを確認します。 キーは " <=" で終わる必要があります。 たとえば、値が 200 の "price <=" は、価格が 200 以下のドキュメントと一致します。 | {"id <=": 200} |
> |
フィールド値がフィルター値より大きいかどうかを確認します。 キーは ">" で終わる必要があります。 たとえば、値が 200 の "price >" は、価格が 200 を超えるドキュメントと一致します。 | {"id >": 200} |
>= |
フィールド値がフィルター値以上かどうかを確認します。 キーは " >=" で終わる必要があります。 たとえば、値が 200 の "price >=" は、価格が 200 以上のドキュメントと一致します。 | {"id >=": 200} |
OR |
フィールド値がいずれかのフィルター値と一致するかどうかを確認します。 複数のサブキーを区切るには、キーに OR を含める必要があります。 たとえば、値が ["red", "blue"] の color1 OR color2 は、color1 が red であるか、color2 が blue であるドキュメントと一致します。 |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
部分文字列と一致します。 | {"column LIKE": "hello"} |
| フィルター演算子を指定しない | フィルターは完全一致を確認します。 複数の値が指定された場合は、いずれかの値と一致します。 | {"id": 200} {"id": [200, 300]} |
次のコード例を参照してください。
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST API
「POST /api/2.0/vector-search/indexes/{index_name}/query」をご参照ください。
ノートブックの例
このセクションの例では、ベクトル検索 Python SDK の使用方法を示します。
LangChain の例
LangChain パッケージと統合して Mosaic AI Vector Search を使用する方法については、LangChain と Mosaic AI Vector Search の使用方法を参照してください。
次のノートブックは、類似性の検索結果を LangChain ドキュメントに変換する方法を示しています。
Python SDK を使用したベクトル検索のノートブック
埋め込みモデルを呼び出すノートブックの例
以下のノートブックは、埋め込み生成用の Mosaic AI Model Serving エンドポイントの構成方法を示しています。