Google BigQuery
この記事では、Azure Databricks で Google BigQuery テーブルの読み取りと書き込みを行う方法について説明します。
重要
この記事で説明する構成は試験段階です。 実験用の機能は現状のまま提供されていて、カスタマー テクニカル サポートを通じて Databricks でサポートされているわけではありません。 クエリフェデレーションの完全なサポートを得るには、代わりにレイクハウス フェデレーション を使用する必要があります。これにより、Azure Databricks ユーザーは Unity Catalog 構文とデータ ガバナンス ツールを利用できます。
キーベースの認証を使用して BigQuery に接続する必要があります。
アクセス許可
プロジェクトには、BigQuery を使用して読み書きするための特定の Google アクセス許可が必要です。
注意
この記事では、BigQuery の具体化されたビューについて説明します。 詳細については、Google の記事「具体化されたビューの概要」を参照してください。 他の BigQuery の用語と BigQuery セキュリティ モデルについては、Google BigQuery のドキュメントを参照してください。
BigQuery を使用したデータの読み取りと書き込みは、次の 2 つの Google Cloud プロジェクトによって異なります。
- プロジェクト (
project): Azure Databricks が BigQuery テーブルの読み取りまたは書き込みを行う Google Cloud プロジェクトの ID。 - 親プロジェクト (
parentProject): 親プロジェクトの ID。読み取りと書き込みに対する課金に使用される Google Cloud プロジェクト ID です。 これを、キーを生成する Google サービス アカウントに関連付けられている Google Cloud プロジェクトに設定します。
BigQuery にアクセスするコードでは、project と parentProject の値を明示的に指定する必要があります。 次のようなコードを使用します。
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Google Cloud プロジェクトに必要なアクセス許可は、project と parentProject が同じかどうかによって異なります。 次のセクションでは、各シナリオに必要なアクセス許可の一覧を示します。
project と parentProject が同じである場合に必要なアクセス許可
project と parentProject の ID が同じである場合は、次の表を使用して最小限のアクセス許可を判断します。
| Azure Databricks タスク | プロジェクトで必要な Google のアクセス許可 |
|---|---|
| 具体化されたビューを使用せずに BigQuery テーブルを読み取る | project プロジェクト:- BigQuery 読み取りセッション ユーザー - BigQuery データ ビューアー (必要に応じて、プロジェクト レベルではなくデータセット/テーブル レベルで権限を付与できます) |
| 具体化されたビューを使用して BigQuery テーブルを読み取る | project プロジェクト:- BigQuery ジョブ ユーザー - BigQuery 読み取りセッション ユーザー - BigQuery データ ビューアー (必要に応じて、プロジェクト レベルではなくデータセット/テーブル レベルで権限を付与できます) 具体化プロジェクト: - BigQuery データ エディター |
| BigQuery テーブルを書き込む | project プロジェクト:- BigQuery ジョブ ユーザー - BigQuery データ エディター |
project と parentProject が異なる場合に必要なアクセス許可
project と parentProject の ID が異なる場合は、次の表を使用して最小限のアクセス許可を判断します。
| Azure Databricks タスク | 必要な Google アクセス許可 |
|---|---|
| 具体化されたビューを使用せずに BigQuery テーブルを読み取る | parentProject プロジェクト:- BigQuery 読み取りセッション ユーザー project プロジェクト:- BigQuery データ ビューアー (必要に応じて、プロジェクト レベルではなくデータセット/テーブル レベルで権限を付与できます) |
| 具体化されたビューを使用して BigQuery テーブルを読み取る | parentProject プロジェクト:- BigQuery 読み取りセッション ユーザー - BigQuery ジョブ ユーザー project プロジェクト:- BigQuery データ ビューアー (必要に応じて、プロジェクト レベルではなくデータセット/テーブル レベルで権限を付与できます) 具体化プロジェクト: - BigQuery データ エディター |
| BigQuery テーブルを書き込む | parentProject プロジェクト:- BigQuery ジョブ ユーザー project プロジェクト:- BigQuery データ エディター |
手順 1: Google Cloud を設定する
BigQuery Storage API を有効にする
BigQuery Storage API は、BigQuery が有効になっている新しい Google Cloud プロジェクトで既定で有効になっています。 ただし、既存のプロジェクトがあり、BigQuery Storage API が有効になっていない場合は、このセクションの手順に従って有効にします。
BigQuery Storage API は、Google Cloud CLI または Google Cloud Console を使用して有効にすることができます。
Google Cloud CLI を使用して BigQuery Storage API を有効にする
gcloud services enable bigquerystorage.googleapis.com
Google Cloud Console を使用して BigQuery Storage API を有効にする
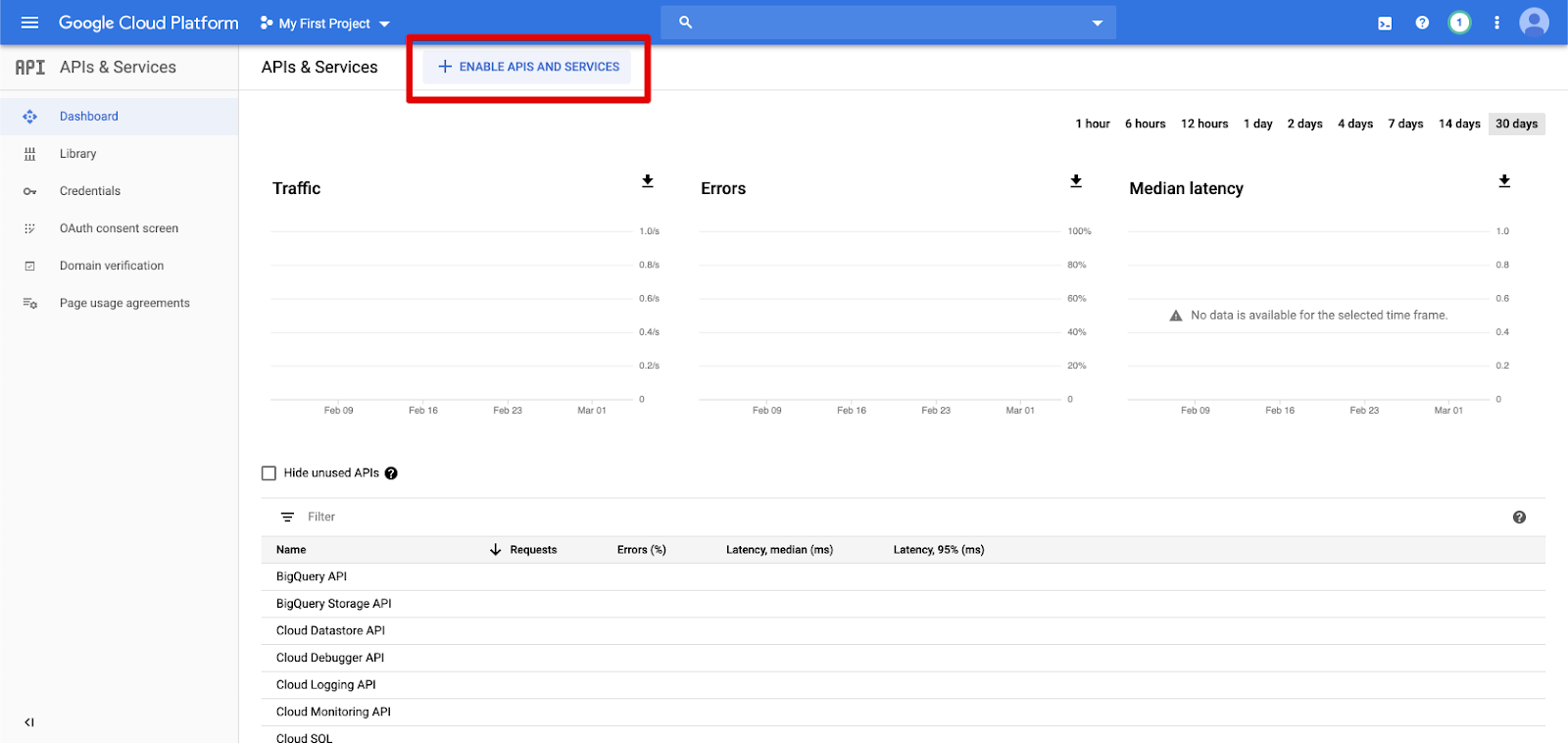
左側のナビゲーション ウィンドウで [API およびサービス] をクリックします。
[API とサービスの有効化] ボタンをクリックします。
検索バーに「
bigquery storage api」と入力し、最初の結果を選択します。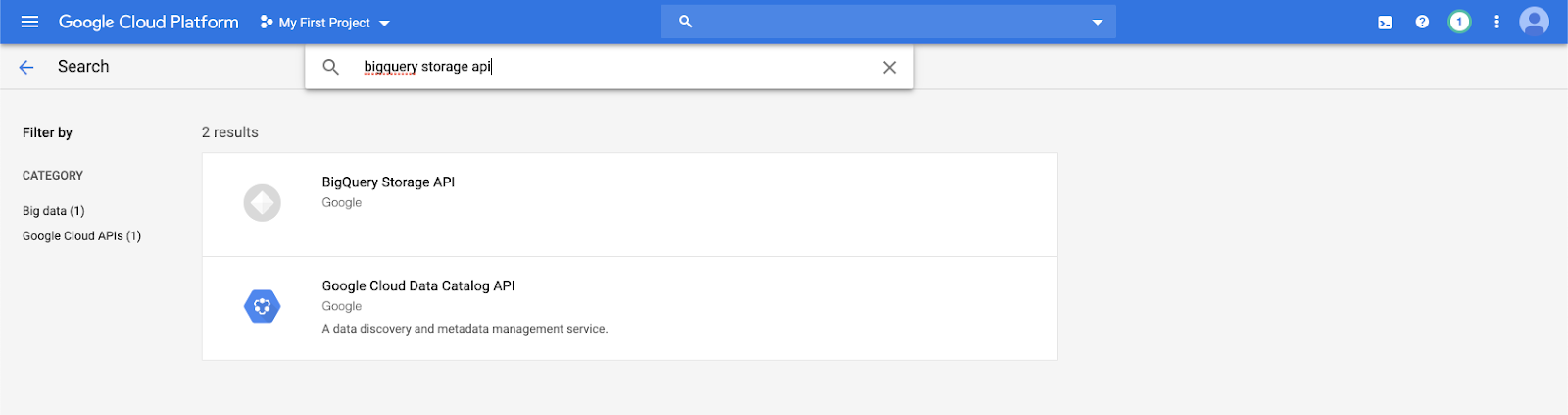
BigQuery Storage API が有効になっていることを確認します。
Azure Databricks の Google サービス アカウントを作成する
Azure Databricks クラスターのサービス アカウントを作成します。 Databricks では、タスクを実行するために必要な最小限の特権をこのサービス アカウントに付与することをお勧めします。 BigQuery のロールとアクセス許可に関するページを参照してください。
Google Cloud CLI または Google Cloud Console を使用して、サービス アカウントを作成できます。
Google Cloud CLI を使用して Google サービス アカウントを作成する
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
サービス アカウントのキーを作成します。
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Google Cloud Console を使用して Google サービス アカウントを作成する
アカウントを作成するには
左側のナビゲーション ウィンドウで [IAM and Admin](IAM と管理) をクリックします。
[サービス アカウント] をクリックします。
[+ CREATE SERVICE ACCOUNT](サービス アカウントの作成) をクリックします。
サービス アカウント名と説明を入力します。
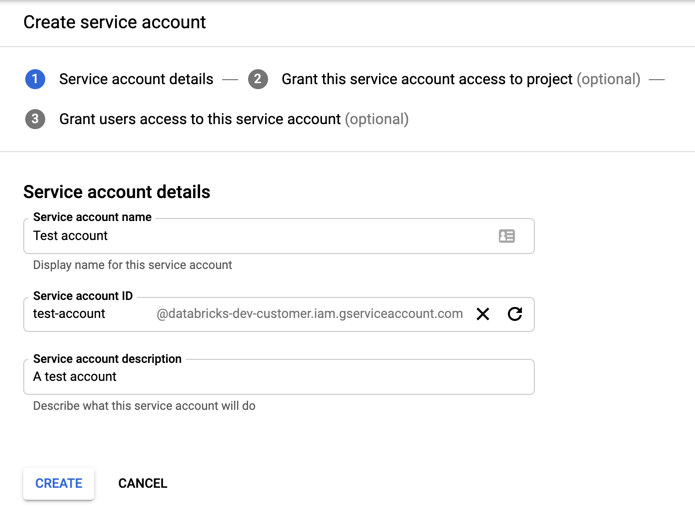
[作成] をクリックします。
サービス アカウントのロールを指定します。 [ロールの選択] ドロップダウンで、「
BigQuery」と入力して次のロールを追加します。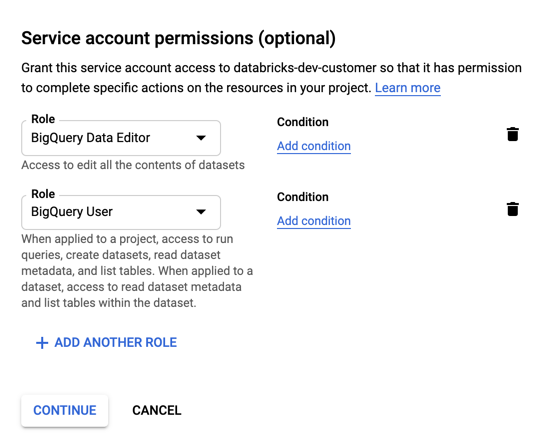
[続行] をクリックします。
[完了] をクリックします。
サービス アカウントのキーを作成するには
サービス アカウントの一覧で、新しく作成したアカウントをクリックします。
[キー] セクションで、[キーを追加] > [新しいキーの作成] ボタンを選択します。
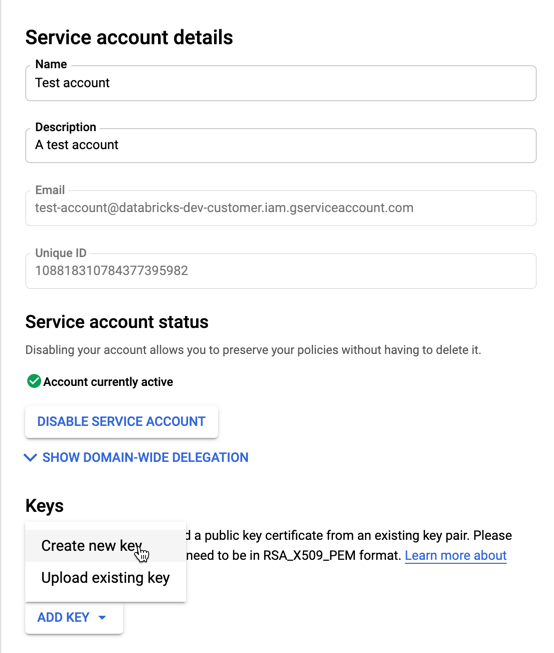
JSON キーの種類をそのまま使用します。
[作成] をクリックします。 JSON キー ファイルがコンピューターにダウンロードされます。
重要
サービス アカウント用に生成する JSON キー ファイルは秘密キーであり、Google Cloud アカウント内のデータセットとリソースへのアクセスを制御するため、承認されたユーザーとのみ共有する必要があります。
一時ストレージ用の Google Cloud Storage (GCS) バケットを作成する
BigQuery にデータを書き込むには、データ ソースが GCS バケットにアクセスする必要があります。
左側のナビゲーション ウィンドウで [ストレージ] をクリックします。
[CREATE BUCKET](バケットの作成) をクリックします。
バケットの詳細を構成します。
[作成] をクリックします。
[アクセス許可] タブと [メンバーの追加] をクリックします。
バケットのサービス アカウントに次のアクセス許可を付与します。
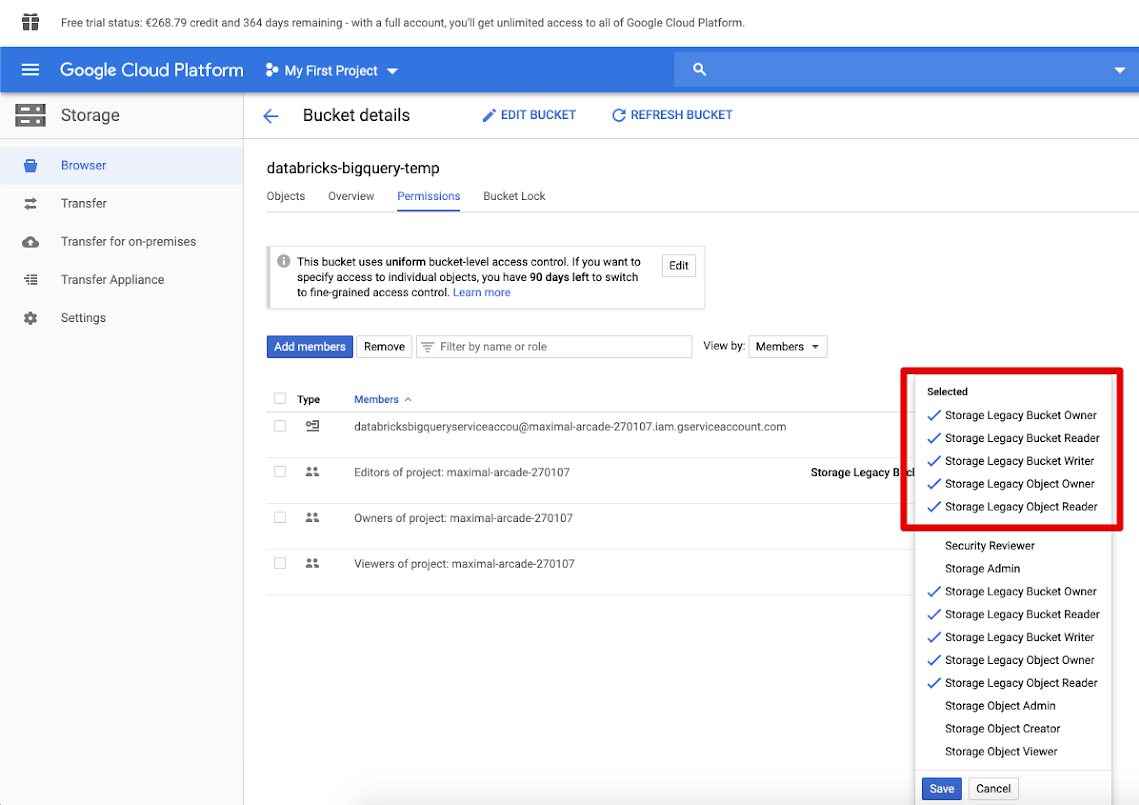
[保存] をクリックします。
手順 2: Azure Databricks を設定する
BigQuery テーブルにアクセスするようにクラスターを構成するには、JSON キー ファイルを Spark 構成として指定する必要があります。 ローカル ツールを使用して、JSON キー ファイルを Base64 エンコードします。 セキュリティ上の理由により、キーにアクセスできる Web ベースのツールやリモート ツールは使用しないでください。
クラスターを構成する場合、次の手順を実行します。
[Spark 構成] タブで、次の Spark 構成を追加します。<base64-keys> を Base64 でエンコードされた JSON キー ファイルの文字列に置き換えます。 かっこ内の他の項目 (<client-email> など) を、JSON キー ファイルのこれらのフィールドの値に置き換えます。
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
BigQuery テーブルの読み取りと書き込み
BigQuery テーブルを読み取る場合は、次のように指定します。
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
BigQuery テーブルに書き込むには、次のように指定します。
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
ここで <bucket-name> は、「一時ストレージ用の Google Cloud Storage (GCS) バケットを作成する」で作成したバケットの名前です。 値と<project-id> 値の要件については、「<parent-id>」を参照してください。
BigQuery から外部テーブルを作成する
重要
この機能は Unity Catalog ではサポートされていません。
Databricks で、BigQuery から直接データを読み取るアンマネージ テーブルを宣言できます。
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Python ノートブックの例: Google BigQuery テーブルを DataFrame に読み込む
次の Python ノートブックでは、Google BigQuery テーブルを Azure Databricks DataFrame に読み込んでいます。
Google BigQuery Python サンプル ノートブック
Scala ノートブックの例: Google BigQuery テーブルを DataFrame に読み込む
次の Scala ノートブックでは、Google BigQuery テーブルを Azure Databricks DataFrame に読み込んでいます。