Databricks Connect リファレンス
注意
この記事では、Databricks Runtime 13.0 以降用の Databricks Connect について説明します。
Databricks Runtime 13.0 以降の Databricks Connect をすばやく開始する方法については、「Databricks Connect」を参照してください。
以前の Databricks Runtime バージョン向けの Databricks Connect に関する情報については、「Databricks Runtime 12.2 LTS 以下用の Databricks Connect」をご覧ください。
Databricks Connect を使用すると、Visual Studio Code や PyCharm などの一般的な IDE、ノートブック サーバー、その他のカスタム アプリケーションを Azure Databricks クラスターに接続できます。
この記事では、Databricks Connect のしくみを説明し、Databricks Connect の使用を開始する手順を順に示し、Databricks Connect の使用時に発生する可能性がある問題のトラブルシューティング方法を説明します。
概要
Databricks Connect は Databricks Runtime 用のクライアントライブラリです。 これにより、Spark API を使用してジョブを作成し、ローカルの Spark セッションではなく、Azure Databricks クラスターでリモート実行することができます。
たとえば、Databricks Connect を使用して DataFrame コマンド spark.read.format(...).load(...).groupBy(...).agg(...).show() を実行すると、リモート クラスターで実行するために Azure Databricks で実行されている Spark サーバーに、コマンドの論理表現が送信されます。
Databricks Connect では、次のことができます。
任意の Python アプリケーションから大規模な Spark ジョブを実行できます。
import pysparkが可能な場所なら、アプリケーションから直接 Spark ジョブを実行できるようになりました。IDE プラグインをインストールしたり、Spark 送信スクリプトを使用したりする必要はありません。注意
Databricks Runtime 13.0 以上用の Databricks Connect は現在、Python アプリケーションでの実行のみをサポートしています。
リモートクラスターを使用している場合でも、IDE でコードをステップ実行してデバッグします。
ライブラリの開発時にすばやく反復処理します。 Databricks Connect で Python ライブラリの依存関係を変更した後にクラスターを再起動する必要はありません。各クライアント セッションはクラスター内で相互に分離されているためです。
作業結果を失うことなく、アイドル状態のクラスターをシャットダウンします。 クライアントアプリケーションはクラスターから切り離されているため、クラスターの再起動またはアップグレードの影響を受けません。再起動やアップグレードは通常、ノートブックで定義されているすべての変数、RDD、およびデータフレームオブジェクトが失われる原因となります。
Databricks Runtime 13.0 以上では、Databricks Connect はオープンソースの Spark Connect 上に構築されるようになりました。 Spark Connect は、DataFrame API と未解決の論理プランをプロトコルとして使用して Spark クラスターへのリモート接続を可能にする、Apache Spark 用の分離されたクライアント/サーバー アーキテクチャを導入しています。 Spark Connect に基づくこの "V2" アーキテクチャにより、Databricks Connect はシンプルで使いやすいシン クライアントになります。 Spark Connect は、IDE、ノートブック、アプリケーションなどのあらゆる場所に埋め込んで Azure Databricks に接続できるため、個々のユーザーとパートナーが同じように、Databricks Lakehouse に基づいて新しい (対話型) ユーザー エクスペリエンスを構築できます。 Spark Connect の詳細については、Spark Connect の概要に関する記事 (英語) を参照してください。
Databricks Connect は、次の図に示すように、コードを実行およびデバッグする場所を決定します。
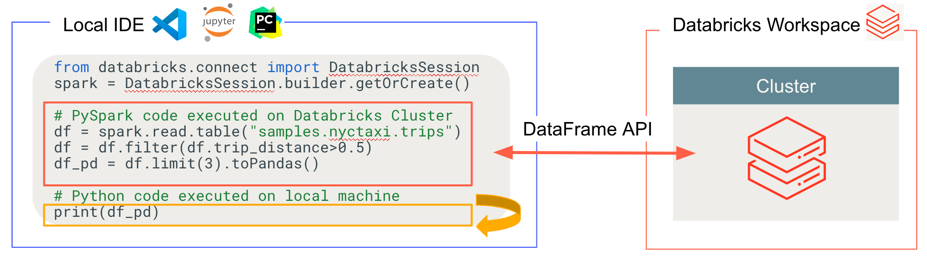
- コードを実行する場合: すべての Python コードはローカルで実行されますが、DataFrame 操作を含むすべての PySpark コードは、リモートの Azure Databricks ワークスペース内のクラスターで実行され、実行応答がローカル呼び出し元に返送されます。
- コードをデバッグする場合: すべての Python はローカルでデバッグされますが、すべての PySpark コードはリモートの Azure Databricks ワークスペース内のクラスターで引き続き実行されます。 コア Spark エンジン コードをクライアントから直接デバッグすることはできません。
必要条件
このセクションには、Databricks Connect の要件を示します。
Unity Catalog に対して有効になっている Azure Databricks ワークスペースとそれに対応するアカウント。 「Unity Catalog の使用の開始」と「Unity Catalog のワークスペースを有効にする」を参照してください。
Databricks Runtime 13.0 以降がインストールされているクラスター。
Unity Catalog と互換性のあるクラスターのみがサポートされます。 これには、割り当てられた、または共有のアクセス モードを持つクラスターが含まれます。 アクセス モードを参照してください。
開発用コンピューターに Python 3 をインストールする必要があり、クライアントの Python インストールのマイナー バージョンは、Azure Databricks クラスターのマイナー Python バージョンと同じである必要があります。 次の表は、各 Databricks Runtime に合わせてインストールされる Python バージョンを示しています。
Databricks Runtime のバージョン Python バージョン 13.2 ML、13.2 3.10 13.1 ML、13.1 3.10 13.0 ML、13.0 3.10 注意
PySpark UDF を使用する場合は、開発用コンピューターにインストールされている Python のマイナー バージョンが、クラスターにインストールされている Databricks Runtime に含まれる Python のマイナー バージョンと一致することが重要です。
Databricks では、Databricks Connect で使用する Python バージョンごとに Python "仮想環境" をアクティブにすることを強く推奨しています。 Python 仮想環境は、正しいバージョンの Python と Databricks Connect を一緒に使用していることを確認するのに役立ちます。 これにより、関連する技術的な問題の解決を軽減または短縮できます。
たとえば、開発マシンで venv を使用していて、クラスターが Python 3.10 を実行している場合、そのバージョンの
venv環境を作成する必要があります。 次のコマンド例は、Python 3.10 を使用してvenv環境をアクティブにするためのスクリプトを生成し、このコマンドは次に、現在の作業ディレクトリ内の.venvという名前の隠しフォルダー内にそれらのスクリプトを配置します。# Linux and macOS python3.10 -m venv ./.venv # Windows python3.10 -m venv .\.venvこれらのスクリプトを使用してこの
venv環境をアクティブにするには、venvs のしくみに関する記事 (英語) を参照してください。Databricks Connect のメジャーとマイナーのパッケージ バージョンは、Databricks Runtime のバージョンと一致している必要があります。 Databricks では、常に、Azure Databricks Runtime のバージョンと一致する、最新の Databricks Connect のパッケージを使用することをお勧めします。 たとえば、Databricks Runtime 13.1 クラスターを使用するときは、
databricks-connect==13.1.*パッケージも使用する必要があります。注意
利用可能な Databricks Connect リリースとメンテナンスの更新プログラムの一覧については、 「Databricks Connect のリリースノート」を参照してください。
Databricks Runtime のバージョンに一致する Databricks Connect の最新のパッケージを使用する必要はありません。 Databricks Runtime 13.0 以降では、Databricks Connect パッケージのバージョン以上のすべての Databricks Runtime バージョンに対して、Databricks Connect パッケージを使用できます。 ただし、新しいバージョンの Databricks Runtime で提供される機能を使用する場合は、それに応じて Databricks Connect パッケージをアップグレードする必要があります。
クライアントの設定
次の手順を実行して、Databricks Connect のローカル クライアントを設定します。
注意
ローカルの Databricks Connect クライアントの設定を開始する前に、Databricks Connect の要件を満たす必要があります。
ヒント
Visual Studio Code 用 Databricks 拡張機能が既にインストールされている場合は、これらのセットアップ手順に従う必要はありません。
Visual Studio Code 用の Databricks 拡張機能には、Databricks Runtime 13.0 以上用の Databricks Connect に対する組み込みのサポートが既にあります。 Visual Studio Code 用 Databricks 拡張機能のドキュメントの「Databricks Connect を使用して Python コードを実行またはデバッグする」に進んでください。
手順 1: Databricks Connect クライアントをインストールする
仮想環境がアクティブな状態で、
uninstallコマンドを実行して PySpark をアンインストールします (既にインストールされている場合)。 これは、databricks-connectパッケージが PySpark と競合するために必要です。 詳細については、「PySpark インストールの競合」を参照してください。 PySpark が既にインストールされているかどうかを調べるには、showコマンドを実行します。# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pyspark仮想環境がアクティブな状態のままで、
installコマンドを実行して Databricks Connect クライアントをインストールします。--upgradeオプションを使用して、既存のクライアント インストールを指定したバージョンにアップグレードします。pip3 install --upgrade "databricks-connect==13.1.*" # Or X.Y.* to match your cluster version.注意
Databricks では、最新のパッケージがインストールされるように、
databricks-connect=X.Yではなくdatabricks-connect==X.Y.*を指定する "ドットとアスタリスク" の表記を追加することをお勧めします。 これは要件ではありませんが、そのクラスターでサポートされている最新の機能を使用できるようにするのに役立ちます。
手順 2: 接続プロパティの構成
このセクションでは、Databricks Connect とリモート Azure Databricks クラスターの間の接続を確立するようにプロパティを構成します。 これらのプロパティには、クラスターで Databricks Connect を認証するための設定が含まれます。
Databricks Connect for Databricks Runtime 13.1 以降では、Databricks Connect には Databricks SDK for Python が含まれています。 この SDK は、Databricks クライアント統合認証標準を実装しています。これは、統合されていて一貫性がある、アーキテクチャとプログラムによる認証アプローチです。 このアプローチは、Azure Databricks を使用した認証の設定と自動化を、より一元的で予測可能なものにします。 これにより、Azure Databricks 認証を一度構成すれば、それ以上認証構成を変更しなくても、複数の Azure Databricks ツールおよび SDK でその構成を使用できます。
注意
Databricks SDK for Python では、まだ Azure MSI 認証が実装されていません。
Databricks Connect for Databricks Runtime 13.0 では、認証に Azure Databricks 個人用アクセス トークン認証のみがサポートされています。
次の構成プロパティを収集します。
- Azure Databricks ワークスペースのインスタンス名。 これは、クラスターのサーバー ホスト名の値と同じです。「クラスターの接続の詳細を取得する」を参照してください。
- クラスターの ID。 クラスター ID は URL から取得できます。 「クラスター URL と ID」を参照してください。
- 使用する Databricks 認証タイプに必要なその他のプロパティは、次のとおりです。
コード内で接続を構成します。 Databricks Connect は、見つかるまで構成プロパティを次の順序で検索します。 見つかると、残りのオプションの検索を停止します。
Azure Databricks 個人用アクセス トークン認証専用の、
DatabricksSessionクラスを介して指定される接続プロパティの直接構成Azure Databricks 個人用アクセス トークン認証にのみ適用されるこのオプション用に、ワークスペース インスタンス名、Azure Databricks 個人用アクセス トークン、およびクラスターの ID を指定します。
以下のコード例は、Azure Databricks 個人用アクセス トークン認証のために
DatabricksSessionクラスを初期化する方法を示します。Databricks では、これらの接続プロパティをコード内で直接指定することはお勧めしません。 その代わりに、Databricks では、後のオプションで説明するように、環境変数または構成ファイルを使用してプロパティを構成することをお勧めします。 以下のコード例では、ユーザーまたはその他の構成ストア (Azure KeyVault など) から必要なプロパティを取得するために、提案された
retrieve_*関数の実装を自分で提供することが想定されています。# By setting fields in builder.remote: from databricks.connect import DatabricksSession spark = DatabricksSession.builder.remote( host = f"https://{retrieve_workspace_instance_name()}", token = retrieve_token(), cluster_id = retrieve_cluster_id() ).getOrCreate() # Or, by using the Databricks SDK's Config class: from databricks.connect import DatabricksSession from databricks.sdk.core import Config config = Config( host = f"https://{retrieve_workspace_instance_name()}", token = retrieve_token(), cluster_id = retrieve_cluster_id() ) spark = DatabricksSession.builder.sdkConfig(config).getOrCreate() # Or, specify a Databricks configuration profile and # the cluster_id field separately: from databricks.connect import DatabricksSession from databricks.sdk.core import Config config = Config( profile = "<profile-name>", cluster_id = retrieve_cluster_id() ) spark = DatabricksSession.builder.sdkConfig(config).getOrCreate() # Or, by setting the Spark Connect connection string in builder.remote: from databricks.connect import DatabricksSession workspace_instance_name = retrieve_workspace_instance_name() token = retrieve_token() cluster_id = retrieve_cluster_id() spark = DatabricksSession.builder.remote( f"sc://{workspace_instance_name}:443/;token={token};x-databricks-cluster-id={cluster_id}" ).getOrCreate()すべての Azure Databricks 認証タイプに対応した、
profile()を使用して指定される Azure Databricks 構成プロファイル名このオプションでは、
cluster_idフィールドおよび、使用する Databricks 認証の種類に必要なその他のフィールドが含まれた Azure Databricks 構成プロファイルを作成または指定します。各認証タイプに必要な構成プロファイル フィールドは次のとおりです。
- Azure Databricks 個人用アクセス トークン認証の場合:
hostとtoken。 - OAuth ユーザー対マシン (U2M) 認証の場合:
host、azure_tenant_id、azure_client_id、およびazure_client_secret。 - Azure サービス プリンシパル認証の場合:
host、azure_tenant_id、azure_client_id、azure_client_secret、および場合によってはazure_workspace_resource_id。 - Azure CLI 認証の場合:
host。
次に、
Configクラスを使用して、この構成プロファイルの名前を設定します。または、構成プロファイルとは別に
cluster_idを指定することもできます。 コード内でクラスター ID を直接指定する代わりに、以下のコード例では、ユーザーまたはその他の構成ストア (Azure KeyVault など) から必要なクラスター ID を取得するために、提案されたretrieve_cluster_id関数の実装を自分で提供することが想定されています。次に例を示します。
# Specify a Databricks configuration profile that contains the # cluster_id field: from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate()- Azure Databricks 個人用アクセス トークン認証の場合:
Azure Databricks 個人用アクセス トークン認証専用の、
SPARK_REMOTE環境変数Azure Databricks 個人用アクセス トークン認証にのみ適用されるこのオプション用に、
SPARK_REMOTE環境変数を次の文字列に設定し、プレースホルダーを適切な値に置き換えます。sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>次に、
DatabricksSessionクラスを次のように初期化します。from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()環境変数を設定するには、オペレーティング システムのドキュメントを参照してください。
すべての Azure Databricks 認証の種類用の、
DATABRICKS_CONFIG_PROFILE環境変数このオプションでは、
cluster_idフィールドおよび、使用する Databricks 認証の種類に必要なその他のフィールドが含まれた Azure Databricks 構成プロファイルを作成または指定します。各認証タイプに必要な構成プロファイル フィールドは次のとおりです。
- Azure Databricks 個人用アクセス トークン認証の場合:
hostとtoken。 - OAuth ユーザー対マシン (U2M) 認証の場合:
host、azure_tenant_id、azure_client_id、およびazure_client_secret。 - Azure サービス プリンシパル認証の場合:
host、azure_tenant_id、azure_client_id、azure_client_secret、および場合によってはazure_workspace_resource_id。 - Azure CLI 認証の場合:
host。
次に、
DATABRICKS_CONFIG_PROFILE環境変数をこの構成プロファイルの名前に設定します。 次に、DatabricksSessionクラスを次のように初期化します。from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()環境変数を設定するには、オペレーティング システムのドキュメントを参照してください。
- Azure Databricks 個人用アクセス トークン認証の場合:
すべての Azure Databricks 認証の種類用の、各接続プロパティの環境変数
このオプションでは、
DATABRICKS_CLUSTER_ID環境変数と、使用する Databricks 認証の種類に必要なその他の環境変数を設定します。各認証タイプに必要な環境変数は次のとおりです。
- Azure Databricks 個人用アクセス トークン認証の場合:
DATABRICKS_HOSTとDATABRICKS_TOKEN。 - OAuth ユーザー対マシン (U2M) 認証の場合:
DATABRICKS_HOST、ARM_TENANT_ID、ARM_CLIENT_ID、およびARM_CLIENT_SECRET。 - Azure サービス プリンシパル認証の場合:
DATABRICKS_HOST、ARM_TENANT_ID、ARM_CLIENT_ID、ARM_CLIENT_SECRET、および場合によってはDATABRICKS_AZURE_RESOURCE_ID。 - Azure CLI 認証の場合:
DATABRICKS_HOST。
次に、
DatabricksSessionクラスを次のように初期化します。from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()環境変数を設定するには、オペレーティング システムのドキュメントを参照してください。
- Azure Databricks 個人用アクセス トークン認証の場合:
すべての Azure Databricks 認証の種類用の、
DEFAULTという名前の Azure Databricks 構成プロファイルこのオプションでは、
cluster_idフィールドおよび、使用する Databricks 認証の種類に必要なその他のフィールドが含まれた Azure Databricks 構成プロファイルを作成または指定します。各認証タイプに必要な構成プロファイル フィールドは次のとおりです。
- Azure Databricks 個人用アクセス トークン認証の場合:
hostとtoken。 - OAuth ユーザー対マシン (U2M) 認証の場合:
host、azure_tenant_id、azure_client_id、およびazure_client_secret。 - Azure サービス プリンシパル認証の場合:
host、azure_tenant_id、azure_client_id、azure_client_secret、および場合によってはazure_workspace_resource_id。 - Azure CLI 認証の場合:
host。
この構成プロファイルに
DEFAULTという名前を付けます。次に、
DatabricksSessionクラスを次のように初期化します。from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()- Azure Databricks 個人用アクセス トークン認証の場合:
Azure Databricks 個人用アクセス トークン認証を使用する場合は、付属の
pysparkユーティリティを使用して、次のように Azure Databricks クラスターへの接続をテストできます。仮想環境がアクティブな状態のままで、次のコマンドを実行します。
SPARK_REMOTE環境変数を前に設定した場合は、次のコマンドを実行します。pysparkSPARK_REMOTE環境変数を前に設定しなかった場合は、代わりに次のコマンドを実行します。pyspark --remote "sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>"Spark シェルが表示されます。次に例を示します。
Python 3.10 ... [Clang ...] on darwin Type "help", "copyright", "credits" or "license" for more information. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 13.0 /_/ Using Python version 3.10 ... Client connected to the Spark Connect server at sc://...:.../;token=...;x-databricks-cluster-id=... SparkSession available as 'spark'. >>>>>>プロンプトで、spark.range(1,10).show()などの単純な PySpark コマンドを実行します。 エラーがない場合は、正常に接続されています。正常に接続されている場合は、Spark シェルを停止するために、
Ctrl + dまたはCtrl + zを押すか、コマンドquit()またはexit()を実行します。
Databricks Connect を使用する
以降のセクションでは、Databricks Connect クライアントを使用するように多数の一般的な IDE とノートブック サーバーを構成する方法について説明します。 組み込みの Spark シェルを使用することもできます。
このセクションの内容は次のとおりです。
- JupyterLab と Python
- クラシック Jupyter Notebook と Python
- Visual Studio Code と Python
- PyCharm と Python
- Eclipse と PyDev
- Spark シェルと Python
JupyterLab と Python
JupyterLab と Python で Databricks Connect を使用するには、次の手順に従います。
JupyterLab をインストールするには、Python 仮想環境がアクティブな状態で、ターミナルまたはコマンド プロンプトから次のコマンドを実行します。
pip3 install jupyterlabWeb ブラウザーで JupyterLab を起動するには、アクティブな Python 仮想環境から次のコマンドを実行します。
jupyter labJupyterLab が Web ブラウザーに表示されない場合は、
localhostまたは127.0.0.1で始まる URL を仮想環境からコピーし、Web ブラウザーのアドレス バーに入力します。JupyterLab で、メインメニューの [File]>[New]>[Notebook] をクリックし、[Python 3 (ipykernel)] を選択し、[Select] をクリックして新しいノートブックを作成します。
ノートブックの最初のセルに、コード例または独自のコードを入力します。 独自のコードを使用する場合は、コード例に示すように、少なくとも
DatabricksSessionをインスタンス化する必要があります。ノートブックを実行するには、[実行] > [すべてのセルを実行] をクリックします。 すべての Python コードはローカルで実行されますが、DataFrame 操作を含むすべての PySpark コードは、リモートの Azure Databricks ワークスペース内のクラスターで実行され、実行応答がローカル呼び出し元に返送されます。
ノートブックをデバッグするには、ノートブックのツール バーの [Python 3 (ipykernel)] の横にあるバグ (デバッガーを有効にする) アイコンをクリックします。 1 つ以上のブレークポイントを設定し、[実行] > [すべてのセルを実行] をクリックします。 すべての Python はローカルでデバッグされますが、すべての PySpark コードはリモートの Azure Databricks ワークスペース内のクラスターで引き続き実行されます。 コア Spark エンジン コードをクライアントから直接デバッグすることはできません。
JupyterLab をシャットダウンするには、[ファイル] > [シャットダウン] をクリックします。 JupyterLab プロセスがターミナルまたはコマンド プロンプトで引き続き実行されている場合は、
Ctrl + cを押してから、yを入力して確定してこのプロセスを停止します。
具体的なデバッグ手順については、「Debugger」 (デバッガー) を参照してください。
クラシック Jupyter Notebook と Python
クラシック Jupyter Notebookと Python で Databricks Connect を使用するには、次の手順に従います。
クラシック Jupyter Notebook をインストールするには、Python 仮想環境がアクティブな状態で、ターミナルまたはコマンド プロンプトから次のコマンドを実行します。
pip3 install notebookWeb ブラウザーでクラシック Jupyter Notebook を起動するには、アクティブな Python 仮想環境から次のコマンドを実行します。
jupyter notebookクラシック Jupyter Notebook が Web ブラウザーに表示されない場合は、
localhostまたは127.0.0.1で始まる URL を仮想環境からコピーし、Web ブラウザーのアドレス バーに入力します。クラシック Jupyter Notebook の [Files] タブで、[New]>[Python 3 (ipykernel)] をクリックして、新しいノートブックを作成します。
ノートブックの最初のセルに、コード例または独自のコードを入力します。 独自のコードを使用する場合は、コード例に示すように、少なくとも
DatabricksSessionをインスタンス化する必要があります。ノートブックを実行するには、[Cell]>[Run All] をクリックします。 すべての Python コードはローカルで実行されますが、DataFrame 操作を含むすべての PySpark コードは、リモートの Azure Databricks ワークスペース内のクラスターで実行され、実行応答がローカル呼び出し元に返送されます。
ノートブックをデバッグするには、ノートブックの先頭に次のコード行を追加します。
from IPython.core.debugger import set_trace次に、
set_trace()を呼び出して、ノートブック実行のその時点にデバッグ ステートメントを入力します。 すべての Python はローカルでデバッグされますが、すべての PySpark コードはリモートの Azure Databricks ワークスペース内のクラスターで引き続き実行されます。 コア Spark エンジン コードをクライアントから直接デバッグすることはできません。クラシック Jupyter Notebook をシャットダウンするには、[File]>[Close and Halt] をクリックします。 クラシック Jupyter Notebook プロセスがターミナルまたはコマンド プロンプトで引き続き実行されている場合は、
Ctrl + cを押してから、yを入力して確定してこのプロセスを停止します。
Visual Studio Code と Python
ヒント
Visual Studio Code 用の Databricks 拡張機能には、Databricks Runtime 13.0 以上用の Databricks Connect に対する組み込みのサポートが既にあります。 Visual Studio Code 用 Databricks 拡張機能のドキュメントの「Databricks Connect を使用して Python コードを実行またはデバッグする」を参照してください。
Visual Studio Code と Python で Databricks Connect を使用するには、次の手順に従います。
Visual Studio Code を起動します。
お使いの Python 仮想環境を含むフォルダーを開きます ([ファイル] > [フォルダーを開く])。
Visual Studio Code ターミナル ([表示] > [ターミナル]) で、仮想環境をアクティブにします。
次のように現在の Python インタープリターを仮想環境から参照されるものに設定します。
- コマンド パレット ([表示] > [コマンド パレット]) で、「
Python: Select Interpreter」と入力し、Enter キーを押します。 - 仮想環境から参照される Python インタープリターへのパスを選択します。
- コマンド パレット ([表示] > [コマンド パレット]) で、「
コード例または独自のコードを含む Python コード (
.py) ファイルをフォルダーに追加します。 独自のコードを使用する場合は、コード例に示すように、少なくともDatabricksSessionをインスタンス化する必要があります。コードを実行するには、メイン メニューの [実行] > [デバッグなしで実行] をクリックします。 すべての Python コードはローカルで実行されますが、DataFrame 操作を含むすべての PySpark コードは、リモートの Azure Databricks ワークスペース内のクラスターで実行され、実行応答がローカル呼び出し元に返送されます。
コードをデバッグするには、次のようにします。
- Python コード ファイルを開いた状態で、実行中にコードを一時停止するブレークポイントを設定します。
- サイドバーの [実行とデバッグ] アイコンをクリックするか、メイン メニューで [表示] > [実行] の順にクリックします。
- [実行とデバッグ] ビューで、[実行とデバッグ] ボタンをクリックします。
- 画面の指示に従って、コードの実行とデバッグを開始します。
すべての Python はローカルでデバッグされますが、すべての PySpark コードはリモートの Azure Databricks ワークスペース内のクラスターで引き続き実行されます。 コア Spark エンジン コードをクライアントから直接デバッグすることはできません。
実行とデバッグの具体的な手順については、デバッガーの構成と実行とVS Code での Python デバッグに関するページを参照してください。
PyCharm と Python
注意
Databricks Connect の使用を開始する前に、要件を満たし、Databricks Connect のクライアントを設定する必要があります。
IntelliJ IDEA Ultimate は、Python を使用する PyCharm のプラグイン サポートも提供されます。 詳細については、IntelliJ IDEA Ultimate 用の Python プラグインに関する記事 (英語) を参照してください。
PyCharm と Python で Databricks Connect を使用するには、次の手順に従います。
- PyCharm を起動します。
- プロジェクトの作成: [ファイル] > [新しいプロジェクト] の順にクリックします。
- [Location] でフォルダー アイコンをクリックし、ご使用の Python 仮想環境へのパスを選択します。
- [以前に構成されたインタープリター] を選びます。
- [インタープリター] で省略記号をクリックします。
- [システム インタープリター] をクリックします。
- [Interpreter] で省略記号をクリックし、仮想環境から参照される Python インタープリターへの完全なパスを選択します。 次に、 [OK] をクリックします
- もう一度 [OK] をクリックします。
- Create をクリックしてください。
- [既存のソースから作成] をクリックします。
- コード例または独自のコードを含む Python コード (
.py) ファイルをプロジェクトに追加します。 独自のコードを使用する場合は、コード例に示すように、少なくともDatabricksSessionをインスタンス化する必要があります。 - Python コード ファイルを開いた状態で、実行中にコードを一時停止するブレークポイントを設定します。
- コードを実行するには、[実行] > [実行] をクリックします。 すべての Python コードはローカルで実行されますが、DataFrame 操作を含むすべての PySpark コードは、リモートの Azure Databricks ワークスペース内のクラスターで実行され、実行応答がローカル呼び出し元に返送されます。
- コードをデバッグするには、[実行] > [デバッグ] をクリックします。 すべての Python はローカルでデバッグされますが、すべての PySpark コードはリモートの Azure Databricks ワークスペース内のクラスターで引き続き実行されます。 コア Spark エンジン コードをクライアントから直接デバッグすることはできません。
- 画面の指示に従って、コードの実行またはデバッグを開始します。
実行とデバッグの具体的な手順については、「Run without any previous configuring」 (事前の構成なしで実行) と「Debug」 (デバッグ) を参照してください。
Eclipse と PyDev
Eclipse と PyDev で Databricks Connect を使用するには、次の手順に従います。
- Eclipse を起動します。
- [File]>[New]>[Project]>[PyDev]>[PyDev Project] の順にクリックし、[Next] をクリックして、プロジェクトを作成します。
- プロジェクト名を指定します。
- [Project contents] で、Python 仮想環境へのパスを指定します。
- [Please configure an interpreter before proceding] をクリックします。
- [Manual config]をクリックします。
- [New]>[Browse for python/pypy exe] をクリックします。
- 仮想環境から参照される Python インタープリターへの完全なパスを参照して選択し、[Open] をクリックします。
- [Select interpreter] ダイアログで、[OK] をクリックします。
- [Selection needed] ダイアログで、[OK] をクリックします。
- [Preferences] ダイアログで、[Apply and Close] をクリックします。
- [PyDev Project] ダイアログで、[Finish] をクリックします。
- [Open Perspective] をクリックします。
- コード例または独自のコードを含む Python コード (
.py) ファイルをプロジェクトに追加します。 独自のコードを使用する場合は、コード例に示すように、少なくともDatabricksSessionをインスタンス化する必要があります。 - Python コード ファイルを開いた状態で、実行中にコードを一時停止するブレークポイントを設定します。
- コードを実行するには、[実行] > [実行] をクリックします。 すべての Python コードはローカルで実行されますが、DataFrame 操作を含むすべての PySpark コードは、リモートの Azure Databricks ワークスペース内のクラスターで実行され、実行応答がローカル呼び出し元に返送されます。
- コードをデバッグするには、[実行] > [デバッグ] をクリックします。 すべての Python はローカルでデバッグされますが、すべての PySpark コードはリモートの Azure Databricks ワークスペース内のクラスターで引き続き実行されます。 コア Spark エンジン コードをクライアントから直接デバッグすることはできません。
具体的な実行とデバッグの手順については、プログラムの実行に関する記事 (英語) を参照してください。
Spark シェルと Python
注意
Databricks Connect の使用を開始する前に、要件を満たし、Databricks Connect のクライアントを設定する必要があります。
Spark シェルは、Azure Databricks 個人用アクセス トークン認証の認証でのみ機能します。
Spark シェルと Python で Databricks Connect を使用するには、次の手順に従います。
Spark シェルを起動し、実行中のクラスターに接続するには、アクティブな Python 仮想環境から次のいずれかのコマンドを実行します。
SPARK_REMOTE環境変数を前に設定した場合は、次のコマンドを実行します。pysparkSPARK_REMOTE環境変数を前に設定しなかった場合は、代わりに次のコマンドを実行します。pyspark --remote "sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>"Spark シェルが表示されます。次に例を示します。
Python 3.10 ... [Clang ...] on darwin Type "help", "copyright", "credits" or "license" for more information. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 13.x.dev0 /_/ Using Python version 3.10 ... Client connected to the Spark Connect server at sc://...:.../;token=...;x-databricks-cluster-id=... SparkSession available as 'spark'. >>>Spark シェルと Python を使用してお使いのクラスターでコマンドを実行する方法については、「Interactive Analysis with the Spark Shell (Spark Shell による対話型分析) を参照してください。
組み込みの
spark変数を使用して、実行中のクラスターのSparkSessionを表します。次に例を示します。>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsすべての Python コードはローカルで実行されますが、DataFrame 操作を含むすべての PySpark コードは、リモートの Azure Databricks ワークスペース内のクラスターで実行され、実行応答がローカル呼び出し元に返送されます。
Spark シェルを停止するには、
Ctrl + dまたはCtrl + zを押すか、コマンドquit()またはexit()を実行します。
コード例
Databricks には、Databricks Connect の使用方法を示すいくつかのサンプル アプリケーションが用意されています。 GitHub の databricks-demos/dbconnect-examples リポジトリを参照してください。
また、次のより単純なコード サンプルを使用して、Databricks Connect を実験することもできます。 これらの例では、Databricks Connect に既定の認証を使用していることを前提としています。
この単純なコード例は、指定されたテーブルに対してクエリを実行して、指定されたテーブルの最初の 5 行を表示します。 異なるテーブルを使用するには、spark.read.table への呼び出しを調整します。
from databricks.connect import DatabricksSession
spark = DatabricksSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
次の長いコード例の実行内容は次のとおりです。
- メモリ内 DataFrame を作成します。
defaultスキーマ内にzzz_demo_temps_tableという名前のテーブルを作成します。 この名前のテーブルが既に存在する場合は、まずテーブルが削除されます。 異なるスキーマまたはテーブルを使用するには、spark.sql、temps.write.saveAsTable、または両方への呼び出しを調整します。- DataFrame の内容をテーブルに保存します。
- テーブルの内容に対して
SELECTクエリを実行します。 - クエリの結果を表示します。
- テーブルを削除します。
from databricks.connect import DatabricksSession
from pyspark.sql.types import *
from datetime import date
spark = DatabricksSession.builder.getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
最新の Databricks Connect に移行する
Databricks Runtime 12.2 LTS 以下用の Databricks Connect から Databricks Runtime 13.0 以上用の Databricks Connect に既存の Python コード プロジェクトまたはコーディング環境を移行するには、次のガイドラインに従います。
注意
Databricks Runtime 13.0 以上用の Databricks Connect は現在、Python ベースのプロジェクトとコーディング環境のみをサポートしています。
Python がローカルにまだインストールされていない場合は、Azure Databricks クラスターに適合するように、要件にリストされている正しいバージョンをインストールします。
必要に応じて、クラスターに適合する正しいバージョンの Python を使用するように Python 仮想環境をアップグレードします。 手順については、仮想環境プロバイダーのドキュメントを参照してください。
仮想環境がアクティブな状態で、仮想環境から PySpark をアンインストールします。
pip3 uninstall pyspark仮想環境がアクティブな状態のままで、Databricks Runtime 12.2 LTS 以下用の Databricks Connect をアンインストールします。
pip3 uninstall databricks-connect仮想環境がアクティブな状態のままで、Databricks Runtime 13.0 以上用の Databricks Connect をインストールします。
pip3 install --upgrade "databricks-connect==13.1.*" # Or X.Y.* to match your cluster version.注意
Databricks では、最新のパッケージがインストールされるように、
databricks-connect=X.Yではなくdatabricks-connect==X.Y.*を指定する "ドットとアスタリスク" の表記を追加することをお勧めします。 これは要件ではありませんが、そのクラスターでサポートされている最新の機能を使用できるようにするのに役立ちます。spark変数 (PySpark でのSparkSessionと同様に、DatabricksSessionクラスのインスタンス化を表す) を初期化するように Python コードを更新します。 コード例については、「手順 2: 接続プロパティの構成」を参照してください。
Databricks ユーティリティにアクセスする
このセクションでは、Databricks Connect を使用して Databricks ユーティリティにアクセスする方法について説明します。
Azure Databricks ワークスペース内から Databricks ファイル システム (DBFS) 関数を呼び出すことができます。 これを行うには、WorkspaceClient クラスの dbfs 変数を使用します。 この方法は、ワークスペース内のノートブックから dbfs 変数を使用して Databricks ユーティリティを呼び出すのと似ています。 WorkspaceClient クラスは、Databricks Runtime 13.0 以上用の Databricks Connect に含まれる Databricks SDK for Python に属しています。
ヒント
付属の Databricks SDK for Python を使用して、DBFS API だけでなく、使用可能ないずれの Databricks REST API にもアクセスできます。 PyPI の databricks-sdk を参照してください。
WorkspaceClient を初期化するには、ワークスペースで Databricks SDK for Python を認証するのに十分な情報を提供する必要があります。 たとえば、次のようなことができます。
ワークスペース URL とアクセス トークンをコード内で直接ハードコーディングし、
WorkspaceClientを次のように初期化します。 このオプションはサポートされていますが、コードがバージョン 管理にチェックインされているか、その他の方法で共有されている場合に、アクセス トークンなどの機密情報が公開される可能性があるため、Databricks はこのオプションをお勧めしません。w = WorkspaceClient(host = "https://<workspace-instance-name>", token = "<access-token-value")フィールド
hostとtokenを含む構成プロファイルを作成または指定し、次のようにWorkspaceClientを初期化します。w = WorkspaceClient(profile = "<profile-name>")Databricks Connect に設定するのと同じ方法で環境変数
DATABRICKS_HOSTとDATABRICKS_TOKENを設定し、WorkspaceClientを次のように初期化します。w = WorkspaceClient()
Databricks SDK for Python は、Databricks Connect の SPARK_REMOTE 環境変数を認識しません。
Databricks SDK for Python の追加の Azure Databricks 認証オプション、および Databricks SDK for Python 内で AccountClient を初期化して、使用可能な Databricks REST API にワークスペース レベルではなくアカウント レベルでアクセスする方法については、PyPI の databricks-sdk を参照してください。
次の例は、ワークスペース内の DBFS ルートに zzz_hello.txt という名前のファイルを作成し、そのファイルにデータを書き込み、ファイルを閉じて、ファイルからデータを読み取り、ファイルを削除します。 この例は、環境変数 DATABRICKS_HOST と DATABRICKS_TOKEN が既に設定されていることを想定しています。
from databricks.sdk import WorkspaceClient
import base64
w = WorkspaceClient()
file_path = "/zzz_hello.txt"
file_data = "Hello, Databricks!"
# The data must be base64-encoded before being written.
file_data_base64 = base64.b64encode(file_data.encode())
# Create the file.
file_handle = w.dbfs.create(
path = file_path,
overwrite = True
).handle
# Add the base64-encoded version of the data.
w.dbfs.add_block(
handle = file_handle,
data = file_data_base64.decode()
)
# Close the file after writing.
w.dbfs.close(handle = file_handle)
# Read the file's contents and then decode and print it.
response = w.dbfs.read(path = file_path)
print(base64.b64decode(response.data).decode())
# Delete the file.
w.dbfs.delete(path = file_path)
ヒント
w.secrets を使用して Databricks ユーティリティの secrets ユーティリティにし、w.jobs を使用して jobs ユーティリティに、w.libraries を使用してlibrary ユーティリティにアクセスすることもできます。
Databricks Connect の無効化
Databricks Connect (および基になる Spark Connect) サービスは、任意のクラスターで無効にすることができます。 Databricks Connect サービスを無効にするには、クラスターで次の Spark 構成を設定します。
spark.databricks.service.server.enabled false
無効にすると、クラスターに到達するすべての Databricks Connect クエリは、適切なエラー メッセージで拒否されます。
Hadoop 構成を設定する
クライアントでは、spark.conf.set API を使用して Hadoop 構成を設定できます。これは、SQL と DataFrame の操作に適用されます。 sparkContext に設定された Hadoop 構成は、クラスター構成に設定するか、ノートブックを使用する必要があります。 これは、sparkContext に設定された構成はユーザー セッションに関連付けられるのではなく、クラスター全体に適用されるからです。
トラブルシューティング
このセクションでは、Databricks Connect で発生する可能性がある一般的な問題とその解決方法について説明します。
このセクションの内容は次のとおりです。
- エラー: StatusCode.UNAVAILABLE、StatusCode.UNKNOWN、DNS の解決に失敗したか、状態 500 の http2 ヘッダーを受信しました
- Python のバージョンが一致しない
- 競合している PySpark インストール
- バイナリの
PATHエントリの競合または欠落 - Windows 上のファイル名、ディレクトリ名、ボリューム ラベル構文が正しくない
エラー: StatusCode.UNAVAILABLE、StatusCode.UNKNOWN、DNS の解決に失敗したか、状態 500 の http2 ヘッダーを受信しました
問題: Databricks Connect でコードを実行しようとすると、StatusCode.UNAVAILABLE、StatusCode.UNKNOWN、DNS resolution failed、Received http2 header with status: 500 などの文字列を含むエラー メッセージが表示されます。
考えられる原因: Databricks Connect がクラスターに到達できません。
推奨される解決策:
- ワークスペース インスタンス名が正しいことを確認します。 環境変数を使用する場合は、お使いのローカル開発マシンで関連する環境変数が使用可能であり、正しいことを確認します。
- クラスター ID が正しいことを確認します。 環境変数を使用する場合は、お使いのローカル開発マシンで関連する環境変数が使用可能であり、正しいことを確認します。
- ご使用のクラスターのカスタム クラスター バージョンが、Databricks Connect と互換性のある適切ものであることを確認します。
Python のバージョンが一致しない
ローカルで使用している Python バージョンのマイナー リリースが、少なくともクラスター上のバージョンと同じ (たとえば、3.10.11 と 3.10.10 なら OK で、3.10 と 3.9 ではダメ) ことを確認します。
複数の Python バージョンがローカルにインストールされている場合は、PYSPARK_PYTHON 環境変数 (たとえば、PYSPARK_PYTHON=python3) を設定して、Databricks Connect で適切なバージョンが使用されていることを確認します。
競合している PySpark インストール
databricks-connect パッケージが PySpark と競合している。 両方をインストールすると、Python で Spark コンテキストを初期化するときにエラーが発生します。 これは、"ストリームの破損" エラーや "クラスが見つかりません" エラーなど、いくつかのパターンで現れる可能性があります。 Python 環境に PySpark がインストールされている場合は、Databricks Connect をインストールする前に PySpark をアンインストールしておくようにしてください。 PySpark をアンインストールした後、Databricks Connect パッケージをすべて再インストールしてください。
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==13.1.*" # or X.Y.* to match your specific cluster version.
バイナリの PATH エントリの競合または欠落
spark-shell のようなコマンドが、Databricks Connect のバイナリではなく、以前にインストールされた他のバイナリを実行するよう、PATH が構成されている場合があります。 Databricks Connect のバイナリを優先とするか、以前にインストールしたバイナリを削除する必要があります。
spark-shell のようなコマンドを実行できない場合、 PATH が pip3 install によって自動的に設定されていない可能性があり、インストール bin ディレクトリを PATH に手動で追加する必要があります。 これが設定されていない場合でも、IDE で Databricks Connect を使用できます。
Windows 上のファイル名、ディレクトリ名、ボリューム ラベル構文が正しくない
Databricks Connect を Windows で使用していて、以下が表示される場合
The filename, directory name, or volume label syntax is incorrect.
Databricks Connect がスペースを含むパスのディレクトリにインストールされました。 これに対処するには、スペースのないディレクトリ パスに をインストールするか、短縮名形式を使用してパスを構成します。
制限事項
Databricks Connect は、次の Azure Databricks の機能とサードパーティのプラットフォームをサポートしません。
PySpark DataFrame API の制限事項
SparkContextクラスとそのメソッドは使用できません。- Resilient Distributed Dataset (RDD) と Datasets はサポートされていません。 DataFrame のみがサポートされています。
Azure Databricks と Databricks Connect の制限事項
- 期間が 3600 秒を超えるクエリはサポートされていないため、失敗します。
- ローカル開発環境とリモート クラスターの同期はサポートされていません。
- コードの互換性を確保し、予期しない実行時エラーを減らすために、ローカル開発環境で使用する Python バージョンと Python パッケージは、クラスターにインストールされている同等のものとできるだけ一致するようにしてください。
- Python のみがサポートされています。 R、Scala、Java はサポートされていません。
- 分散トレーニングはサポートされません。
- MLflow はサポートされていますが、
mlflow.pyfunc.spark_udf(spark, ...)を使用したモデル推論はされていません。mlflow.pyfunc.load_model(<model>)を使用してモデルをローカルに読み込むか、カスタム Pandas UDF としてそれをラップできます。 SparkContextを使用して Log4j ログ レベルを変更することはできません。- Mosaic はサポートされていません。
Azure Databricks クラスターの制限事項
Databricks Connect で使用されるアクセス トークンに関連付けられている Azure Databricks ワークスペース ユーザーには、ターゲット クラスターに対するアタッチ可能以上のアクセス許可が必要です。
CREATE TABLE table AS SELECT ...SQL コマンドは常に機能するとは限りません。 代わりにspark.sql("SELECT ...").write.saveAsTable("table")を使用してください。Azure Active Directory 資格情報のパススルーは Databricks Runtime 7.3 LTS 以降を実行している標準クラスターでのみサポートされており、サービスプリンシパル認証と互換性がありません。
Azure Active Directory (AD) トークンは自動的に更新されず、最初に生成されてから 1 時間後に有効期限が切れます。