HorovodRunner: Horovod を使用した分散型ディープ ラーニング
重要
Horovod と HorovodRunner は非推奨になりました。 15.4 LTS ML 以降のリリースでは、このパッケージはプレインストールされません。 分散ディープ ラーニングの場合、Databricks では、PyTorch での分散トレーニングに TorchDistributor を使用するか、TensorFlow を使用した分散トレーニング用の tf.distribute.Strategy API を使用することをお勧めします。
HorovodRunner を使用して機械学習モデルの分散トレーニングを実行し、Azure Databricks で Spark ジョブとして Horovod トレーニング ジョブを起動する方法について説明します。
HorovodRunner とは
HorovodRunner は、Horovod フレームワークを使用して Azure Databricks で分散型ディープ ラーニング ワークロードを実行するための一般的な API です。 Horovod を Spark のバリア モードと統合することで、Azure Databricks は、Spark 上で実行時間の長いディープ ラーニング トレーニング ジョブの安定性を高めることができます。 HorovodRunner は、Horovod フックを使用したディープ ラーニング トレーニング コードを含む Python メソッドを受け取ります。 HorovodRunner によってドライバーのメソッドが pickle され、Spark worker に配布されます。 Horovod MPI ジョブは、バリア実行モードを使用して Spark ジョブとして埋め込まれます。 最初の Executor は、BarrierTaskContext を使用してすべてのタスクの Executor の IP アドレスを収集し、mpirun を使用して Horovod ジョブをトリガーします。 Python MPI プロセスごとに、pickle されたユーザー プログラムが読み込まれ、逆シリアル化され、実行されます。
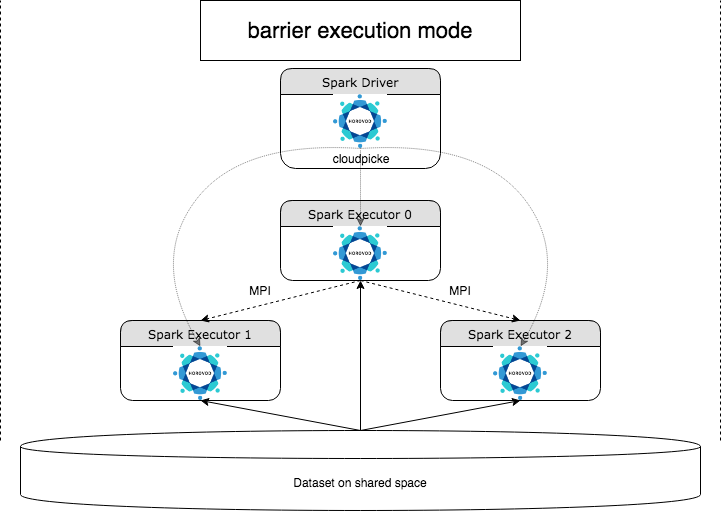
HorovodRunner を使用した分散トレーニング
HorovodRunner を使用すると、Horovod トレーニング ジョブを Spark ジョブとして起動できます。 HorovodRunner API では、表に示すメソッドがサポートされています。 詳細については、HorovodRunner API のドキュメントを参照してください。
| メソッドとシグネチャ | 説明 |
|---|---|
init(self, np) |
HorovodRunner のインスタンスを作成します。 |
run(self, main, **kwargs) |
main(**kwargs) を呼び出して、Horovod トレーニング ジョブを実行します。 main 関数とキーワード引数は cloudpickle を使用してシリアル化され、クラスター worker に分散されます。 |
HorovodRunner を使用して分散トレーニング プログラムを開発するための一般的なアプローチは次のとおりです。
- ノード数で初期化された
HorovodRunnerインスタンスを作成します。 - Horovod の使用法で説明されているメソッドに従って、Horovod トレーニング メソッドを定義します。import ステートメントは必ずメソッド内に追加してください。
- トレーニング メソッドを
HorovodRunnerインスタンスに渡します。
次に例を示します。
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
n 個のサブプロセスのみを使用してドライバーで HorovodRunner を実行するには、hr = HorovodRunner(np=-n) を使用します。 たとえば、ドライバー ノードに 4 つの GPU がある場合、n から 4 までを選択できます。 パラメーター np の詳細については、HorovodRunner API のドキュメントを参照してください。 サブプロセスごとに 1 つの GPU をピン留めする方法の詳細については、Horovod のユーザー ガイドを参照してください。
一般的なエラーは、TensorFlow オブジェクトが見つからないか、オブジェクトを pickle できないことです。 これは、library import ステートメントが他の実行プログラムに配布されていない場合に発生します。 この問題を回避するには、Horovod トレーニング メソッドの先頭と Horovod トレーニング メソッドで呼び出される他のユーザー定義関数内の "両方" に、すべての import ステートメント (例: import tensorflow as tf) を含めます。
Horovod Timeline を使用して Horovod トレーニングを記録する
Horovod には、Horovod Timeline と呼ばれる、アクティビティのタイムラインを記録する機能があります。
重要
Horovod Timeline は、パフォーマンスに大きな影響を与えます。 Horovod Timeline を有効にすると、Inception3 のスループットが最大 40% 低下する可能性があります。 HorovodRunner ジョブを高速化するために Horovod Timeline を使用しないでください。
トレーニングの進行中は、Horovod Timeline を表示できません。
Horovod Timeline を記録するには、HOROVOD_TIMELINE 環境変数をタイムライン ファイルを保存する場所に設定します。 Databricks は、タイムライン ファイルを簡単に取得できるように、共有ストレージ上の場所を使用することを推奨しています。 たとえば、次のように DBFS ローカルファイルの API を使用できます。
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
次に、トレーニング関数の先頭と末尾にタイムライン固有のコードを追加します。 次のノートブックの例には、トレーニングの進行状況を表示するための回避策として使用できるコード例が含まれています。
Horovod Timeline のサンプル ノートブック
タイムライン ファイルをダウンロードするには、Databricks CLI を使用した後、Chrome ブラウザーの chrome://tracing 機能を使用してそれを表示します。 次に例を示します。
開発ワークフロー
単一ノードのディープ ラーニング コードを分散トレーニングに移行する一般的な手順を以下に示します。 このセクションの「例: HorovodRunner を使用して分散ディープ ラーニングに移行する」では、これらの手順を示します。
- 1 つのノード コードを準備する: TensorFlow、Keras、または PyTorch を使用して単一ノード コードを準備してテストします。
- Horovod に移行する: Horovod の使用方法の指示に従って、Horovod でコードを移行し、ドライバーでテストします。
hvd.init()を追加して Horovod を初期化します。config.gpu_options.visible_device_listを使用して、このプロセスで使用されるようにサーバーの GPU をピン留めします。 1 つのプロセスあたり 1 つの GPU の一般的な設定では、これをローカル ランクに設定できます。 その場合、サーバー上の最初のプロセスに最初の GPU が割り当てられ、2 番目のプロセスに 2 つ目の GPU が割り当てられます。- データセットのシャードを含めます。 このデータセット演算子は、各 worker が一意のサブセットを読み取ることができるため、分散トレーニングを実行する場合に非常に便利です。
- worker の数で学習速度をスケールします。 同期分散トレーニングの有効なバッチ サイズは、worker の数によってスケーリングされます。 学習速度を上げると、バッチ サイズの増加が相殺されます。
hvd.DistributedOptimizerでオプティマイザーをラップします。 分散オプティマイザーは、勾配計算を元のオプティマイザーに委任し、allreduce または allgather を使用して勾配を平均化し、平均化された勾配を適用します。hvd.BroadcastGlobalVariablesHook(0)を追加して、初期変数の状態をランク 0 から他のすべてのプロセスにブロードキャストします。 これは、ランダムな重みでトレーニングが開始されたとき、またはチェックポイントから復元されたときに、すべての worker の一貫した初期化を確保するために必要です。 または、MonitoredTrainingSessionを使用していない場合は、グローバル変数が初期化された後にhvd.broadcast_global_variables操作を実行できます。- 他の worker によって破損されないように、worker 0 にのみチェックポイントを保存するようにコードを変更します。
- HorovodRunner に移行する: HorovodRunner は、Python 関数を呼び出して Horovod トレーニング ジョブを実行します。 メインのトレーニング プロシージャを 1 つの Python 関数にラップする必要があります。 その後、ローカル モードおよび分散モードで HorovodRunner をテストできます。
ディープ ラーニング ライブラリを更新する
TensorFlow、Keras、または PyTorch をアップグレードまたはダウングレードする場合は、新しくインストールされたライブラリに対してコンパイルされるように Horovod を再インストールする必要があります。 たとえば、TensorFlow をアップグレードする場合、Databricks は、TensorFlow のインストール手順の init スクリプトを使用し、その末尾に次の TensorFlow 固有の Horovod インストール コードを追加することを推奨しています。 PyTorch やその他のライブラリのアップグレードやダウングレードなど、さまざまな組み合わせで動作するようにするには、Horovod のインストール手順を参照してください。
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
例: HorovodRunner を使用して分散ディープ ラーニングに移行する
次の例は、MNIST データセットに基づいており、HorovodRunner を使用して単一ノードのディープ ラーニング プログラムを分散型ディープ ラーニングに移行する方法を示しています。
制限事項
- ワークスペース ファイルを操作する場合、
npが 1 より大きく設定され、ノートブックが他の相対ファイルからインポートされると、HorovodRunner は機能しません。HorovodRunnerの代わりに horovod.spark を使用することを検討してください。 WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peerのようなエラーが発生した場合、クラスターのノード間のネットワーク通信に問題があることを示します。 このエラーを解決するには、次のスニペットをトレーニング コードに追加して、プライマリ ネットワーク インターフェイスを使用します。
import os
os.environ["OMPI_MCA_btl_tcp_if_include"]="eth0"
os.environ["NCCL_SOCKET_IFNAME"]="eth0"