専用コンピューティング (以前のシングル ユーザー コンピューティング) でのきめ細かいアクセス制御
この記事では、専用コンピューティング (専用 アクセス モードで構成された汎用またはジョブ コンピューティング) で実行されるクエリに対してきめ細かいアクセス制御を可能にするデータ フィルター機能 紹介します。 「アクセス モード」を参照してください。
このデータ フィルター処理は、サーバーレス コンピューティングを使用してバックグラウンドで実行されます。
専用コンピューティングの一部のクエリでデータ フィルター処理が必要な理由
Unity カタログでは、次の機能を使用して、列と行レベル (詳細なアクセス制御とも呼ばれます) で表形式データへのアクセスを制御できます。
ユーザーが参照されるテーブルからデータを除外したり、フィルターやマスクを適用しているテーブルにクエリを行ったりする場合、次のコンピューティング リソースを制限なく利用できます。
- SQL ウェアハウス
- スタンダード コンピュート (以前の共有コンピュート)
ただし、専用のコンピューティングを使用してこのようなクエリを実行する場合は、コンピューティングとワークスペースが特定の要件を満たしている必要があります。
専用のコンピューティング リソースは、Databricks Runtime 15.4 LTS 以降にある必要があります。
そのワークスペースが、ジョブ、ノートブック、Delta Live テーブルのサーバーレス コンピューティングで有効である必要があります。
ワークスペース リージョンでサーバーレス コンピューティングがサポートされていることを確認するには、「リージョンで可用性が制限される機能」をご覧ください。
専用のコンピューティング リソースとワークスペースがこれらの要件を満たしている場合、詳細なアクセス制御を使用するビューまたはテーブルに対してクエリを実行するたびに、データ フィルター処理が自動的に実行されます。
具体化されたビュー、ストリーミング テーブル、標準ビューのサポート
動的ビュー、行フィルター、列マスクに加えて、データ フィルターを使用すると、Databricks Runtime 15.3 以下を実行している専用コンピューティングではサポートされていない次のビューとテーブルに対するクエリも有効になります。
Databricks Runtime 15.3 以下を実行する専用コンピューティングでは、ビューでクエリを実行するユーザーは、ビューによって参照されるテーブルとビューに SELECT する必要があります。つまり、ビューを使用してきめ細かいアクセス制御を提供することはできません。 Databricks Runtime 15.4 とデータ フィルター処理では、ビューでクエリを実行するユーザーは、参照先のテーブルとビューへのアクセス許可を必要としません。
専用コンピューティングでのデータ フィルター処理のしくみ
クエリが次のデータベース オブジェクトにアクセスするたびに、専用のコンピューティング リソースによってクエリがサーバーレス コンピューティングに渡され、データ フィルター処理が実行されます。
- ユーザーが
SELECT権限を持っていないテーブル上に構築されたビュー - 動的ビュー
- 行フィルターまたは列マスクが定義されているテーブル
- 具体化されたビューとストリーミング テーブル
次の図では、ユーザーは行フィルターが適用された SELECT、table_1、view_2 に table_w_rls 権限を持っています。 ユーザーは、SELECT によって参照される table_2には view_2 権限を持っていません。

フィルター処理は必要ないため、table_1 のクエリは専用のコンピューティング リソースによって完全に処理されます。
view_2 および table_w_rls に対するクエリでは、ユーザーがアクセスできるデータを返すにはデータ フィルター処理が必要です。 これらのクエリは、サーバーレス コンピューティングのデータ フィルター機能によって処理されます。
どのようなコストが発生しますか?
お客様は、データ フィルター処理の実行に使用するサーバーレス コンピューティング リソースに対して課金されます。 価格情報については、「プラットフォーム レベルとアドオンを参照してください。
システム課金の使用状況テーブルに対してクエリを実行すると、請求額を確認できます。 たとえば、次のクエリでは、ユーザー別にコンピューティング コストを分類します。
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
データ フィルター処理が行われるときのクエリのパフォーマンスを表示する
専用コンピューティングの Spark UI には、クエリのパフォーマンスを理解するために使用できるメトリックが表示されます。 コンピューティング リソースで実行するクエリごとに、SQL/データフレーム タブにクエリ グラフの表現が表示されます。 クエリがデータ フィルター処理に関係していた場合、UI はグラフの下部に RemoteSparkConnectScan オペレーター ノードを表示します。 そのノードには、クエリのパフォーマンスを調査するために使用できるメトリックが表示されます。 「Apache Spark UI でコンピューティング情報を表示する」をご覧ください。
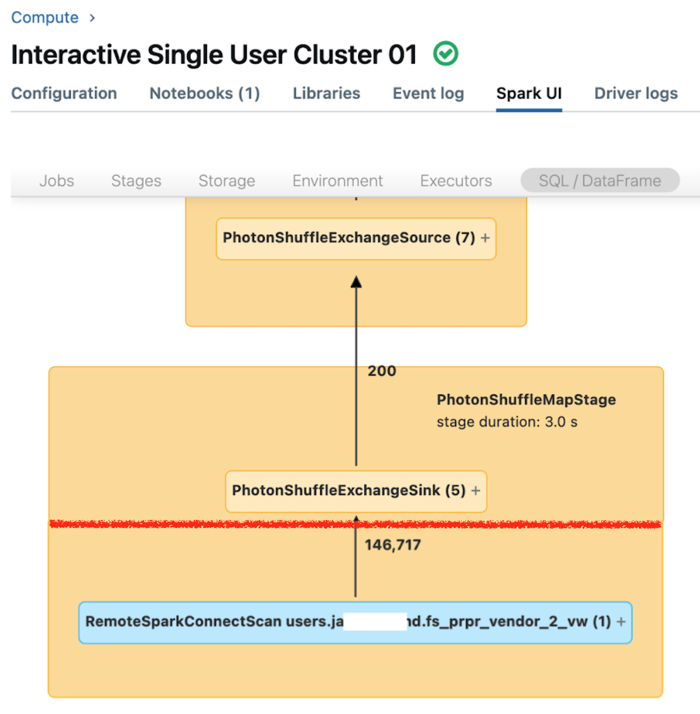
RemoteSparkConnectScan オペレーター ノードを展開すると、次のような質問に対処できるメトリックが表示されます。
- データ フィルター処理にかかった時間 "リモート実行時間の合計" を確認します。
- データ フィルター処理後に残った行の数 "行の出力" を確認します。
- データ フィルター処理後に返されたデータの量 (バイト単位) "行の出力サイズ" を確認します。
- パーティション排除され、ストレージから読み取る必要がなかったデータ ファイルの数 "排除されたファイル" と "排除されたファイルのサイズ" を確認します。
- 排除できず、ストレージから読み取る必要があったデータ ファイルの数 "読み取られたファイル" と "読み取られたファイルのサイズ" を確認します。
- 読み取る必要があったファイルのうち、キャッシュに既にあったファイルの数 "キャッシュ ヒット サイズ" と "キャッシュ ミス サイズ" を確認します。
制限事項
行フィルターまたは列マスクが適用されているテーブルに対する書き込みまたは更新のテーブル操作はサポートされません。
具体的には、
INSERT,DELETE、UPDATE、REFRESH TABLE、MERGEなどの DML 操作はサポートされていません。 これらのテーブルには、読み込み (SELECT) のみ可能です。データ フィルターが呼び出されると、自己結合は既定でブロックされますが、これらのコマンドを実行するコンピューティングで
spark.databricks.remoteFiltering.blockSelfJoinsを false に設定することで許可できます。専用コンピューティング リソースで自己結合を有効にする前に、データ フィルター機能によって処理される自己結合クエリが同じリモート テーブルのさまざまなスナップショットを返す可能性があることに注意してください。
- Docker イメージではサポートされません。