コードで AI エージェントを作成する
この記事では、MLflow ChatModelを使用して、コードで AI エージェントを作成する方法について説明します。 Azure Databricks では、MLflow ChatModel を利用して、評価、トレース、デプロイなどの Databricks AI エージェント機能との互換性を確保します。
ChatModelとは
ChatModel は、会話型 AI エージェントの作成を簡略化するように設計された MLflow クラスです。 OpenAI の ChatCompletion API と互換性のあるモデル構築するための標準化されたインターフェイスを提供します。
ChatModel は、OpenAI の ChatCompletion スキーマを拡張します。 この方法を使用すると、ChatCompletion 標準をサポートするプラットフォームとの広範な互換性を維持しながら、独自のカスタム機能も追加できます。
開発者は、ChatModelを使用して、エージェントの追跡、評価、ライフサイクル管理のために Databricks および MLflow ツールと互換性のあるエージェントを作成できます。これは、運用対応モデルのデプロイに不可欠です。
MLflow の ChatModel 概要ページを参照してください。
必要条件
Databricks では、エージェントの開発時に最新バージョンの MLflow Python クライアントをインストールすることをお勧めします。
この記事のアプローチを使用してエージェントを作成してデプロイするには、次の要件を満たす必要があります。
- バージョン 0.15.0 以降
databricks-agentsインストールする - バージョン 2.20.0 以降
mlflowインストールする
%pip install -U -qqqq databricks-agents>=0.15.0 mlflow>=2.20.0
ChatModel エージェントを作成する
エージェントは、mlflow.pyfunc.ChatModelのサブクラスとして作成できます。 この方法には、次の利点があります。
- 型指定された Python クラスを使用して、ChatCompletion スキーマと互換性のあるエージェント コードを記述できます。
- MLflow は、エージェントをログに記録するときに、
input_exampleがなくても、チャット完了と互換性のある署名を自動的に推論します。 これにより、エージェントの登録とデプロイのプロセスが簡略化されます。 「ログ中にモデル シグネチャを推論する」を参照してください。
次のコードは、Databricks ノートブックで最適に実行されます。 ノートブックは、エージェントの開発、テスト、反復処理に便利な環境を提供します。
MyAgent クラスは、必要な predict メソッドを実装する mlflow.pyfunc.ChatModelを拡張します。 これにより、Mosaic AI Agent Framework との互換性が確保されます。
このクラスには、ストリーミング出力を処理するために _create_chat_completion_chunk および predict_stream オプションのメソッドも含まれています。
from dataclasses import dataclass
from typing import Optional, Dict, List, Generator
from mlflow.pyfunc import ChatModel
from mlflow.types.llm import (
# Non-streaming helper classes
ChatCompletionRequest,
ChatCompletionResponse,
ChatCompletionChunk,
ChatMessage,
ChatChoice,
ChatParams,
# Helper classes for streaming agent output
ChatChoiceDelta,
ChatChunkChoice,
)
class MyAgent(ChatModel):
"""
Defines a custom agent that processes ChatCompletionRequests
and returns ChatCompletionResponses.
"""
def predict(self, context, messages: list[ChatMessage], params: ChatParams) -> ChatCompletionResponse:
last_user_question_text = messages[-1].content
response_message = ChatMessage(
role="assistant",
content=(
f"I will always echo back your last question. Your last question was: {last_user_question_text}. "
)
)
return ChatCompletionResponse(
choices=[ChatChoice(message=response_message)]
)
def _create_chat_completion_chunk(self, content) -> ChatCompletionChunk:
"""Helper for constructing a ChatCompletionChunk instance for wrapping streaming agent output"""
return ChatCompletionChunk(
choices=[ChatChunkChoice(
delta=ChatChoiceDelta(
role="assistant",
content=content
)
)]
)
def predict_stream(
self, context, messages: List[ChatMessage], params: ChatParams
) -> Generator[ChatCompletionChunk, None, None]:
last_user_question_text = messages[-1].content
yield self._create_chat_completion_chunk(f"Echoing back your last question, word by word.")
for word in last_user_question_text.split(" "):
yield self._create_chat_completion_chunk(word)
agent = MyAgent()
model_input = ChatCompletionRequest(
messages=[ChatMessage(role="user", content="What is Databricks?")]
)
response = agent.predict(context=None, model_input=model_input)
print(response)
エージェント クラス MyAgent は 1 つのノートブックで定義されていますが、別のドライバー ノートブックを作成する必要があります。 ドライバー ノートブックは、エージェントをモデル レジストリに記録し、Model Serving を使用してエージェントをデプロイします。
この分離は、MLflow のモデルをコード手法から使用してモデルをログに記録するために Databricks が推奨するワークフローに従います。
例: ChatModel で LangChain をラップする
既存の LangChain モデルがあり、他の Mosaic AI エージェント機能と統合する場合は、互換性を確保するために MLflow ChatModel でラップできます。
このコード サンプルでは、次の手順を実行して、ChatModelとして実行できる LangChain をラップします。
- LangChain の最終的な出力を
mlflow.langchain.output_parsers.ChatCompletionOutputParserでラップして、チャット完了出力署名を生成する LangchainAgentクラスはmlflow.pyfunc.ChatModelを拡張し、次の 2 つの主要なメソッドを実装します。predict: チェーンを呼び出し、書式設定された応答を返すことによって、同期予測を処理します。predict_stream: チェーンを呼び出し、応答のチャンクを生成することで、ストリーミング予測を処理します。
from mlflow.langchain.output_parsers import ChatCompletionOutputParser
from mlflow.pyfunc import ChatModel
from typing import Optional, Dict, List, Generator
from mlflow.types.llm import (
ChatCompletionResponse,
ChatCompletionChunk
)
chain = (
<your chain here>
| ChatCompletionOutputParser()
)
class LangchainAgent(ChatModel):
def _prepare_messages(self, messages: List[ChatMessage]):
return {"messages": [m.to_dict() for m in messages]}
def predict(
self, context, messages: List[ChatMessage], params: ChatParams
) -> ChatCompletionResponse:
question = self._prepare_messages(messages)
response_message = self.chain.invoke(question)
return ChatCompletionResponse.from_dict(response_message)
def predict_stream(
self, context, messages: List[ChatMessage], params: ChatParams
) -> Generator[ChatCompletionChunk, None, None]:
question = self._prepare_messages(messages)
for chunk in chain.stream(question):
yield ChatCompletionChunk.from_dict(chunk)
パラメーターを使用してエージェントを構成する
エージェント フレームワークでは、パラメーターを使用してエージェントの実行方法を制御できます。 これにより、コードを変更することなく、エージェントのさまざまな特性を使用して迅速に反復処理できます。 パラメーターは、Python ディクショナリまたは .yaml ファイルで定義するキーと値のペアです。
コードを構成するには、キー値パラメーターのセットである ModelConfigを作成します。 ModelConfig は Python ディクショナリまたは .yaml ファイルです。 たとえば、開発中にディクショナリを使用し、運用環境のデプロイと CI/CD 用の .yaml ファイルに変換できます。 ModelConfigの詳細については、MLflow のドキュメントを参照してください。
ModelConfig の例を次に示します。
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
コードから構成を呼び出すには、次のいずれかを使用します。
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
value = model_config.get('sample_param')
取得元スキーマを設定する
AI エージェントは、多くの場合、ベクター検索インデックスを使用して関連するドキュメントを検索して返す一種のエージェント ツールであるレトリバーを使用します。 取得機能の詳細については、「非構造化取得 AI エージェント ツール」を参照してください。
レトリバーが正しくトレースされるようにするには、コードでエージェントを定義するときに mlflow.models.set_retriever_schema を呼び出します。 set_retriever_schema を使用して、返されたテーブル内の列名を、primary_key、text_column、doc_uriなどの MLflow の予期されるフィールドにマップします。
# Define the retriever's schema by providing your column names
# These strings should be read from a config dictionary
mlflow.models.set_retriever_schema(
name="vector_search",
primary_key="chunk_id",
text_column="text_column",
doc_uri="doc_uri"
# other_columns=["column1", "column2"],
)
注
doc_uri 列は、レトリバーのパフォーマンスを評価する際に特に重要です。 doc_uri は、レトリバーによって返されるドキュメントの主な識別子であり、地上真偽評価セットと比較できます。 評価セット を参照してください。
other_columns フィールドを使用して列名の一覧を指定することで、取得元のスキーマに追加の列を指定することもできます。
複数のレトリバーがある場合は、各レトリバー スキーマに一意の名前を使用して、複数のスキーマを定義できます。
カスタム入力と出力
一部のシナリオでは、client_type や session_idなどの追加のエージェント入力や、今後の対話のためにチャット履歴に含めてはならない取得ソース リンクなどの出力が必要になる場合があります。
これらのシナリオでは、MLflow ChatModel、ChatParams フィールド custom_input と custom_outputを使用した OpenAI チャット完了要求と応答の拡張をネイティブにサポートします。
PyFunc および LangGraph エージェントのカスタム入力と出力を作成する方法については、次の例を参照してください。
警告
エージェント評価レビュー アプリ では、現在、追加の入力フィールドを持つエージェントのトレースのレンダリングはサポートされていません。
PyFunc カスタム スキーマ
次のノートブックは、PyFunc を使用したカスタム スキーマの例を示しています。
PyFunc カスタム スキーマ エージェント ノートブック
PyFunc カスタム スキーマ ドライバー ノートブック
LangGraph カスタム スキーマ
次のノートブックは、LangGraph を使用したカスタム スキーマの例を示しています。 ノートブックの wrap_output 関数を変更して、メッセージ ストリームから情報を解析および抽出できます。
LangGraph カスタム スキーマ エージェント ノートブック
LangGraph カスタム スキーマ ドライバー ノートブック
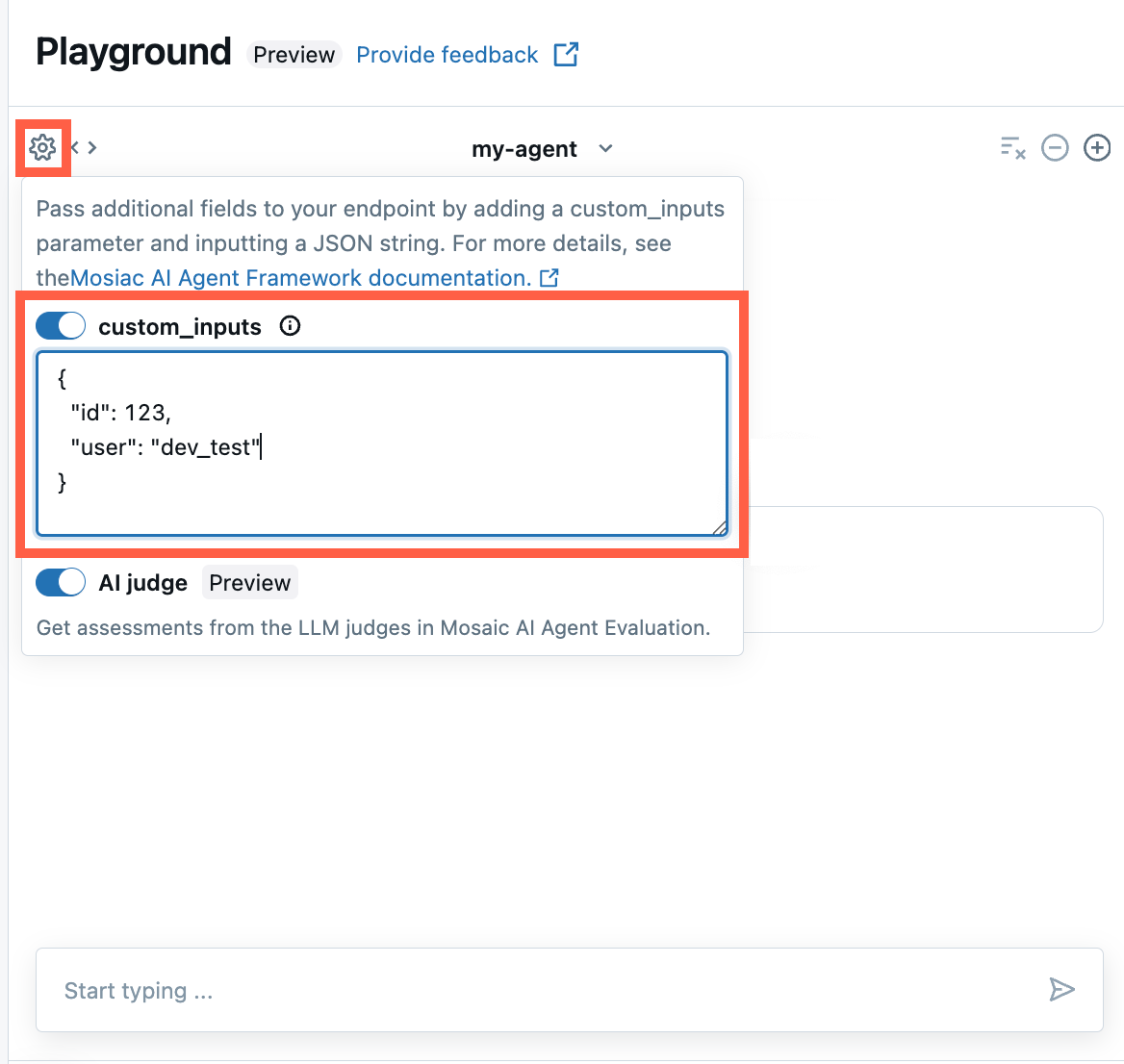
AI Playground とエージェント レビュー アプリで custom_inputs を提供する
エージェントが custom_inputs フィールドを使用して追加の入力を受け取る場合、AI Playground と エージェント レビュー アプリの両方でこれらの入力を手動で指定できます。
AI プレイグラウンドまたはエージェント レビュー アプリで、歯車アイコン
 を選択します。
を選択します。custom_inputs を有効にします。
エージェントの定義された入力スキーマに一致する JSON オブジェクトを指定します。
ストリーミング エラーの伝達
モザイク AI は、databricks_output.errorの下の最後のトークンでのストリーミング中に発生したエラーを伝播します。 このエラーを適切に処理して表示するのは、呼び出し元のクライアント次第です。
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute"
}
}
}
ノートブックの例
これらのノートブックは、Databricks でのエージェントの作成を示す単純な "Hello, world" チェーンを作成します。 最初の例では単純なチェーンを作成し、2 番目のサンプル ノートブックでは、開発中にパラメーターを使用してコードの変更を最小限に抑える方法を示しています。
シンプルなチェーン ノートブック
単純なチェーン ドライバー ノートブック
パラメーター化されたチェーン ノートブック
パラメーター化されたチェーン ドライバー ノートブック
次のステップ
- 独自のエージェント ツールを作成します。
- AI エージェントのをログに記録します。
- AI エージェントにトレースを追加します。
- AI エージェントをデプロイします。