Azure Stack Edge Pro で GPU 共有を使用する IoT Edge ワークロードをデプロイする
この記事では、コンテナー化されたワークロードで Azure Stack Edge Pro GPU デバイスの GPU を共有する方法について説明します。 この手法では、マルチプロセス サービス (MPS) を有効にし、IoT Edge デプロイを使用して GPU ワークロードを指定する必要があります。
前提条件
開始する前に次の点を確認します。
アクティブ化され、コンピューティングが構成されている Azure Stack Edge Pro GPU デバイスにアクセスできること。 Kubernetes API エンドポイントがあり、デバイスにアクセスするクライアント上の
hostsファイルにこのエンドポイントを追加済みであること。サポートされているオペレーティング システムでクライアント システムにアクセスしていること。 Windows クライアントを使用している場合、デバイスにアクセスするには、システムで PowerShell 5.0 以降が実行されている必要があります。
ローカル システムに次のデプロイ
jsonを保存すること。 このファイルの情報を使用して、IoT Edge デプロイを実行します。 この展開は、NVIDIA で一般公開されている単純な CUDA コンテナーに基づいています。{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
GPU ドライバーと CUDA のバージョンを確認する
最初の手順では、デバイスで必要な GPU ドライバーと CUDA のバージョンが実行されていることを確認します。
デバイスの PowerShell インターフェイスに接続します。
次のコマンドを実行します。
Get-HcsGpuNvidiaSmiNVIDIA smi 出力から、デバイス上の GPU バージョンと CUDA バージョンをメモしておきます。 Azure Stack Edge 2102 ソフトウェアを実行している場合、このバージョンは次のドライバー バージョンに対応します。
- GPU ドライバー バージョン: 460.32.03
- CUDA バージョン: 11.2
出力例を次に示します。
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>このセッションは開いたままにしておいてください。記事全体を通してこれを使用して NVIDIA smi 出力を表示します。
コンテキスト共有なしでデプロイする
ここで、マルチプロセス サービスが実行されておらず、コンテキスト共有がない場合に、アプリケーションをデバイスにデプロイできます。 Azure portal を使用して、ご利用のデバイスに存在する iotedge 名前空間にデプロイします。
IoT Edge 名前空間にユーザーを作成する
まず、iotedge 名前空間に接続するユーザーを作成します。 IoT Edge モジュールは、iotedge 名前空間にデプロイされます。 詳細については、デバイス上の Kubernetes 名前空間に関する記事を参照してください。
ユーザーを作成し、iotedge 名前空間へのアクセス権をユーザーに付与するには、次の手順に従います。
デバイスの PowerShell インターフェイスに接続します。
iotedge名前空間に新しいユーザーを作成します。 次のコマンドを実行します。New-HcsKubernetesUser -UserName <user name>出力例を次に示します。
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=プレーン テキストで表示される出力をコピーします。 その出力を、ローカル コンピューター上のユーザー プロファイルの
.kubeフォルダー (C:\Users\<username>\.kubeなど) に config ファイル (拡張子なし) として保存します。作成したユーザーに
iotedge名前空間へのアクセス権を付与します。 次のコマンドを実行します。Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>出力例を次に示します。
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
詳細な手順については、「Azure Stack Edge Pro GPU デバイスで kubectl を使用して Kubernetes クラスターに接続して管理する」を参照してください。
ポータルを使用してモジュールをデプロイする
Azure portal を使用して IoT Edge モジュールをデプロイします。 N 体シミュレーションを実行する、一般公開されている NVIDIA CUDA サンプル モジュールを展開します。
デバイスで IoT Edge サービスが実行されていることを確認します。

右ペインで [IoT Edge] タイルを選択します。 [IoT Edge] > [プロパティ] に移動します。 右ペインで、デバイスに関連付けられている IoT Hub リソースを選択します。
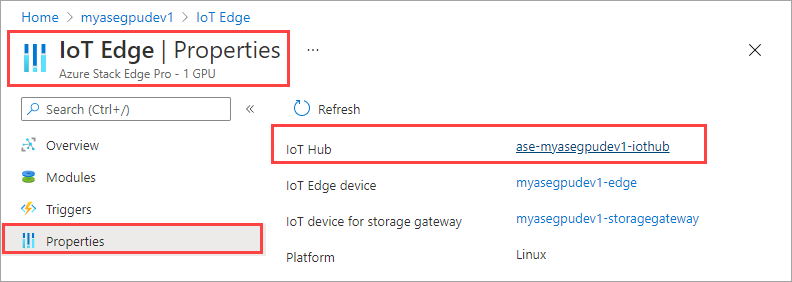
IoT Hub リソース内で、[デバイスの自動管理] > [IoT Edge] に移動します。 右ペインで、ご利用のデバイスに関連付けられている IoT Edge デバイスを選択します。
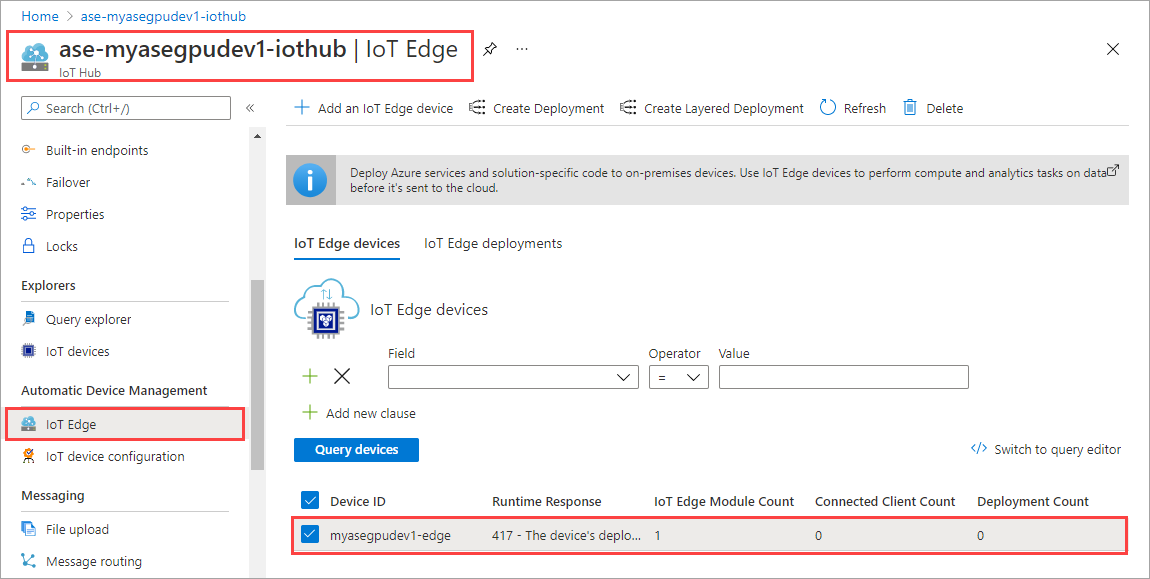
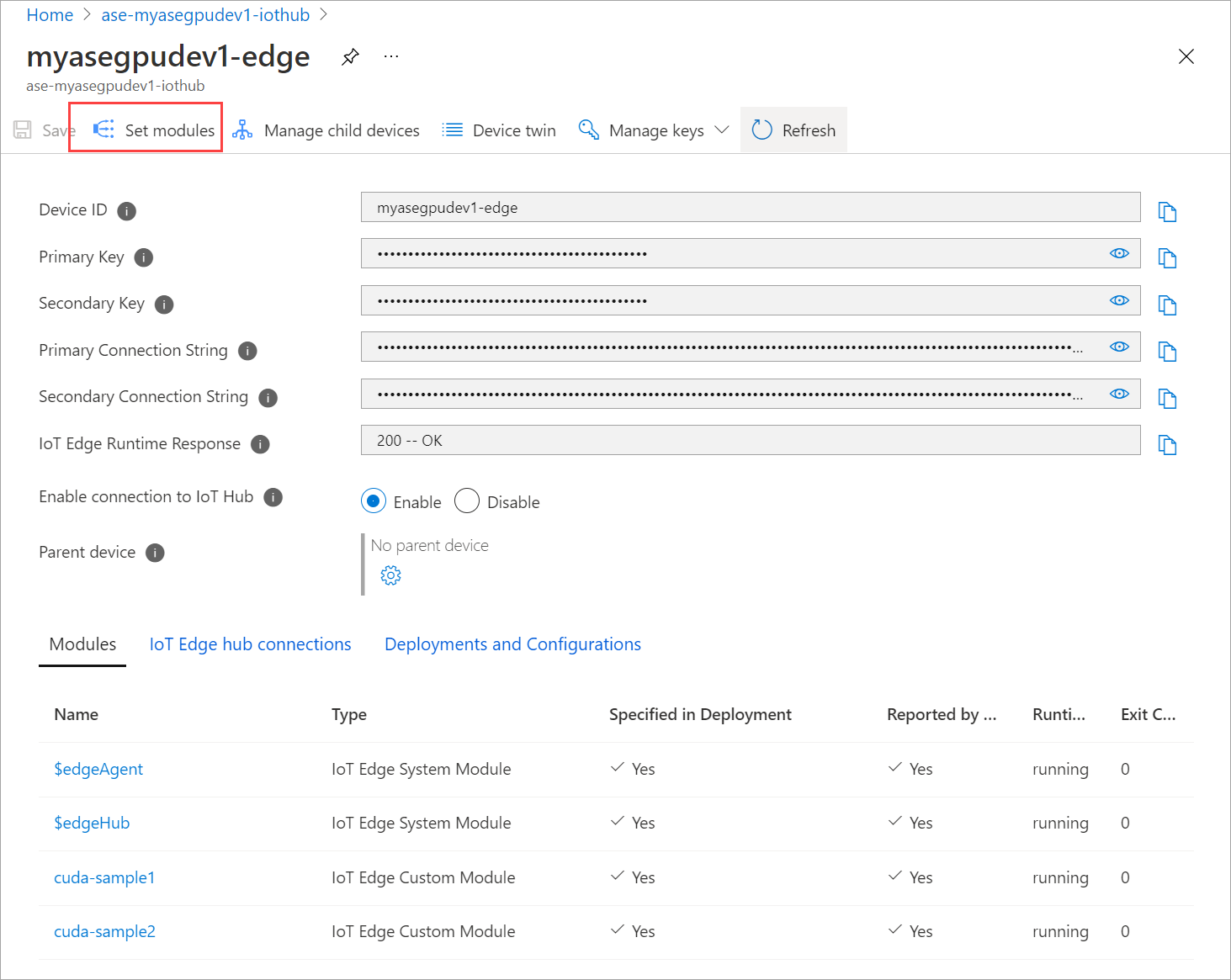
[Set modules](モジュールの設定) を選びます。
![[モジュールの設定] に移動します。](media/azure-stack-edge-gpu-deploy-iot-edge-gpu-sharing/gpu-sharing-deploy-4.png)
[+ 追加] > [+ IoT Edge モジュール] を選択します。
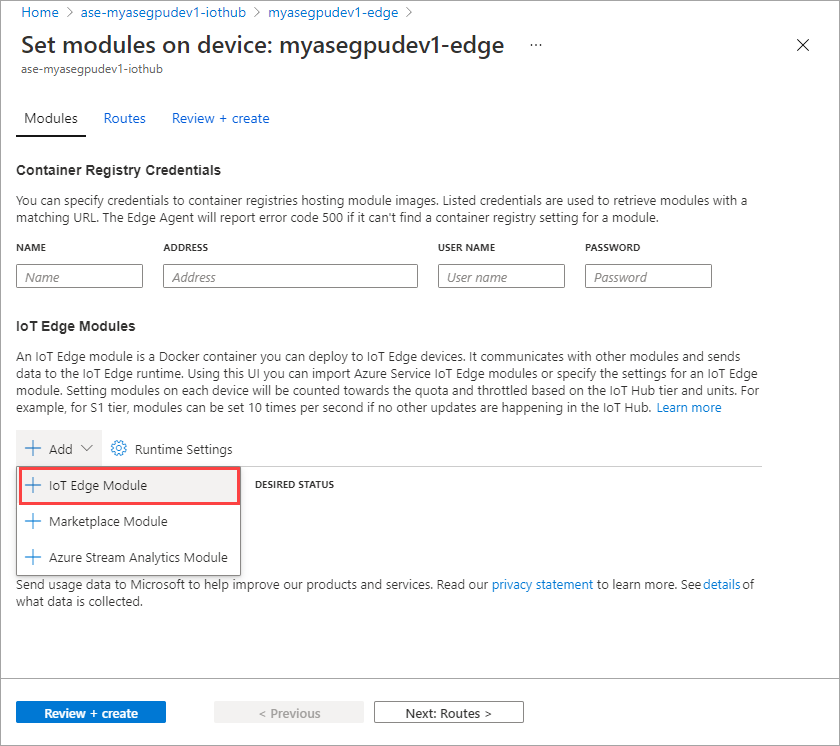
[モジュールの設定] タブで、[IoT Edge モジュール名] と [イメージのURI] を指定します。 [Image Pull Policy]\(イメージ プル ポリシー\) を [On create]\(作成時\)に設定します。
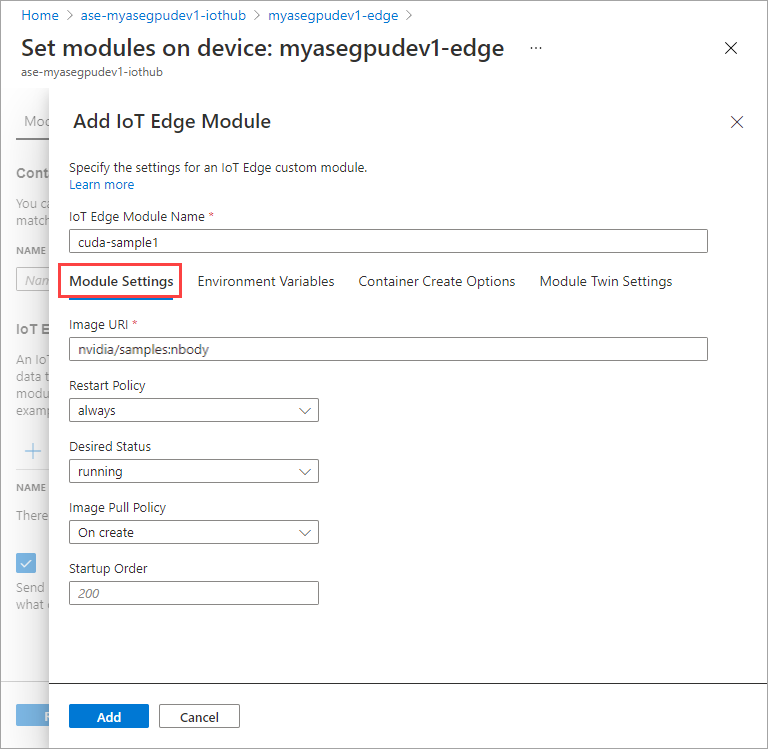
[環境変数] タブで、NVIDIA_VISIBLE_DEVICES を 0 として指定します。
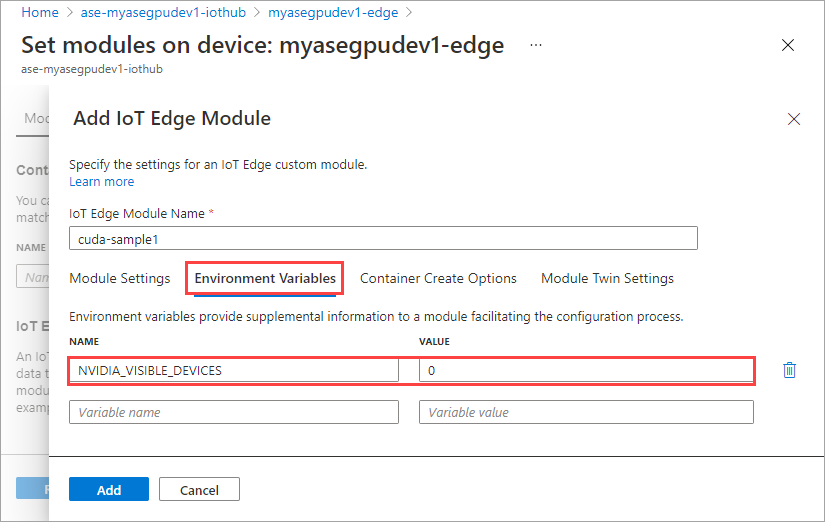
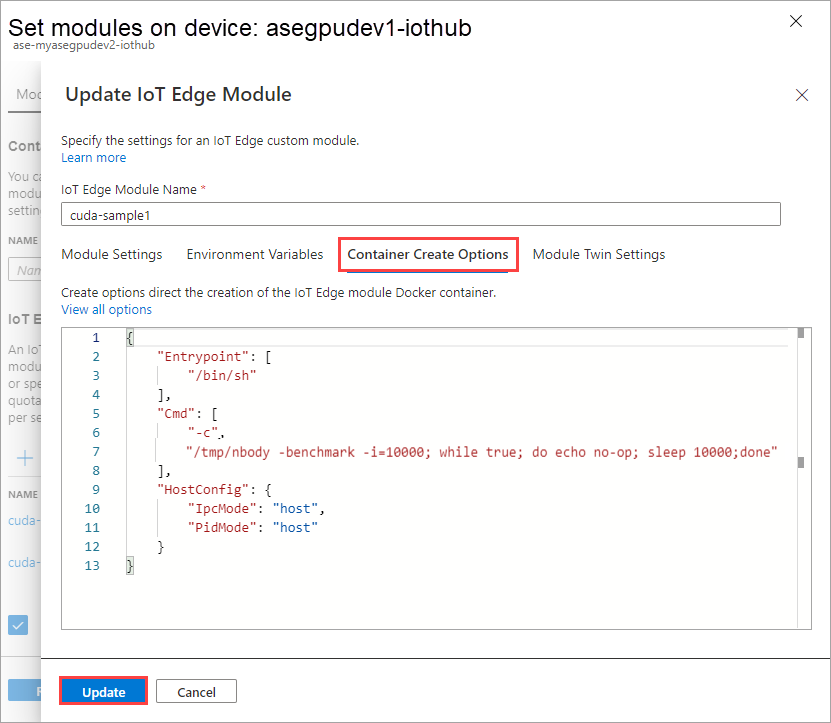
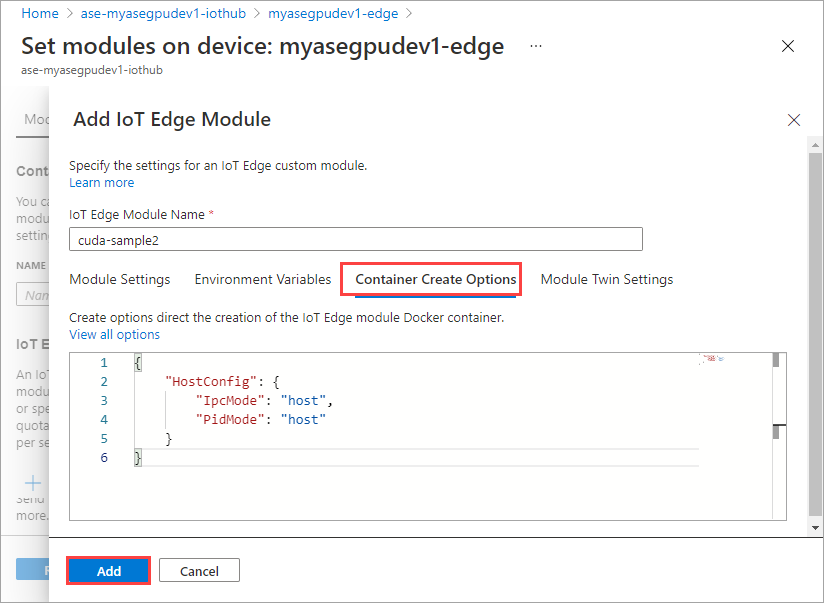
[コンテナーの作成オプション] タブで、次のオプションを指定します。
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }オプションは次のように表示されます。
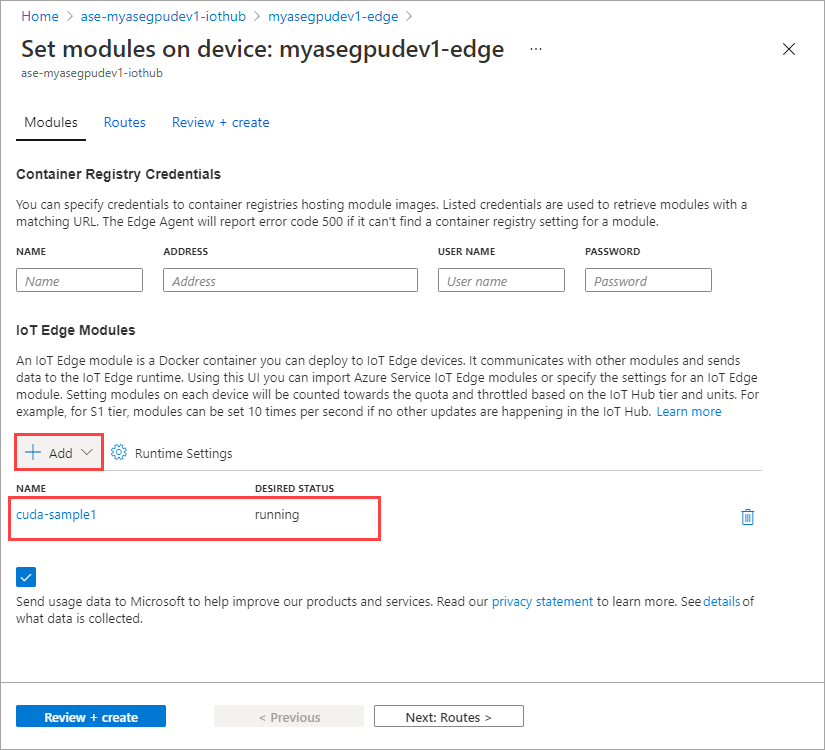
[追加] を選択します。
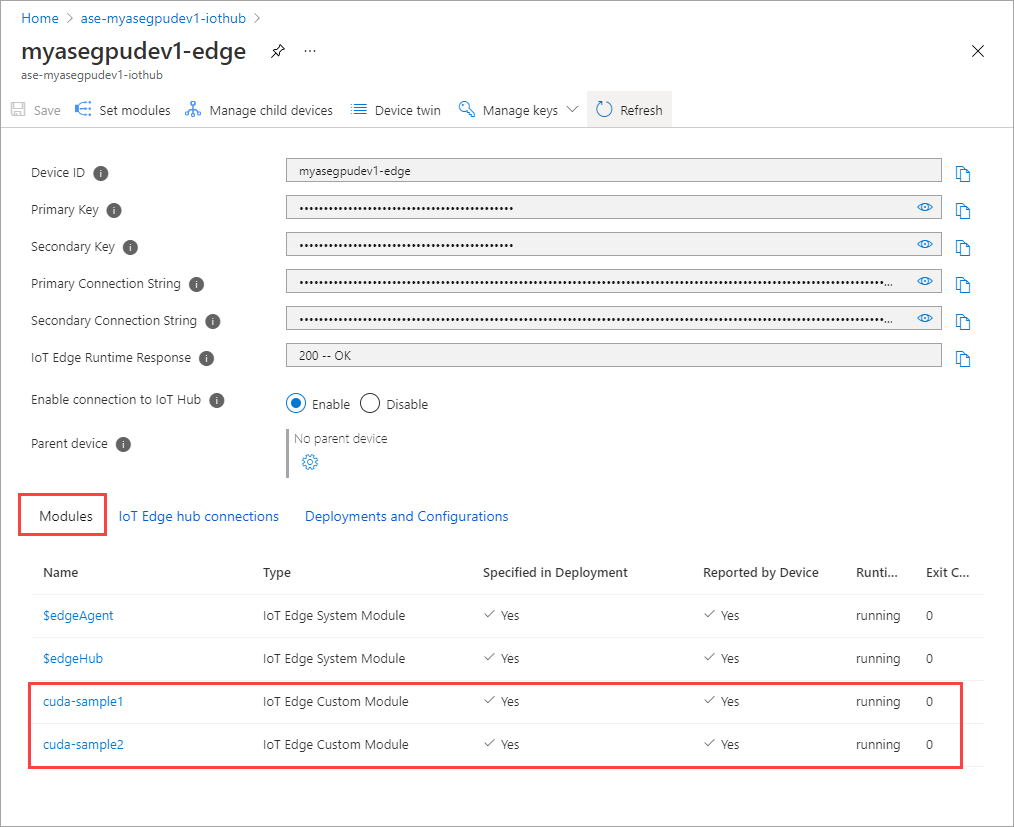
追加したモジュールは [実行中] と表示されます。
最初のモジュールの追加時に行ったすべての手順を繰り返して、モジュールを追加します。 この例では、モジュールの名前を
cuda-sample2と指定します。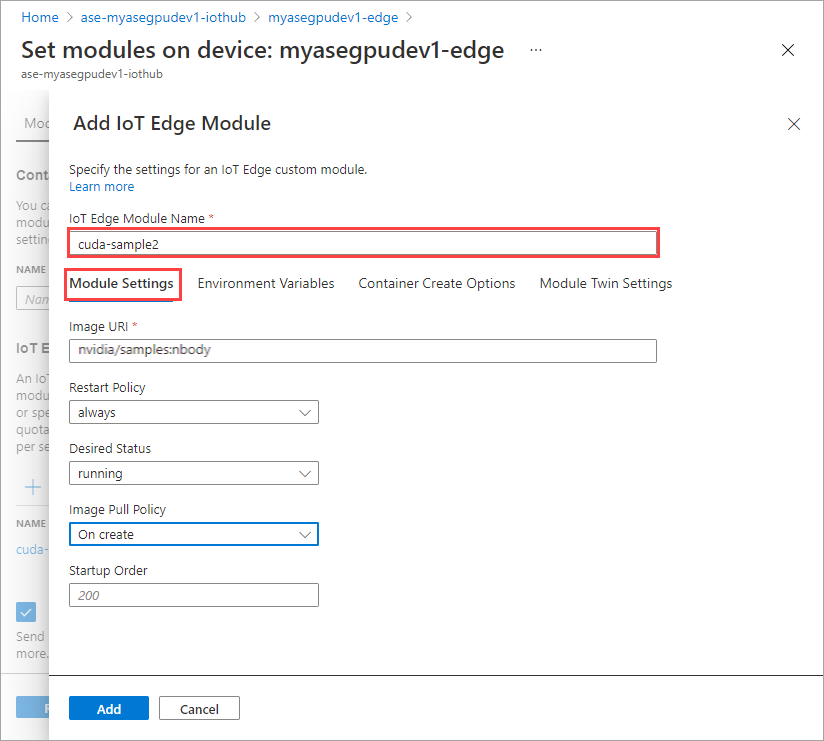
両方のモジュールが同じ GPU を共有するので、同じ環境変数を使用します。
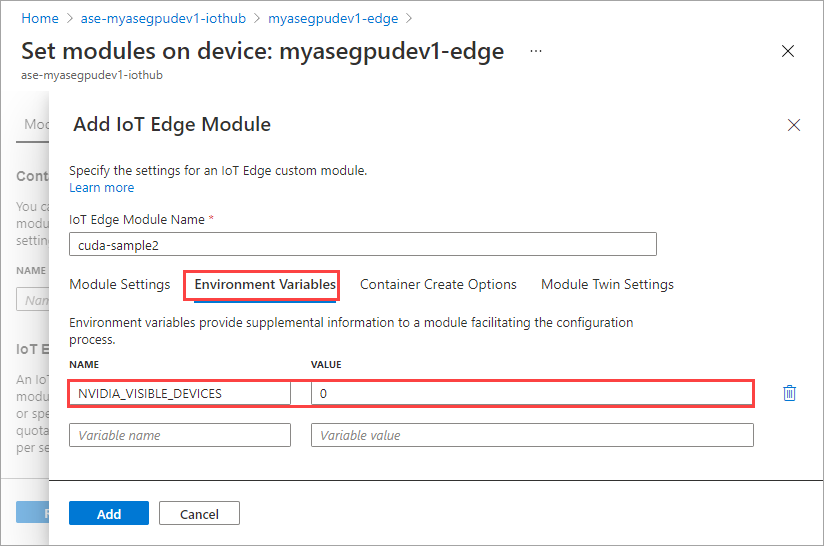
最初のモジュールに対して指定したものと同じコンテナーの作成オプションを使用し、[追加] を選択します。
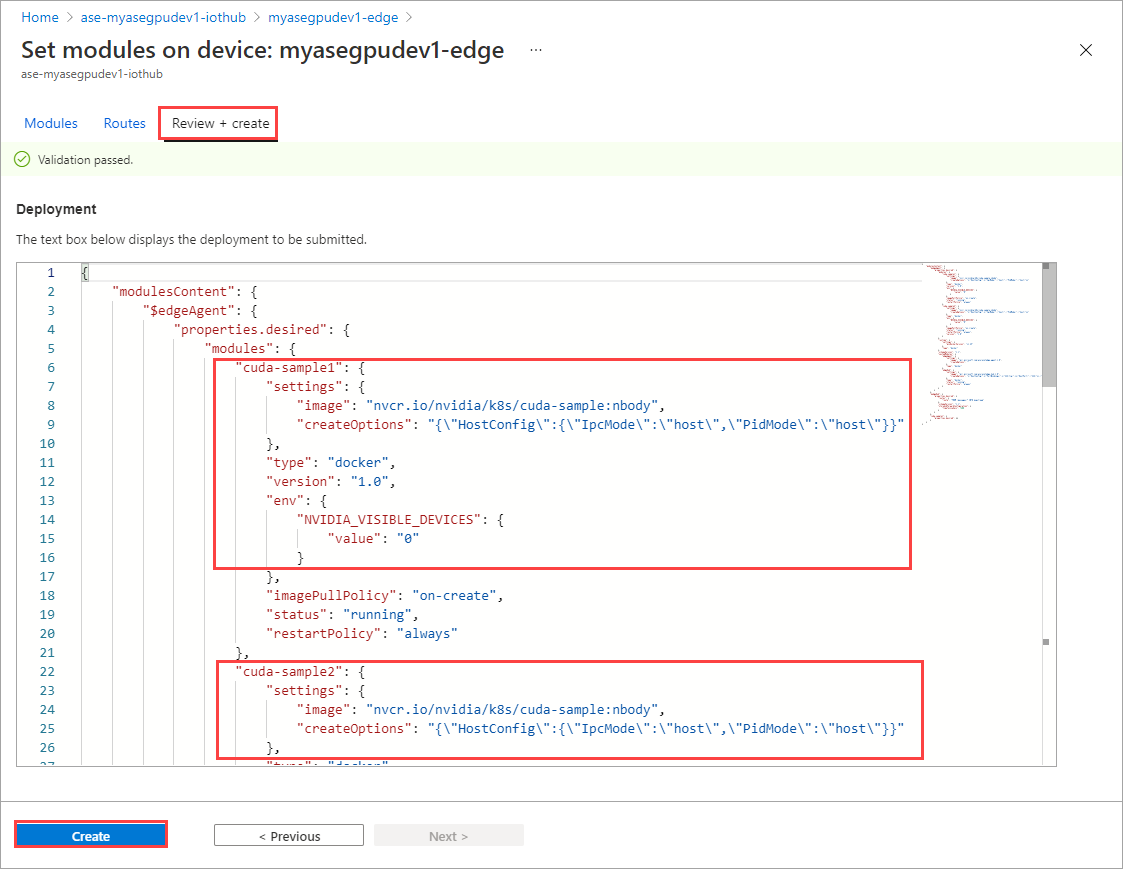
[モジュールの設定] ページで [確認および作成] を選択し、[作成] を選択します。
これで、両方のモジュールの [ランタイムの状態] が [実行中] と表示されます。
ワークロードのデプロイを監視する
新しい PowerShell セッションを開きます。
iotedge名前空間で実行されているポッドの一覧を表示します。 次のコマンドを実行します。kubectl get pods -n iotedge出力例を次に示します。
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>2 つのポッド (
cuda-sample1-97c494d7f-lnmnsとcuda-sample2-d9f6c4688-2rld9) がデバイスで実行されています。両方のコンテナーで N 体シミュレーションが実行されている間に、NVIDIA smi 出力の GPU 使用率を確認します。 デバイスの PowerShell インターフェイスにアクセスし、
Get-HcsGpuNvidiaSmiを実行します。両方のコンテナーで N 体シミュレーションが実行されているときの出力例を次に示します。
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>ご覧のように、GPU 0 で 2 つのコンテナーが N 体シミュレーションを行っている状態で実行されています。 また、対応するメモリ使用量を表示することもできます。
シミュレーションが完了すると、NVIDIA smi 出力に、デバイスで実行されているプロセスがないことが示されます。
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>N 体シミュレーションが完了したら、ログを表示して、デプロイの詳細と、シミュレーションの完了にかかった時間を把握します。
最初のコンテナーからの出力例を次に示します。
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>2 つ目のコンテナーからの出力例を次に示します。
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>モジュールのデプロイを停止します。 デバイスの IoT Hub リソースで次のようにします。
[Automatic Device Deployment]\(デバイスの自動デプロイ\) > [IoT Edge] に移動します。 デバイスに対応する IoT Edge デバイスを選択します。
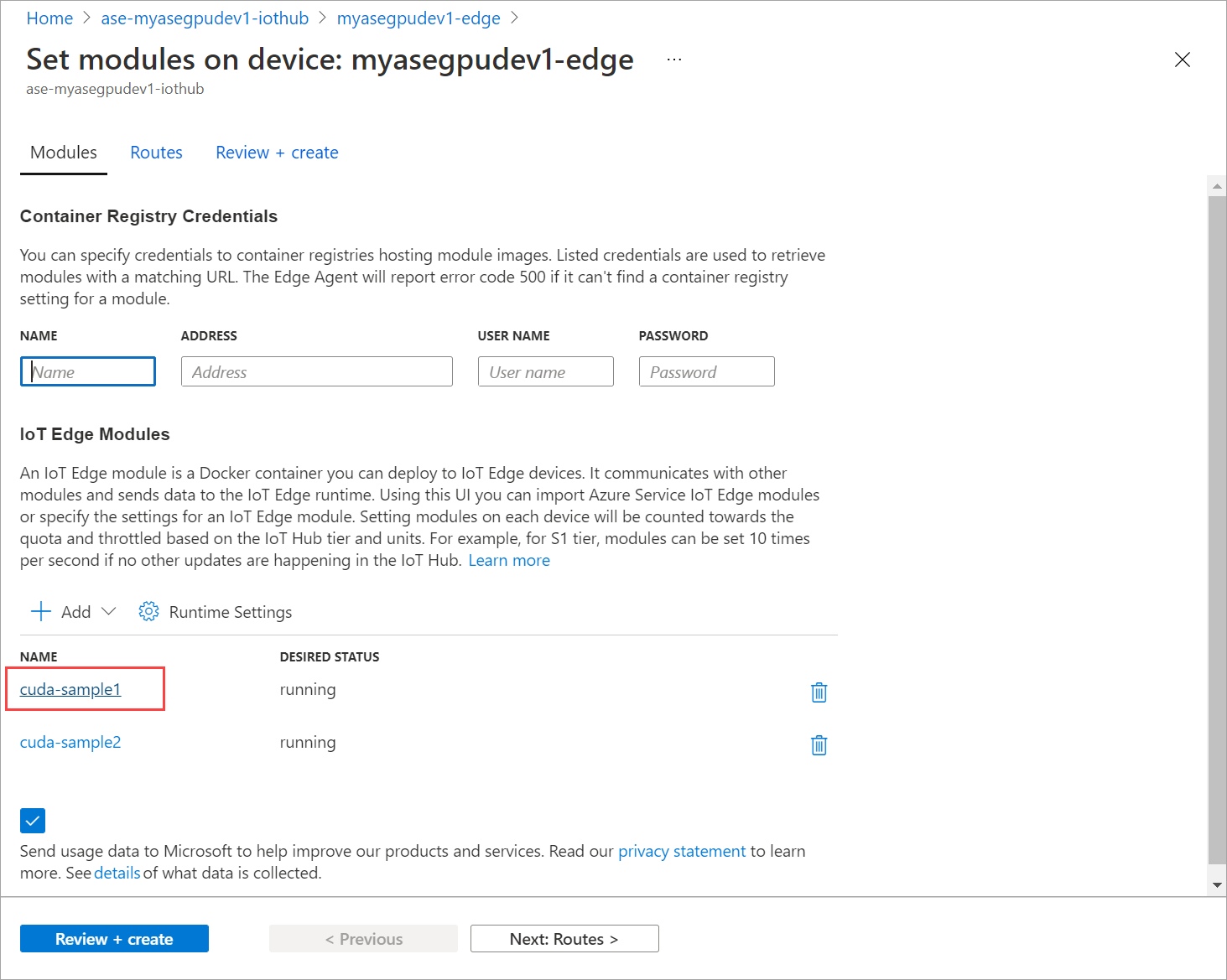
[モジュールの設定] に移動し、モジュールを選択します。
[モジュール] タブで、モジュールを選択します。
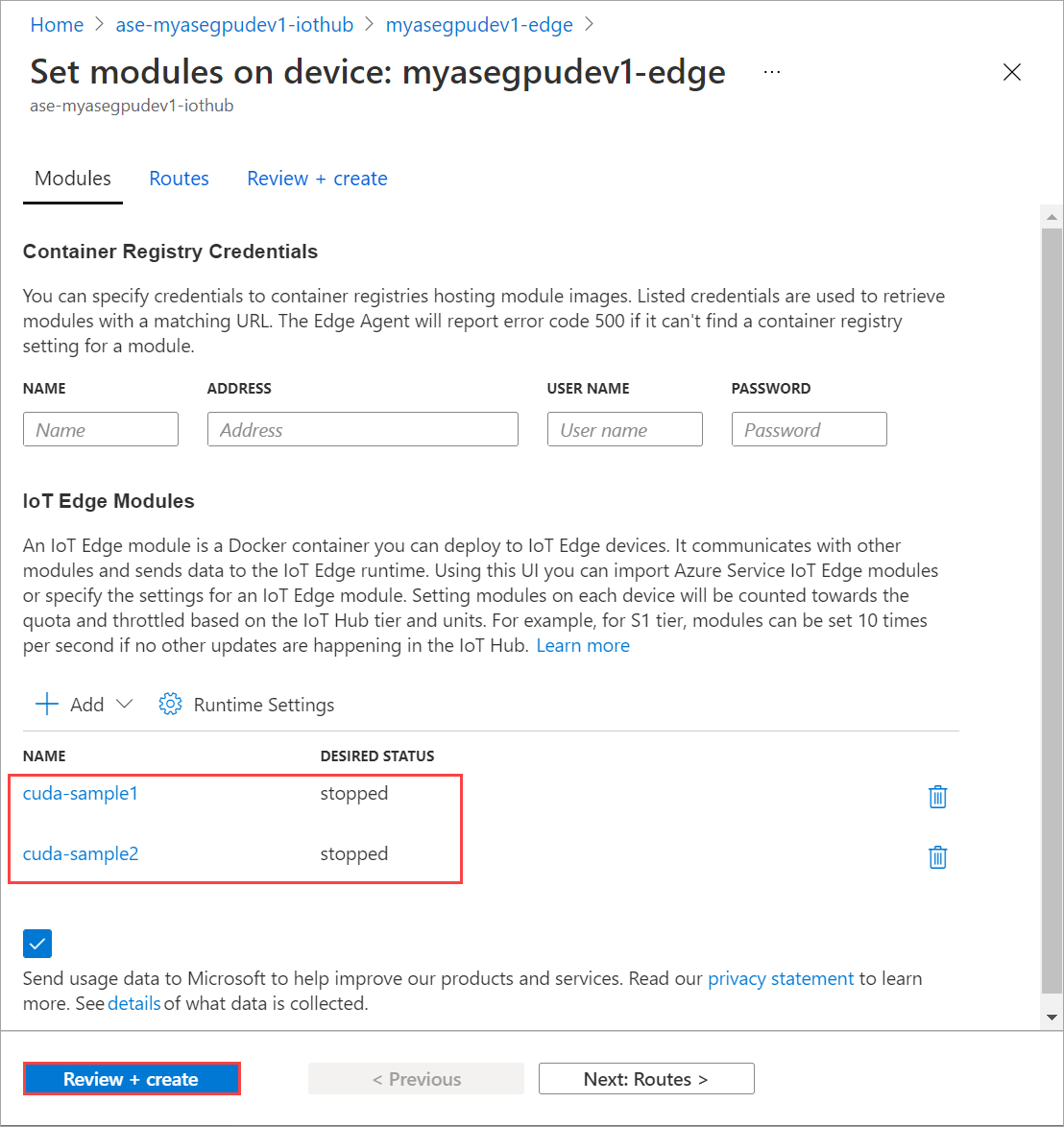
[モジュールの設定] タブで、[必要な状態] を [停止] に設定します。 [更新] を選択します。

手順を繰り返して、デバイスにデプロイされている 2 つ目のモジュールを停止します。 [確認および作成] を選択し、次に [作成] を選択します。 これにより、デプロイが更新されます。
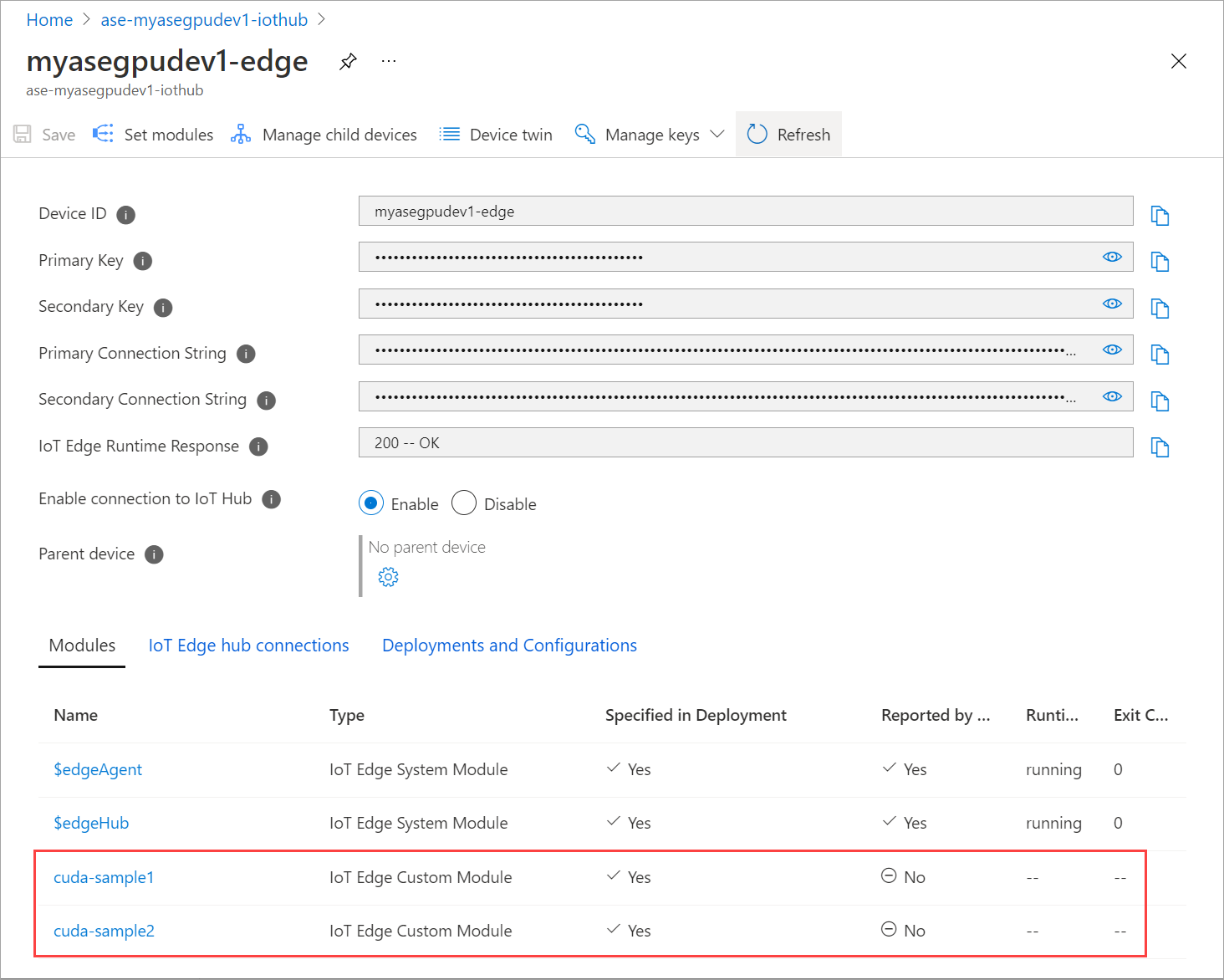
[モジュールの設定] ページを複数回更新します。 モジュールの [ランタイムの状態] が [停止] と表示されるまで行います。
コンテキスト共有ありでデプロイする
ここで、デバイスで MPS が実行されている場合に、2 つの CUDA コンテナーに N 体シミュレーションをデプロイできます。 まず、デバイスで MPS を有効にします。
デバイスの PowerShell インターフェイスに接続します。
デバイスで MPS を有効にするには、
Start-HcsGpuMPSコマンドを実行します。[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>デバイスの PowerShell インターフェイスから NVIDIA smi 出力を取得します。 デバイスで
nvidia-cuda-mps-serverプロセス (MPS サービス) が実行されていることが確認できます。出力例を次に示します。
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi以前に停止したモジュールをデプロイします。 [モジュールの設定] を使用して、[必要な状態] を [実行中] に設定します。
出力例を次に示します。
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>デバイスにモジュールがデプロイされ、実行されていることが確認できます。
モジュールがデプロイされると、両方のコンテナーで N 体シミュレーションの実行も開始されます。 最初のコンテナーでシミュレーションが完了したときの出力例を次に示します。
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>2 つ目のコンテナーでシミュレーションが完了したときの出力例を次に示します。
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>両方のコンテナーで N 体シミュレーションが実行されているときに、デバイスの PowerShell インターフェイスから NVIDIA smi 出力を取得します。 出力例を次に示します。 3 つのプロセスがあり、
nvidia-cuda-mps-serverプロセス (種類 C) は MPS サービスに対応し、/tmp/nbodyプロセス (種類 M + C) は各モジュールによってデプロイされた N 体ワークロードに対応します。[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi