Azure Databricks でのレガシ MLflow Model Serving
重要
この機能はパブリック プレビュー段階にあります。
重要
- このドキュメントは廃止され、更新されない可能性があります。 このコンテンツで言及されている製品、サービス、テクノロジは、サポートされなくなりました。
- この記事のガイダンスは、レガシ MLflow Model Serving に関するものです。 Databricks では、モデル エンドポイントのデプロイとスケーラビリティを強化するために、モデル提供ワークフローを Model Serving に移行することを推奨しています。 詳細については、「モザイク AI モデルサービスを使用してモデルをデプロイする」を参照してください。
レガシ MLflow Model Serving では、モデル レジストリの機械学習モデルを、このモデル バージョンとそのステージの可用性に基づいて自動的に更新される REST エンドポイントとしてホストすることができます。 クラシック コンピューティング プレーンと呼ばれる領域内において、お客様の所有アカウントで実行される単一ノード クラスターが使用されます。 このコンピューティング プレーンには、仮想ネットワークとそれに関連するコンピューティング リソース、たとえば、ノートブックやジョブ用のクラスター、Pro および Classic SQL ウェアハウス、レガシ モデル提供エンドポイントが含まれます。
特定の登録済みモデルに対してモデルの提供を有効にした場合、Azure Databricks によってモデルの一意のクラスターが自動的に作成され、そのクラスター上にアーカイブされていないすべてのバージョンのモデルがデプロイされます。 Azure Databricks は、エラーが発生した場合はクラスターを再起動し、モデルに対するモデルの提供を無効にするときにクラスターを終了します。 モデルの提供は、モデル レジストリと自動的に同期し、新しく登録したモデル バージョンをデプロイします。 デプロイされたモデル バージョンは、標準のREST API 要求でクエリすることができます。 Azure Databricks は、標準認証を使用して、モデルに対する要求を認証します。
このサービスのプレビュー中は、Databricks では低スループットと、重要ではないアプリケーションでの使用をお勧めします。 ターゲット スループットは 200 qps で、ターゲットの可用性は 99.5% ですが、どちらも保証されていません。 さらに、要求ごとに 16 MB のペイロード サイズ制限があります。
各モデル バージョンは、MLflow モデル デプロイを使用してデプロイされ、その依存関係で指定された Conda 環境で実行されます。
Note
- アクティブなモデル バージョンが存在しない場合でも、提供が有効になっている限り、クラスターは維持されます。 サービング クラスターを終了するには、登録済みモデルのモデルの提供を無効にします。
- クラスターはすべての目的のクラスターと見なされ、すべての目的のワークロードの価格が適用されます。
- グローバル初期化スクリプトは、モデル提供クラスターでは実行されません。
重要
Anaconda Inc. は、anaconda.org チャネルのサービス利用規約を更新しました。 Anaconda のパッケージ化と配布に依存している場合は、新しいサービス利用規約に基づいて商用ライセンスが必要になることがあります。 詳細については、「Anaconda Commercial Edition の FAQ」を参照してください。 Anaconda チャネルの使用には、同社のサービス使用条件が適用されます。
v1.18 (Databricks Runtime 8.3 ML 以前) より前にログに記録された MLflow モデルは既定で、conda defaults チャネル (https://repo.anaconda.com/pkgs/) を依存関係としてログに記録されていました。 このライセンスの変更により、Databricks は MLflow v1.18 以降を使用してログに記録されたモデルの defaults チャネルの使用を停止しました。 ログに記録された既定のチャネルは現在、conda-forge であり、これはコミュニティで管理されている https://conda-forge.org/ を指しています。
モデルの conda 環境から defaults チャネルを除外 せずに MLflow v1.18 より前にモデルをログに記録した場合、そのモデルは意図していない defaults チャネルに依存している可能性があります。
モデルにこの依存関係があるかどうかを手動で確認するには、ログに記録されたモデルと共にパッケージ化された channel ファイル内での conda.yaml 値を調べることができます。 たとえば、conda.yaml チャネルの依存関係を持つモデルの defaults は次のようになります。
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricks では、Anaconda リポジトリを使用してモデルを操作することが、Anaconda との関係の下で許可されているかどうか判断できないため、Databricks のお客様に変更を強制していません。 Databricks の使用を通じた Anaconda.com リポジトリの使用が、Anaconda の条件下で許可されている場合は、何も行う必要はありません。
モデルの環境で使用されるチャネルを変更する場合は、新しい conda.yaml でモデル レジストリにモデルを再登録できます。 これを行うには、conda_env の log_model() パラメーターでチャネルを指定します。
log_model() API の詳細については、使用しているモデル フレーバー (scikit-learn の log_model など) の MLflow ドキュメントを参照してください。
conda.yaml ファイルの詳細については、MLflow のドキュメントを参照してください。
必要条件
- レガシ MLflow Model Serving は、Python MLflow モデルで使用できます。 conda 環境では、すべてのモデルの依存関係を宣言する必要があります。 ログ モデルの依存関係に関する記事を参照してください。
- モデルの提供を有効にするには、クラスターの作成アクセス許可が必要です。
モデル レジストリからのモデルの提供
モデルの提供は、モデル レジストリの Azure Databricks で使用できます。
モデルの提供を有効または無効にする
その [登録済みのモデル] ページからモデルの提供を有効にします。
[提供] タブをクリックします。モデルの提供がまだ有効になっていない場合は、[提供を有効にする] ボタンが表示されます。
![[提供を有効にする] ボタン](../../_static/images/mlflow/enable-serving.png)
[提供の有効化] をクリックします。 [提供] タブが表示され、[状態] が [保留中] と表示されます。 数分後に [状態] が [準備完了] に変わります。
モデルの提供を無効にするには、[停止] をクリックします。
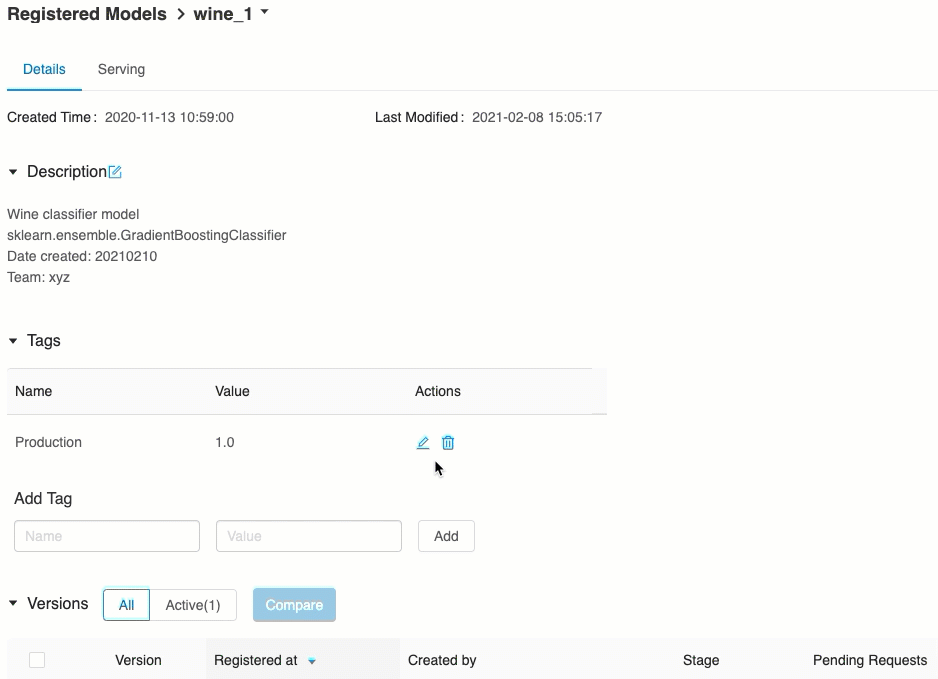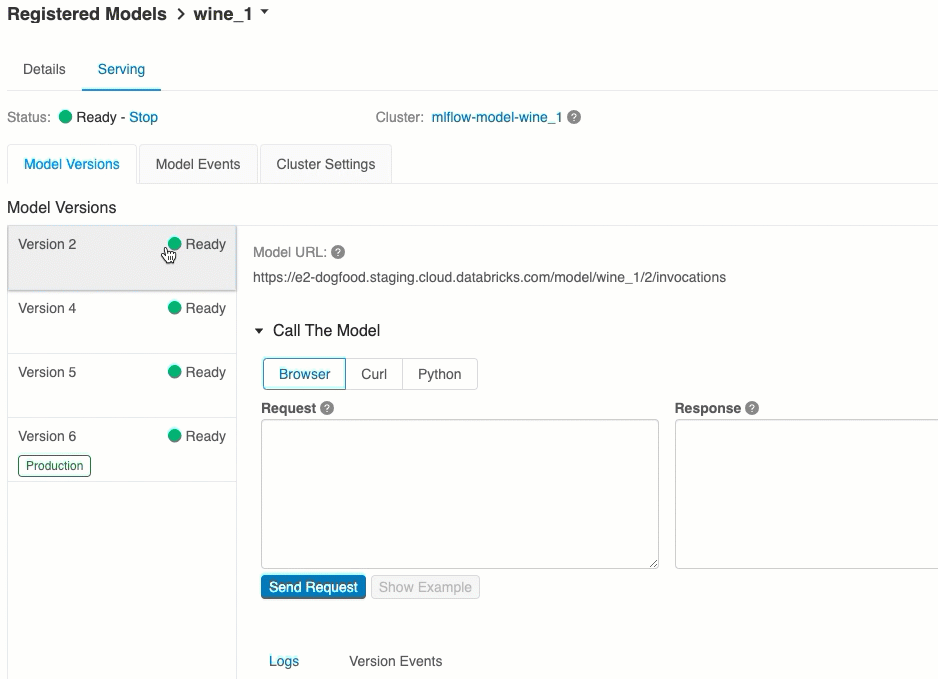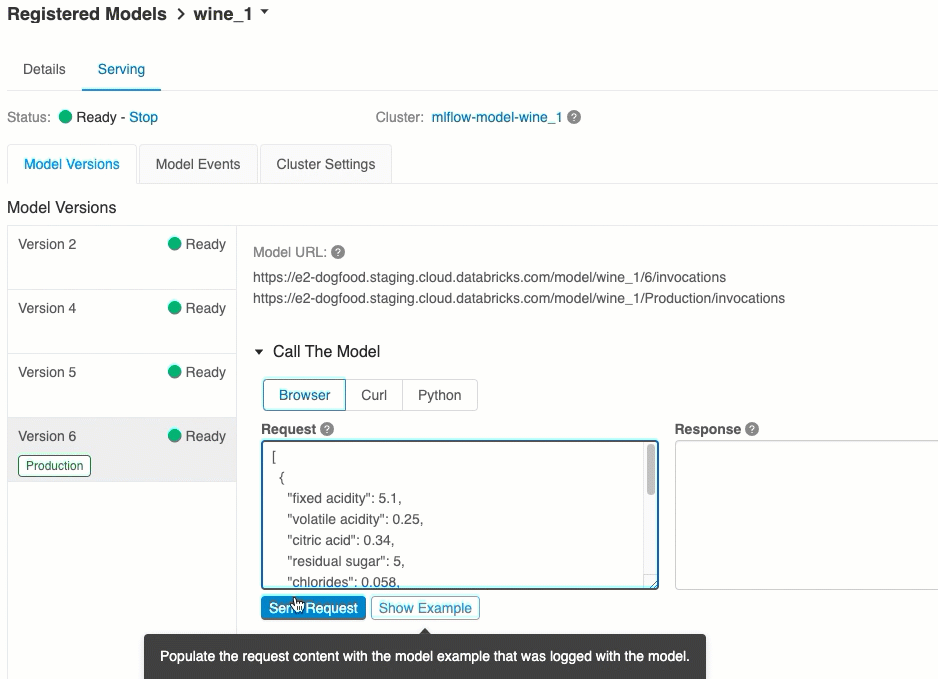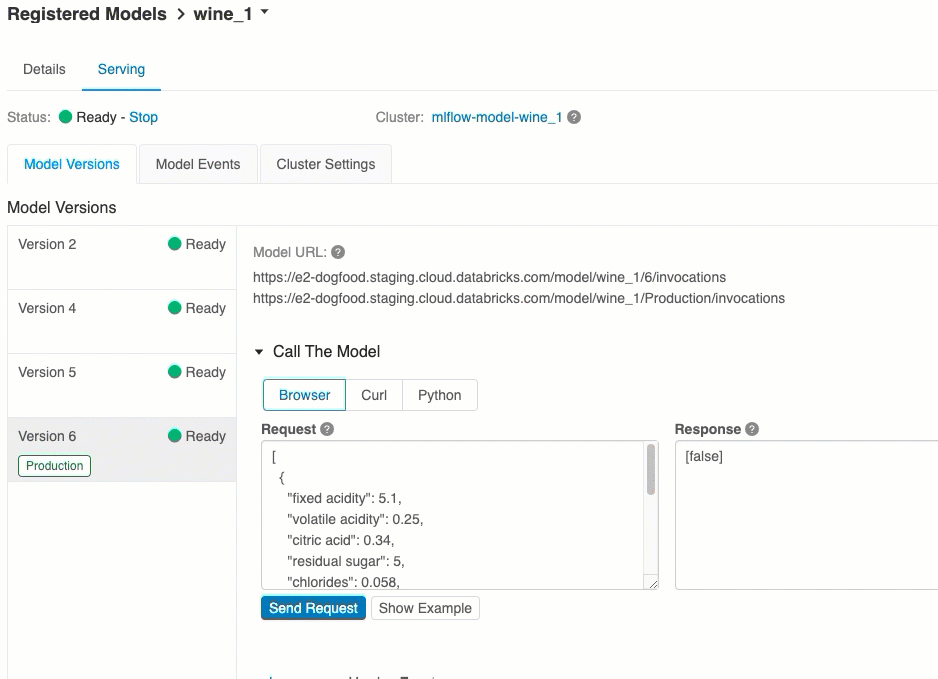
モデルの提供を検証する
[提供] タブから、提供されるモデルに要求を送信し、応答を表示できます。
モデル バージョンの URI
デプロイされた各モデル バージョンには、1 つ以上の一意の URI が割り当てられます。 少なくとも、各モデル バージョンには、次のように構築された URI が割り当てられます。
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
たとえば、iris-classifier として登録済みのモデルのバージョン 1 を呼び出す場合は、次の URI を使用します。
https://<databricks-instance>/model/iris-classifier/1/invocations
モデル バージョンをステージ別に呼び出すこともできます。 たとえば、バージョン 1 が運用環境のステージにある場合は、次の URI を使用してスコア付けすることもできます。
https://<databricks-instance>/model/iris-classifier/Production/invocations
使用可能なモデルの URI の一覧が、[提供] ページの [モデル バージョン] タブの上部に表示されます。
提供されるバージョンを管理する
アクティブな (アーカイブされていない) モデル バージョンはすべてデプロイされ、URI を使用してクエリを実行できます。 Azure Databricks は、登録時に新しいモデル バージョンを自動的にデプロイし、アーカイブ時に古いバージョンを自動的に削除します。
Note
登録済みモデルのデプロイされたバージョンはすべて、同じクラスターを共有します。
モデルのアクセス権を管理する
モデルのアクセス権は、モデル レジストリから継承されます。 提供機能を有効または無効にする場合は、登録済みモデルに対する "管理" アクセス許可が必要です。 読み取り権限を持つすべてのユーザーは、デプロイされている任意のバージョンをスコア付けできます。
デプロイされたモデルのバージョンをスコア付けする
デプロイされたモデルをスコア付けするには、UI を使用するか、モデル URI に REST API 要求を送信します。
UI を使用したスコア付け
これは、モデルをテストする最も簡単で最速の方法です。 モデル入力データを JSON 形式で挿入し、[要求の送信] をクリックします。 モデルが入力例でログに記録されている場合は (上の図に示すように)、[例の読み込み] をクリックして入力例を読み込みます。
REST API 要求を使用してスコア付けする
標準の Databricks 認証を使用して、REST API を介してスコアリングの要求を送信できます。 次の例は、MLflow 1.x. で個人用アクセス トークンを使用した認証を示しています。
Note
セキュリティのベスト プラクティスとして、自動化ツール、システム、スクリプト、アプリを使用して認証する場合、Databricks では、ワークスペース ユーザーではなくサービス プリンシパルに属する個人用アクセス トークンを使用することを推奨しています。 サービス プリンシパルのトークンを作成するには、「サービス プリンシパルのトークンを管理する」をご覧ください。
以下の例では、MODEL_VERSION_URI (https://<databricks-instance>/model/iris-classifier/Production/invocations は <databricks-instance>) のような と、DATABRICKS_API_TOKEN という名前の Databricks REST API トークンを指定して、提供されるモデルのクエリを実行する方法を示しています。
次の例は、MLflow 1.x で作成されたモデルのスコアリング形式を反映しています。 MLflow 2.0 を使用する場合は、要求ペイロード形式を更新する必要があります。
Bash
データフレーム入力を受け入れるモデルに対してクエリを実行するスニペット。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
テンソル入力を受け入れるモデルに対してクエリを実行するスニペット。 テンソル入力は、「TensorFlow Serving の API ドキュメント」の説明に従って書式設定する必要があります。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
PowerBI
次の手順を使用して、Power BI Desktop でデータセットをスコア付けできます。
スコア付けするデータセットを開きます。
[データの変換] に移動します。
左側のパネルを右クリックし、[新しいクエリの作成] を選択します。
[ビュー > 詳細エディター] へ移動します。
適切な
DATABRICKS_API_TOKENとMODEL_VERSION_URIを入力した後、クエリ本文を以下のコード スニペットに置き換えます。(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPrediction希望するモデル名でクエリに名前を付けます。
データセットの詳細クエリ エディターを開き、モデル関数を適用します。
提供されるモデルを監視する
[提供] ページには、サービング クラスターの状態インジケーターと個々のモデル バージョンが表示されます。
- サービング クラスターの状態を検査するには、[モデル イベント] タブを使用します。このタブには、このモデルのすべてのサービング イベントの一覧が表示されます。
- 1 つのモデル バージョンの状態を検査するには、[モデル バージョン] タブをクリックし、スクロールして [ログ] タブまたは [バージョン イベント] タブを表示します。
![[提供] タブ](../../_static/images/mlflow/serving-tab.png)
サービング クラスターをカスタマイズする
サービング クラスターをカスタマイズするには、[提供] タブの [クラスター設定] タブを使用します。
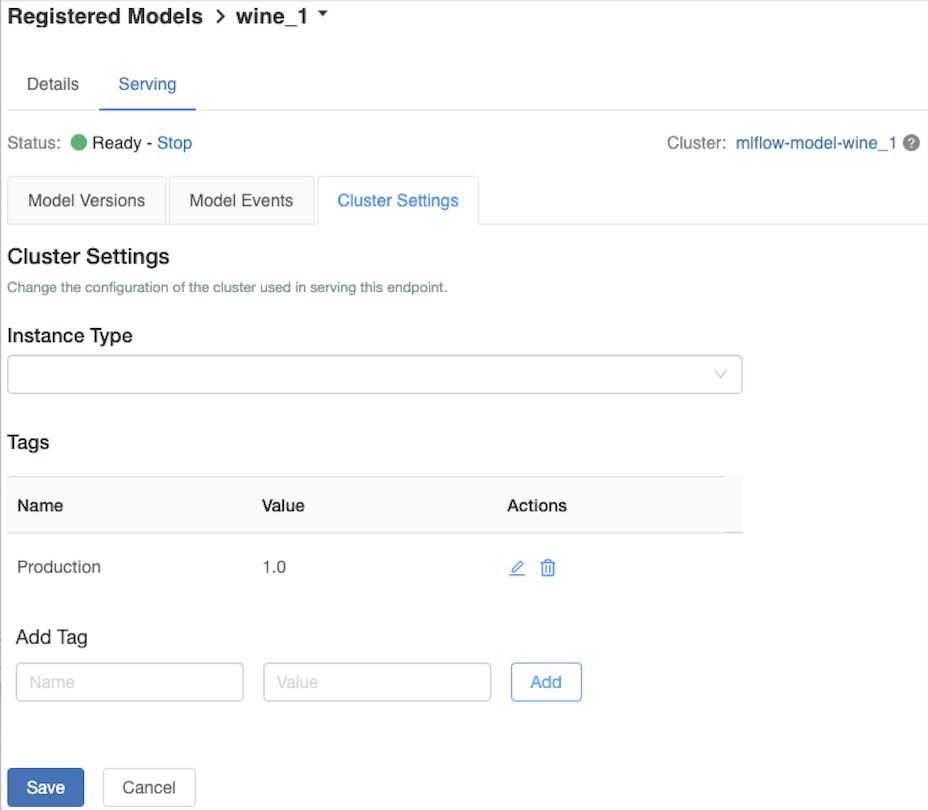
- サービング クラスターのメモリ サイズとコア数を変更するには、[インスタンスの種類] ドロップダウン メニューを使用して目的のクラスター構成を選択します。 [保存] をクリックすると、既存のクラスターが終了し、指定した設定で新しいクラスターが作成されます。
- タグを追加するには、[タグの追加] フィールドに名前と値を入力し、[追加] をクリックします。
- 既存のタグを編集または削除するには、[タグ] テーブルの [アクション] 列にあるアイコンのいずれかをクリックします。
Feature Store の統合
レガシ モデル提供により、公開されているオンライン ストアの特徴値を自動的に検索できます。
$ aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
既知のエラー
ResolvePackageNotFound: pyspark=3.1.0
このエラーは、モデルが pyspark に依存し、Databricks Runtime 8.x を使用してログに記録されると発生する可能性があります。
このエラーが表示される場合は、conda_envを使用してモデルをログに記録するときに バージョンを明示的に指定します。
Unrecognized content type parameters: format
このエラーは、新しい MLflow 2.0 スコアリング プロトコル形式の結果として発生することがあります。 このエラーが表示されている場合は、古いスコアリング要求形式を使用している可能性があります。 このエラーを解決するため、以下を実行できます。
スコアリング要求の形式を最新のプロトコルに更新します。
Note
以下の例は、MLflow 2.0 で導入されたスコアリング形式を反映しています。 MLflow 1.x を使用する場合は、
log_model()API 呼び出しを変更し、必要な MLflow バージョンの依存関係をextra_pip_requirementsパラメーターに含めることができます。 そうすれば、適切なスコアリング形式が確実に使用されます。mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
pandas データフレーム入力を受け入れるモデルに対してクエリを実行します。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'テンソル入力を受け入れるモデルに対してクエリを実行します。 テンソル入力は、「TensorFlow Serving の API ドキュメント」の説明に従って書式設定する必要があります。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)PowerBI
次の手順を使用して、Power BI Desktop でデータセットをスコア付けできます。
スコア付けするデータセットを開きます。
[データの変換] に移動します。
左側のパネルを右クリックし、[新しいクエリの作成] を選択します。
[ビュー > 詳細エディター] へ移動します。
適切な
DATABRICKS_API_TOKENとMODEL_VERSION_URIを入力した後、クエリ本文を以下のコード スニペットに置き換えます。(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPrediction希望するモデル名でクエリに名前を付けます。
データセットの詳細クエリ エディターを開き、モデル関数を適用します。
スコアリング要求で
mlflow.pyfunc.spark_udf()などの MLflow クライアントが使用されている場合は、MLflow クライアントをバージョン 2.0 以降にアップグレードして最新の形式を使用します。 更新された MLflow 2.0 での MLflow モデル スコアリング プロトコルの詳細を確認してください。
サーバーで受け入れられる入力データ形式 (pandas の分割指向形式など) の詳細については、MLflow のドキュメントを参照してください。